PRINCÍPIOS E TÉCNICAS DE ELETROENCEFALOGRAFIA EM NEUROCIÊNCIA
AULA 09 - Teoria da Informação: O Teorema de Shannon (parte II)
Instituto de Ciência e Tecnologia
Graduação em Engenharia Biomédica
Prof. Dr. Adenauer G. Casali
Laboratório de Neuroengenharia e Computação
casali@unifesp.br



PRINCÍPIOS E TÉCNICAS DE EEG EM NEUROCIÊNCIA
- A prova e o significado do "Shannon's source coding theorem"
- A Entropia de Shannon
- Entropia Conjunta
- Informação Mútua
- Entropia Condicional
Adenauer G. CASALI
AULA 09
Nesta aula, nós veremos...

1. Shannon's source coding theorem
Princípios e Técnicas de EEG
Aula 09
\text{Mas quantos elementos possui o conjunto de sequências típicas $T_{N\beta}$?}
\text{Na aula passada mostramos que praticamente todas as sequências de $X^N$ estão em $T_{N\beta}$ quando}
\text{Comprimir $X^N$ para o conjunto de sequências típicas $T_{N\beta}$ sem perder nada significativo!}
N\rightarrow \infty \text{. A ideia então é a seguinte:}
\text{Lembre que o subconjunto de elementos típicos de $\mathcal{A}_X^{N}$ com tolerância $\beta$ é definido por:}
T_{N\beta} \equiv \Bigl\{ \vec{x}\in \mathcal{A}_{X}^{N} : \Bigl| \frac{1}{N}\log_2\Bigl(\frac{1}{P(\vec{x})}\Bigr) - H\Bigr|< \beta\Bigr\}
(NH - \beta) <\log_2\Bigl(\frac{1}{P(\vec{x})}\Bigr)< (NH + \beta)
\text{Portanto, se $\vec{x}$ é uma sequência típica, vale o seguinte:}
2^{-NH - \beta} < P(\vec{x}) < 2^{-NH + \beta}
1. Shannon's source coding theorem
Princípios e Técnicas de EEG
Aula 09
\text{Qantos elementos possui o conjunto de sequências típicas $T_{N\beta}$?}
\text{Então, a menor probabilidade de um elemento de $T_{N\beta}$ é $2^{-N(H(X)+\beta)}$ e a probabilidade total contida}
\text{em $T_{N\beta}$ obviamente deve ser menor que 1, portanto:}
|T_{N\beta}|2^{-N(H(X)+\beta)}< 1\rightarrow |T_{N\beta}|< 2^{N(H(X)+\beta)}
\text{Em unidades, logarítmicas, $\log_2(|T_{N\beta}|) < N(H(X)+\beta)$ bits, ou seja: }
\frac{1}{N}\log_2(|T_{N\beta}|) < H(X)+\beta
\text{Isso significa que sempre podemos comprimir $X^N$ com risco $\delta$ de forma a $\frac{1}{N}H_{\delta}(X^N) < H(X)+\delta$.}
H(X) é um limite superior da informação contida em X para N grande!
\text{$H(X)$ é o limite superior de $\frac{1}{N}H_{\delta}(X^N) $: seria também o limite inferior?}
\text{Suponha que não seja o limite superiore, isto é, suponha que existe uma compressão $S'_{\delta}$ de $X^N$ }
\text{Ora, a probabilidade de $\vec{x}$ estar em $S'_{\delta}$, porém, é:}
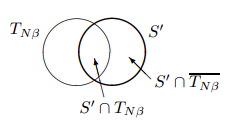
P(\vec{x} \in S') = P(\vec{x} \in S'\bigcap T_{N\beta}) + P(\vec{x} \in S'\bigcap \overline{T_{N\beta}})
\text{de uma sequência típica é $2^{-N(H-\beta)}$. Portanto, a máxima probabilidade de $\vec{x}$ estar em $S'\bigcap T_{N\beta}$ é }
\text{Por hipótese, o número de sequências em $S'$ é no máximo $2^{N(H-\epsilon)}$ e a probabilidade máxima }
\text{Como vimos na aula passada, pelo teorema dos grandes números, a probabilide de $\vec{x}$ não estar}
\text{$2^{N(H-\epsilon)}2^{-N(H-\beta)} = 2^{-N(\epsilon-\beta)}$}
\text{De onde se segue que: $\:\:\:P(\vec{x} \in S') \leq 2^{-N(\epsilon-\beta)} + \frac{\sigma_h^2}{\beta^2N}$}
\text{tal que $\frac{1}{N}H_{\delta}(X^N) < H -\epsilon $ para algum $\epsilon$.}
\text{Lembre-se que isto significa que $P(\vec{x}\in S'_{\delta})>1-\delta$ }
1. Shannon's source coding theorem
Princípios e Técnicas de EEG
Aula 09
\text{ em $T_{N\beta}$ é no máximo $\sigma_h^2/\beta^2N$.}
P(\vec{x} \in S') \leq 2^{-N(\epsilon-\beta)} + \frac{\sigma_h^2}{\beta^2N}
\text{Neste caso, basta escolher um $\beta$ menor que $\epsilon$ para ver que esta probabilidade vai a zero! Isto é }
P(\vec{x} \in S'_{\delta})< 1-\delta
\text{Portanto, não existe uma compressão $S'_{\delta}$ de $X^N$ tal que $\frac{1}{N}H_{\delta}(X^N) < H -\epsilon $ para algum $\epsilon$.}
1. Shannon's source coding theorem
Princípios e Técnicas de EEG
Aula 09
\text{Lembre-se de que $\beta$ é o parâmetro de tolerância e }
\text{pode ser escolhido como o menor possível }
\text{Isto tudo pode ser resumido no seguinte teorema: }
\text{{\it \bf Shannon's Source Coding Theorem:} Se $X$ for um ensemble com $H(X) = H$ bits, }
\text{dado $\epsilon>0$ e $0<\delta<1$, existe um inteiro positivo $N_0$ tal que para $N>N_0$: }
\Bigl|\frac{1}{N}H_{\delta}(X^N) - H \Bigr| <\epsilon.
\text{Ou em português: uma sequência de $N$ variáveis independentes provenientes de um processo X}
\text{pode ser comprimida em pelo menos $NH(X)$ bits com {\bf perda negligível de informação} quando }
\text{$N\rightarrow \infty$. Por outro lado, se a sequência for comprimida em menos de $NH(X)$ bits é praticamente }
\text{certo que {\bf informação será perdida.} }
\text{Portanto, $H(X)$ é a medida de informação média (informação por termo) contida no ensemble $X$!}
1. Shannon's source coding theorem
Princípios e Técnicas de EEG
Aula 09
\text{Para ganharmos intuição sobre o que está acontecendo, vamos trabalhar com este exemplo: }
\text{Moeda viciada, definindo o seguinte ensemble:}
\mathcal{A}_X = \{\text{cara$=0$, coroa$=1$}\}
\mathcal{P}_X =\{0.9, 0.1\}
\text{Vamos encontrar as compressões para sequências $N=4$ com diferentes riscos $\delta$.}
0000\rightarrow p_0 = (0.9)^4 = 0.6561, n_0=1
0001, 0010, 0100, 1000 \rightarrow p_1 = (0.9)^3(0.1)=0.0729, n_1=4
0011, 0101, 1001, 0110, 1010, 1100 \rightarrow p_2 = (0.9)^2(0.1)^2=0.0081,n_2=6
0111, 1011, 1101, 1110 \rightarrow p_3 = (0.9)(0.1)^3=0.0009,n_3=4
1111 \rightarrow p_4 = (0.1)^4=0.0001,n_4=1
H(X) = 0.468995\: bits
|\mathcal{A}_X| = 1\: bit
1. Shannon's source coding theorem
Princípios e Técnicas de EEG
Aula 09
0000\rightarrow p_0 = (0.9)^4 = 0.6561, n_0=1
0001, 0010, 0100, 1000 \rightarrow p_1 = (0.9)^3(0.1)=0.0729, n_1=4
0011, 0101, 1001, 0110, 1010, 1100 \rightarrow p_2 = (0.9)^2(0.1)^2=0.0081,n_2=6
0111, 1011, 1101, 1110 \rightarrow p_3 = (0.9)(0.1)^3=0.0009,n_3=4
1111 \rightarrow p_4 = (0.1)^4=0.0001,n_4=1
\delta=0
H_\delta=\log_2|S_{\delta}| = \log_2 16 = 4
\delta=0.0001
H_\delta=\log_2|S_{\delta}| = \log_2 15 = 3.9068
\delta=0.0010
H_\delta=\log_2|S_{\delta}| = \log_2 14 = 3.8074
\delta=0.0019
H_\delta=\log_2|S_{\delta}| = \log_2 14 = 3.7004
\delta=0.3439
H_\delta=\log_2|S_{\delta}| = \log_2 1 = 0
\vdots
\vdots
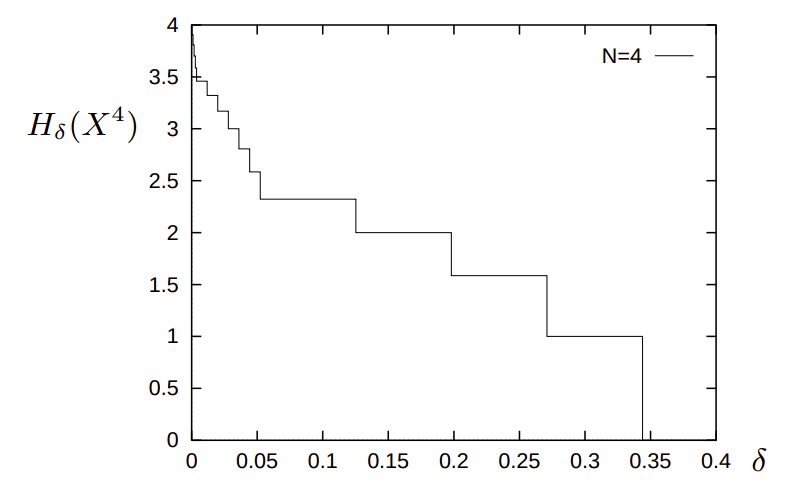
Fonte: MacKay, cap. 2
1. Shannon's source coding theorem
Princípios e Técnicas de EEG
Aula 09
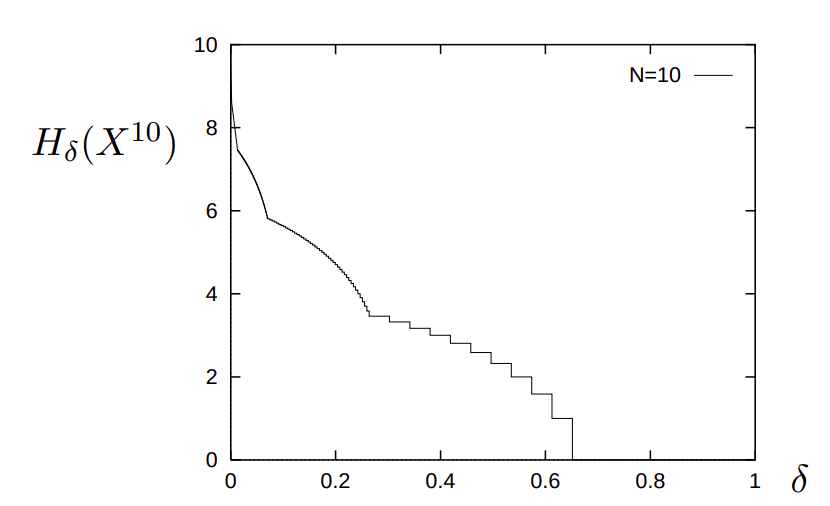
Fonte: MacKay, cap. 2
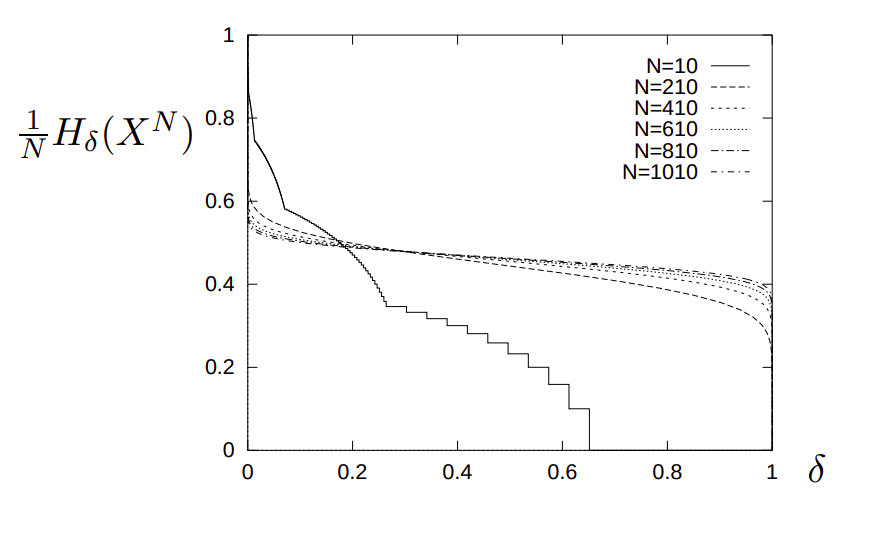
1. Shannon's source coding theorem
Princípios e Técnicas de EEG
Aula 09
\text{Quando $N$ cresce $H_\delta$ não mais depende sensivelmente de $\delta$}
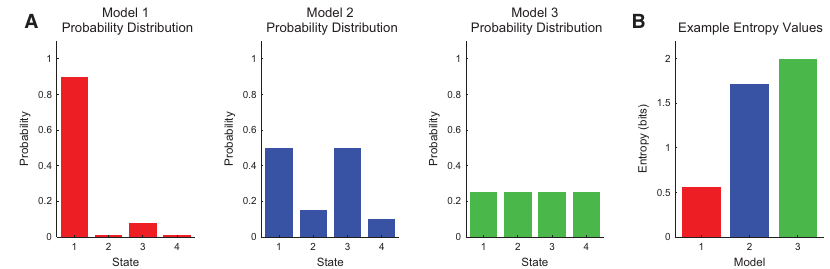
\text{A {\bf Entropia de Shannon} de $X$ é definida por: } H(X) = -\sum_{i=1}^{I}p_i\log_2(p_i)
\text{Seja um {\bf ensemble} X: }(x,\mathcal{A}_X, \mathcal{P}_X), \text{ onde $x$ é o {\it outcome} de uma}
\text{variável aleatória com $I$ valores possíveis e que formam o conjunto }
\mathcal{A}_X = \{a_1, a_2,..., a_i,...,a_I\}, \text{ com respectivas probabilidades}
\mathcal{P}_X = \{p_1, p_2,..., p_i,...,p_I\}, \text{ sendo } P(x=a_i)=p_i, p_i\geq 0, \sum_{a_i\in \mathcal{A}_X}P(x=a_i) = 1.
\text{A {\bf Entropia de Shannon} de $X$ é a média da Informação $In(x)$ de cada {\it outcome}: }
H(X) = \sum_{i=1}^{I}P(x=a_i)In(x=a_i)
In(x) = \log_2\Bigl(\frac{1}{P(x)}\Bigr)
2. A Entropia de Shannon
Princípios e Técnicas de EEG
Aula 09
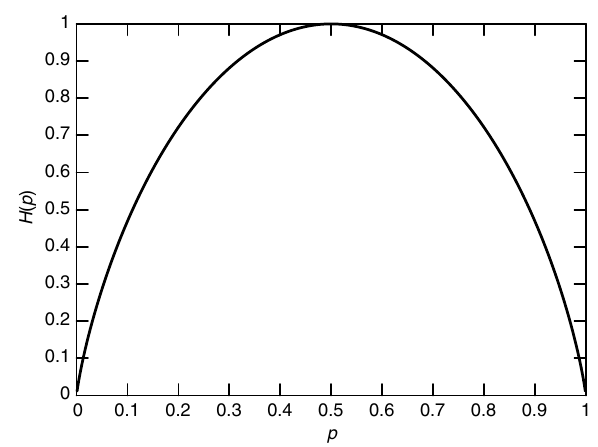
Comportamento de H para uma variável binária (com probabilidade p)
Fonte: Cover and Thomas, "Elements of Information Theory" (2006)
2. A Entropia de Shannon
Princípios e Técnicas de EEG
Aula 09
3. Entropia Conjunta (multivariada)
Princípios e Técnicas de EEG
Aula 09
Entropia multivariada
p(x_i)
Uma variável
X=\{ x_i\}
H(X,Y) = \sum_{i,j}p(x_i,y_j)\log_2(\frac{1}{p(x_i,y_j)})
p(x_i,y_j)
Duas variáveis
X=\{ x_i\}
Y=\{ y_j\}
H(X) = \sum_{i}p(x_i)\log_2(\frac{1}{p(x_i)})
Entropia multivariada
Por exemplo: duas moedas que são jogadas independentemente (sem vieses)
Moeda 1 (X):
Moeda 2 (Y):
x_1=\textrm{cara}
x_2=\textrm{coroa}
y_1=\textrm{cara}
y_2=\textrm{coroa}
p(x_1,y_1)=\frac{1}{4}\\
p(x_1,y_2)=\frac{1}{4}\\
p(x_2,y_1)=\frac{1}{4}\\
p(x_2,y_2)=\frac{1}{4}\\
H(X,Y) = p(x_1,y_1)\log_2(\frac{1}{p(x_1,y_1)})+p(x_1,y_2)\log_2(\frac{1}{p(x_1,y_2)})+p(x_2,y_1)\log_2(\frac{1}{p(x_2,y_1)})+p(x_2,y_2)\log_2(\frac{1}{p(x_2,y_2)})
H(X,Y) = \sum_{i,j}p(x_i,y_j)\log_2(\frac{1}{p(x_i,y_j)})
H(X,Y) = \frac{1}{4}\log_2(4)+\frac{1}{4}\log_2(4)+\frac{1}{4}\log_2(4)+\frac{1}{4}\log_2(4)
= \log_2(4)
= 2\:\:\textrm{bits}
3. Entropia Conjunta (multivariada)
Princípios e Técnicas de EEG
Aula 09
De fato se os processos são independentes:
H(X,Y) = \sum_{i,j}p(x_i,y_j)\log_2(\frac{1}{p(x_i,y_j)})
p(x_i,y_j)=p(x_i)p(y_j)
H(X,Y) = \sum_{i,j}p(x_i)p(y_j)\log_2(\frac{1}{p(x_i)p(y_j)})
= \sum_{i,j}p(x_i)p(y_j)\bigl(\log_2(\frac{1}{p(x_i)})+\log_2(\frac{1}{p(y_j)})\bigr)
= \Bigl(\sum_{i}p(x_i)\log_2(\frac{1}{p(x_i)})\Bigr)+ \Bigl(\sum_{j}p(y_j)\log_2(\frac{1}{p(y_j)})\Bigr)
= H(X) + H(Y)
A informação contida em X + Y é igual à
informação contida em X + informação contida em Y
H(X) + H(Y) - H(X,Y)=0
Informação mútua entre X e Y:
Se os processos são independentes:
3. Entropia Conjunta (multivariada)
Princípios e Técnicas de EEG
Aula 09
4. Informação Mútua
Princípios e Técnicas de EEG
Aula 09
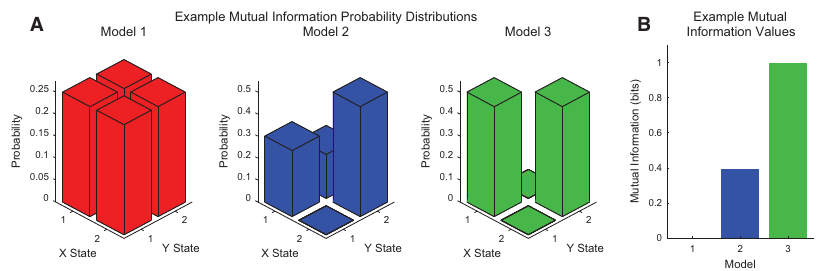
Informação Mútua (Mutual Information)
MI(X,Y) = H(X) + H(Y) - H(X,Y)
Informação em X e Y conjuntamente
Informação em X e Y independentemente
MI: medida da diferença entre p(X)p(Y) e p(X,Y): chamada de distância de Kullback-Leibler
MI: também pode ser entendida como a informação que Y providencia sobre X e que X providencia sobre Y (simétrica)
4. Informação Mútua
Informação Mútua (Mutual Information)
Princípios e Técnicas de EEG
Aula 09
5. Entropia Condicional
Princípios e Técnicas de EEG
Aula 09
Entropia condicional
H(X,Y) = \sum_{i,j}p(x_i,y_j)\log_2(\frac{1}{p(x_i,y_j)})
H(X|Y) = \sum_{i,j}p(x_i,y_j)\log_2(\frac{1}{p(x_i|y_j)})
p(x_i|y_j) = \frac{p(x_i,y_j)}{p(y_j)}
H(X|Y) = \sum_{i,j}p(x_i,y_j)\log_2(\frac{p(y_j)}{p(x_i,y_j)})
H(X|Y) = \sum_{i,j}p(x_i,y_j)\log_2(\frac{1}{p(x_i,y_j)})-\sum_{j}p(y_j)\log_2(\frac{1}{p(y_j)})
H(X|Y) = H(X,Y)-H(Y)
Medida da informação que "sobra" na variável X, depois que Y é conhecido!
Informação Mútua e entropia condicional
MI(X,Y) = H(X) + H(Y) - H(X,Y)
MI: informação em X menos a informação em X depois que conhecemos Y:
medida da informação que Y providencia sobre X
H(X|Y) = H(X,Y)-H(Y)
MI(X,Y) = H(X) - H(X|Y)
= H(Y) - H(Y|X)
(e que X providencia sobre Y)
5. Entropia Condicional
Princípios e Técnicas de EEG
Aula 09
Informação Mútua e entropia condicional
H(X)
H(Y)
MI(X,Y)
H(X|Y)
H(Y|X)
H(X,Y)
Informação em X e Y
Informação em X
Informação em Y
Informação em Y
dado X (conhecido X)
Informação em X
dado Y (conhecido Y)
5. Entropia Condicional
Princípios e Técnicas de EEG
Aula 09
Exemplo de uso da Informação Mútua
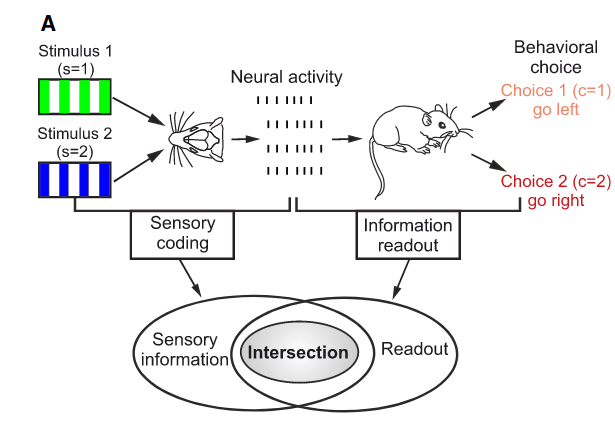
Neural Decoding
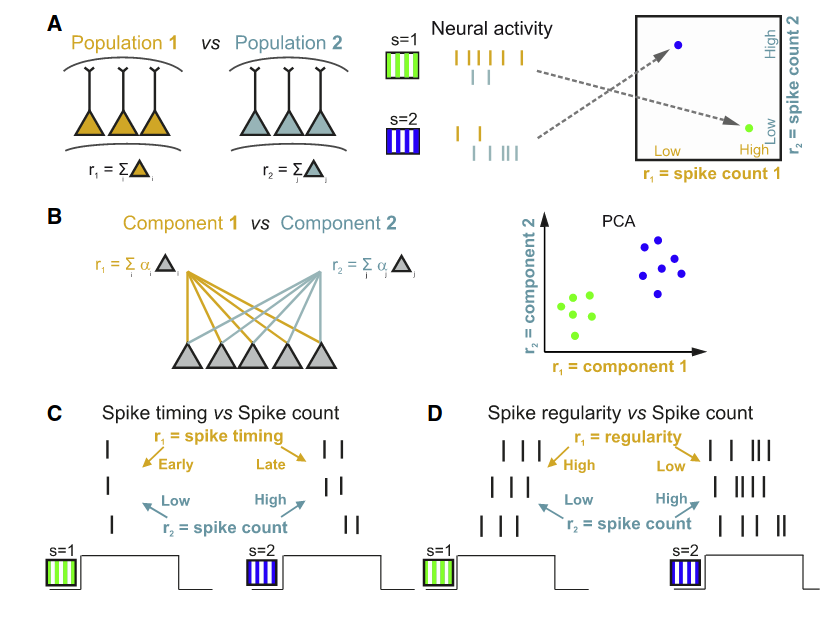
6. Exemplo de uso da Informação Mútua
Princípios e Técnicas de EEG
Aula 09
PRINCÍPIOS E TÉCNICAS DE ELETROENCEFALOGRAFIA EM NEUROCIÊNCIA
Próximas Aulas:
AULA 10 - Pré-processamento do EEG (parte II)
AULA 11 - Pré-processamento do EEG na prática
Instituto de Ciência e Tecnologia
Graduação em Engenharia Biomédica
Prof. Dr. Adenauer G. Casali
Laboratório de Neuroengenharia e Computação
casali@unifesp.br
Tópicos Avançados - Aula 09 - Teoria da Informação: O Teorema de Shannon (parte II)
By ADENAUER GIRARDI CASALI



