PRINCÍPIOS E TÉCNICAS DE ELETROENCEFALOGRAFIA EM NEUROCIÊNCIA
AULA 07 - Teoria da Informação: O Teorema de Shannon (parte I)
Instituto de Ciência e Tecnologia
Graduação em Engenharia Biomédica
Prof. Dr. Adenauer G. Casali
Laboratório de Neuroengenharia e Computação
casali@unifesp.br



PRINCÍPIOS E TÉCNICAS DE EEG EM NEUROCIÊNCIA
- Informação neural
- Claude Shannon e o conceito de Informação como redução de incerteza
- Preparação para o teorema de Shannon: ensemble, sequências e compressão
- O conjunto das Sequencias Típicas
Adenauer G. CASALI
AULA 07
Nesta aula, nós veremos...

1. Informação Neural
Princípios e Técnicas de EEG
Aula 07
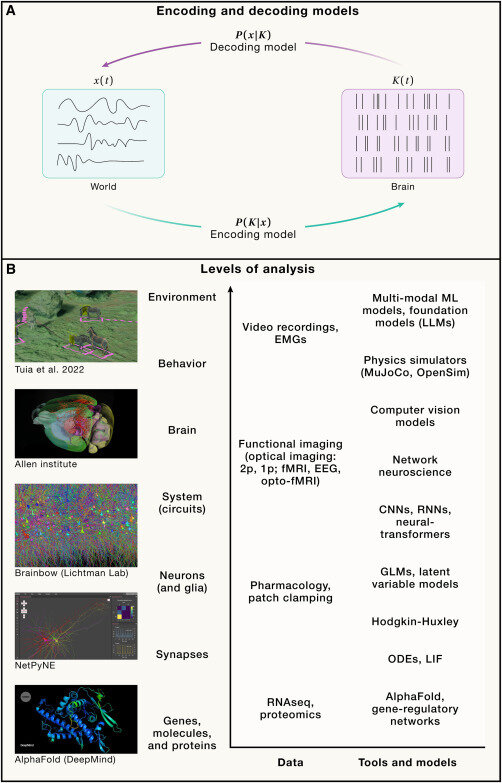
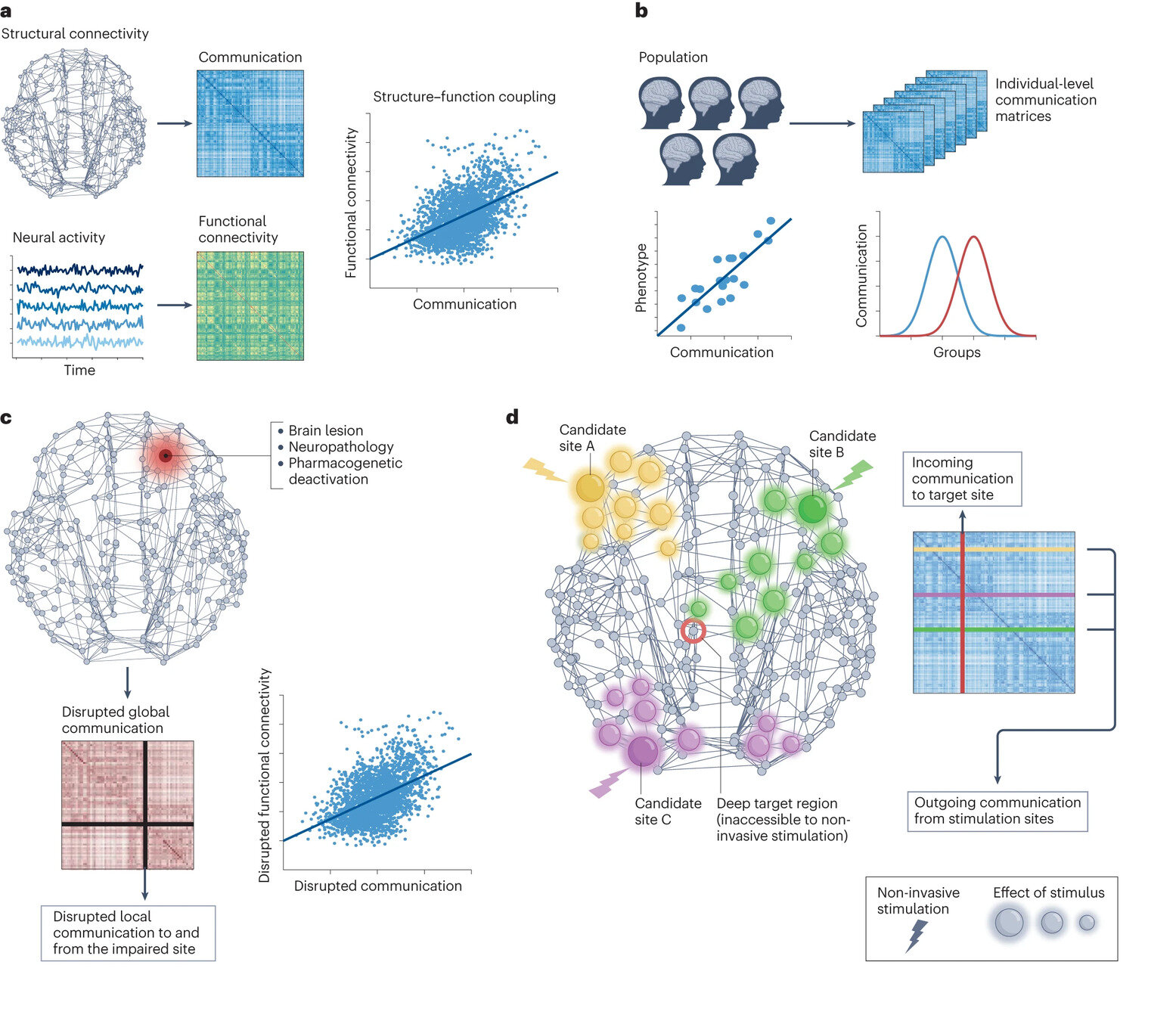
Fonte: Zhu et al. (2025)
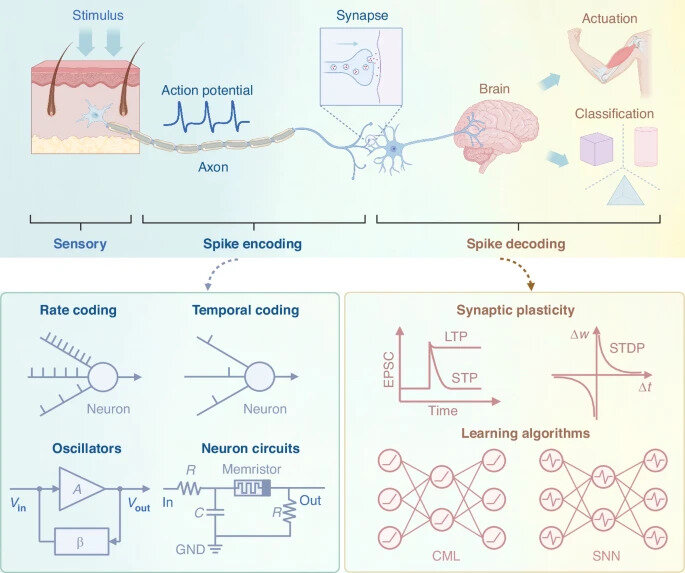
Fonte: Mattis et al., (2024)
1. Informação Neural
Princípios e Técnicas de EEG
Aula 07
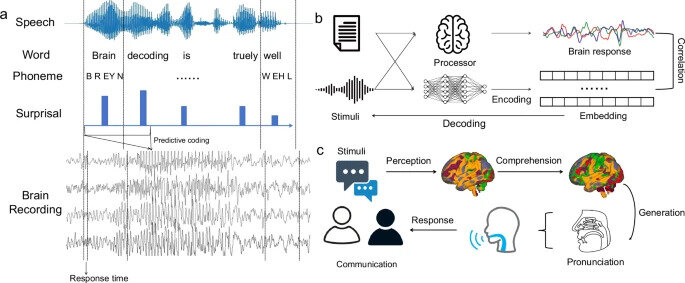
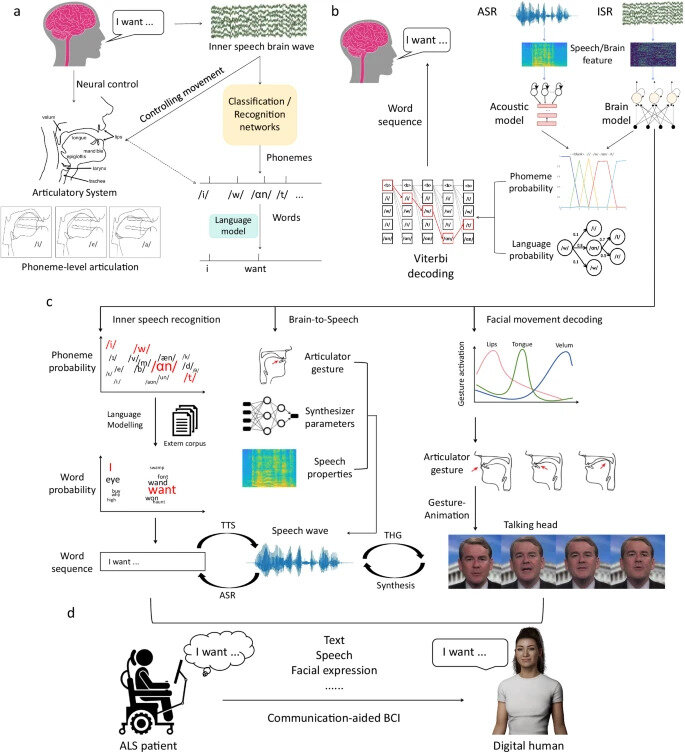
"Speech Neuroprosthesis"
1. Informação Neural
Princípios e Técnicas de EEG
Aula 07
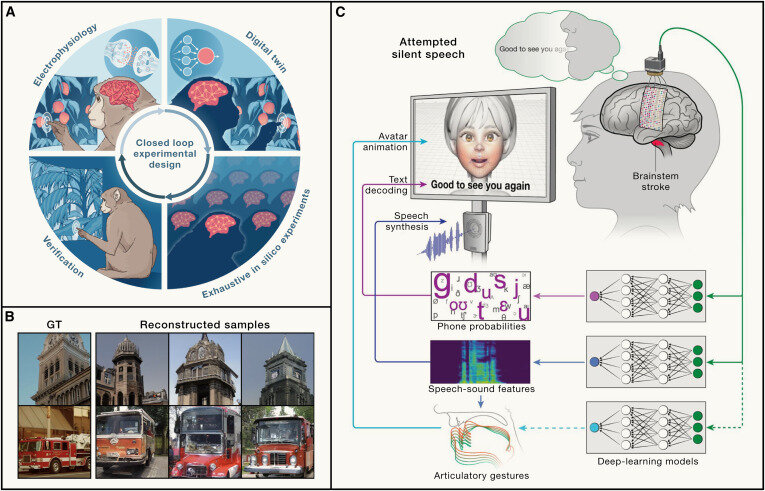
Fonte: Mattis et al., (2024)
Mas o que é "Informação" exatamente?
Princípios e Técnicas de EEG
Aula 07
Claude Shannon
(1916-2001)


Fonte: Shannon, C. (1948)
2. Claude Shannon e o conceito de Informação
Princípios e Técnicas de EEG
Aula 07
Claude Shannon
(1916-2001)
"A basic idea in information theory is that information can be treated very much like a physical quantity, such as mass or energy."
\text{Conceito de \bf{ensemble}:}
\text{Um {\bf ensemble} X é uma tripla: }(x,\mathcal{A}_X, \mathcal{P}_X), \text{ onde $x$ é o {\it outcome} de uma}
\text{variável aleatória com $I$ valores possíveis e que formam o conjunto }
\mathcal{A}_X = \{a_1, a_2,..., a_i,...,a_I\}, \text{ com respectivas probabilidades}
\mathcal{P}_X = \{p_1, p_2,..., p_i,...,p_I\}, \text{ sendo } P(x=a_i)=p_i, p_i\geq 0, \sum_{a_i\in \mathcal{A}_X}P(x=a_i) = 1.
\text{Como medir quanta informação há na variável $x$?}
\text{Imagine um ensemble onde }\mathcal{A}_X =\{a_1\}, \text{ isto é, só há um valor possível para $x$.}
\text{Neste caso, medir $x$ {\it informa} algo?}
3. Preparação para o Teorema de Shannon
Princípios e Técnicas de EEG
Aula 07
\text{Se }\mathcal{A}_X =\{a_1\}, \text{ a informação em $x$ é nula.}
\text{A Informação em $X$ tem a ver com o número de elementos em $\mathcal{A}_X$, também denotado por $|\mathcal{A}_X|$.}
\text{Podemos usar a escala logarítmica, para que quando $|\mathcal{A}_X|=1$, a informação seja nula. Definimos:}
H_0(X) = \log_2(|\mathcal{A}_X|)
\text{Mas será que esta é de fato a medida de informação em $X$? Por exemplo, não seria possível}
\text{que $X$ possuísse redundâncias? Isto é, que houvesse mais valores em $\mathcal{A}_x$ do que necessário}
\text{Seria possível {\bf comprimir} $\mathcal{A}_X$ para um ensemble menor sem perder informação relevante? }
\text{e usamos {\it bits} como unidade.}
\text{na prática?}
3. Preparação para o Teorema de Shannon
Princípios e Técnicas de EEG
Aula 07
\text{De fato, considere dois ensembles $X$ e $Y$: }
\text{$\mathcal{A}_X = \{0,1\}$, com $\mathcal{P}_X = \{1/2, 1/2\}$ }
\text{$\mathcal{A}_Y = \{0,1\}$, com $\mathcal{P}_Y = \{0.999, 0.001\}$ }
H_0(X) = \log_2(|\mathcal{A}_X|) = 1 \:bit
H_0(Y) = \log_2(|\mathcal{A}_Y|) = 1 \:bit
\text{$X$ parece conter mais informação que $Y$: quando você mede $x$, você descobre algo mais }
\text{{\bf surpreendente} do que ao medir $y$. $x$ é menos {\bf previsível} do que $y$ mesmo se $|\mathcal{A}_X|=|\mathcal{A}_Y|$.}
\text{A informação de um ensemble é uma medida da {\bf imprevisibilidade} do seu {\it outcome}.}
\text{Precisamos então levar em conta as probabilidades!}
3. Preparação para o Teorema de Shannon
Princípios e Técnicas de EEG
Aula 07
\text{Por exemplo, considere $X$ tal que: }
\mathcal{A}_X = \{a,b,c,d,e,f,g,h\}
\mathcal{P}_X = \{1/4,1/4,1/4,3/16,1/64,1/64,1/64,1/64\}
\text{Podemos pensar em comprimir $X$ assumindo um certo risco de perder algum valor de $x$ no processo}
\text{Compressão com risco $\delta$: formamos o menor subconjunto $S_{\delta}$ tal que $P(x\notin S_{\delta})\leq \delta $}
\text{O ensemble $X$ acima pode ser comprimido para um ensemble de 2 bits com risco $\delta = 1/16$.}
\text{Para encontrar $S_{\delta}$ basta ordenar os elementos de $\mathcal{A}_X$ em ordem decrescente de probabilidade}
\text{e adicionar elementos até que a probabilidade cumulativa seja $\geq (1-\delta)$.}
\text{A quantidade de informação sob tal compressão é $H_{\delta}(X) = \log_2(|S_{\delta}|)$.}
3. Preparação para o Teorema de Shannon
Princípios e Técnicas de EEG
Aula 07
\text{Mas como isso poderia ser útil? Afinal tudo parece depender de $\delta$, certo? Não exatamente! }
\text{Mas para isso, teremos que considerar {\bf sequências} geradas a partir de um {\bf ensemble}.}
\text{O resultado que buscamos é o teorema principal de Shannon.}
\text{Uma sequência $\vec{x}$ de comprimento $N$ de um ensemble $X$ é um {\it outcome} do ensemble definido}
\text{pelo produto cartesiano $X^N = (\vec{x}, \mathcal{A}_{X}^N, \mathcal{P}_{X^N})$ }
\mathcal{A}_X = \{a_1,a_2,...,a_i,...,a_I\}
\mathcal{P}_X = \{p_1,p_2,...,p_i,...,p_I\}
\text{Por exemplo, para o ensemble $X$ tal que:}
\vec{x} = a_1a_1a_4a_2a_5a_2a_1a_8
\text{Uma sequência de $X^8$ é $\vec{x}\in\mathcal{A}_X^8$:}
\text{e $P(\vec{x}) = p_1^3p_2^2p_4p_5p_8$}
3. Preparação para o Teorema de Shannon
Princípios e Técnicas de EEG
Aula 07
p_iN \text{ elementos }a_i, i=1...I.
\text{O que é relevante sobre sequências é que se $N\rightarrow \infty$, as sequências revelam a estrutura de $\mathcal{P}_X$}
P(\vec{x}) = P(x_1)P(x_2)...P(x_N) \approx p_1^{Np_1}p_2^{Np_2}...p_I^{Np_I}
\text{Então a probabilidade desta sequência típica é:}
\text{Em escala logarítmica:\:}\:\: \log_2P(\vec{x})\approx Np_1\log_2(p_1)+Np_2\log_2(p_2) +....+ Np_I\log_2(p_I)
\text{Vamos definir uma grandeza $H$ para o ensemble $X$ da seguinte forma: } H(X) = -\sum_{i=1}^{I}p_i\log_2(p_i)
\text{Se formarmos uma sequência suficientemente grande, devemos esperar que a sequência contenha}
\mathcal{A}_X = \{a_1,a_2,...,a_i,...,a_I\}
\mathcal{P}_X = \{p_1,p_2,...,p_i,...,p_I\}
\text{Ainda para o ensemble $X$ tal que:}
4. Sequências Típicas
Princípios e Técnicas de EEG
Aula 07
\text{Note que a probabilidade de uma string típica de $X$ para $N$ grande é}
\log_2P(\vec{x})\approx -NH(X)
\text{Com } H(X) = -\sum_{i=1}^{I}p_i\log_2(p_i)
P(\vec{x})\approx 2^{-NH(X)}
\text{Chamamos o subconjunto de elementos típicos de $\mathcal{A}_X^{N}$ com tolerância $\beta$ de $T_{N\beta}$:}
T_{N\beta} \equiv \Bigl\{ \vec{x}\in \mathcal{A}_{X}^{N} : \Bigl| \frac{1}{N}\log_2\Bigl(\frac{1}{P(\vec{x})}\Bigr) - H\Bigr|< \beta\Bigr\}
\text{Com esta definição, poderemos provar o chamado {\it Source Coding Theorem} de Shannon!}
\text{É claro que podemos esperar um certo desvio em torno desse valor (visto que a sequência é}
\text{aleatória). Para controlar este desvio, vamos introduzir um parâmetro $\beta$ e definir o que segue.}
4. Sequências Típicas
Princípios e Técnicas de EEG
Aula 07
\text{Defina a seguinte variável aleatória:}
u_{\vec{x}} = \frac{1}{N} \log_2\Bigl(\frac{1}{P(\vec{x})}\Bigr)
\text{Note que esta variável aleatória corresponde à média entre $N$ variáveis aleatórias $h_{x_n}$, $n=1...N$:}
\text{com $\vec{x}$ saído do ensemble $X^N$, $\:\:\vec{x}=x_1x_2...x_N$.}
h_{x_n} = \log_2\Bigl(\frac{1}{P(x_n)}\Bigr)
\text{pois $P(\vec{x}) = P(x_1)P(x_2)...P(x_n)...P(x_N)$} \text{ e }
\text{Veja que o valor esperado da variável aleatória $h_{x_n}$ é}
\sum_{n=1}^{I} P(x_n) \log_2\Bigl(\frac{1}{P(x_n)}\Bigr) = H(X)
u_{\vec{x}} = \frac{1}{N} \log_2\Bigl(\frac{1}{P(\vec{x})}\Bigr) = \frac{1}{N}\sum_{n=1}^{N} \log_2\Bigl(\frac{1}{P(x_n)}\Bigr) = \bar{h}_{x_n}
\text{E vamos chamar de $\sigma^2_{h}$ a variância desta variável aleatória.}
4. Sequências Típicas
Princípios e Técnicas de EEG
Aula 07
\text{Se $u$ é a média entre $N$ variáveis independentes $h_n$, $n=1...N$, cada uma com valor esperado $H$}
\text{Vamos precisar do seguinte resultado clássico de estatística, a Lei dos grandes números:}
\text{e variância $\sigma^2$, então:}
P\bigr((u-H)^2 \geq \alpha\bigl)\leq \frac{\sigma^2 }{\alpha N}
\text{Essa lei dos grandes números implica para a nossa variável $u_{\vec{x}}$ que:}
\text{Ou, de forma complementar:}
\text{Ou seja, para qualquer $\alpha$ e $\sigma^2$, $u$ se aproxima do valor esperado $H$ quando $N$ cresce}
P\Bigl( \Bigl|\frac{1}{N} \log_2\Bigl(\frac{1}{P(\vec{x})}\Bigr)-H(X)\Bigr|^2\geq \alpha \Bigr)\leq \frac{\sigma_h^2}{\alpha N}
P\Bigl( \Bigl|\frac{1}{N} \log_2\Bigl(\frac{1}{P(\vec{x})}\Bigr)-H(X)\Bigr|^2 <\alpha \Bigr)\geq 1- \frac{\sigma_h^2}{\alpha N}
4. Sequências Típicas
Princípios e Técnicas de EEG
Aula 07
\text{Fazendo $\alpha=\beta^2$, reconhecemos que pela definição de sequência típica pertencente a $T_{N\beta}$:}
P\Bigl( \vec{x}\in T_{N\beta}\Bigr)\geq 1- \frac{\sigma_h^2}{\beta^2 N}
\text{Ou seja, se $N$ for grande, a probabilidade de uma string $\vec{x}$ ser típica tende a 1.}
\text{Quantos elementos possui o conjunto de sequências típicas $T_{N\beta}$?}
\text{Praticamente todas as sequências de $X^N$ estão em $T_{N\beta}$ quando $N$ cresce: podemos comprimir $X^N$ }
\text{para $T_{N\beta}$ sem perder nada significativo! Isso nos leva à pergunta chave para encontrarmos a medida}
Continua na próxima aula...
\text{de informação associada a X:}
4. Sequências Típicas
PRINCÍPIOS E TÉCNICAS DE ELETROENCEFALOGRAFIA EM NEUROCIÊNCIA
Próximas Aulas:
AULA 08 - Pré-processamento do EEG (parte I)
AULA 09 (Tópicos Avançados) - O Teorema de Shannon - parte II
Instituto de Ciência e Tecnologia
Graduação em Engenharia Biomédica
Prof. Dr. Adenauer G. Casali
Laboratório de Neuroengenharia e Computação
casali@unifesp.br
Tópicos Avançados - Aula 07 - Teoria da Informação: O Teorema de Shannon (parte I)
By ADENAUER GIRARDI CASALI



