Graphics Programming Virtual Meetup


Discord
vk_mini_path_tracer
Chapter 6
Compute Shaders
Link to the tutorial
https://nvpro-samples.github.io/vk_mini_path_tracer/
Source code
https://github.com/nvpro-samples/vk_mini_path_tracer
Shaders
- The code the GPU runs
- Vulkan uses SPIR-V
- Binary format
- Commonly use GLSL or HLSL
- "human readable"
- C-like languages
#version 460
#extension GL_EXT_debug_printf : require
layout(local_size_x = 16, local_size_y = 8, local_size_z = 1) in;
void main()
{
debugPrintfEXT("Hello from invocation (%d, %d)!\n",
gl_GlobalInvocationID.x, gl_GlobalInvocationID.y);
}Shader execution
- GPU's are massively parallel machines
- Characterized as 'SPMD'
- Single Program, Multiple Data
- The GPU may run many hundreds or thousands of 'invocations' at the same time
- How and what does the invocation depends on the shader type
Shader Types
- Organized by which pipeline they run in
- Graphics
- Vertex - Run on each vert in a mesh
- Fragment - "Pixel shading"
- Also: tessellation control, tessellation evaluation, geometry, fragment, task, and mesh
- Compute
- General Purpose computation
- Can control how it gets invoked
- Raytracing
- Ray generation, any hit, callable, closest hit, intersection, and miss
- More work to use, don't necessarily need it
- Graphics
Ray Queries
- Able to execute ray tracing from a compute shader
- Simplify the code by a large margin
- Aren't without tradeoffs:
- Can't 'call' other shaders from a compute shader
- Raytracing Pipelines offer more places for optimal utilization of hardware
Work Groups
- Can be thought of as a division of 3d points of equal size
- Compute shaders are invoked in a '3d' fashion
- In that shaders use these coordinates to determine which array elements are 'theirs'
- Optimal performance means creating work-group sizes that utilize the hardware best
- Different GPU's result in different sizes
- Complex topic, and terminology isn't consistent between API's & hardware
Work Groups Cont'
- Given a 15x13 matrix
- Tile the array with 16x8x1 invocations per work group
- Need 1x2x1 work groups to do everything

Creating a "shader"
- Create a folder called 'shaders'
- Make a new file called 'raytrace.comp.glsl'
- comp for compute
- Add this code
#version 460
layout(local_size_x = 16, local_size_y = 8, local_size_z = 1) in;
void main()
{
}- Get cmake to regenerate & rebuild then run
- Should see 'raytrace.comp.glsl.spv' created
- Use the 'GL_EXT_debug_printf' extension
- Then make the shader print text
- Will print 128 times, one for each invocation
- Need to implement the code to make this shader be executed first
#version 460
#extension GL_EXT_debug_printf : require
layout(local_size_x = 16, local_size_y = 8, local_size_z = 1) in;
void main()
{
debugPrintfEXT("Hello world!");
}"Hello, World!"
How shaders get compiled
- Like CPU compilation, but targets 'SPIR-V'
- Standard Portable Intermediate Representation-V
- GLSL often uses `glslangValidator`
- Drivers then interpret it into ASM specific to a GPU
- Allows GPU's to change ASM every generation but still run the same shader code.
- Contrast to SIMD in CPU's
- Does requires 'just in time' compilation, caching helps reduce this burden
- Can view GPU ASM if desired
- Also can view SPIR-V directly with spirv-dis
But how does it really get compiles?
- Through CMake magic of course!
- Not important for this tutorial
- Basically the following happens:
- CMake looks for glsl files
- The runs glslangValidator on them
file(GLOB_RECURSE GLSL_SOURCE_FILES "shaders/*.glsl")
foreach(GLSL ${GLSL_SOURCE_FILES})
get_filename_component(FILE_NAME ${GLSL} NAME)
_compile_GLSL(${GLSL} "shaders/${FILE_NAME}.spv" GLSL_SOURCES SPV_OUTPUT)
endforeach(GLSL)Now to 'make' the shader
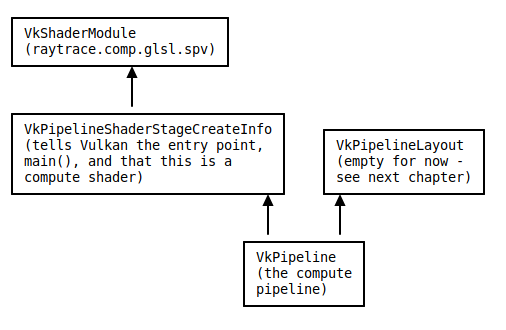
- Need several Vulkan objects
- VkShaderModule
- VkPipelineShaderStageCreateInfo
- VkPipelineLayout
- VkPipeline
- Need two additional header files
- nvh/fileoperations.h
- nvvk/shaders_vk.hpp
#define STB_IMAGE_WRITE_IMPLEMENTATION
#include <fileformats/stb_image_write.h>
#include <nvh/fileoperations.hpp> // For nvh::loadFile
#include <vulkan/vulkan.h> // For the full (not only core) Vulkan API
#define NVVK_ALLOC_DEDICATED
#include <nvvk/allocator_vk.hpp> // For NVVK memory allocators
#include <nvvk/context_vk.hpp>
#include <nvvk/shaders_vk.hpp> // For nvvk::createShaderModule
#include <nvvk/structs_vk.hpp> // For nvvk::makeUpdate main.cpp's header
Enable "Debug Printf"
- Implemented in the validation layers
- Only needed for this chapter
- handy for debugging in the future
deviceInfo.addDeviceExtension(VK_KHR_SHADER_NON_SEMANTIC_INFO_EXTENSION_NAME);
VkValidationFeaturesEXT validationInfo = nvvk::make<VkValidationFeaturesEXT>();
VkValidationFeatureEnableEXT validationFeatureToEnable =
VK_VALIDATION_FEATURE_ENABLE_DEBUG_PRINTF_EXT;
validationInfo.enabledValidationFeatureCount = 1;
validationInfo.pEnabledValidationFeatures = &validationFeatureToEnable;
deviceInfo.instanceCreateInfoExt = &validationInfo;
#ifdef _WIN32
_putenv_s("DEBUG_PRINTF_TO_STDOUT", "1");
#else // If not _WIN32
putenv("DEBUG_PRINTF_TO_STDOUT=1");
#endif // _WIN32- Next to render_width and render_height
- For convenience, so we don't have magic numbers
static const uint32_t workgroup_width = 16;
static const uint32_t workgroup_height = 8;Add two workgroup size constants
- Find the SPIR-V file
- Load it into memory
- Give it to the driver + other info
- Get a VkShaderModule in return
std::vector<std::string> searchPaths =
{ PROJECT_ABSDIRECTORY,
PROJECT_ABSDIRECTORY "../",
PROJECT_RELDIRECTORY,
PROJECT_RELDIRECTORY "../",
PROJECT_NAME};
// used later for obj loading
VkShaderModule rayTraceModule =
nvvk::createShaderModule(context,
nvh::loadFile("shaders/raytrace.comp.glsl.spv", true, searchPaths));Lets create a VkShaderModule
- spir-v files can have more than one 'entry point'
- Need to tell it to use "main"
- Need to say its a compute shader
VkPipelineShaderStageCreateInfo shaderStageCreateInfo
= nvvk::make<VkPipelineShaderStageCreateInfo>();
shaderStageCreateInfo.stage = VK_SHADER_STAGE_COMPUTE_BIT;
shaderStageCreateInfo.module = rayTraceModule;
shaderStageCreateInfo.pName = "main";Lets create a VkPipelineShaderStageCreateInfo!
- VkPipelineLayout's describe the inputs for the shader
- We have no inputs currently
- So there is nothing to lay out!
// For the moment, create an empty pipeline layout. You can
// ignore this code for now; we'll replace it in the next chapter.
VkPipelineLayoutCreateInfo pipelineLayoutCreateInfo =
nvvk::make<VkPipelineLayoutCreateInfo>();
pipelineLayoutCreateInfo.setLayoutCount = 0;
pipelineLayoutCreateInfo.pushConstantRangeCount = 0;
VkPipelineLayout pipelineLayout;
NVVK_CHECK(vkCreatePipelineLayout(context,
&pipelineLayoutCreateInfo, VK_NULL_HANDLE, &pipelineLayout));Empty VkPipelineLayout
- Very simple struct
- Compared to graphics pipelines which have about 15 members
typedef struct VkComputePipelineCreateInfo {
VkStructureType sType;
const void* pNext;
// Lets one modify how the pipeline works
VkPipelineCreateFlags flags;
VkPipelineShaderStageCreateInfo stage;
VkPipelineLayout layout;
// Used for deriving compute pipelines
// - we won't use this in this tutorial.
VkPipeline basePipelineHandle;
int32_t basePipelineIndex;
} VkComputePipelineCreateInfo;VkComputePipelineCreateInfo description
- Plug the previous structures into this one
- You can create multiple pipelines at once
- We only need one
VkComputePipelineCreateInfo pipelineCreateInfo
= nvvk::make<VkComputePipelineCreateInfo>();
pipelineCreateInfo.stage = shaderStageCreateInfo;
pipelineCreateInfo.layout = pipelineLayout;
VkPipeline computePipeline;
NVVK_CHECK(vkCreateComputePipelines(context, // Device
VK_NULL_HANDLE, // Pipeline cache (uses default)
1, &pipelineCreateInfo, // Compute pipeline create info
VK_NULL_HANDLE, // Allocator (uses default)
&computePipeline)); // OutputCreating the VkPipeline
- Remove the `fillValue` & vkCmdFillBuffer
- Bind the Compute Pipeline
- Dispatch the shader with a specified number of workgroups
- The three parameters are dimensions X, Y, and Z
// Bind the compute shader pipeline
vkCmdBindPipeline(cmdBuffer,
VK_PIPELINE_BIND_POINT_COMPUTE, computePipeline);
// Run the compute shader with one workgroup for now
vkCmdDispatch(cmdBuffer, 1, 1, 1);'Dispatching' the Compute Pipeline
- No longer using transfers, but a direct write
- transfer-to-host -> shader-to-host
- Replace srcAccessMask with
VK_ACCESS_SHADER_WRITE_BIT
- Replace srcStageMask with
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT
VkMemoryBarrier memoryBarrier = nvvk::make<VkMemoryBarrier>();
memoryBarrier.srcAccessMask = VK_ACCESS_SHADER_WRITE_BIT; // Make shader writes
memoryBarrier.dstAccessMask = VK_ACCESS_HOST_READ_BIT; // Readable by the CPU
vkCmdPipelineBarrier(cmdBuffer, // The command buffer
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT, // From the compute shader
VK_PIPELINE_STAGE_HOST_BIT, // To the CPU
0, // No special flags
1, &memoryBarrier, // An array of memory barriers
0, nullptr, 0, nullptr); // No other barriersNeed to update the barrier
- Destroy the following before you destroy the device
- VkPipeline
- VkPipelineLayout
- VkShaderModule
vkDestroyPipeline(context, computePipeline, nullptr);
vkDestroyShaderModule(context, rayTraceModule, nullptr);
vkDestroyPipelineLayout(context, pipelineLayout, nullptr);Lastly: Cleanup
Should see the following
INFO: UNASSIGNED-DEBUG-PRINTF
--> Validation Information: [ UNASSIGNED-DEBUG-PRINTF ] Object 0: handle = 0x1cb865172d8, type = VK_OBJECT_TYPE_DEVICE; | MessageID = 0x92394c89 | Hello world!
- Query a shader invocations 'coordinates'
- Print that info
- Log is unlikely to be in order
debugPrintfEXT("Hello from invocation (%d, %d)!\n",
gl_GlobalInvocationID.x, gl_GlobalInvocationID.y);Lets print the invocation indices!
INFO: UNASSIGNED-DEBUG-PRINTF
--> Validation Information: [ UNASSIGNED-DEBUG-PRINTF ] Object 0: handle = 0x283f9fc4c48, type = VK_OBJECT_TYPE_DEVICE; | MessageID = 0x92394c89 | Hello from invocation (0, 0)!
Thank you!
Questions?
Next week: Descriptors
Graphics Programming Virtual Meetup
Vulkan Mini Path Tracer Chapter 6
By Charles Giessen


