PRINCÍPIOS E TÉCNICAS DE ELETROENCEFALOGRAFIA EM NEUROCIÊNCIA
AULA 12 - Como estimar entropia na prática?
Instituto de Ciência e Tecnologia
Graduação em Engenharia Biomédica
Prof. Dr. Adenauer G. Casali
Laboratório de Neuroengenharia e Computação
casali@unifesp.br



PRINCÍPIOS E TÉCNICAS DE EEG EM NEUROCIÊNCIA
Como estimar entropia e informação na prática?
1. binning,
2. kDE (e dilema viés x variância)
3. k-NN
4. GCMI
Adenauer G. CASALI
AULA 12
Nesta aula, nós veremos...

1. Como estimar H e MI na prática?
Princípios e Técnicas de EEG
Aula 12
H(X) = \sum_{i}p(x_i)\log_2(\frac{1}{p(x_i)})
\text{1. O que é $x_i$?}
?
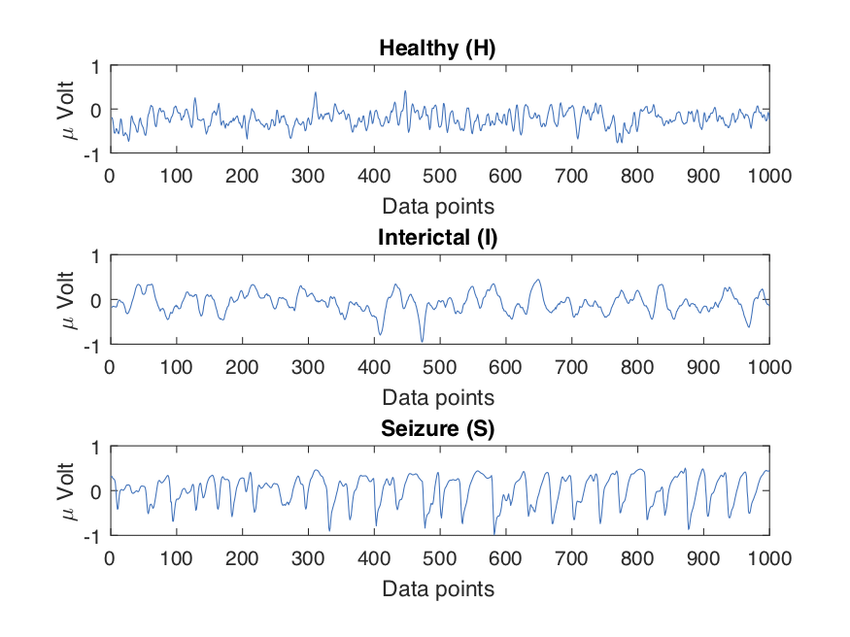
\text{i) Amplitude do EEG no tempo: $x_i= V(t_i)$}
\text{ii) Potência espectral na frequência: $x_i = P(f_i)$}
\text{iii) Fase na frequência: $x_i = \Theta(f_i)$}
\text{iv) Fase instantâne no tempo: $x_i = \Theta(t_i)$}
\text{2. Como encontrar $P(x_i)$?}
\text{i) Histogramas ({\it binning})}
\text{ii) Kernel Density Estimation (KDE)}
\text{iii) Vizinhos mais próximos (k-NN)}
\text{iv) Gaussian Copula MI (GCMI)}
\text{2. Como encontrar $P(x_i)$?}
\text{i) Histogramas ({\it binning})}
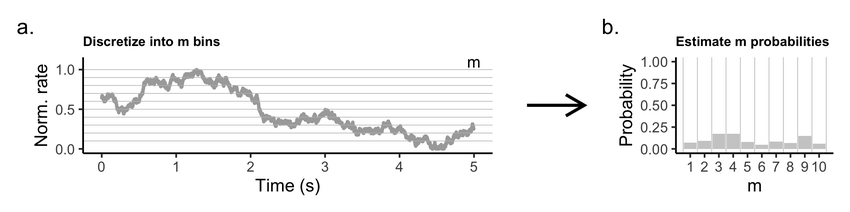
Fonte: Peterson and Voytek (2021)
\text{- Dividir eixo em um número fixo de bins}
\text{- Usar uma largura fixa dos bins (número variável)}
\text{Como definis os {\it bins}?}
\text{- Estratégias automáticas (Sturges, Freedman-Diaconis, etc...)}
\text{{\it Bins} representam regiões do espaço de estados}
\text{ Frequência de ocupação das regiões determinam as probabilidades}
\text{ PREMISSA: Estacionariedade!}
1.Histogramas
Princípios e Técnicas de EEG
Aula 12
\text{2. Como encontrar $P(x_i)$?}
\text{i) Histogramas ({\it binning})}
\text{Simples e Fácil de implementar}
\text{Intuitivo}
\text{Baixo Custo Computacional}
\text{Referência para métodos mais complicados}
\text{Depende da escolha dos bins!}
\text{Viés sistemático: enropia subestimada}
\text{Muito sensível ao tamanho da época}
\text{Problema da escala}
\text{pouco: perde informação}
\text{muito: mede ruído}
\text{Viés x Variância!}
\text{correção: Miller-Madow}
\text{bins vazios: distorções na entropia}
\text{mudar a unidade do EEG altera a entropia!}
Que tal estimar a entropia sem discretizar?
\text{Problema da dimensionalidade}
\text{$k$ bins: $N/k^d$ pontos por {\it bin}! }
Princípios e Técnicas de EEG
Aula 12
1.Histogramas
\text{2. Como encontrar $P(x_i)$?}
\text{ii) Kernel Density Estimation (KDE)}
\text{Ao invés de discretizar, suavizar!}
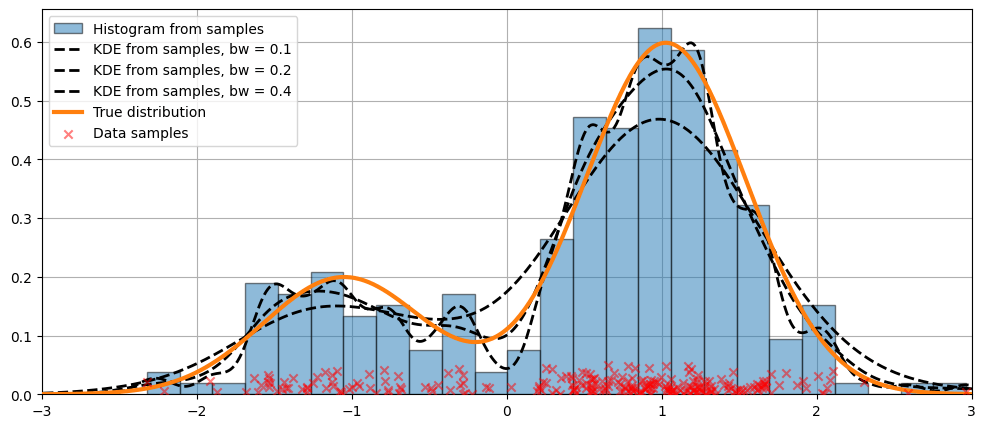
Fonte: statsmodel
\text{- Cada amostra $x_i$ {\it espalha} uma probabilidade $\hat{p}_i(x)$ ao seu redor:}
\hat{p}_i(x) = \frac{1}{h} K\Bigl(\frac{x-x_i}{h}\Bigr)
\text{$K(u)$: Kernel}
K(u) = K(-u)
\int_{-\infty}^{\infty}K(u)du = 1
\frac{d}{du}K(u) <0 \text{ quando $u>0$}
\int_{-\infty}^{\infty} uK(u)du = 0
\text{- Probabilidade em um ponto $\hat{p}(x)$ é a média de $\hat{p}_i(x)$}
\text{$h$: largura de banda ({\it bandwidth})}
\hat{p}(x) = \frac{1}{N} \sum_{i=1}^{N}\hat{p}_i(x)
\text{Gaussiano:}
K(u) = \frac{e^{-u^2}}{\sqrt{2\pi}}
Princípios e Técnicas de EEG
Aula 12
2.KDE
\text{2. Como encontrar $P(x_i)$?}
\text{Estimativa contínua}
\text{Mais fiel aos dados}
\text{Em geral melhor que histogramas}
\text{Intuição geométrica local}
\text{Depende da escolha de $h$!}
\text{Custo computacional}
\text{Viés das bordas}
\text{Problema da escala}
\text{grande: perde informação}
\text{pequeno: mede ruído}
\text{Viés x Variância!}
\text{vai com $\sim N^2$}
\text{subestima a densidade nos limites}
\text{requer normalização (z-score)}
\text{ii) Kernel Density Estimation (KDE)}
\text{Problema da dimensionalidade}
\text{erro $\sim N^{-4/(4+d)}$}
Princípios e Técnicas de EEG
Aula 12
2.KDE
\text{Calculando o erro na estima de $p(x)$}
\text{{\it Mean Integrated Square Error (MISE)}:}
MISE= \mathbb{E}\Bigl[\int(\hat{p}(x) - p(x))^2 dx\Bigr]
\hat{p}(x)- p(x)
= \bigl(\hat{p}(x)-\mathbb{E}[\hat{p}(x)]\bigr) + \bigl(\mathbb{E}[\hat{p}(x)]- p(x)\bigr)
\text{Viés$(x)$: erro em assumir que $\hat{p}$ representa, na média, $p$}
(\hat{p}(x)- p(x))^2
= \bigl(\hat{p}(x)-\mathbb{E}[\hat{p}(x)]\bigr)^2 + 2\bigl(\hat{p}(x)-\mathbb{E}[\hat{p}(x)]\bigr)\text{Viés}(x)+ \bigl(\text{Viés}(x)\bigr)^2
\mathbb{E}[(\hat{p}(x)- p(x))^2]
= \mathbb{E}\bigl[\bigl(\hat{p}(x)-\mathbb{E}[\hat{p}(x)]\bigr)^2\bigr] + 2\mathbb{E}\bigl[\bigl(\hat{p}(x)-\mathbb{E}[\hat{p}(x)]\bigr)\bigr]\text{Viés}(x)+ \bigl(\text{Viés}(x)\bigr)^2
\text{Valor esperado em relação às amostras}
\text{0}
\mathbb{E}[(\hat{p}(x)- p(x))^2]
= \mathbb{E}\bigl[\bigl(\hat{p}(x)-\mathbb{E}[\hat{p}(x)]\bigr)^2\bigr] + \bigl(\text{Viés}(x)\bigr)^2
\text{Variância$(x)$: quanto em média $\hat{p}(x)$ flutua em torno da sua própria média}
Princípios e Técnicas de EEG
Aula 12
2.KDE
\text{Calculando o erro na estima de $p(x)$}
MISE= \int \Bigl[\text{Variância}(x) + \text{Viés}^2(x)\Bigr]dx
\text{Cálculo do viés}:
\text{Viés}(x)= \mathbb{E}[\hat{p}(x)]- p(x)
\hat{p}(x) = \frac{1}{Nh} \sum_{i=1}^{N} K\Bigl(\frac{x-x_i}{h}\Bigr)
\mathbb{E}[\hat{p}(x)] = \frac{1}{Nh} \sum_{i=1}^{N} \mathbb{E}\Bigl[ K\Bigl(\frac{x-x_i}{h}\Bigr)\Bigr]
\mathbb{E}[\hat{p}(x)] = \int K(z) p(x-hz) dz
p(x-hz) = p(x) - hzp'(x) + \frac{h^2 z^2}{2}p''(x) +...
z=\frac{x-u}{h}
= \frac{1}{Nh} N \mathbb{E}\Bigl[ K\Bigl(\frac{x-u}{h}\Bigr)\Bigr]
= \frac{1}{h} \int K\Bigl(\frac{x-u}{h}\Bigr)p(u)du
\text{Toda as amostras $i$ vêm do mesmo processo, $p(x_i)=p(u)$, com mesma esperança}
\text{$hz$ é pequeno para valores de $z$ relevantes ($z$ grande tem probabilidade muito baixa)}
\text{VALE EM GERAL!}
Princípios e Técnicas de EEG
Aula 12
2.KDE
\text{Calculando o erro na estima de $p(x)$}
\mathbb{E}[\hat{p}(x)] = \int K(z) p(x-hz) dz
p(x-hz) = p(x) - hzp'(x) + \frac{h^2 z^2}{2}p''(x) +...
\mathbb{E}[\hat{p}(x)] = \int K(z) p(x) dz - \int hzK(z) p'(x) dz + \int \frac{h^2z^2}{2}K(z) p''(x) dz + ...
= p(x) \int K(z) dz - hp'(x)\int zK(z) dz + \frac{h^2}{2}p''(x)\int z^2 K(z) dz + ...
= p(x) + \frac{h^2}{2}p''(x)\int z^2 K(z) dz + ...
\text{Viés}(x)= \mathbb{E}[\hat{p}(x)]- p(x) \sim h^2 \frac{p''(x)}{2}\int z^2 K(z) dz
1
0
Princípios e Técnicas de EEG
Aula 12
2.KDE
\text{Calculando o erro na estima de $p(x)$}
MISE= \int \Bigl[\text{Variância}(x) + \text{Viés}^2(x)\Bigr]dx
\text{Cálculo da variância}:
\hat{p}(x) = \frac{1}{Nh} \sum_{i=1}^{N} K\Bigl(\frac{x-x_i}{h}\Bigr) = \frac{1}{N}\sum_{i=1}^{N}\hat{p}_i(x)
\text{Variância}(x)= \mathbb{E}\bigl[\bigl(\hat{p}(x)-\mathbb{E}[\hat{p}(x)]\bigr)^2\bigr]
= \text{Var}\Bigl[\hat{p}(x)\Bigr]
\text{Var}[\hat{p}_u(x)] = \mathbb{E}[\hat{p}_u^2(x)] -\mathbb{E}[\hat{p}_u(x)]^2
= \frac{1}{N^2}\sum_{i-1}^{N}\text{Var}\Bigl[\hat{p}_i(x)\Bigr]
\text{Os $x_i$ são independentes e identicamente distribuídos, $p(x_i)=p(u)$}
= \frac{1}{N}\text{Var}\Bigl[\hat{p}_u(x)\Bigr]
\text{Variância}(x)= \frac{1}{N}\mathbb{E}[\hat{p}_u^2(x)] -\frac{1}{N}\mathbb{E}[\hat{p}_u(x)]^2
Princípios e Técnicas de EEG
Aula 12
2.KDE
\text{Calculando o erro na estima de $p(x)$}
= \frac{1}{h^2} \int K\Bigl(\frac{x-u}{h}\Bigr)^2 p(u)du
\text{Variância}(x)= \frac{1}{N}\mathbb{E}[\hat{p}_u^2(x)] -\frac{1}{N}\mathbb{E}[\hat{p}_u(x)]^2
\mathbb{E}[\hat{p}_u(x)]^2 \sim p^2(x) +...
\mathbb{E}[\hat{p}_u^2(x)]
= \frac{1}{h} \int K^2(z) p(x-hz)dz
p(x-hz) = p(x) - hzp'(x) + \frac{h^2 z^2}{2}p''(x) +...
= \frac{p(x)}{h} \int K^2(z) dz + ...
\mathbb{E}[\hat{p}_u(x)] = p(x) + \frac{h^2}{2}p''(x)\int z^2 K(z) dz + ...
\text{Variância}(x)=\frac{1}{Nh}p(x)\int K^2(z)dz - \frac{1}{N}p^2(x) + ...
\text{Variância}(x) \sim \frac{1}{Nh}p(x)\int K^2(z)dz
Princípios e Técnicas de EEG
Aula 12
2.KDE
\text{Calculando o erro na estima de $p(x)$}
\text{Variância}(x)\sim \frac{1}{Nh}p(x)\int K^2(z)dz
MISE \sim \frac{1}{Nh} + h^4
\text{$h$ grande: erra por muito viés}
\text{$h$ pequeno: erra por muita variância}
\text{$N$ pequeno: erra por muita variância}
MISE= \int \Bigl[\text{Variância}(x) + \text{Viés}^2(x)\Bigr]dx
\text{Viés}(x) \sim h^2 \frac{p''(x)}{2}\int z^2 K(z) dz
Princípios e Técnicas de EEG
Aula 12
2.KDE
\text{2. Como encontrar $P(x_i)$?}
\text{ii) Kernel Density Estimation (KDE)}
\text{Problema da dimensionalidade: {\it the Curse of Dimensionality}}
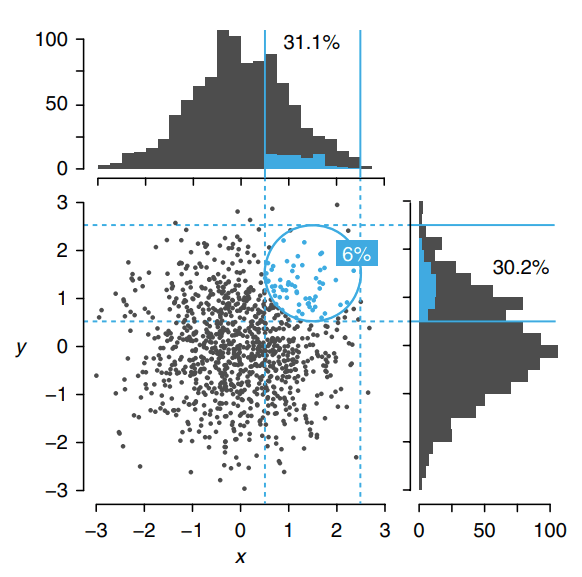
Fonte: Altman and Krzywinski (2018)
\text{Em $d$ dimensões, um $h$ cobre o volume $h^d$}
\text{Mesmo $h$ cobre um volume muito maior: densidade de pontos cai!}
\text{Menor densidade, maior variância!}
MISE \sim h^4 + \frac{1}{Nh^d}
MISE'(h_{opt}) \sim 4h_{opt}^3 -\frac{d}{N}h_{opt}^{-d-1} =0
\frac{4N}{d} = h_{opt}^{-d-4}
h_{opt}\sim N^{-1/(d+4)}
MISE_{opt} \sim N^{-4/(d+4)} + N^{-1}N^{d/(d+4)}
\sim N^{-4/(d+4)} + N^{-4/(d+4)}
\sim \Bigl(\frac{1}{N}\Bigr)^{4/(d+4)}
\text{$d$ dimensões:}
Princípios e Técnicas de EEG
Aula 12
2.KDE
\text{2. Como encontrar $P(x_i)$?}
\text{ii) Kernel Density Estimation (KDE)}
\text{Problema da dimensionalidade: {\it the Curse of Dimensionality}}
MISE \sim h^4 + \frac{1}{Nh^d}
\sim \Bigl(\frac{1}{N}\Bigr)^{4/(d+4)}
\text{Informação mútua entre dois canais: $d=2$}
\text{Análise tempo-frequência (t,f,c): $d=3$}
\text{Decoding: muitos canais em muitos tempos }
\text{Transfer Entropy: $d\geq 3$}
\text{Conectividade multivariada }
Que tal estimar a entropia sem estimar diretamente a densidade de probabilidade?
Princípios e Técnicas de EEG
Aula 12
2.KDE
\text{2. Como encontrar $P(x_i)$?}
\text{Método de Kraskov, Stogbauer e Grassberger: usar uma estatística local adaptativa!}
\text{O inverso da distância entre vizinhos pode servir de {\it surrogado} da probabilidade}
\text{iii) Vizinhos mais próximos (k-NN)}
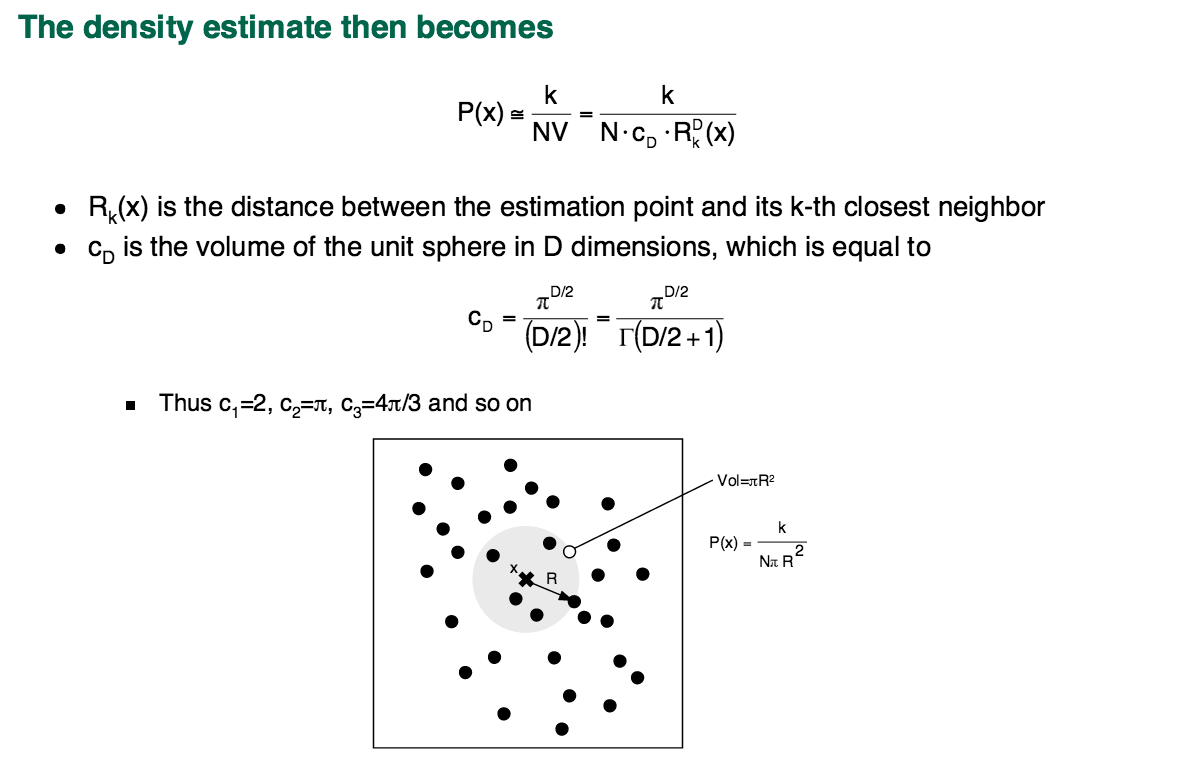
Princípios e Técnicas de EEG
Aula 12
3. k-NN
\text{2. Como encontrar $P(x_i)$?}
\text{Para cada ponto $x$ em $d$ dimensões: considere $\epsilon$ a distância até o k-ésimo vizinho e use}
\text{(KDE: raio fixo $h$)}
\hat{p}(x) = \frac{k}{N\epsilon ^{d}}
\text{Número fixo de vizinhos}
\text{iii) Vizinhos mais próximos (k-NN)}
\text{adapta-se localmente!}
\text{(KDE: sofre mais com esparsidade)}
\text{Em alta dimensão, KDE tem muitos espaços vazios}
\text{k-NN: ajusta o volume para garantir sempre $k$ pontos!}
Princípios e Técnicas de EEG
Aula 12
3. k-NN
\text{2. Como encontrar $P(x_i)$?}
\text{Adaptação local}
\text{Evita escolha de largura de banda global}
\text{Reduz esparsidade artificial}
\text{Melhor comportamento em $d$ moderado}
\text{Depende da escolha de $k$!}
\text{Custo computacional}
\text{Assimetria nas bordas}
\text{Problema da escala}
\text{grande: perde informação}
\text{pequeno: mede ruído}
\text{Viés x Variância!}
\text{vai com $\sim N\log N$}
\text{ vizinhos todos para um lado}
\text{ainda requer normalização (z-score)}
\text{Problema da dimensionalidade}
\text{erro $\sim \frac{k^d}{N}+\frac{1}{k^2} \sim N^{-2/(2+d)}$}
\text{iii) Vizinhos mais próximos (k-NN)}
Que tal eliminar a escala antes de tudo?
Princípios e Técnicas de EEG
Aula 12
3. k-NN
\text{2. Como encontrar $P(x_i)$?}
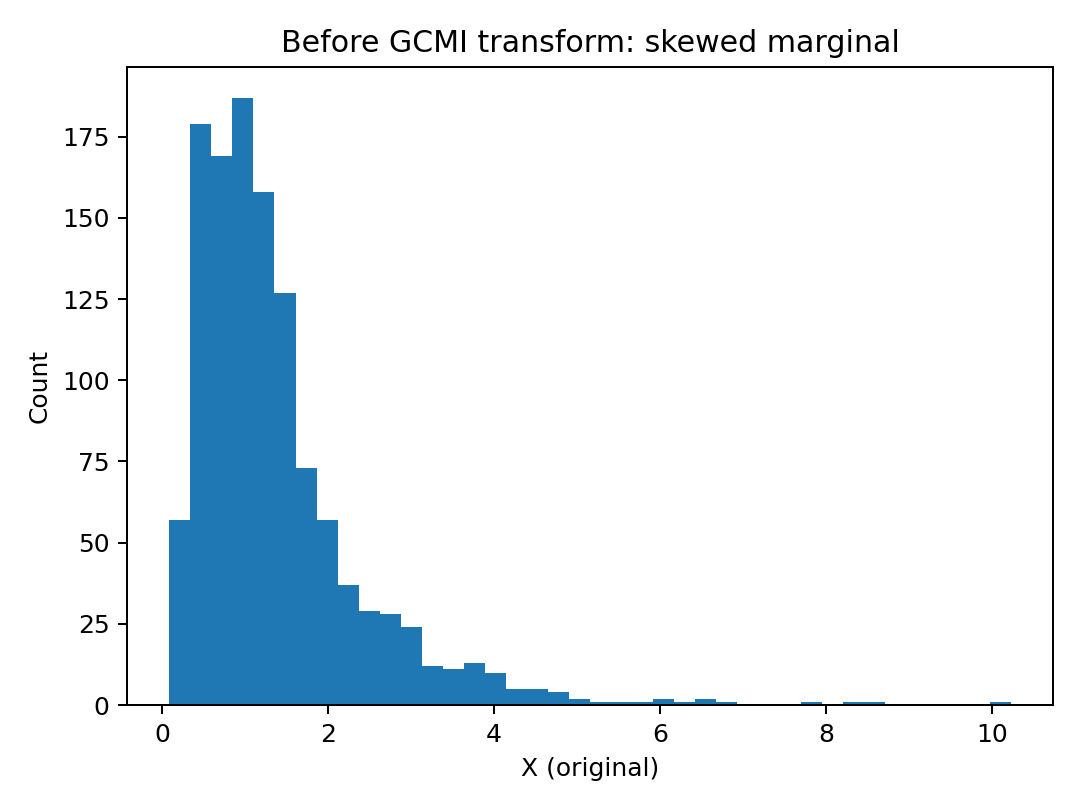
\text{iv) Gaussian Copula MI (GCMI)}
\text{Pensado especificamente para EEG/MEG}
\text{a) Passar valores $x_i$ para {\it ranks} ($r_i$)}
\text{b) Normalizar entre $0$ e $1$: $u_i = \frac{r_i}{N+1}$}
\text{c)Transformar em uma variável $z$ com distribuição normal:}
\text{A variável $u$ tem distribuição próxima de uniforme}
\text{Dado um percentil $u \in (0,1)$, qual o valor $z$ de uma gaussiana $\mathcal{N}(0,1)$ com este percentil? }
\text{Todas as variáveis ficam na mesma escala probabilística!}
\text{Transformação monotônica: preserva as dependências!}
Princípios e Técnicas de EEG
Aula 12
4. GCMI
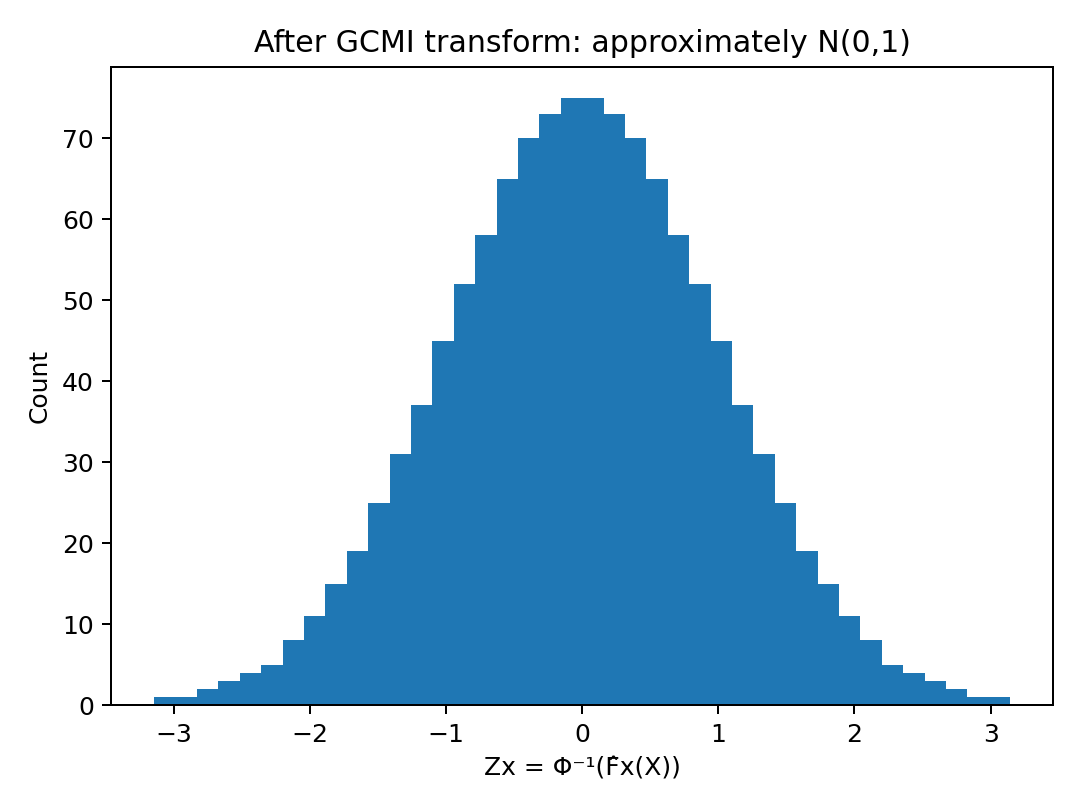
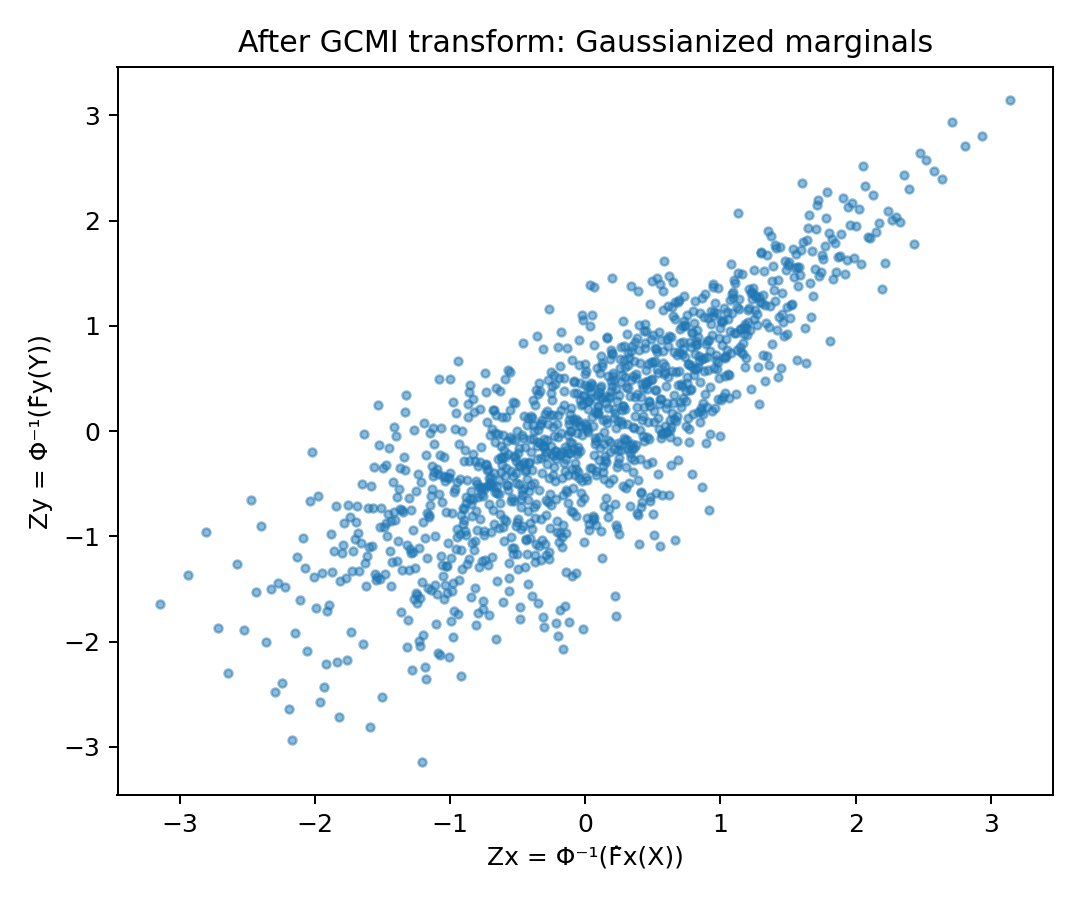
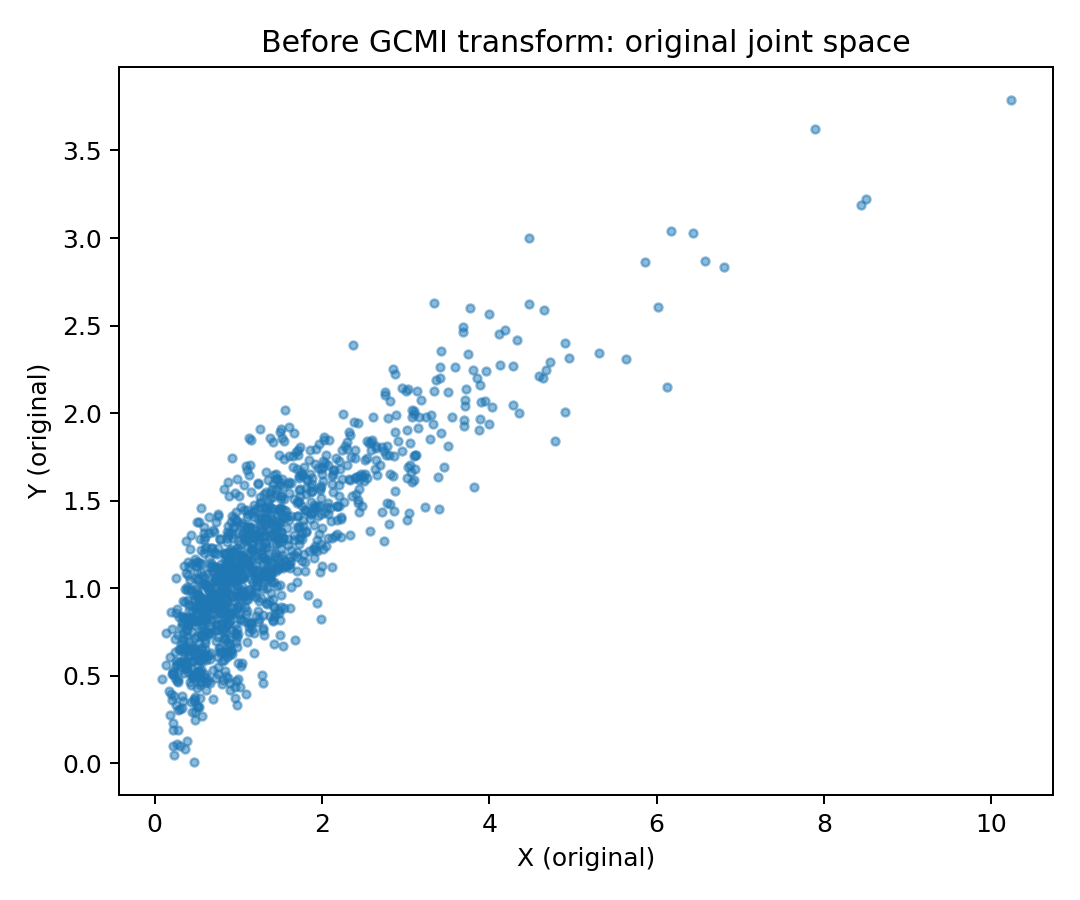
x\rightarrow z_x
y\rightarrow z_y
P(x,y)\rightarrow \mathcal{N}(z_x, z_y)
Princípios e Técnicas de EEG
Aula 12
4. GCMI
\text{2. Como encontrar $P(x_i)$?}
\text{iv) Gaussian Copula MI (GCMI)}
\mathcal{N}(\vec{z}|\Sigma) = \frac{1}{\sqrt{(2\pi)^d |\Sigma|}}\exp\Bigl(-\frac{1}{2}\vec{z}^{T}\Sigma^{-1}\vec{z}\Bigr)
\vec{x}\rightarrow \vec{z}
\Sigma=\begin{pmatrix}
1 & \Sigma_{1,2} & \cdots & \Sigma_{1,L} \\
\Sigma_{2,1} & 1 & \cdots & \Sigma_{2,L} \\
\vdots & \vdots & \ddots & \vdots \\
\Sigma_{L,1} & \Sigma_{L,2} & \cdots & 1
\end{pmatrix}
\text{Tudo codificado nas covariâncias!}
H(\vec{z}) = -\sum_{\vec{z}}p(\vec{z})\log_2 p(\vec{z}) = -\log_2 e \times \sum_{\vec{z}}p(\vec{z})\ln p(\vec{z})
= \log_2 e\times\Bigl(\frac{1}{2}\log_2 \bigl((2\pi)^d |\Sigma|\bigr) + \frac{1}{2}d \Bigr)
\text{Exemplo:}
Princípios e Técnicas de EEG
Aula 12
4. GCMI
\text{2. Como encontrar $P(x_i)$?}
\text{Resolve o problema da escala}
\text{Evita estimar densidade}
\text{Mais estável para poucos dados (covariância)}
\text{Robusto a outliers (ranks)}
\text{Assume dependência gaussiana na cópula}
\text{Não é estimador universal (como k-NN)}
\text{Perde informação da amplitude absoluta}
\text{Pode falhar em distribuição discreta}
\text{dependência linear no espaço transformado}
\text{se altamente não-linear: perde a dependência }
\text{paramétrico e empírico}
\text{ só usa ordem relativa}
\text{empate de ranks em dados categóricos}
\text{Colapsa em altíssima dimensão}
\text{quando $N \sim d$}
\text{iv) Gaussian Copula MI (GCMI)}
\text{Custo computacional $\sim N$}
Princípios e Técnicas de EEG
Aula 12
4. GCMI
Na próxima aula...
Entropia de Gibbs
Entropia de Boltzmann
Entropia de Shannon
Entropia Aproximada
Entropia de Perturbação
Entropia Multiescala
Entropia Espectral
Entropia de Tsalis
Entropia de Von Neumann
Entropia de Transferência
Entropia de Kolmogorov-Sinai
Entropia de Réniy
Entropia de Bekenstein
Entropia de Hawking
Entropia Conjunta
Entropia Condicional
Entropia Algorítmica
Entropia Fuzzy
Princípios e Técnicas de EEG
Aula 12
PRINCÍPIOS E TÉCNICAS DE ELETROENCEFALOGRAFIA EM NEUROCIÊNCIA
Próximas Aulas:
AULA 13 (Tópicos Avançados) - As muitas entropias do EEG
AULA 14 - Ritmos do EEG
Instituto de Ciência e Tecnologia
Graduação em Engenharia Biomédica
Prof. Dr. Adenauer G. Casali
Laboratório de Neuroengenharia e Computação
casali@unifesp.br
Tópicos Avançados - Aula 12 - Como estimar entropia na prática
By ADENAUER GIRARDI CASALI



