PRINCÍPIOS E TÉCNICAS DE ELETROENCEFALOGRAFIA EM NEUROCIÊNCIA
AULA 13 - As Muitas Entropias do EEG
Instituto de Ciência e Tecnologia
Graduação em Engenharia Biomédica
Prof. Dr. Adenauer G. Casali
Laboratório de Neuroengenharia e Computação
casali@unifesp.br



PRINCÍPIOS E TÉCNICAS DE EEG EM NEUROCIÊNCIA
As muitas entropias do EEG:
1. Entropia na biologia e física,
2. Entropia e incerteza,
3. Princípio de Landauer,
4. Entropia de Kolmogovor-Sinai,
5. Approximate entropy/sample entropy,
6. Multiscale entropy,
7. Permutation entropy,
8. Spectral entropy.
Adenauer G. CASALI
AULA 13
Nesta aula, nós veremos...

As muitas entropias
Entropia de Gibbs
Entropia de Boltzmann
Entropia de Shannon
Entropia Aproximada
Entropia de Perturbação
Entropia Multiescala
Entropia Espectral
Entropia de Tsalis
Entropia de Von Neumann
Entropia de Transferência
Entropia de Kolmogorov-Sinai
Entropia de Réniy
Entropia de Bekenstein
Entropia de Hawking
Entropia Conjunta
Entropia Condicional
Entropia Algorítmica
Entropia Fuzzy
Princípios e Técnicas de EEG
Aula 13
Escalas da vida: macro-estável, micro-estocástico!
"Microstates": estocástico
"Macrostate": estável
Homeostase: processo de auto-regulação que estabilizam você em microestados que resultam em você ser você!
Fenótipo: repertório de estados nos quais um organismo pode existir
Micro x Macro: ENTROPIA
1. Entropia na Física
Princípios e Técnicas de EEG
Aula 13
Mecânica estatística

Microscópico
Macroscópico
(energia cinética, posição, velocidade, etc...)
(Energia Interna, Volume, Temperatura, Pressão, etc...)
Entropia de um Sistema em um dado Macroestado
Número de microestados que resultam no mesmo macroestado
1. Entropia na Física
Princípios e Técnicas de EEG
Aula 13
Exemplo: 4 moléculas em duas câmaras
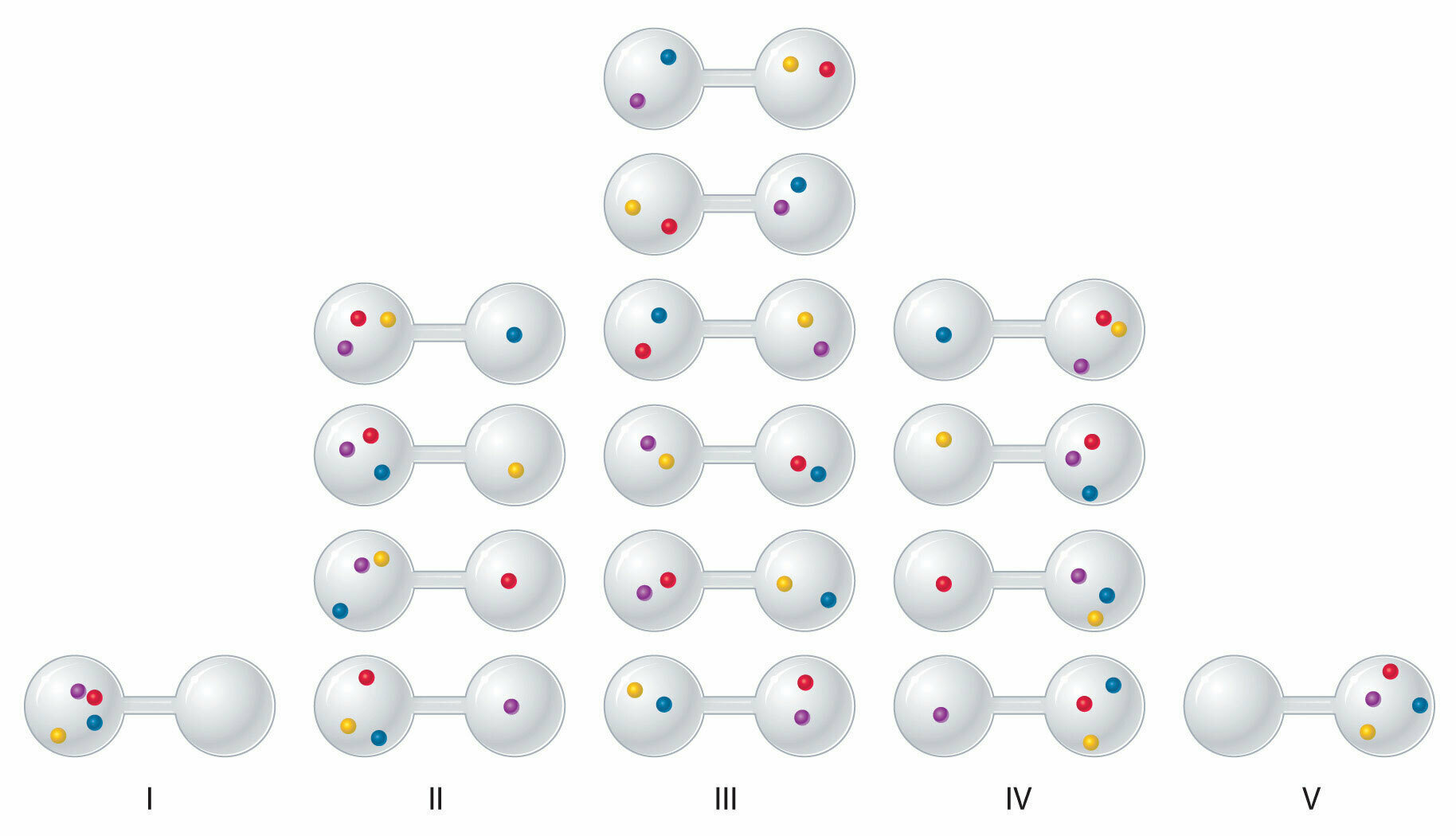
N= 1 + 4 + 6 + 4 + 1=16
\frac{4!}{4!0!}=1
\frac{4!}{3!1!}=4
\frac{4!}{2!2!}=6
\frac{4!}{1!3!}=4
\frac{4!}{0!4!}=1
p_I=p_{V}=\frac{\Omega_I}{\Omega}=\frac{1}{16}
p_{II}=p_{IV}=\frac{\Omega_{II}}{\Omega}=\frac{4}{16}
p_{III}=\frac{\Omega_{III}}{\Omega}=\frac{6}{16}
Quantas configurações?
"Macroestados"
Probabilidades das configurações:
\Omega_i
= número de microestados
1. Entropia na Física
Princípios e Técnicas de EEG
Aula 13
Entropia de um macroestado: medida do número de possíveis microestados naquela configuração (em escala logarítmica)
S = k_B\ln \Omega
Boltzmann:
p_i\text{ = probabilidade de um microestado $i$ em determinado macroestado}
\text{Entropia média do Macroestado: } \bar{S} =\sum_{i}p_iS_i = -k_B \sum_i p_i \ln p_i
\text{(microestados igualmente prováveis): }p_i = \frac{1}{\Omega_i}\rightarrow \ln \Omega_i = -\ln p_i
\text{Entropia do microestado: }S_i = -k_B \ln p_i
Generalização de Gibbs:
De uma perspectiva macroscópica, os sistemas evoluem em direção ao estado mais provável. E, se todos os microestados forem igualmente provávels, o macroestado mais provável é o que tem o maior número possível de microestados.
1. Entropia na Física
Princípios e Técnicas de EEG
Aula 13
I_x = \ln \frac{1}{p(X=x)}=-\ln p(X=x)
p(X=x)
probabilidade de um determinado X ter uma configuração específica x dentre todas as configurações possíveis
Probabilidade baixa = surpresa ao descobrir a configuração de X. Quanto maior a "surpresa" ao descobrir X, mais "informação" X contém.
H = \bar{I} = - \sum_x p(X=x) \ln p(X=x)
Entropia = informação média de X (medida de "surpresa")
Entropia em termos de informação: "redução de incerteza", "surpresa"
Informação da configuração x(em escala log):
2. Entropia e Incerteza
Princípios e Técnicas de EEG
Aula 13
E \geq k_BT \ln 2,
Para apagar um bit de informação em temperatura T é necessário gastar energia
Princípio de Landauer (1961)
o que corresponde a um aumento de entropia termodinâmica de
\Delta S \geq k_B \ln 2.
Perda de informação
precisa ser compensada por aumento de entropia física!!!
Informação não é algo abstrato: Informação é fisicamente corporificada em sistemas!
Bennett (1982): computação finita NÃO É REVERSÍVEL (porque precisa apagar memória!)
Teoria da Informação é parte da Física Fundamental Contemporânea
(ver por exemplo Parrondo et al., 2015)
3. Princípio de Landauer e Computação
Princípios e Técnicas de EEG
Aula 13
Mas em termos de EEG, calcular a entropia de Shannon é só o começo...
- Sample Entropy
- Approximate Entropy
- Multiscale Entropy
- Permutation Entropy
- Spectral Entropy
- Transfer Entropy
- ....
Aproximações operacionais da entropia de Shannon sob diferentes restrições
Definem diferentes estimadores de informação
(mas a ideia de fundo é sempre a mesma!)
As muitas entropias: Entropias do EEG
Princípios e Técnicas de EEG
Aula 13
Entropia de Kolmogorov-Sinai (KS)
H_{KS} = \lim_{m\rightarrow \infty} H(x_{t+m}|x_{t}, x_{t+1},...,x_{t+m-1})
\sim \text{incerteza do futuro {\bf dado} o passado}
\text{Lembre que: }H(X|Y) = H(X,Y)-H(Y)
H_{KS} = \lim_{m\rightarrow \infty} \Bigl[H(x_{t}, x_{t+1},...,x_{t+m-1},x_{t+m}) - H(x_{t}, x_{t+1},...,x_{t+m-1})\Bigr]
\text{séries muito longas: ``passado'' fica estável}
4. Entropia de Kolmogorov-Sinai
Princípios e Técnicas de EEG
Aula 13
\text{Regra da cadeia em probabilidades: }
P(x_1,x_2,...,x_L) = P(x_1|x_2,...,x_{L})P(x_2,...,x_{L})
P(x_2,...,x_L) = P(x_2|x_3,...,x_{L})P(x_3,...,x_{L})
P(x_3,...,x_L) = P(x_3|x_4,...,x_{L})P(x_4,...,x_{L})
P(x_1,x_2,...,x_L) = P(x_1|x_2,...,x_{L})P(x_2|x_3,...,x_{L})... P(x_{L-1}|x_{L})P(x_L)
"Chain rule" (regra da cadeia)
P(x_{L-1},x_L) = P(x_{L-1}|x_L)P(x_{L})
.\\
.\\
.
P(x_1,x_2,...,x_L) = \prod_{k=1}^{L} P(x_k|x_{k+1},...,x_{L})
4. Entropia de Kolmogorov-Sinai
Princípios e Técnicas de EEG
Aula 13
\text{Da mesma forma (sentido inverso): }
P(x_1,x_2,...,x_L) = P(x_L|x_1,...,x_{L-1})P(x_1,...,x_{L-1})
P(x_1,...,x_{L-1}) = P(x_{L-1}|x_1,...,x_{L-2})P(x_1,...,x_{L-2})
P(x_1,...,x_{L-2}) = P(x_{L-2}|x_1,...,x_{L-3})P(x_1,...,x_{L-3})
P(x_1,x_2,...,x_L) = P(x_L|x_1,...,x_{L-1})P(x_{L-1}|x_1,...,x_{L-2})... P(x_{2}|x_{1})P(x_1)
"Chain rule" (regra da cadeia)
P(x_{1},x_2) = P(x_{2}|x_1)P(x_{1})
.\\
.\\
.
P(x_1,x_2,...,x_L) = \prod_{k=1}^{L} P(x_{L-k+1}|x_{1},...,x_{L-k})
4. Entropia de Kolmogorov-Sinai
Princípios e Técnicas de EEG
Aula 13
\log_2(P(x_1,x_2,...,x_M)) = \log_2\Bigl(\prod_{k=1}^{m} P(x_{m-k+1}|x_{1},...,x_{m-k})\Bigr) = \sum_{k=1}^{m}\log_2 P(x_{m-k+1}|x_{1},...,x_{m-k})
H(x_1,x_2,...,x_m) = \sum_{k=1}^{m} H(x_{m-k+1}|x_{1},...,x_{m-k})
\text{Se $m$ for muito grande e {\bf o processo for estacionário}:}
H(x_1,x_2,...,x_m) \approx m H(x_m|x_1,...x_{m-1})
\approx \lim_{m\rightarrow \infty} \frac{1}{m}H(x_{t}, x_{t+1},...,x_{t+m})
H_{KS} = \lim_{m\rightarrow \infty} H(x_{t+m}|x_{t}, x_{t+1},...,x_{t+m-1})
\text{Numa série estacionária longa: KS mede a informação nova por símbolo}
Entropia de Kolmogorov-Sinai (KS)
\text{ENTROPY RATE!}
P(x_1,x_2,...,x_m) = \prod_{k=1}^{m} P(x_{m-k+1}|x_{1},...,x_{m-k})
"Chain rule" (regra da cadeia para entropias)
4. Entropia de Kolmogorov-Sinai
Princípios e Técnicas de EEG
Aula 13
\approx \lim_{m\rightarrow \infty} \frac{1}{m}H(x_{t}, x_{t+1},...,x_{t+m})
H_{KS} = \lim_{m\rightarrow \infty} H(x_{t+m}|x_{t}, x_{t+1},...,x_{t+m-1})
\text{Processo determinístico (ex: sinal periódico):}
Entropia de Kolmogorov-Sinai (KS)
H_{KS} = 0
\text{Processo aleatório (ex: ruído branco):}
H_{KS} = H(X)
\text{Sistema nem determinístico nem totalmente imprevisível (EEG):}
0 < H_{KS} < H(X)
4. Entropia de Kolmogorov-Sinai
Princípios e Técnicas de EEG
Aula 13
Approximate Entropy/Sample Entropy: estima de KS
Introduzida por Steven Pincus: PNAS (1991)
Refinada por Joshua Richman: American Journal of Physiology (2001)
\text{``padrão'' $i$: }\vec{v}_i=[x_i, x_{i+1},...,x_{i+m-1}]
\text{$m$: inteiro positivo}
d(\vec{v}_i,\vec{v_j})= \text{ distância entre dois padrões (tipicamente a máxima ou distância de Chebyshev:)}
C_{i}^{m}(r)=\text{número de $j$s que estão próximos dos $i$s de pelo menos $r$/ número total de padrões}
d(\vec{v}_i,\vec{v_j})< r
C_{i}^{m}(r)=\text{probabilidade de encontrar um padrão semelhante ao padrão $i$}
\text{$r$: real positivo}
d(\vec{v}_i,\vec{v_j})= \max_{k}|x_{i+k}-x_{j+k}|
5. Approximate Entropy/Sample Entropy
Princípios e Técnicas de EEG
Aula 13
Approximate Entropy
\approx \overline{\log_2(p)}
\Phi^{m}(r)=\frac{1}{N-m+1}\sum_{i=1}^{N-m+1}\log_2 C_i^m(r)
C_{i}^{m}(r)\sim \text{probabilidade $p_i$ de encontrar um padrão semelhante a ao padrão $i$}
\text{ApEn}(m,r)=\Phi^{m}(r)-\Phi^{m+1}(r)
\sim \text{positiva: aumentar o tamanho do padrão gera novidade}
\sim \text{negativa: aumentar o tamanho do padrão reforça semelhança}
\text{Estima da Taxa de Entropia no tempo!}
\text{ para $m\rightarrow \infty$, aproxima KS}
?

5. Approximate Entropy/Sample Entropy
Princípios e Técnicas de EEG
Aula 13
Approximate Entropy
\text{Problemas:}
\text{Dimensão finita $m$}
\text{Tolerância $r$}
\text{Para séries curtas pode ser muito enviesada}
\text{{\bf Sample Entropy}: contar {\bf pares} de padrões e não padrões individuais}
\text{$P_{m}(r)$ = número de pares de padrões semelhantes $(r)$ de tamanho $m$}
\text{SampEn}(m,r)=\log_2\bigl(P_{m}(r)\bigr) - \log_2\bigl(P_{m+1}(r)\bigr)
\text{SampEn}(m,r)=-\log_2\Bigl(\frac{P_{m+1}(r)}{P_{m}(r)}\Bigr) \approx -\log_2 \text{Prob(semelhante em $m+1$}|\text{semelhante em $m$)}
\text{Auto-matches}
Sample Entropy
\text{(log da média e não média do log)}
\text{(estima direta de probabilidade)}
5. Approximate Entropy/Sample Entropy
Princípios e Técnicas de EEG
Aula 13
Multiscale Entropy
Introduzida por Costa et al.: PRL (2002)
\text{``padrão'' $i$ com escala $\tau$: }y^{(\tau)}_i=\frac{1}{\tau}\sum_{k=(i-1)\tau +1}^{i\tau}x_k
\text{=média do sinal na escala $\tau$}
\text{MSE$(\tau)=$SampEn$(y^{(\tau)};m,r)$}
\text{$\tau$}
\text{analisar a curva em função da escala}
\text{Processo determinístico: baixa entropia em todas escalas}
\text{Processo aleatório: alta entropia que cai rapidamente com aumento da escala}
\text{EEG: entropia alta/moderada em diversas escalas}
6. Multiscale Entropy
Princípios e Técnicas de EEG
Aula 13
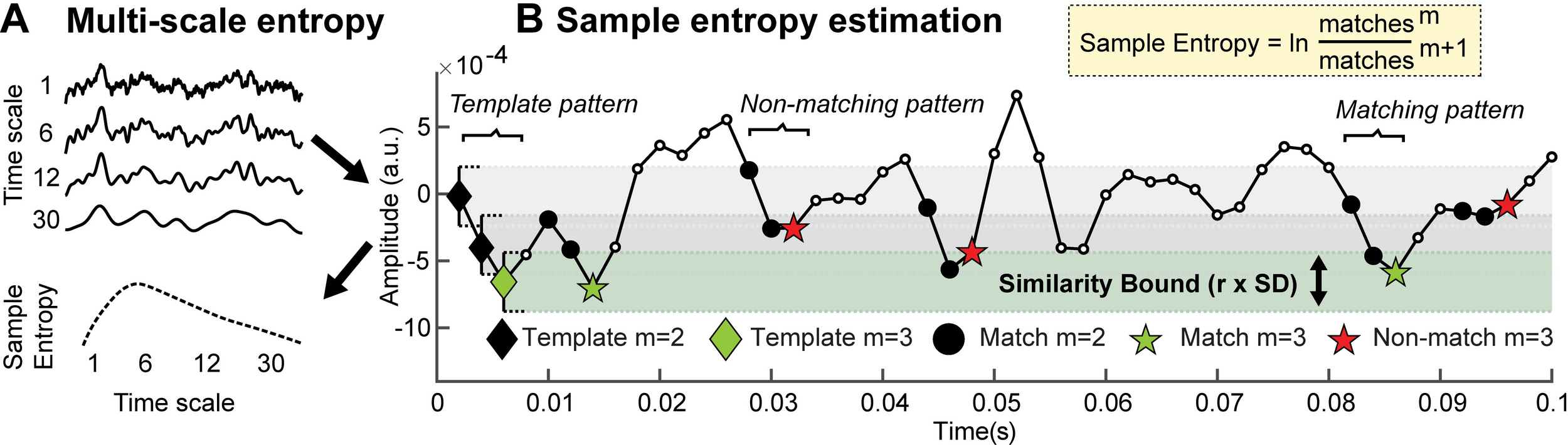
Fonte: Kosciessa et al., 2020
6. Multiscale Entropy
Princípios e Técnicas de EEG
Aula 13
\text{Problemas:}
\text{Dependência de parâmetros ($\tau$, $r$): interação entre parâmetros!}
Multiscale Entropy
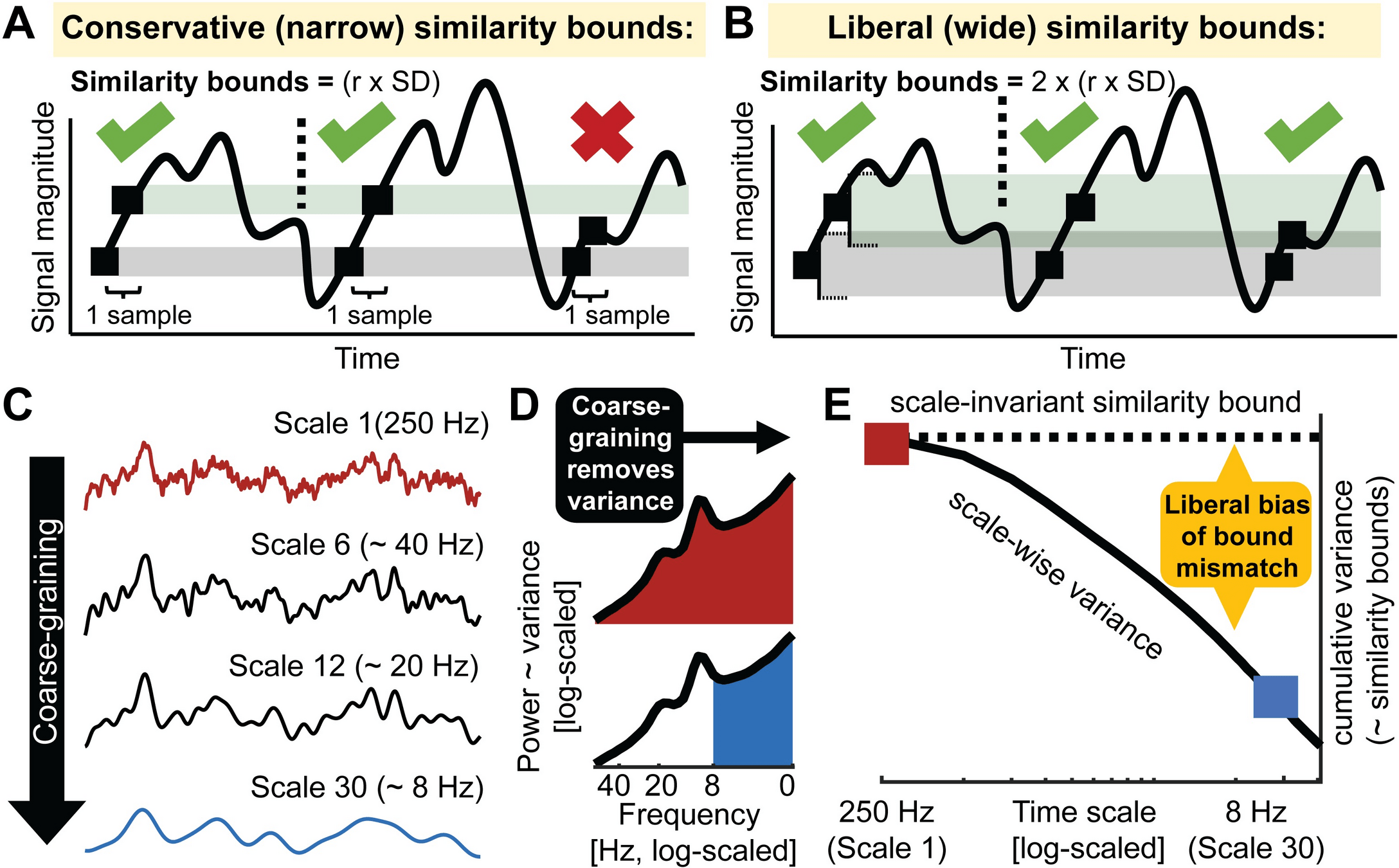
\text{escala maior produz redução de variância do sinal}
\text{mesmo $r$ introduz viés para baixa entropia}
\text{com escala maior!}
Fonte: Kosciessa et al., 2020
6. Multiscale Entropy
Princípios e Técnicas de EEG
Aula 13
\text{Problemas:}
\text{Dependência de parâmetros ($\tau$, $r$): interação entre parâmetros!}
\text{Redução do tamanho da série: tamanho efetivo = $N/\tau$ (instabilidade para $\tau$ grande)}
\text{Média na escala: filtro passa-baixa que pode destruir dinâmica relevante}
\text{$\tau$ captura viés x variância (pequeno: muito ruído, grande: pouca informação)}
Multiscale Entropy
\text{Qual o significado das diferentes escalas?}
6. Multiscale Entropy
Princípios e Técnicas de EEG
Aula 13
\text{Escala fina: alta frequência? Escala grosseira: baixa frequência?}
\text{Não!}
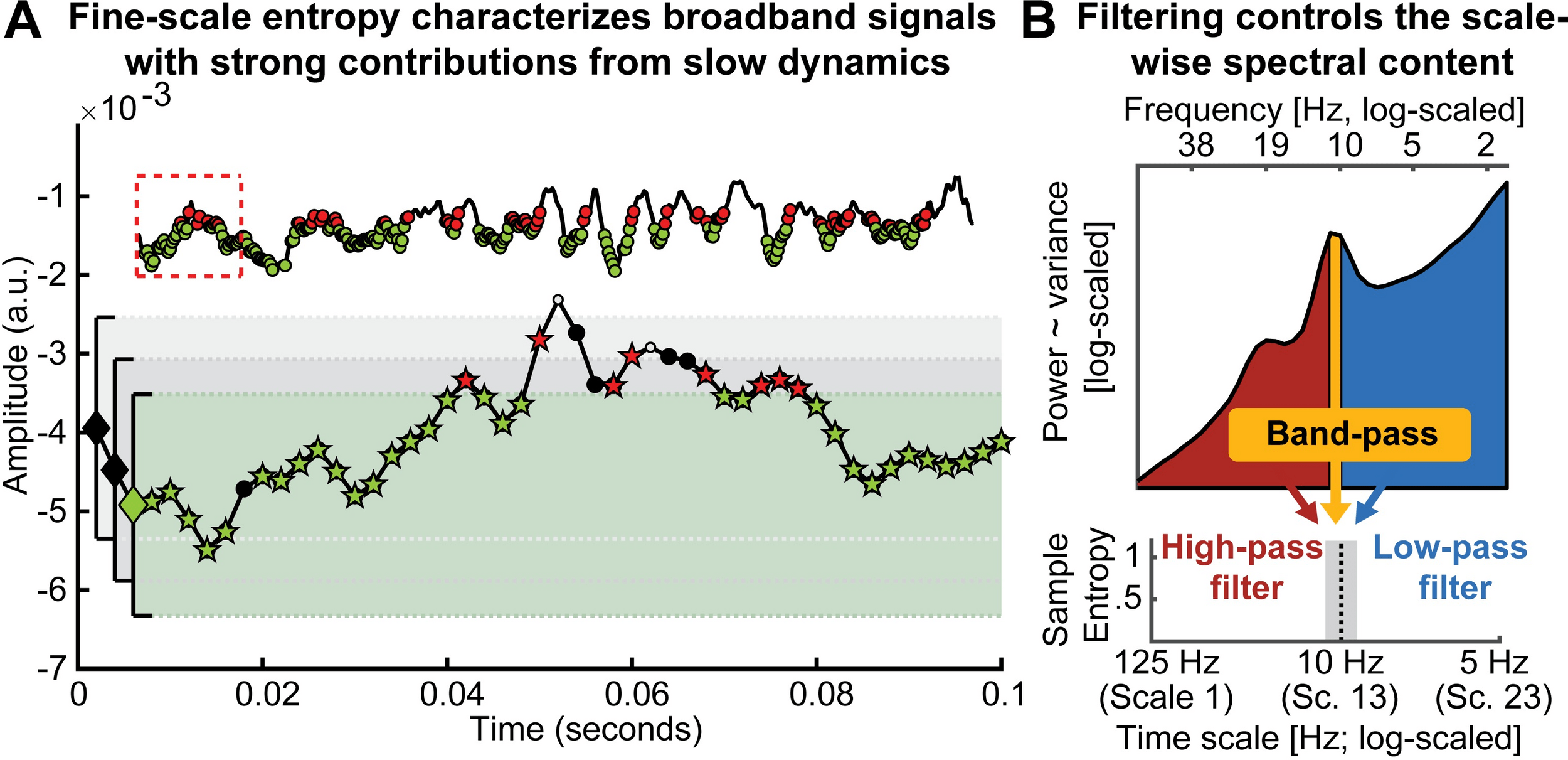
\text{Escala fina: efeitos broadband!}
\text{Escala grosseira: low-pass}
Fonte: Kosciessa et al., 2020
\text{Usar filtros passa-baixa e passa-alta}
\text{(pouca especificidade a altas frequências)}
6. Multiscale Entropy
Princípios e Técnicas de EEG
Aula 13
Permutation Entropy
Introduzida por Band and Pompe: PRL (2002)
\text{``padrão'' $i$ com atraso $\tau$: }\vec{v}_i=[x_i, x_{i+\tau},...,x_{i+(m-1)\tau}]
\text{Transformar em um padrão de ordenação ($\pi$): }{\pi}_i=[\text{rank}(x_i), \text{rank}(x_{i+\tau}),...,\text{rank}(x_{i+(m-1)\tau})]
\text{Estimar $p(\pi)$}
\text{Calcular a entropia de Shannon}
H = -\sum_{i}p(\pi_i)\log_2p(\pi_i)
7. Permutation Entropy
Princípios e Técnicas de EEG
Aula 13
Permutation Entropy
\vec{x}=[3.9, 4.6, 2.3, 2.9, 6.1, 2, 3.4, 3.7, 9, 2.5, 7.3, 4.2, 4.0, 4.3, 8.0, 7.1, 2.1]
\pi_1=[3, 4, 1, 2]
\text{Exemplo ($m=4$, $\tau=1$):}
H(\pi)=\text{diversidade dos padrões ordinais do sinal}
\{\pi\}=\{[1, 2, 3, 4],[1,2,4,3],[1,3,2,4],[1,3,4,2],[1,4,2,3],[1,4,3,2],
[2,1,3,4],[2,1,4,3],...\}
\pi_2=[3, 1, 2, 4]
\pi_3=[2, 1, 4, 3]
\pi_4=[2, 4, 1, 3]
7. Permutation Entropy
Princípios e Técnicas de EEG
Aula 13
Permutation Entropy
\text{Problemas:}
\text{Ignora a magnitude: estratégia simbólica (pode ser {\bf vantagem!})}
\text{Dependência em $m$}
\text{$m!$ padrões: problema para séries curtas}
\text{O que fazer com empates?}
\text{Dependência em $\tau$}
Há também versões "Multiscale" da Permutation Entropy!
7. Permutation Entropy
Princípios e Técnicas de EEG
Aula 13
Spectral Entropy
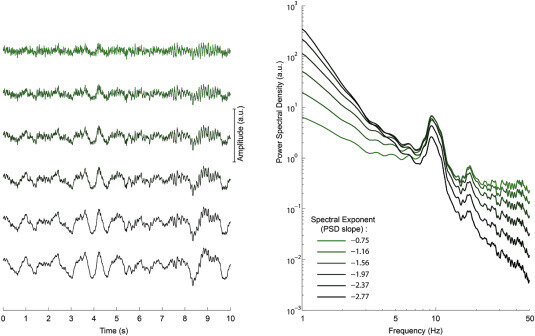
Fonte: Colombo et al., 2019
\text{``Probabilidade'' de um oscilador $f$:}
\text{$p(f) =\frac{P(f)}{\sum_f P(f)}$}
\text{Entropia Espectral:}
H = -\sum_f p(f)\log_2(p(f))
8. Spectral Entropy
Princípios e Técnicas de EEG
Aula 13
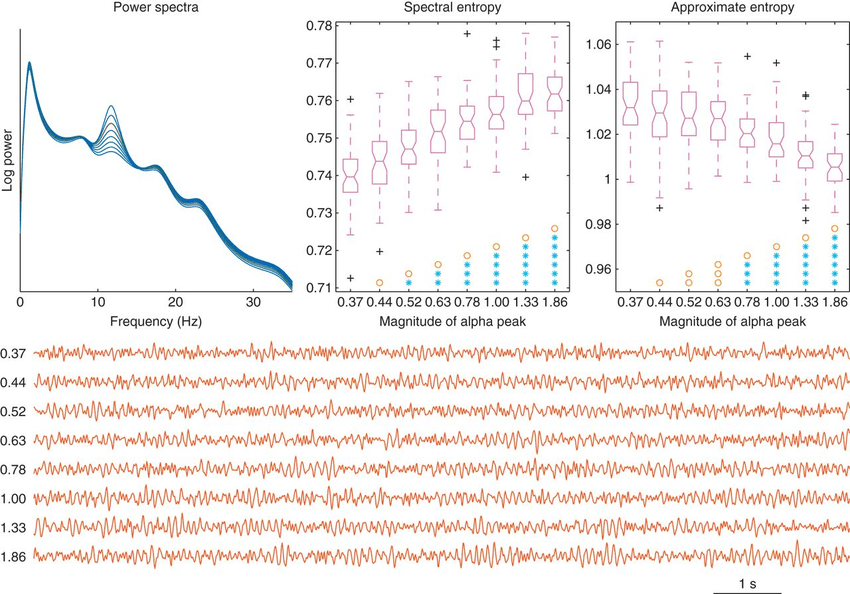
Fonte: Anier et al. (2012)
8. Spectral Entropy
Princípios e Técnicas de EEG
Aula 13
Spectral Entropy
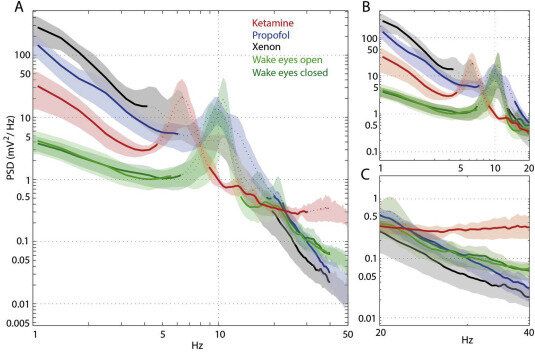
Fonte: Colombo et al., 2019
\text{Aplicação em anestesia!}
\text{Evidência moderada de utilidade clínica}
8. Spectral Entropy
Princípios e Técnicas de EEG
Aula 13
PRINCÍPIOS E TÉCNICAS DE ELETROENCEFALOGRAFIA EM NEUROCIÊNCIA
Próximas Aulas:
AULA 14 - Ritmos do EEG
AULA 15 (Tópicos Avançados) -Conectividade Funcional
Instituto de Ciência e Tecnologia
Graduação em Engenharia Biomédica
Prof. Dr. Adenauer G. Casali
Laboratório de Neuroengenharia e Computação
casali@unifesp.br
Tópicos Avançados - Aula 13 - As muitas entropias do EEG
By ADENAUER GIRARDI CASALI



