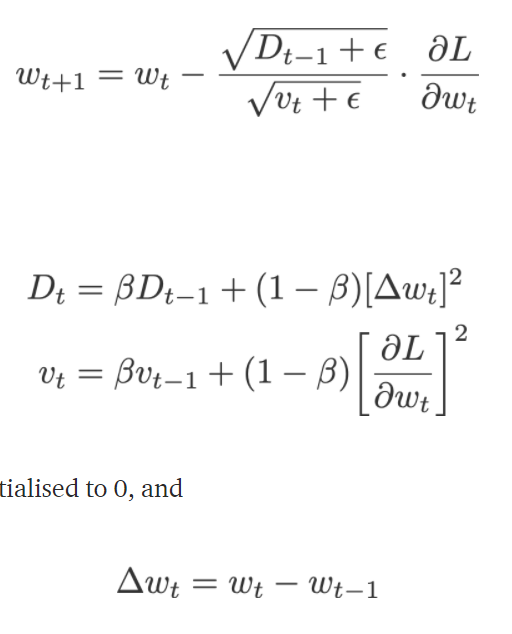
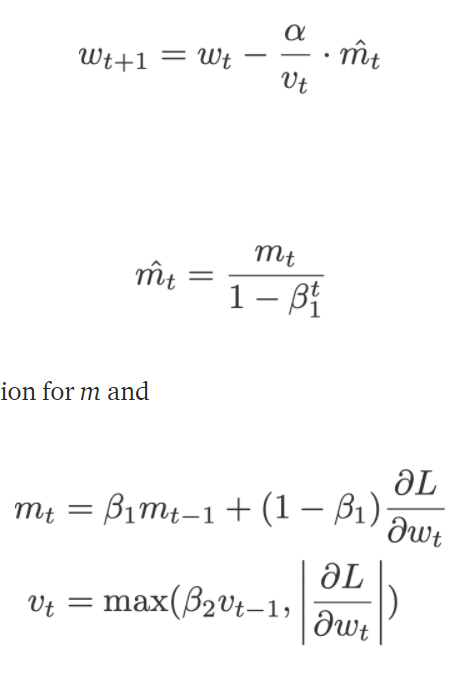
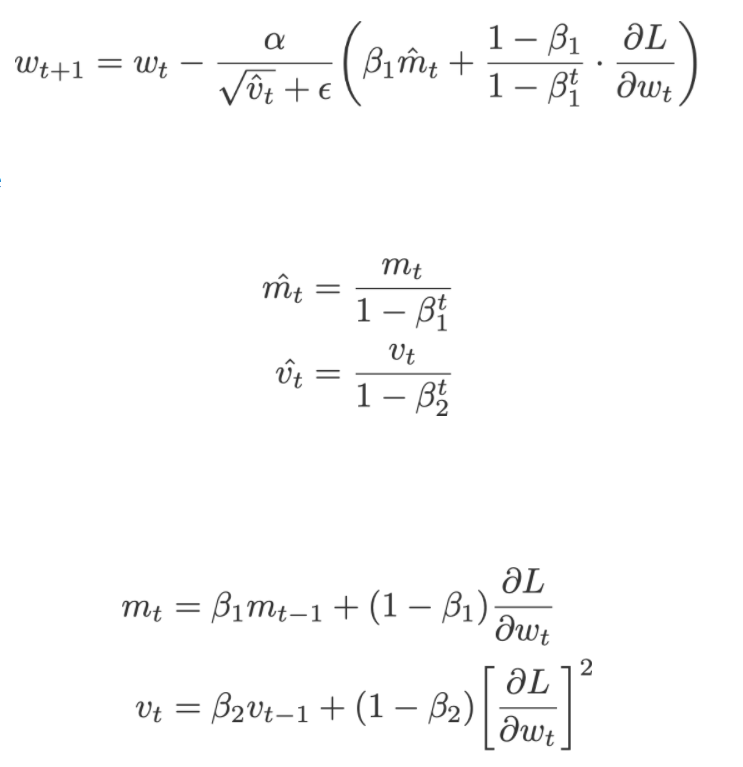
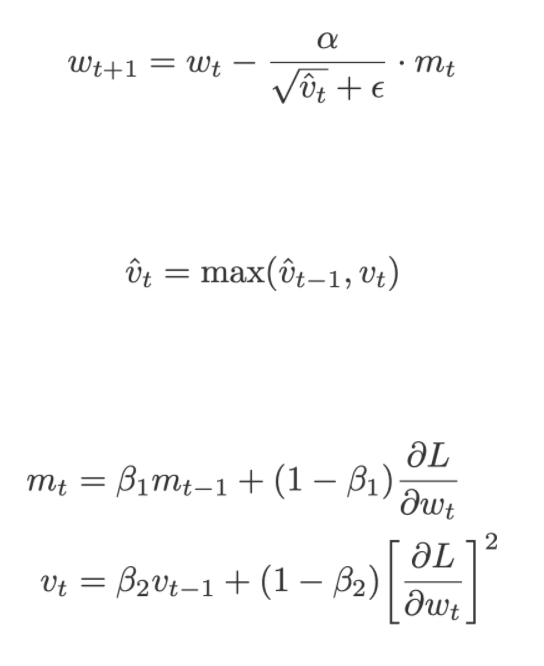
Amrutha
Course Content Developer for Deep Learning course by Professor Mitesh Khapra. Offered by IIT Madras Online degree - Programming and Data Science.
Activation function, Optimizer
Activation functions
| Already Present | Additional |
|---|---|
| 1. Sigmoid 2. TanH 3. ReLU 4. Leaky ReLU 5. Parametric ReLU 6. Exponential ReLU 7. Parametric ReLU 8. Maxout Neuron |
1. Softplus 2. Gaussian Error Linear Unit (GELU) 3. Scaled Exponential Linear Unit (SELU) 4. Sigmoid Linear Unit (SiLU, Sigmoid shrinkage, SiL, or Swish-1) 5. Mish 6. Gaussian 7. Truncation Linear Unit (TLU) |
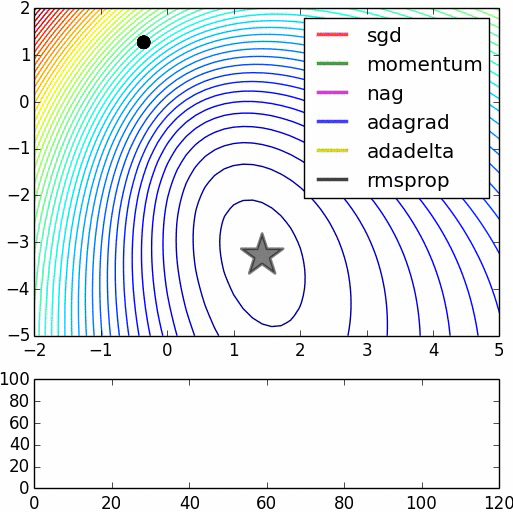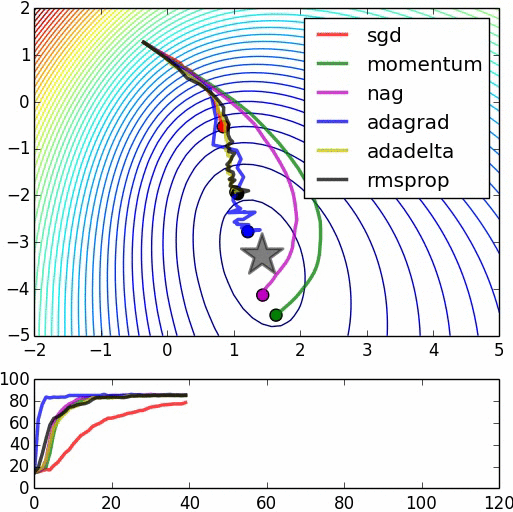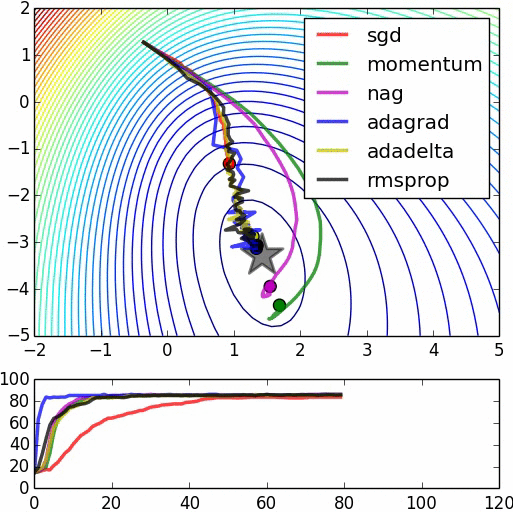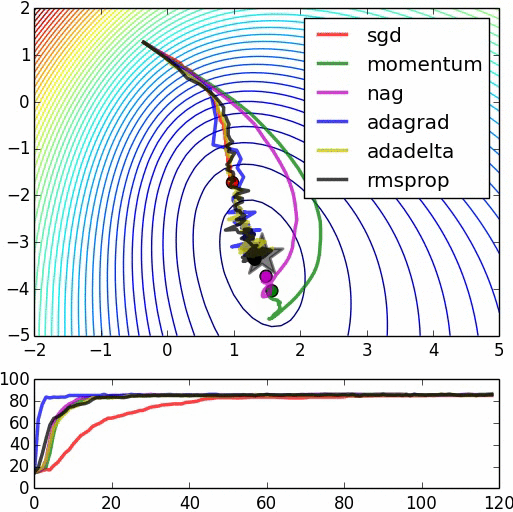
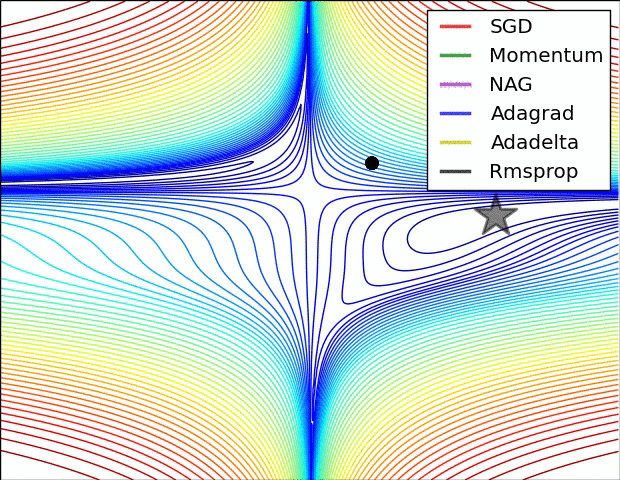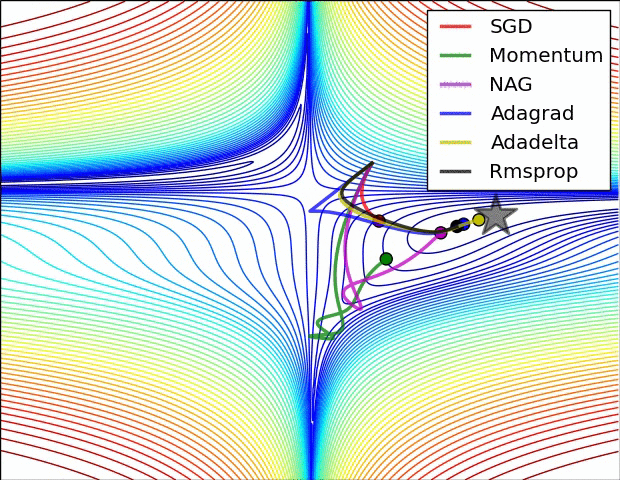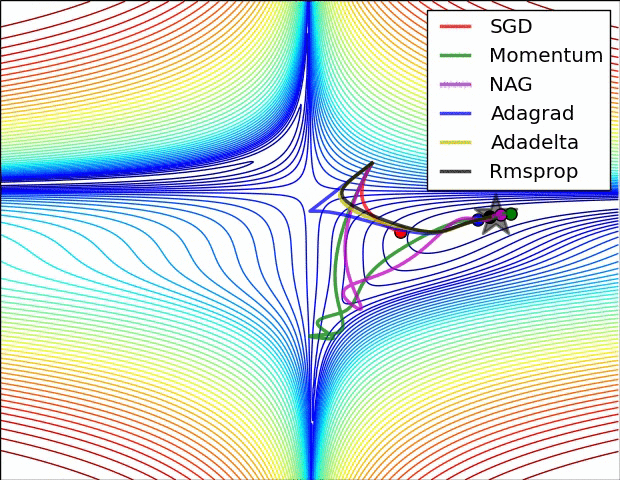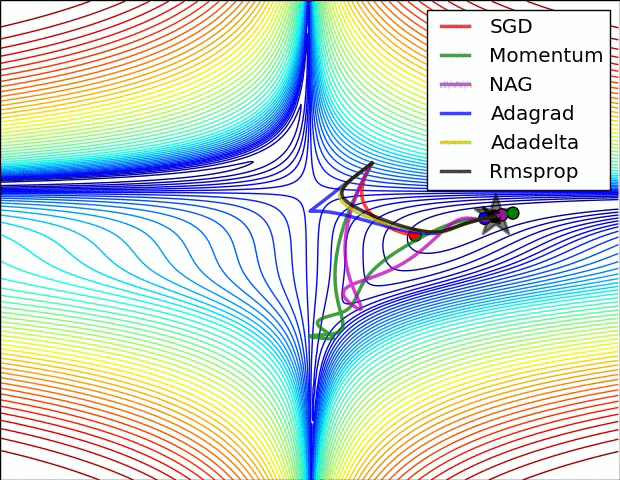
Optimizers
| Already Present | Additional |
|---|---|
| 1. Gradient Descent (GD) 2. Momentum Based GD 3. Nesterov Accelerated GD 4. Stochastic GD 5. AdaGrad 6. RMSProp 7. Adam |
1. Adadelta 2. Adamax 3. Nadam 4. AMSGrad 5. AdamW 6. QHAdam 7. FTRL 8. YellowFin 9. AggMo 10. Demon |
Adadelta
Adamax
Nadam
AMSGrad
By Amrutha



