cog sci 131 section
week 02/14/22
by yuan meng
agenda
- get user inputs in jupyter
- regex refresher + practice
- hw4 prompt walkthrough
get user inputs
def pay_for_a_vehicle():
# enter plate number
plate = input("enter plate number: ")
# enter parking duration
duration = int(input("enter duration (min): "))
# print confirmation
print(f"Confirmation: {plate} is paid for {duration} min")
# return inputs for later use
return plate, durationuse the input() function in jupyter
store each user input in a variable
when you run it, you'll be asked to type inputs
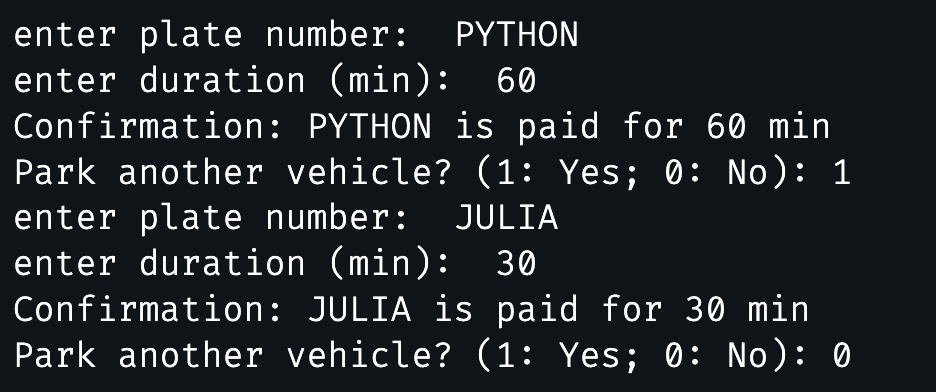
park multiple cars until you don't want to? 👉 use break in while-loop
while True:
# enter information for one vehicle
plate, duration = pay_for_a_vehicle()
# ask whether to pay for another
another = int(input("Park another vehicle? (1: Yes; 0: No):"))
# if not, break
if another == 0:
break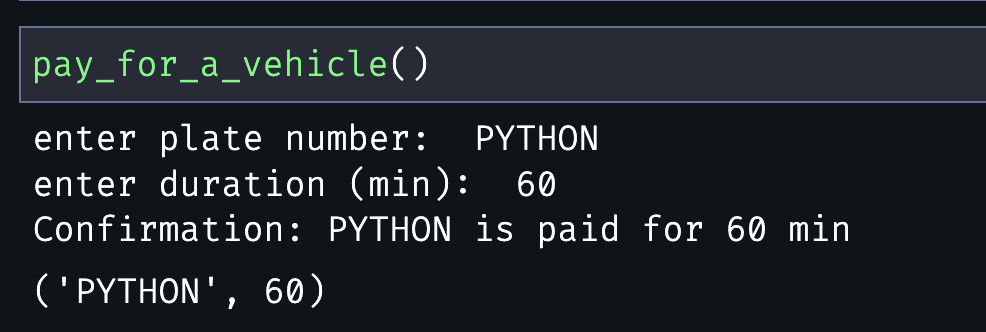
regex 101
find patterns in strings (tutorial)
-
match = re.search(pattern, string)
- how regex "thinks": starts from leftmost match + uses as much as of the string possible ("greedy")
- success (if match returns True) 👉 can use match.group() to return matching text; failure (if match returns False) 👉 returns None
-
occurrence: r"pattern" (pass raw strings)
- literal matching: "ordinary" characters match themselves 👉 not ordinary: ^$*+?{[]\|()}
- also special: \t (tab), \n (newline), \r (return)
- make any character ordinary: \ (e.g., \^)
- any single character: . (period)
- any particular type of character: \w (letter, digit, or _), \s (white space), \d (decimal digit)
- specify location: ^ (start), $ (end)
- repetitions: + (1 or more), * (0 or more), ? (0 or 1)
- not sure? use set [abc] or a|b|c 👉 match 'a', 'b', or 'c'
example: extract the email in "address colorless green ideas to chomsky1928@mit.edu"
# use built-in "re" library
import re
# test case
test = "address colorless green ideas to chomsky1928@mit.edu"
# write out pattern in 2 groups
pattern = r"(\w+\d+)@(\w+.\w+)"
# search for pattern in example
match = re.search(pattern, test)
# print results
if not match:
print("can't find emails")
else:
print(f"email found: {match.group()}")- first group: \w+d+ (repeating word characters + digits)
- second group: \w+.\w+ (word characters, period 👉 literal in group, word characters)
groups can be retrieved separately: match.group(1) is "chomsky1928" and match.group(2) is "mit@edu"
() denote a group
email found: chomsky1928@mit.edu
regex 101
- compare regex functions
- re.search(pattern, string): only finds first match and returns a string
- re.findall(pattern, string): finds all matches and returns a list
- re.sub(pattern, replacement, string): replace matches
-
practice: use regex to extract the following content
- i ate an icream" 👉 what did i eat
- drop common suffixes in company names: e.g., Apple Inc. 👉 Apple, Intel Corp. 👉 Intel...
example answers
# example 1: special -> exclude the word itself
re.search(r"(?<=ate).*$", "i ate an apple")
# example 2: special -> multi-line pattern
suffixes = re.compile(
r"""(,? inc.?| limited| unlimited| corporation| corp| llp.?| llc.?| ltd.?|
|\s?company| companies| & company| & co| and company| & son| holdings| solutions|
| partners| holdings| technologies| tech| infotech| informationnology| group| consulting|
| productions| digital| services| usa| us|\s?united states| global| worldwide| international)""",
re.MULTILINE,
)
# full name of company
full_name = "Apple Inc."
# replace suffix with empty string
simplified = suffixes.sub("", full_name.lower())(?<=abc)def: this pattern is called "positive lookbehind" 👉 looks for "abc" and returns "def" that's behind
cumbersome code i wrote for a data etl pipeline
you guessed it... there are also lookahead and lookaround... (learn more)
hw4 prompts
cogsci131_02_14_section
By Yuan Meng




