




Alireza Afzal Aghaei
Graduate student at SBU
Introduction to
Alireza Afzal Aghaei
Ph.D. Student
Shahid Beheshti University
Mathematical Modeling of engineering problems leads to
Ordinary differential equations
Partial differential equations
Integral equations
Optimal control
$$y''(x) + \frac{2}{x} y'(x) + y^m(x)=0$$
$$y(0)=1\\y'(0)=0$$
A linear first order differential is defined as
with the exact solution
$$z(t) = z(t_0) + \int_{t_0}^{t_1} f(z(t),t)\ dt$$
$$\frac{{dz}}{{dt}} = f\left( {z(t),t} \right),\ \ \ z \left( {{t_0}} \right) = {z_0},$$
Analytical Methods
Separation of variables
Laplace transform
Numerical Methods
Finite differences
Euler method
Runge-kutta
Adams–Bashforth
can be approximated by
Theorem. The solution to the following IVP
where \(\Delta t = t_n- t_{n-1}\) is an small step-size.
$$\frac{{dz}}{{dt}} = f\left( {z(t),t} \right),\ \ \ z \left( {{t_0}} \right) = {z_0},$$
$${z_{n + 1}} = {z_n} + \Delta t\,{f(z_n, t_n)},\quad n=1,2,\ldots$$
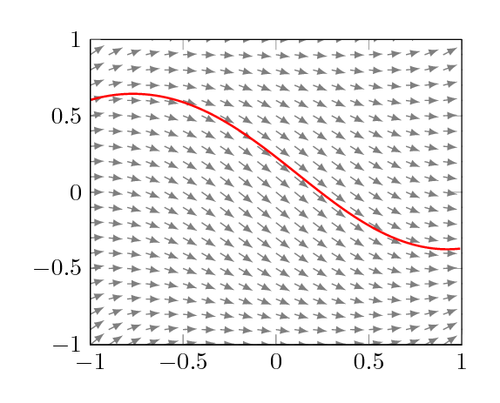
Euler method vs. modern solvers
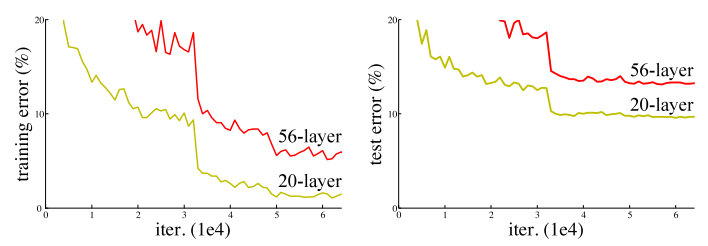
Training error (left) and test error (right) on CIFAR-10 with 20-layer and 56-layer “plain” networks.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016.
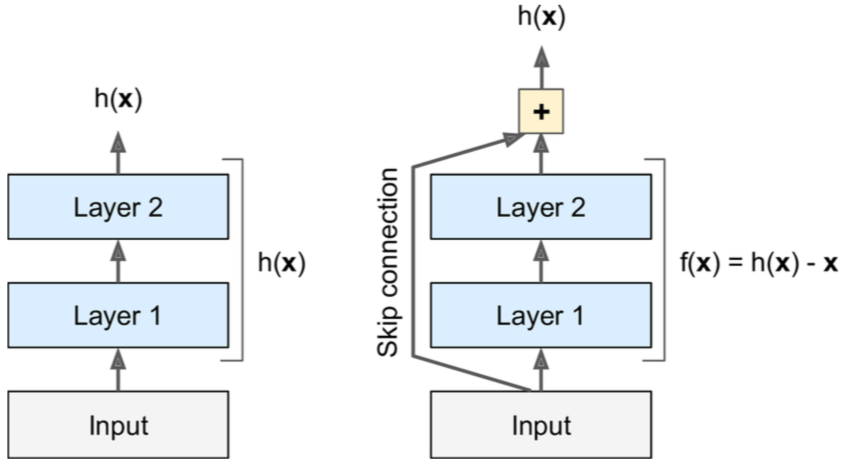
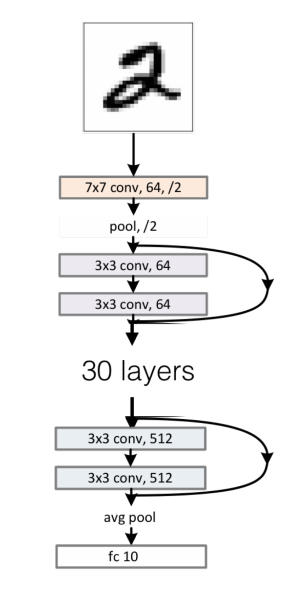
Traditional networks vs Resnets
In a general form, ResNets can be formulated as
By setting functions \(f,h\) as identity mappings
$$z_{t+1} = z_t + \mathcal{F}(z_t, \theta_t)\\$$
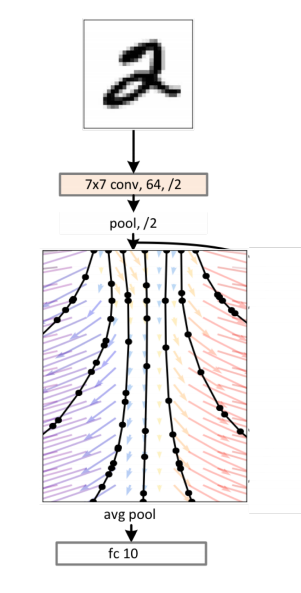
A chain of residual blocks in a neural network is basically a solution of the ODE with the Euler method!
| Network | Fixed-step Numerical Scheme |
|---|---|
| ResNet, RevNet, ResNeXt, etc. | Forward Euler |
| PolyNet | Approximation to Backward Euler |
| FractalNet | Runge-Kutta |
| DenseNet | Runge-Kutta |
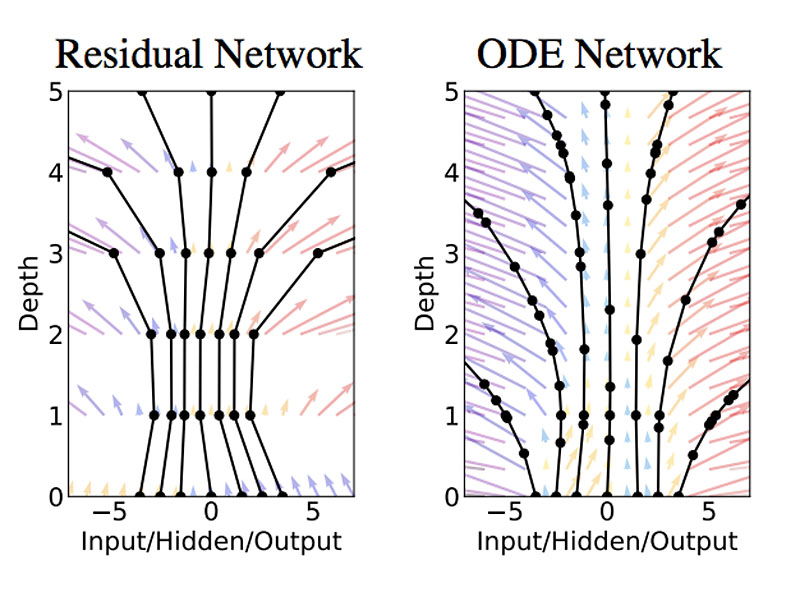
Let’s replace ResNet / EulerSolverNet with some abstract concept as ODESolveNet with much better accuracy than Euler’s method
Chen, Tian Qi, Yulia Rubanova, Jesse Bettencourt, and David K. Duvenaud. "Neural ordinary differential equations." In Advances in neural information processing systems, pp. 6571-6583. 2018.
Predict the output value for input \(x\) by solving $$\frac{{dz}}{{dt}} = \mathcal{F}\left( {z(t),t,\theta} \right)$$ w.r.t initial condition $$z \left( {{0}} \right) = {x},$$ by a black-box ODE solver where $$t \in [0, T].$$
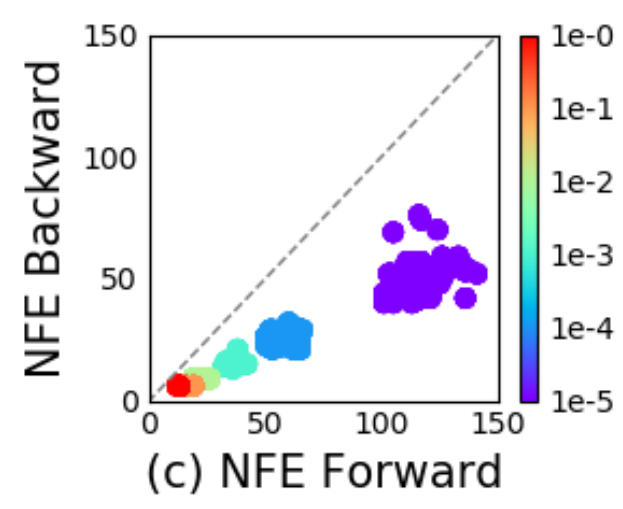
The effect of adaptive solver
def F(z, t, θ):
return nnet([z,t], θ)
def FixedNODE(z):
for t in [1:T]:
z = z + F(z, t, θ)
return zdef F(z, t, θ):
return nnet([z,t], θ)
def AdaptiveNODE(z):
z = ODESolve(F, z, 0, T, θ)
return z
def F(z, t, θ):
return nnet(z, θ[t])
def resnet(z):
for t in [1:T]:
z = z + F(z, t, θ)
return zdef F(z, t, θ):
return nnet[t](z, θ[t])
def resnet(z):
for t in [1:T]:
z = z + F(z, t, θ)
return zDifferent Res Blocks for each time step
Different weights for similar Res Blocks
Shared weights, continuous model
Replace Euler with adaptive solver
$$L(z(t_n)) = L(\ z(t_0) + \int_{t_0}^{t_n} \mathcal{F}(z(t),t, \theta)dt\ )$$
$$=L(ODESolve(\mathcal{F},z(t_0),t_0,t_n,\theta))$$
$$\frac{\partial L}{\partial z(t)},\frac{\partial L}{\partial \theta}=??$$
Naive approach: Backprop through the solver
New approach: Adjoint sensitivity analysis
$$v^TC=v^TAB=(A^Tv)^TB=u^TB$$
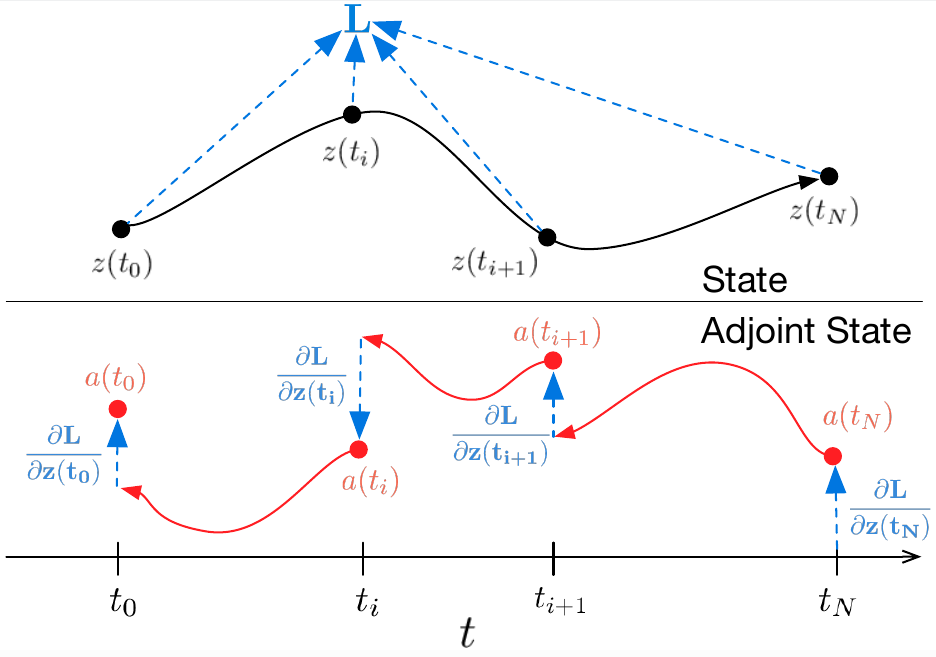
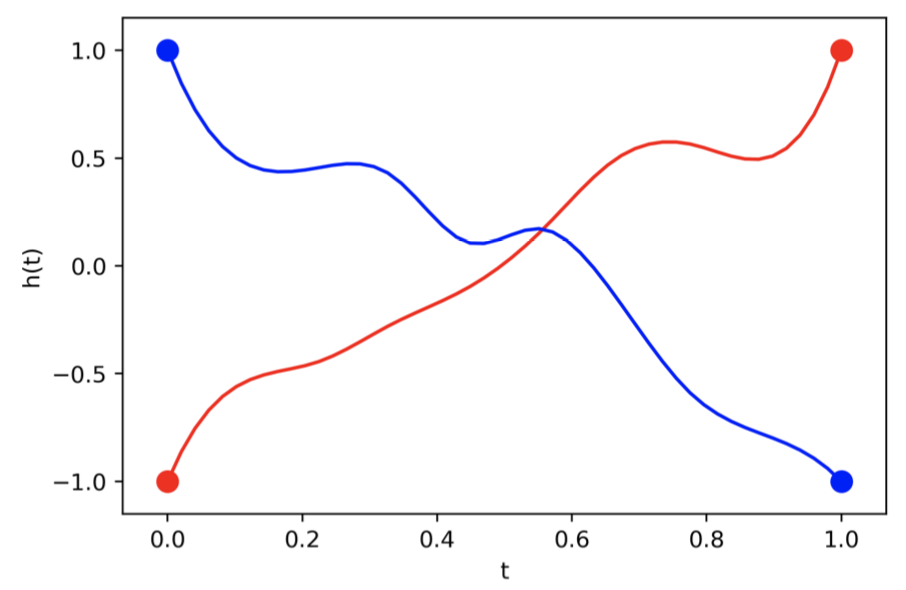
Reverse-mode differentiation of an ODE solution
Theorem. By defining adjoint state $$a(t) = \frac{\partial L}{\partial z(t)},$$ its dynamics are given by ODE
$$\frac{\text{d}a(t)}{\text{d}t} = - a(t)^T \frac{\partial \mathcal{F}(z(t),t,\theta)}{\partial z}.$$
A simple proof is available in Appendix B.
$$\frac{\partial L}{\partial t_n} = a(t_n)^T\mathcal{F}(z(t),t,\theta)$$
$$\frac{\partial L}{\partial \theta} = -\int_{t_n}^{t_0} a(t)^T \frac{\partial \mathcal{F}(z(t),t,\theta)}{\partial \theta}dt$$
$$\frac{\partial L}{\partial t_0} = a(t_n)-\int_{t_n}^{t_0} a(t)^T \frac{\partial \mathcal{F}(z(t),t,\theta)}{\partial t}dt$$
$$\frac{\partial L}{\partial z(t_0)} = a(t_n) -\int_{t_n}^{t_0} a(t)^T \frac{\partial \mathcal{F}(z(t),t,\theta)}{\partial z(t)}dt$$
\(a = \frac{\partial L}{\partial z_t}\)
\(z_{t+h} = z_t + h \mathcal{F}(z_t)\)
\(a_t = a_{t+h} + h a_{t+h} \frac{\partial \mathcal{F}(z_t)}{\partial z_t}\)
\(\frac{\partial L}{\partial \theta} = h a_{t+h} \frac{\partial \mathcal{F}(z(t),\theta)}{\partial \theta}\)
\(a(t) = \frac{\partial L}{\partial z(t)}\)
\(z(t+h) = z(t) + \int_t^{t+h}\mathcal{F}(z(t))dt\)
\(a(t) = a(t+h) + \int_{t+h}^t a(t)^T \frac{\partial \mathcal{F}(z(t))}{\partial z(t)}dt\)
\(\frac{\partial L}{\partial \theta} = \int_t^{t+h} a(t)^T \frac{\partial \mathcal{F}(z(t),\theta)}{\partial \theta}dt\)
Define
Forward
Backward
Params
ResNet
NODE
NFE = Number of Function Evaluations
nn = Network(
Dense(...), # making some primary embedding
ODESolve(...), # "infinite-layer neural network"
Dense(...) # output layer
)Pseudocode of NODE usage
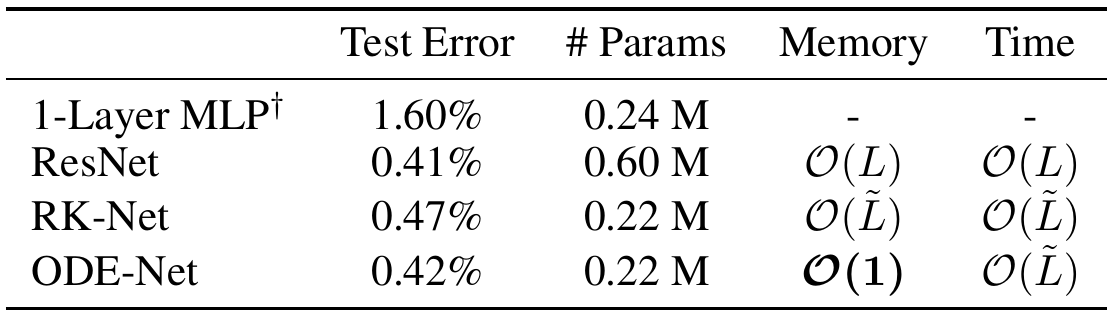
Performance on the MNIST dataset
ResNet vs NODE
| Model | Test score | # Params | Time (sec) |
|---|---|---|---|
| Resnet(6) | 85.43% | 0.6M | 3700 |
| Resnet(1) | 83.62% | 0.22M | 1500 |
| NODE | 83.90% | 0.22M | 11000 |
Results on CIFAR-10 dataset
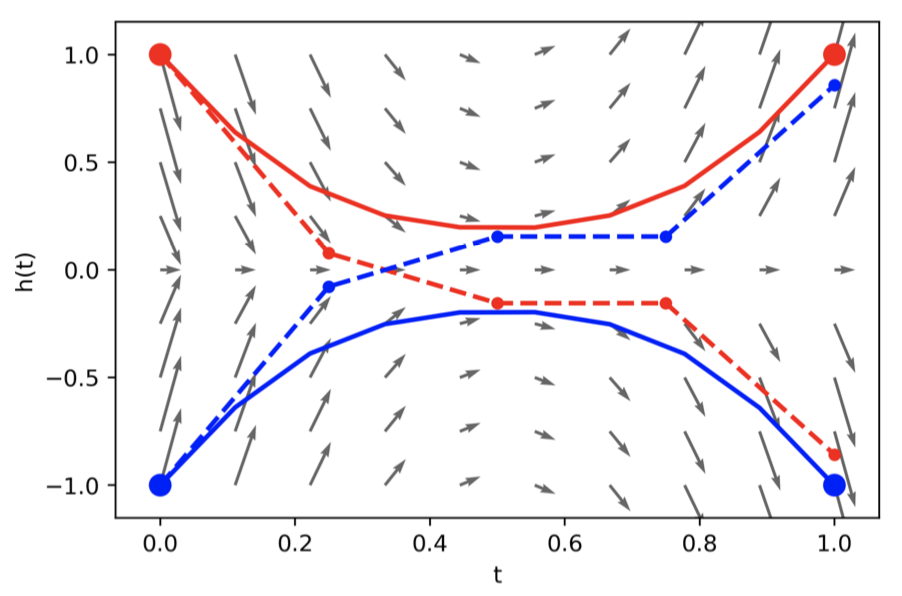
what if the map we are trying to model cannot be described by a vector field?
Ideal mapping
ResNet vs NODE
what if the map we are trying to model cannot be described by a vector field?
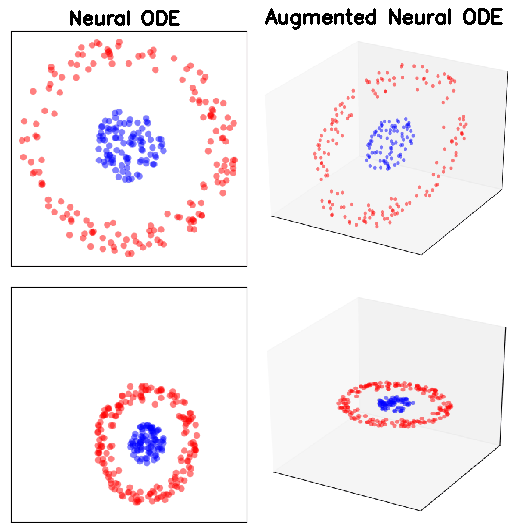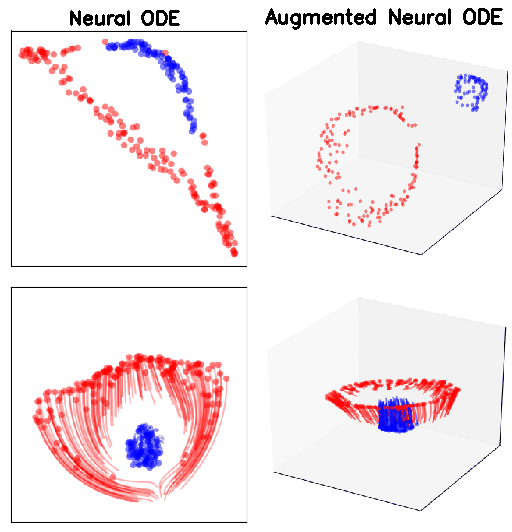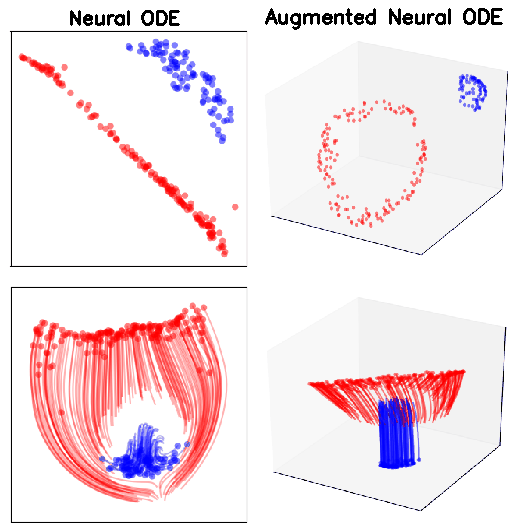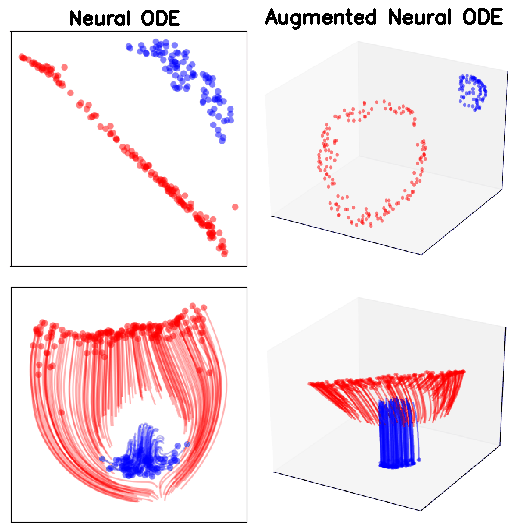
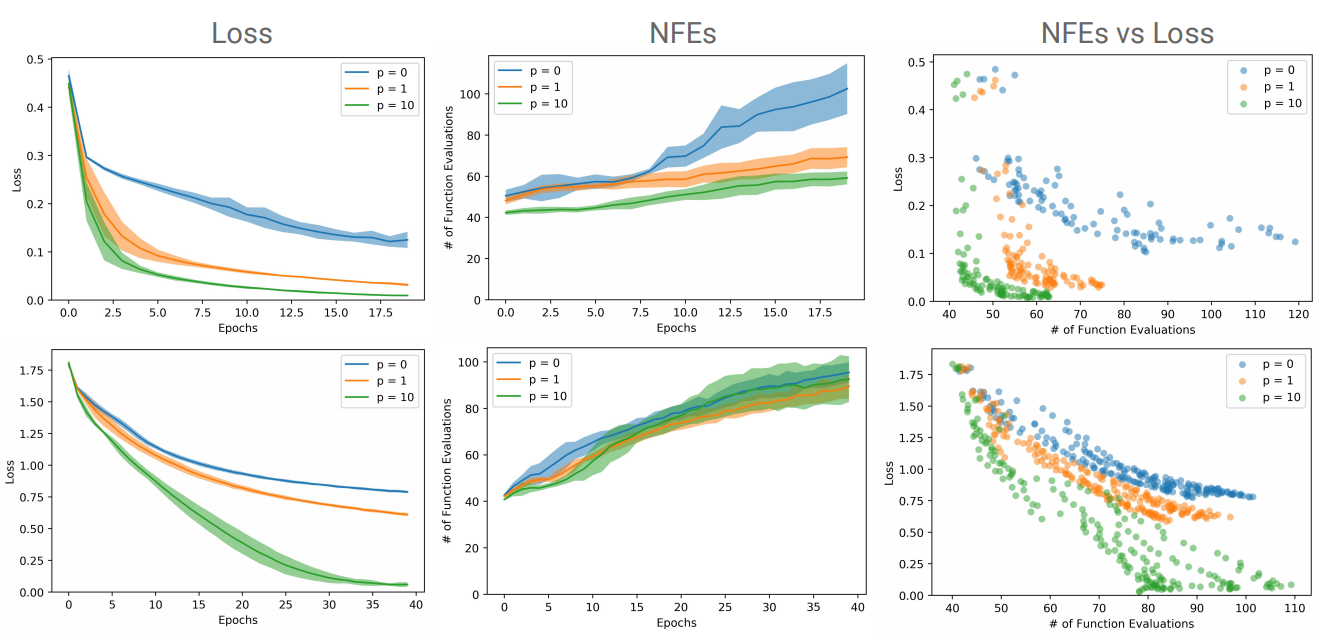
MNIST (top row) and CIFAR10 (bottom row). p indicates the size of the augmented dimension
Accuracy
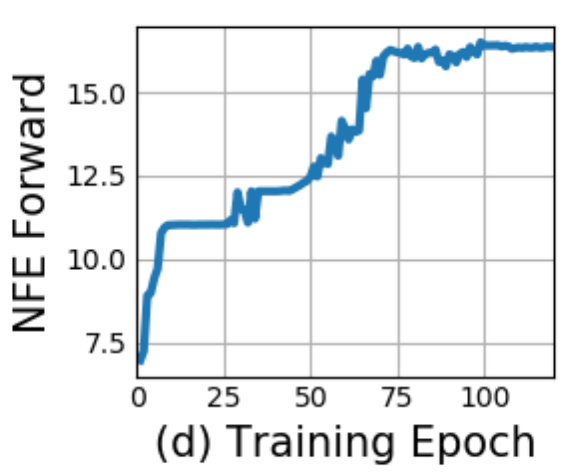
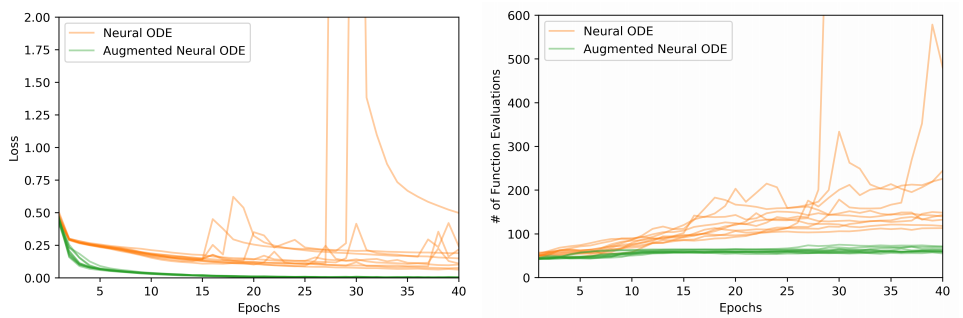
Instabilities in the loss (left) and NFEs (right) on MNIST
$ pip install torchdiffeq
$ git clone https://github.com/EmilienDupont/augmented-neural-odesimport torch
import seaborn
import matplotlib.pyplot as plt
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import TensorDataset, DataLoader
from anode.conv_models import ConvODENet
from anode.models import ODENet
from anode.training import Trainer
from sklearn.datasets import load_irishidden_dim = 10
augment_dim = 10
epochs = 20
device = torch.device('cpu')features, labels = load_iris(return_X_y=True)
iris = TensorDataset(torch.FloatTensor(features),
torch.LongTensor(labels))
train_loader = DataLoader(iris, shuffle=True, batch_size=16)node = ODENet(device,
data_dim=4,
hidden_dim=hidden_dim,
output_dim=3,
augment_dim=0)
optimizer = torch.optim.Adam(node.parameters(), lr=1e-3)
trainer = Trainer(node, optimizer, device,
classification=True, verbose=False)
trainer.train(train_loader, num_epochs=epochs)node = ODENet(device,
data_dim=4,
hidden_dim=hidden_dim,
output_dim=3,
augment_dim=0,
time_dependent=True)
optimizer = torch.optim.Adam(node.parameters(), lr=1e-3)
trainer = Trainer(node, optimizer, device,
classification=True, verbose=False)
trainer.train(train_loader, num_epochs=epochs)anode = ODENet(device,
data_dim=4,
hidden_dim=hidden_dim,
output_dim=3,
augment_dim=augment_dim
)
optimizer = torch.optim.Adam(anode.parameters(), lr=1e-3)
trainer = Trainer(anode, optimizer, device,
classification=True, verbose=False)
trainer.train(train_loader, num_epochs=epochs)anode = ODENet(device,
data_dim=4,
hidden_dim=hidden_dim,
output_dim=3,
augment_dim=augment_dim,
time_dependent=True
)
optimizer = torch.optim.Adam(anode.parameters(), lr=1e-3)
trainer = Trainer(anode, optimizer, device,
classification=True, verbose=False)
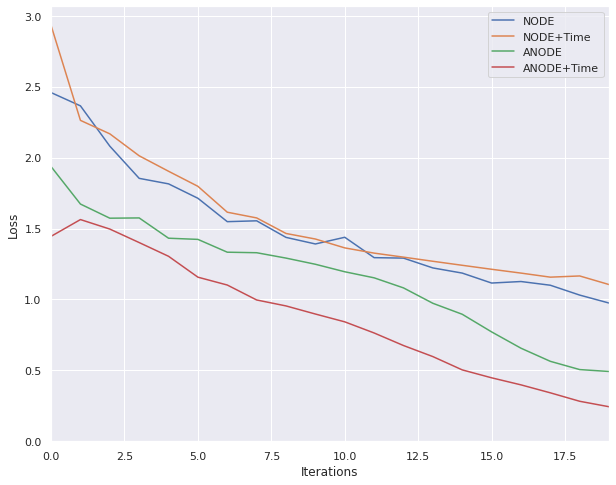
trainer.train(train_loader, num_epochs=epochs)Comparison of models
batch_size = 256
n_classes = 10
train_loader = DataLoader(datasets.MNIST('.', train=True,
download=True,
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.0, ), (1.0, ))])),
batch_size=batch_size, shuffle=True)
test_loader = DataLoader(datasets.MNIST('.', train=False,
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.0, ), (1.0, ))])),
batch_size=batch_size, shuffle=True)
anode = ConvODENet(device, img_size=(1, 28, 28), num_filters=16,
output_dim=n_classes, augment_dim=5)
optimizer = torch.optim.Adam(anode.parameters(), lr=0.001)
trainer = Trainer(anode, optimizer, device, classification=True)
trainer.train(train_loader, num_epochs=50)
Graph Neural Ordinary Differential Equations
Deep Neural Networks Motivated by Partial Differential Equations
PDE-Net 2.0: Learning PDEs from data with a numeric-symbolic hybrid deep network
A mean-field optimal control formulation of deep learning
Deep learning theory review: An optimal control and dynamical systems perspective
Neupde: Neural network based ordinary and partial differential equations for modeling time-dependent data
SNODE: Spectral Discretization of Neural ODEs for System Identification
FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models
Differential equations as models of deep neural networks
Approximation Capabilities of Neural Ordinary Differential Equations
Neural SDE: Stabilizing Neural ODE Networks with Stochastic Noise
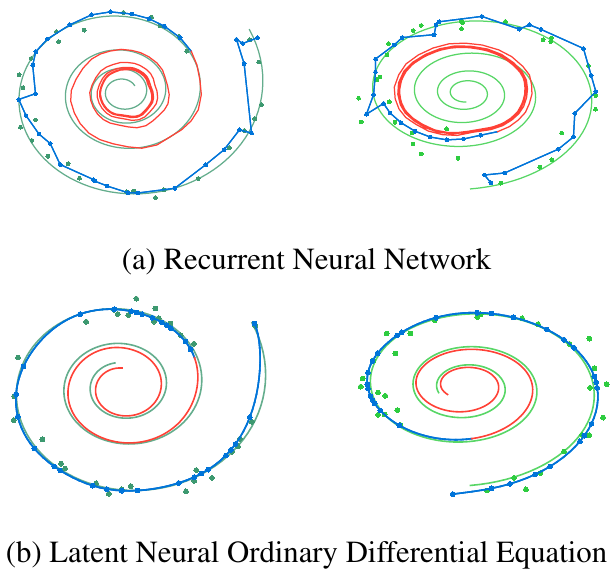
Latent Ordinary Differential Equations for Irregularly-Sampled Time Series
ODE-Inspired Network Design for Single Image Super-Resolution
Neural ODEs with stochastic vector field mixtures
ODE2VAE: Deep generative second order ODEs with Bayesian neural networks
Accelerating Neural ODEs with Spectral Elements
The fully explained article is available at
By Alireza Afzal Aghaei




