BI Dashboard Implementation
vincentchiang@kkbox.com
Senior Developer Advocate @
江品陞 @

About me
- Developer Advocate @
- Functional Programming Lover
- Data Engineer
- Cryptocurrency Trader

zaoldyeck @
當一間公司的產品
在市場上已經發展成熟
要如何繼續成長?
垂直整合


提供音樂串流服務
舉辦實體演唱會、售票
投資娛樂產業、負責音樂版權
水平整合
如何讓音樂在更多的載體
或者情境上被使用?









KKBOX 是一間軟體公司
我們並不擅長硬體設計製造
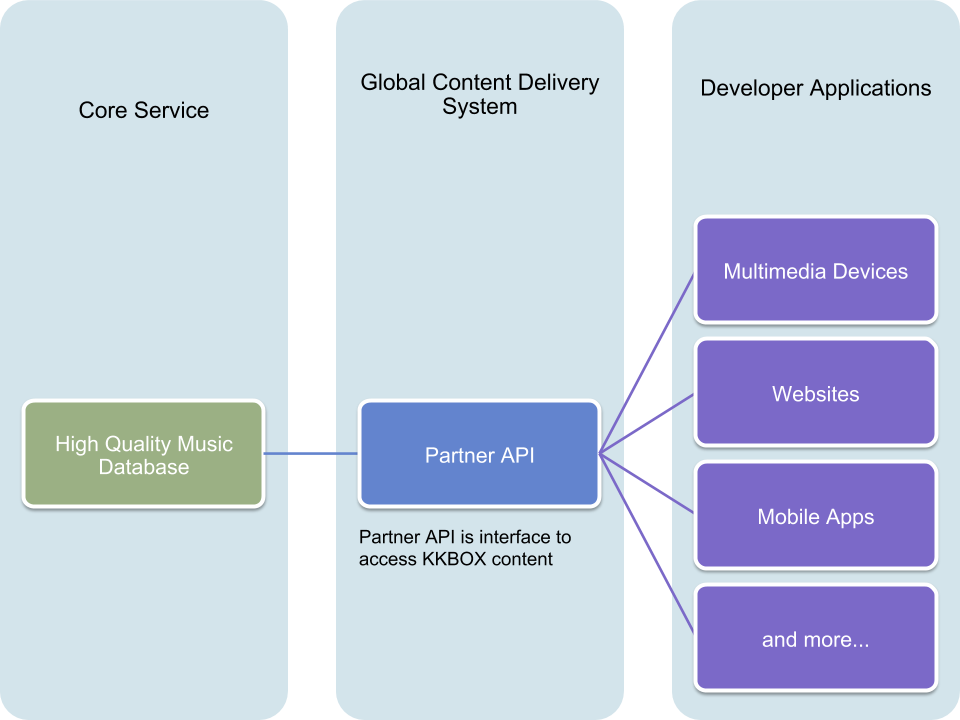
KKBOX Open API (developer.kkbox.com)
KKBOX Open API 提供什麼?
- KKBOX 全曲庫資料
- 排行榜、分類歌單、個人推薦歌單
- 會員收藏歌曲
- 打造專屬於該平台的 KKBOX





透過 Open API 我們可以
- 降低合作夥伴與我們的串接門檻
- 從 Access Log 分析,使我們暸解
- 何種平台具有發展性
- 在其他平台上什麼數據熱門
- 何種面向的產品會吸引使用者
- 異於官方產品的使用者習慣
- 最終,幫助我們制定商業決策
- BI Dashboard
2018-1 KKBOX Open API 武林大會

Questions
- 如何知道用戶喜不喜歡我們的產品?
- 從 Open API 上線以來的流量成長
- 如何知道哪一個 Client 用量最大?
- 用戶透過 Open API 搜尋哪些歌曲 / 歌手 / 專輯 / 歌單?
- 如何知道哪些 Resource 最受歡迎?
Today we focus on
- Not Google Analytics
- About API Access Log processing
- for Business Intelligence
BI Dashboard Implemantaion
-
Log Storage
- facebookarchive/scribe, AWS S3
-
ETL(Extract-Transform-Load)
- Scala
-
Data Storage
- Google Cloud BigQuery
-
Data Visualization
- Google Data Studio

ETL Issues
- 資料處理邏輯複雜
- 中途易出錯,需要做例外處理
- 數據量大,需要高效高併發
我們期望的資料結構
| client_id | url_path | header_key | herder_value | request_ parameter_key |
request_ parameter_value |
reponse_status | response_body | timestamp |
|---|---|---|---|---|---|---|---|---|
| "demo id" | "/v1.1/search" | "Authorization" | "Bearer access_token" | "q" | "五月天" | 200 | "派對動物" | "2017-11-21T15:00:03+08:00" |
| "demo id2" | "/v1.1/charts" | "Authorization" | "Bearer access_token" | "territory" | "TW" | 200 | "2017-11-21T15:00:03+09:00" |
Local
Scribe Server
Central
Scribe Server
Web API Server
Load Balancer
Web API Server
Web API Server
Web API Server
Web API Server
Local
Scribe Server
Local
Scribe Server
Local
Scribe Server
Local
Scribe Server
Central
Scribe Server
Client API Request
Access Log
Access Log
Access Log
Access Log
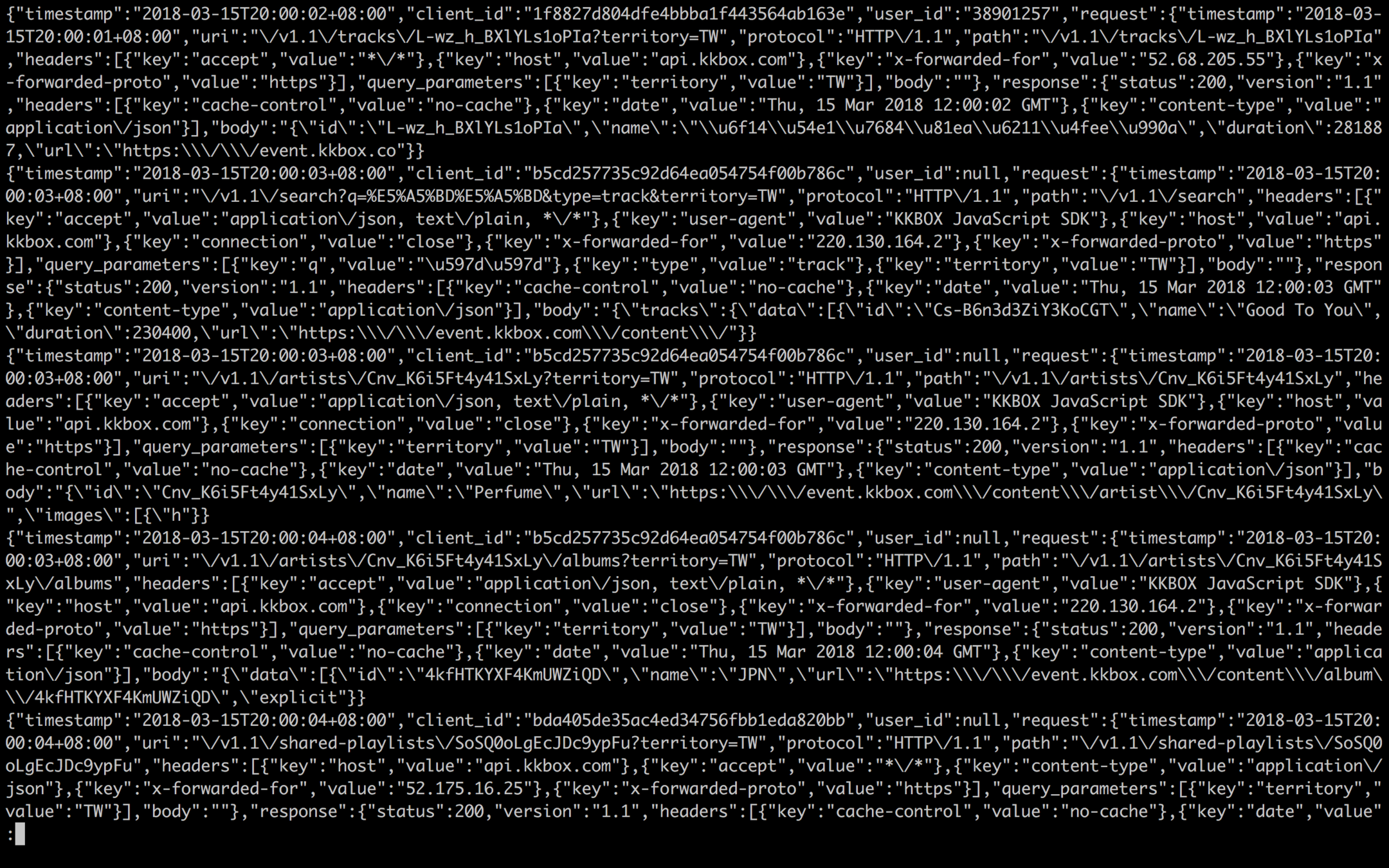
{
"timestamp": "2017-11-21T15:00:03+08:00",
"client_id": "demo_client_id",
"user_id": null,
"request": {
"timestamp": "2017-11-21T15:00:03+08:00",
"uri": "\/v1.1\/shared-playlists\/4nUZM-TY2aVxZ2xaA-\/tracks?territory=TW",
"protocol": "HTTP\/1.1",
"path": "\/v1.1\/shared-playlists\/4nUZM-TY2aVxZ2xaA-\/tracks",
"headers": [
{
"key": "accept",
"value": "application\/json, text\/plain, *\/*"
},
{
"key": "user-agent",
"value": "KKBOX JavaScript SDK"
},
{
"key": "host",
"value": "api.kkbox.com"
},
{
"key": "connection",
"value": "close"
},
{
"key": "x-forwarded-for",
"value": "220.130.164.2"
},
{
"key": "x-forwarded-proto",
"value": "https"
}
],
"query_parameters": [
{
"key": "territory",
"value": "TW"
}
],
"body": ""
},
"response": {
"status": 200,
"version": "1.1",
"headers": [
{
"key": "cache-control",
"value": "no-cache"
},
{
"key": "content-type",
"value": "application\/json"
},
{
"key": "date",
"value": "Tue, 21 Nov 2017 07:00:03 GMT"
}
],
"body": "{\"data\":[{\"id\":\"SsJItLYfDXYxalPgtU\",\"name\":\"\\u9019\\u500b\\u4e16\\u754c\",\"duration\":240195,\"url\":\"https:\\\/\\\/event.kkbox.com\\\/conten"
}
}{
"timestamp": "2017-11-21T15:00:03+08:00",
"client_id": "demo_client_id",
"user_id": null,
"request": {
"timestamp": "2017-11-21T15:00:03+08:00",
"uri": "\/v1.1\/shared-playlists\/4nUZM-TY2aVxZ2xaA-\/tracks?territory=TW",
"protocol": "HTTP\/1.1",
"path": "\/v1.1\/shared-playlists\/4nUZM-TY2aVxZ2xaA-\/tracks",
"headers": {
"accept": "application\/json, text\/plain, *\/*",
"user_agent": "KKBOX JavaScript SDK",
"host": "api.kkbox.com",
"connection": "close",
"x_forwarded_for": "220.130.164.2",
"x_forwarded_proto": "https"
},
"query_parameters": {
"territory": "TW"
},
"body": ""
},
"response": {
"status": 200,
"version": "1.1",
"headers": {
"cache_control": "no-cache",
"content_type": "application\/json",
"date": "Tue, 21 Nov 2017 07:00:03 GMT"
},
"body": "{\"data\":[{\"id\":\"SsJItLYfDXYxalPgtU\",\"name\":\"\\u9019\\u500b\\u4e16\\u754c\",\"duration\":240195,\"url\":\"https:\\\/\\\/event.kkbox.com\\\/conten"
}
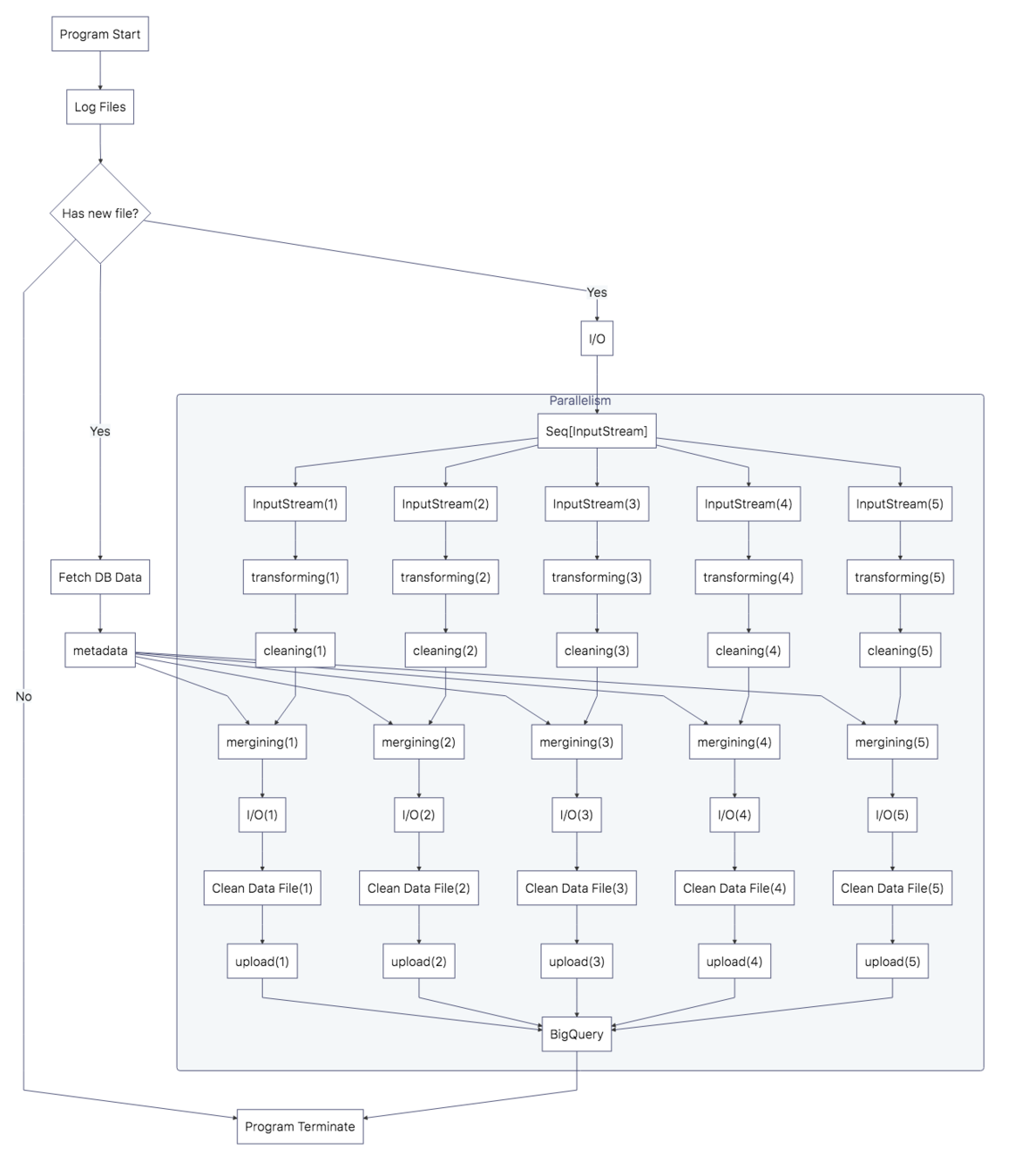
}Data Pipeline
- Transforming
- Cleaning
- Merging
| user_id | status | last_login |
|---|
| user_id | song_id | client_id | device_id | listen_at |
|---|
動態資料
靜態資料
| user_id | status | last_login | song_id | client_id | device_id | listen_at |
|---|
Title Text
- Running on JVM
- Highly performance
- Mixing object-oriented and functional programming
- Easily to make program concurrency and parallelism





Programming Lang Choosing
> 1,000,000 or Not?
Benefits for data pipeline
- Type safety
- No side effect
- Lambda Expression
- Concurrency
- all for Parallelism
Type safety
val optionWithInt: Option[Int] = Some(1)
val emptyOption: Option[Int] = None
if (optionWithInt.isDefined) println(optionWithInt.get) //1
emptyOption match {
case Some(int) => println(int) // 1
case None => println("is empty") // is empty
}
val value = emptyOption.getOrElse(0) // 0No Side Effect
/* Cause Side effect */
var value = 0
def addValue(): Unit = {
value += 1
}
println(value) // 1
val values = mutable.Seq(1, 2, 3, 4, 5)
for (i <- values.indices) {
values(i) = values(i) + 1
}
println(values) // ArrayBuffer(2, 3, 4, 5, 6)/* No side effect */
val value = 0
def addValue(v: Int): Int = v + 1
val newValue = addValue(value)
println(value) // 0
println(newValue) // 1
val values = Seq(1, 2, 3, 4, 5)
val newValues = values.map(_ + 1)
println(values) // List(1, 2, 3, 4, 5)
println(newValues) // List(2, 3, 4, 5, 6)Lambda Expression
// no Lambda Expression
import scala.collection.mutable
val seq: Seq[String] = Seq("1", "2", "3", "4", "5", "6", "7", "8", "9", "10")
var result: Seq[Int] = mutable.Seq()
for (i <- seq.indices) {
val int = i.toInt
if (int > 5) result = result :+ int * 10
}
println(result) // ArrayBuffer(60, 70, 80, 90)// with Lambda Expression
val seq: Seq[String] = Seq("1", "2", "3", "4", "5", "6", "7", "8", "9", "10")
val result = seq
.map(_.toInt)
.filter(_ > 5)
.map(_ * 10)
println(result) // ArrayBuffer(60, 70, 80, 90)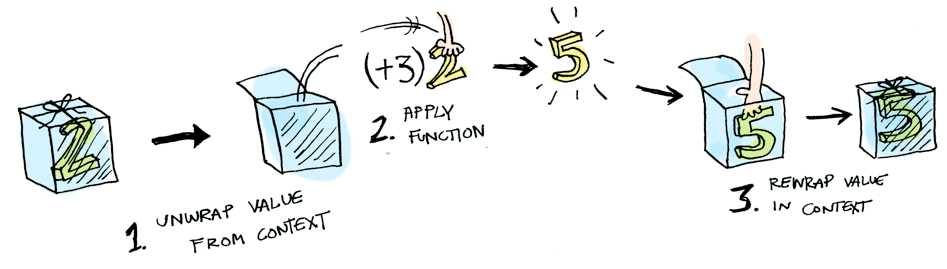
Concurrency
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.duration.Duration
import scala.concurrent.{Await, Future}
def stringToInt(s: String) = Future {
Thread.sleep(1000)
s.toInt
}
def add(i: Int) = Future {
Thread.sleep(1000)
i + 1
}
def multiply(i: Int) = Future {
Thread.sleep(1000)
i * 10
}
val task = stringToInt("1") flatMap {
i => add(i)
} flatMap {
i => multiply(i)
}
Await.result(task, Duration.Inf)
val task2: Future[Future[Int]] = for {
int <- stringToInt("1")
int2 <- add(int)
} yield multiply(int, int2)
Await.result(task2, Duration.Inf)Parallelism
import scala.collection.parallel.ParSeq
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.duration.Duration
import scala.concurrent.{Await, Future}
val data: Seq[String] = Seq("1", "2", "3", "4", "5", "6", "7", "8", "9", "10")
val parSeq: ParSeq[Int] = data
.par
.map(_.toInt)
.filter(_ > 5)
.map(_ + 1)
def stringToInt(s: String) = Future {
Thread.sleep(1000)
s.toInt
}
val seqOfFuture: ParSeq[Future[Int]] = data
.par
.map(stringToInt)
val futureOfSeq: Future[ParSeq[Int]] = Future.sequence(eventualInt)
Await.result(futureOfSeq, Duration.Inf)KKBOX Open API Server
Scribe Server
Data Transforming
Data Cleaning
Data Merging
Data Upload
Google Cloud BigQuery
Google Data Studio
Access Log
@throws[IOException]
@throws[InterruptedException]
@throws[TimeoutException]
def writeFileToTable(path: Path, tableName: String = "open_api_log", datasetName: String = "production", isAutodetect: Boolean = false): Long = { // [START writeFileToTable]
val yes = true
val tableId: TableId = TableId.of(datasetName, tableName)
val writeChannelConfiguration: WriteChannelConfiguration = WriteChannelConfiguration
.newBuilder(tableId)
.setCreateDisposition(CreateDisposition.CREATE_IF_NEEDED)
.setFormatOptions(FormatOptions.json)
.setAutodetect(isAutodetect)
.setIgnoreUnknownValues(yes)
.setWriteDisposition(WriteDisposition.WRITE_APPEND)
.setMaxBadRecords(99999999)
.build
val writer: TableDataWriteChannel = bigQuery.writer(writeChannelConfiguration)
// Write data to writer
try {
val stream: OutputStream = Channels.newOutputStream(writer)
try
Files.copy(path, stream)
finally if (stream != null) stream.close()
}
// Get load job
var job: Job = writer.getJob
job = job.waitFor()
val stats: LoadStatistics = job.getStatistics[LoadStatistics]
stats.getEndTime
// [END writeFileToTable]
}Data Visualization Issues
- 資料載入速度慢
- 與 Standard SQL 不相容(例如不能 join)
- 資料不民主
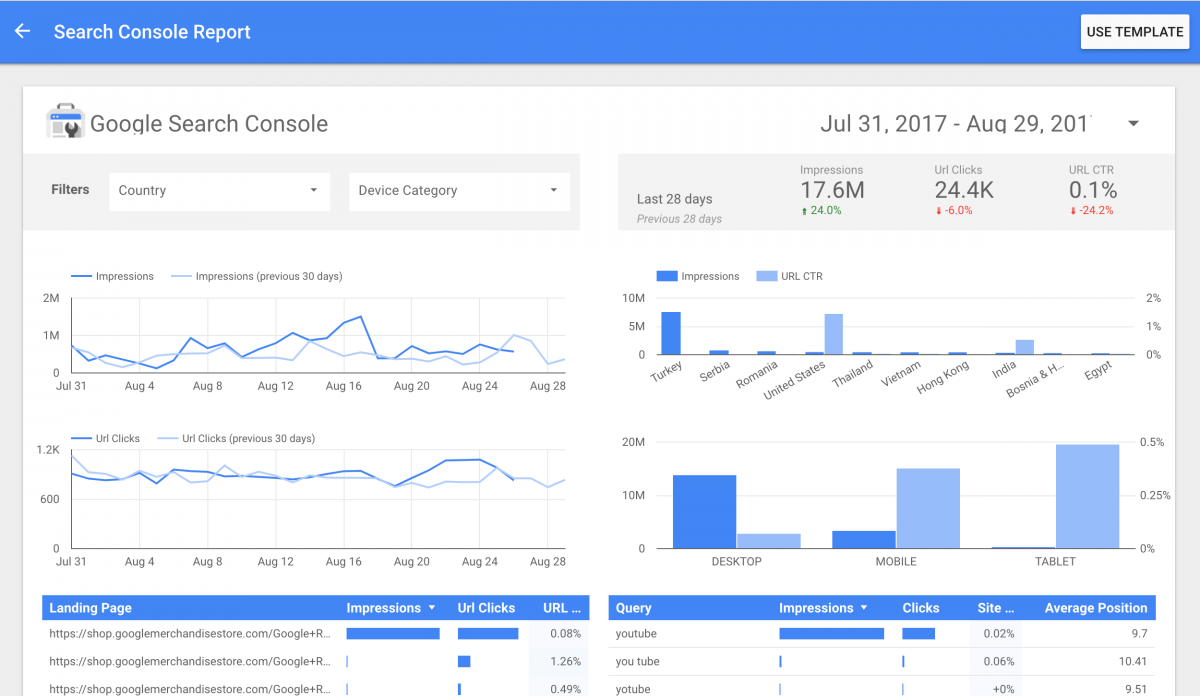
BigQuery + Data Studio

BigQuery
- 優異的資料查詢速度
- 便宜的價格(資料記得要做 Auto Partition)
- 與 Standard SQL 相容
Data Studio
- 用 G suite 管理儀表板權限(類似 Google Doc)
- 視覺化方式建立圖表
成果
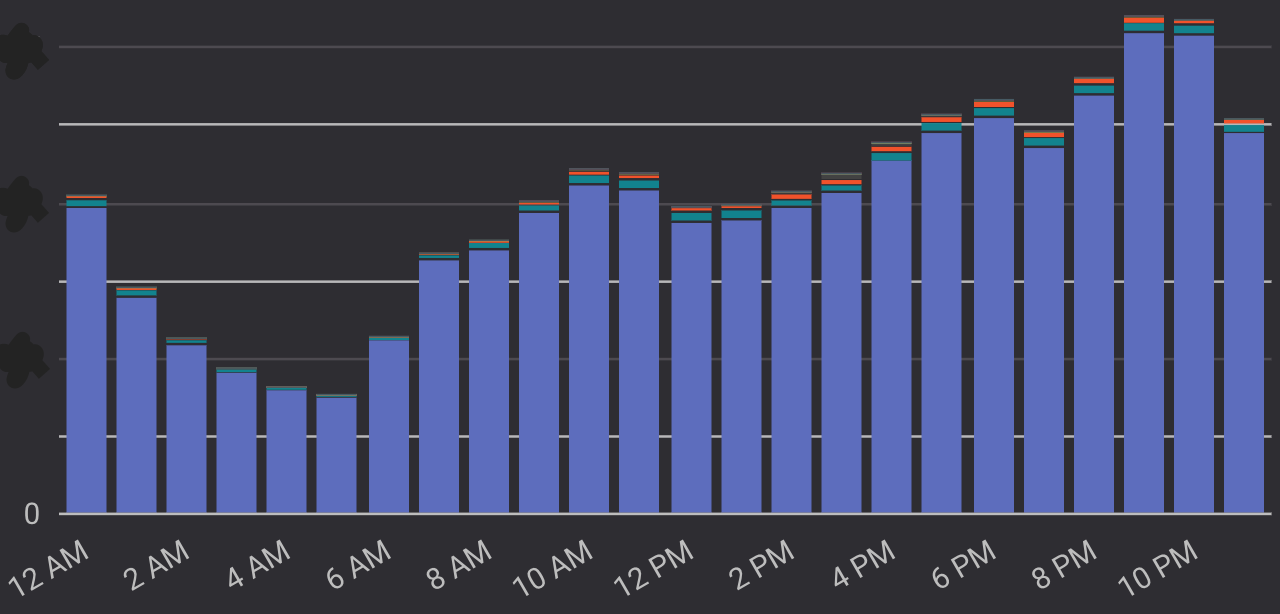
- 發現 IoT 用戶的使用習慣與 App 不同
- 用量高峰發生在晚間
- 有聲書類別意外擠進排行榜
- 從數據中設法勾勒出特定使用者的輪廓
分眾

水平發展策略
開放資料
分析數據用量與使用情境
與互補型合作夥伴串接
描繪特殊受眾輪廓
推出分眾產品
Thanks!
Data Visualization
Visualization Framework Choosing
- Google Cloud BigQuery + Google Data Studio
- Reasons
-
Google Cloud BigQuery
- 資料將不斷累積 => 不適合堆在單一伺服器
- 性能優越
- 可以用 SQL 做 Query
-
Google Data Studio
- 可直接拉 BigQuery 的資料做視覺化
- G Suite
- 內建權限管理
- 易實現資料民主化
-
Google Cloud BigQuery
Weaknesses of BigQuery
- Not schemaless
Questions
- 如何知道用戶喜不喜歡我們的產品?
- 從 Open API 上線以來的流量成長
- 如何知道哪一個 Client 用量最大?
- 用戶透過 Open API 搜尋哪些歌曲 / 歌手 / 專輯 / 歌單?
- 如何知道哪些 Resource 最受歡迎?
Questions
- 如何知道用戶喜不喜歡我們的產品?
- 如何定義喜歡? => Domain Knowledge
- 用戶黏著度 => Custom SQL
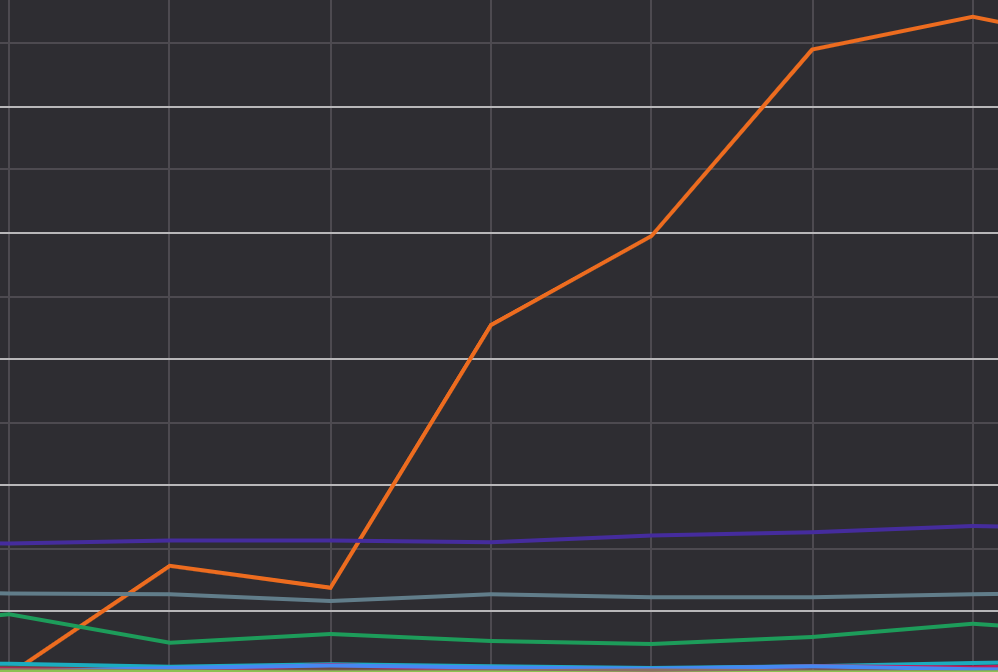
- 從 Open API 上線以來的流量成長 => 趨勢
- 如何知道哪一個 Client 用量最大? => 比較
- 用戶透過 Open API 搜尋哪些歌曲 / 歌手 / 專輯 / 歌單? => 分佈
- 如何知道哪些 Resource 最受歡迎? => 列表 / 分佈
如何知道用戶喜不喜歡我們的產品?
-- Custom SQL
select
DATE(TIMESTAMP_MICROS(timestamp*1000),"Asia/Taipei") as date,
client_key,
client_name,
count(user_id)/count(distinct(user_id)) as listen_times_per_user
from production.open_api_log
where request.path="/v1.1/music_streaming" and
developer_id is null and
user_id is not null and
response.status=200
group by date, client_id, client_key, client_name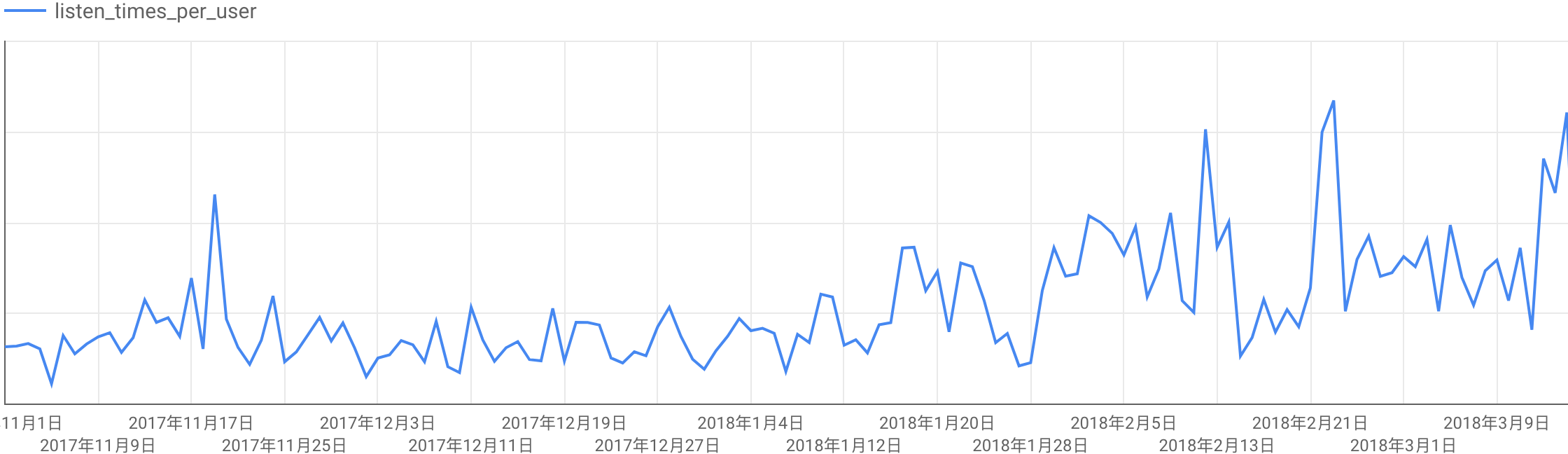
從 Open API 上線以來的流量成長
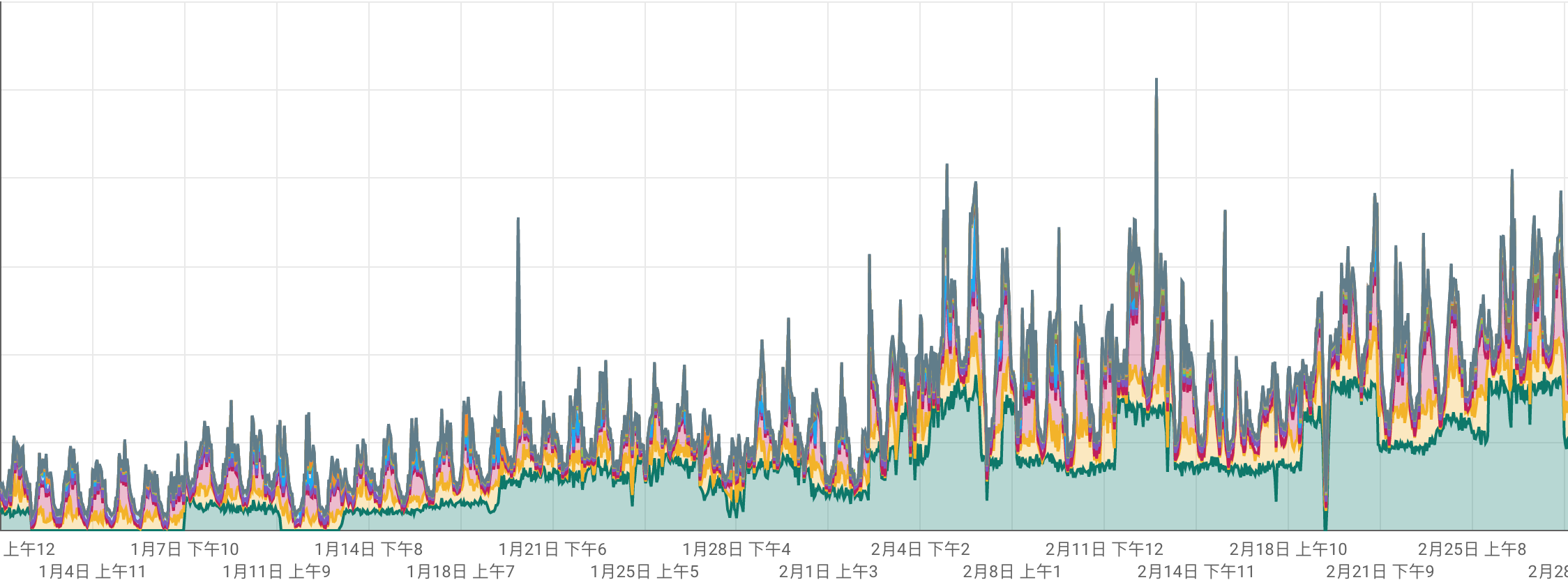
如何知道哪一個 Client 用量最大?
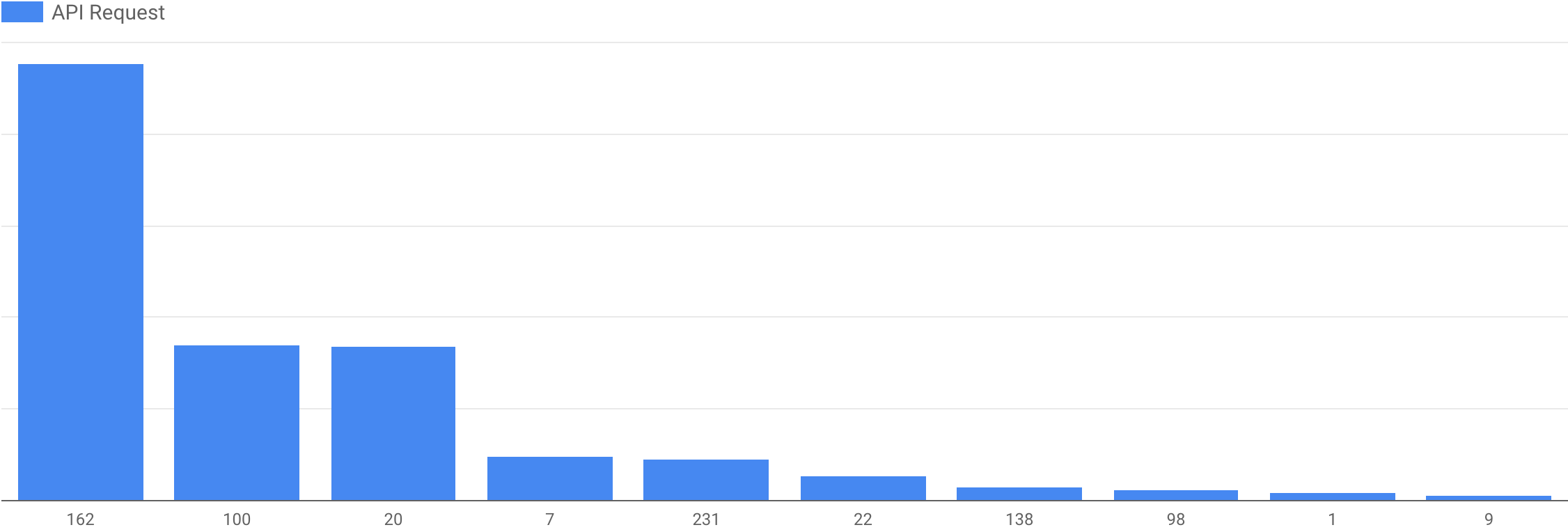
用戶透過 Open API 搜尋哪些歌曲 / 歌手 / 專輯 / 歌單?
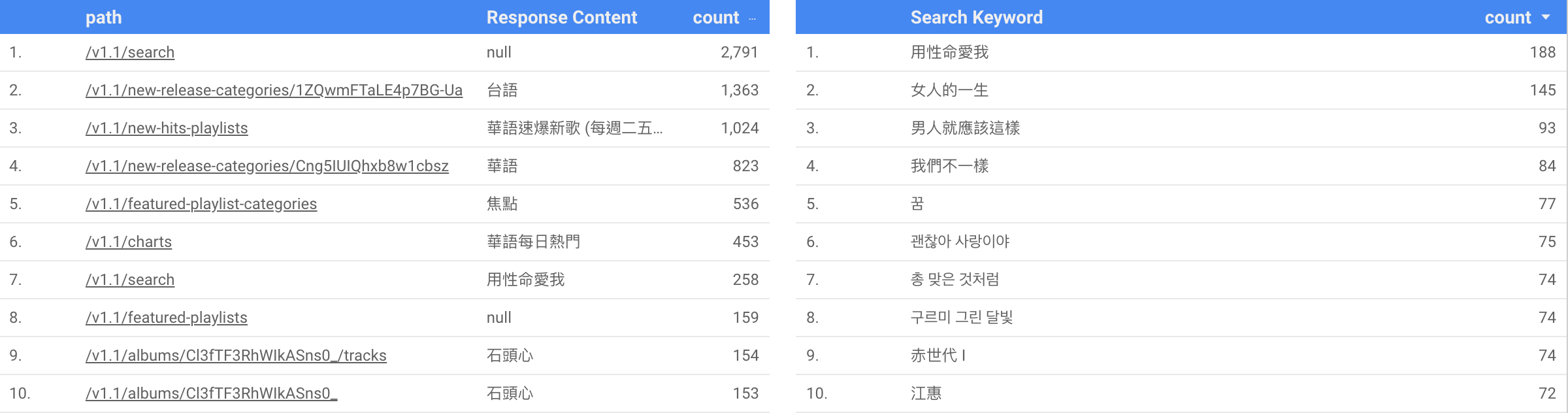
Resource 使用分佈

還有一種叫散佈圖
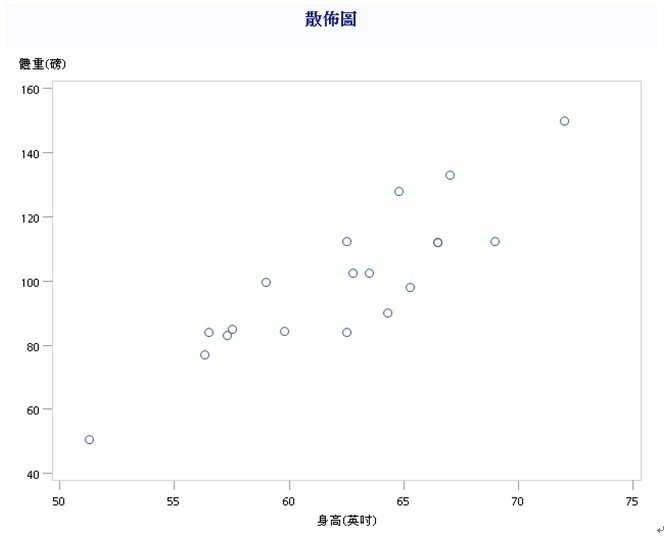
Summary
- Business Logic
- 定義問題
- 釐清需求
- Data Processing
- No side effect
- Type safe
- Concurrency
- Data Visualization
- Domain Knowledge => Custom SQL
- 看趨勢 => 趨勢圖
- 比大小 => 長條圖
- 看分佈 => 分佈圖
- 關聯性 => 散佈圖
BI Dashboard Implementation
By zaoldyeck




