SSSP
Pthread
-
BellmenFord
-
Dijkstra
-
Parallel BellmenFord
Sequential
-
no negative cycle
-
Dijkstra
-
better time complexity
Parallel
-
Dijkstra need a global queue
-
BellmenFord
-
Paralle second for loop
-
need lock each vertex's distance_to_source
-
lock take lots of time
-
clone the previous iteration result
Result

Parallel Read
-
txt file
-
vertex need mutex
Parallel Read
-
the i thread skip i/total_thread line
-
the skip still need linear time
-
string to integer
-
use lock when add neighbors
Parallel Read(20K)

balance
the i - 1 thread do more 10% work than i thread

implement of djk

other optimization
-
uint32_t int32_t 20% IO
-
struct 40% compute
MPI sync
-
Use MPI graph library
-
MPI_Dist_graph_create
-
MPI_Dist_graph_neighbors_count
-
MPI_Dist_graph_neighbors
-
MPI_Neighbors_allgather
Library optimize
-
Each vertex only synchronize with neighbors
-
Allgather with tree transform
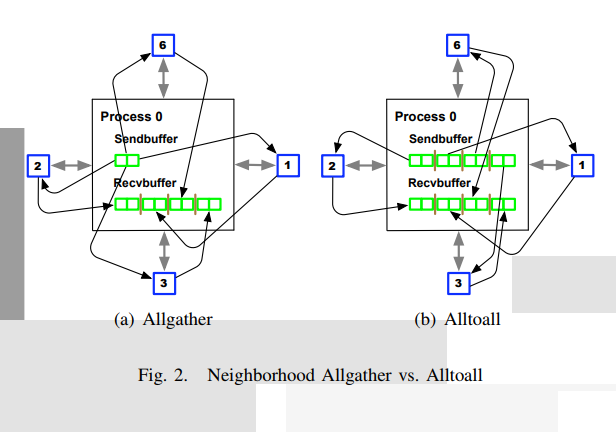
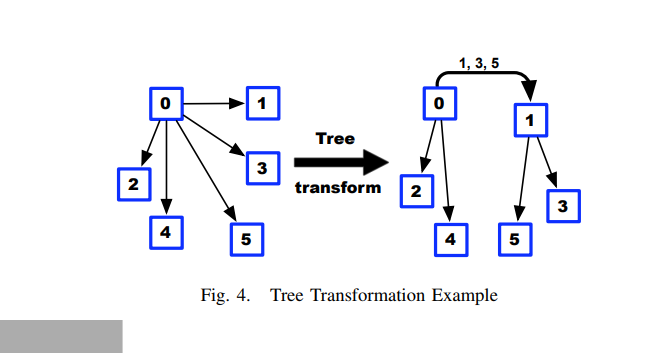
MPI Synchronize
MPI_Dist_graph_neighbors(graph_communicator, indrgee, sources,
sources_weight, outdegree, destinations, destinations_weight);
while ( not global_done ) {
// 對圖中的每一個點,接收鄰居的 destination_to_source
MPI_Neighbor_allgather(&distance_to_source, 1,
MPI_INT, neighbors_dest_to_source, 1, MPI_INT, graph_communicator);
bool local_done = true;
for ( ssize_t i = 0; i < indrgee; ++i) {
if (neighbors_dest_to_source[i] == std::numeric_limits<int32_t>::max())
continue;
const int32_t your_weight = neighbors_dest_to_source[i] + sources_weight[i];
if ( your_weight < distance_to_source) {
distance_to_source = your_weight;
parent = sources[i];
local_done = false;
}
}
// reduce local_done with logical and
MPI_Allreduce(&local_done, &global_done, 1, MPI::BOOL, MPI_LAND,
graph_communicator);
}Parallel construct
// if nprocs > 16, use only 16
activeConstructor = (nprocs < 16) ? nprocs : 16;
if (Rank < activeConstructor) {
std::ifstream infs;
infs.open(input_file);
infs >> vertex_num >> edge_num;
infs.close();
// count offset, workload, parallel construct
ParallelConstructGraph();
} else {
int32_t* sources = nullptr;
int32_t* degrees = nullptr;
int32_t* destinations = nullptr;
int32_t* weights = nullptr;
// collective call
MPI_Dist_graph_create(MPI_COMM_WORLD, 0, sources, degrees, destinations,
weights, MPI_INFO_NULL, false, &graph_communicator);
}Parallel construct

MPI async
-
MPI_Irecv
-
MPI_Waitany
-
select
MPI async
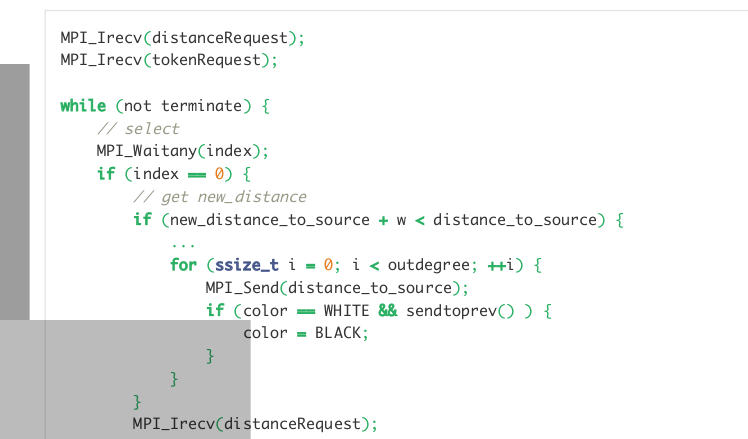
async v.s sync

SSSP
By zlsh80826



