


Artëm Sobolev
Research Scientist in Machine Learning
Probability Theory and Bayesian Approach
We want to make predictions about some \( x \)
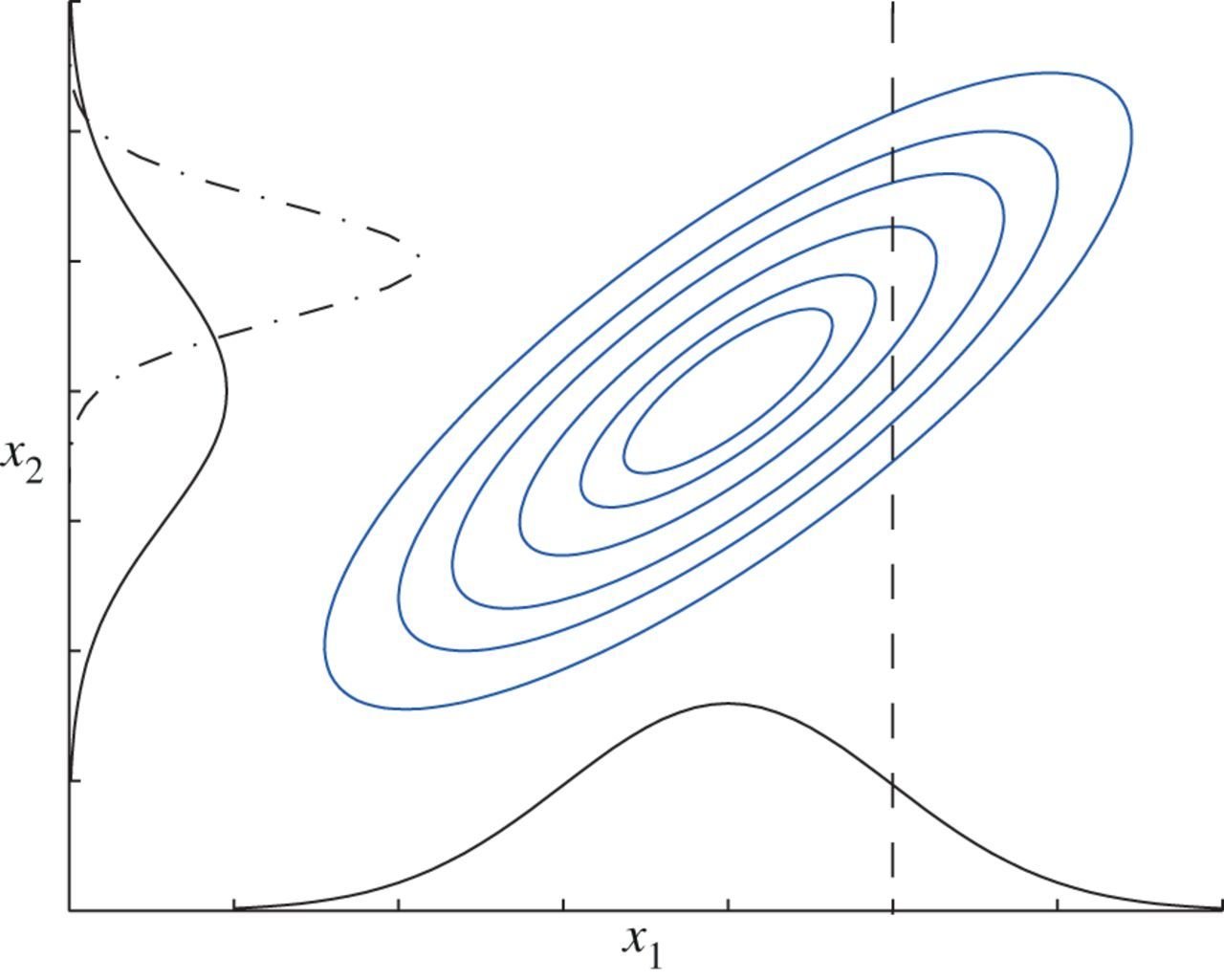
$$ \mathbb{E} X = \mu $$
$$ \text{Cov}(X_i, X_j) = \Sigma_{ij} $$
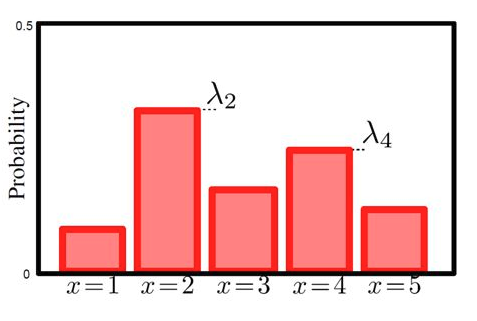
$$ p(X = k) = \pi_k \Leftrightarrow p(x) = \prod_{k=1}^K \pi_k^{[x = k]} $$
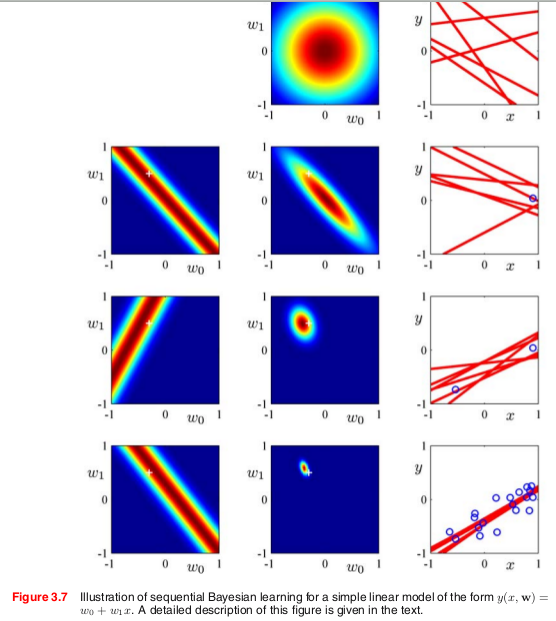
Putting Bayesian into Neural Networks
and Neural Networks in Bayesian
INTRACTABLE
INTRACTABLE
INTRACTABLE
Overcoming the intractability
Preferred Neural Networks
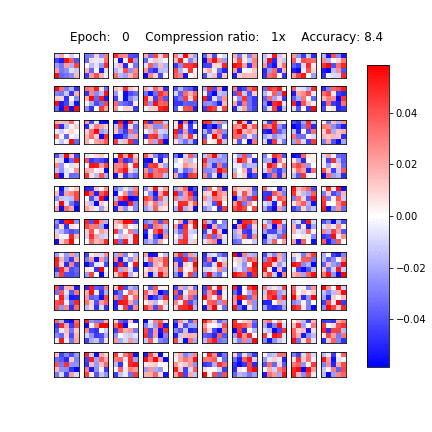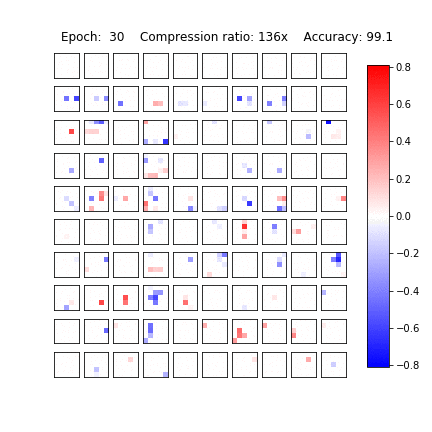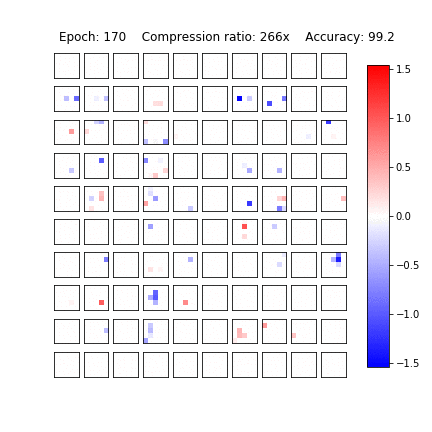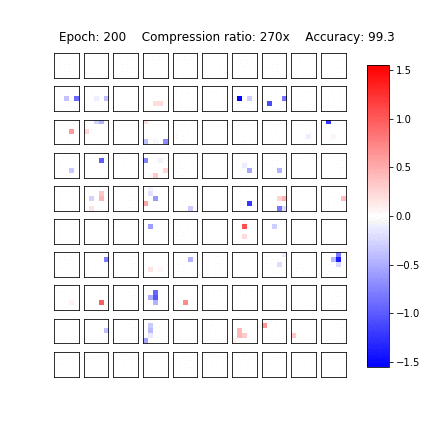
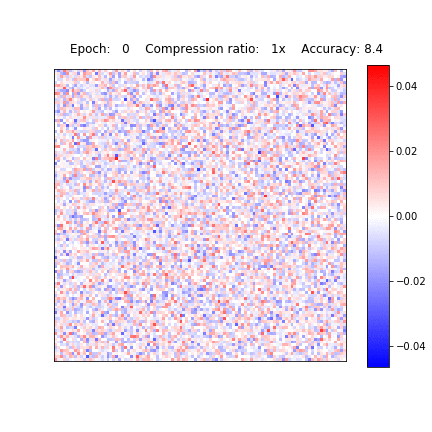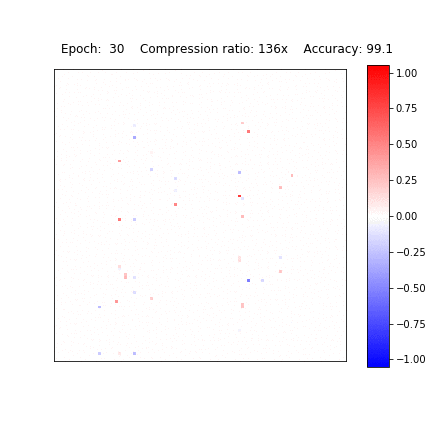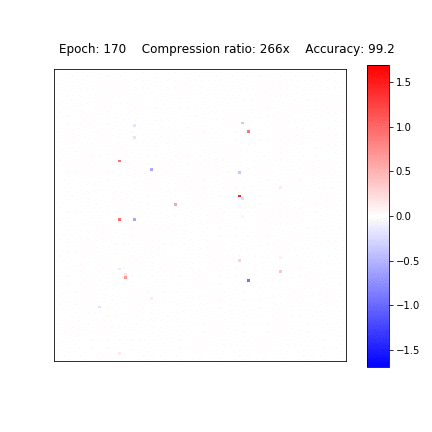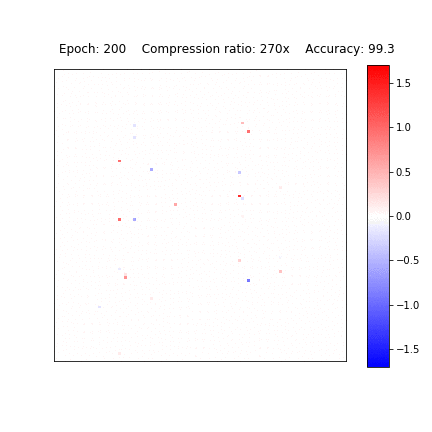
Variational Dropout Sparsifies Deep Neural Networks
D. Molchanov, A. Ashukha, D. Vetrov, ICML 2017
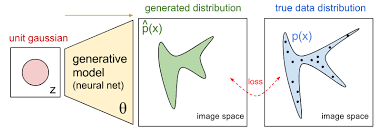
Generating everything out of nothing
Auto-Encoding Variational Bayes
D. P Kingma, M. Welling, ICLR 2013
What this all was for
I sometimes blog about different cutting-edge-like topics:
By Artëm Sobolev
Intro to BDL for a summer school




