









Kevin Song
I'm a student at UT (that's the one in Austin) who studies things.
(Almost) everything we've discussed so far occurs in main memory (RAM):
RAM is nice! It's relatively speedy, and you can store a lot of stuff in there.
....but it's got a major drawback.
RAM is not persistent! If the power gets cut off, all data in main memory is lost.
Imagine having not only to reload chrome if you run out of power on your laptop, but also having to reinstall the entire operating system.
To solve this problem, we introduce stable storage (disks). These devices retain data even after the power to them has been shutoff (i.e. they are persistent).
Now we can turn off the computer without losing important data!
But now we have to deal with communication between the CPU and disk, which is very different from communication with main memory!
(Almost) everything we've discussed so far occurs in main memory (RAM):
Now we've added persistent storage which is large, very slow, and order-dependent.
But we can use lots of common systems design tricks to make sure this doesn't affect us too badly!
Remember: disk access is slow !
Unfortunately, we cannot always avoid paying the disk access cost (if we could, we wouldn't need the disk!)
Read account A from disk
Read account B from disk
Add $100 to account A
Subtract $100 from account B
Write new account B to disk
Write new account A to diskWe mention this here for completeness, but we won't discuss this idea in detail until next lecture.
If our system crashes here, we've subtracted $100 from account B, but haven't added it to account A. We've destroyed $100.
The filesystem consists of raw block numbers. User programs are responsible for keeping track of which blocks they use, and for making sure they don't overwrite other program's blocks.
For example, the following filesystem is easy to implement, and is as fast and as consistent as the user chooses to make it:
A file is named by the a hash of its contents. All files are in the root directory. Filenames cannot be changed.
How fast is this design? How many disk accesses do we need in order to perform common operations?
Will this design cause application programmers to tear their hair out? Does it require some deep knowledge of the system or is that abstracted away?
Can this design become corrupted if the computer fails (e.g. through sudden power loss), or if small pieces of data are damaged? Can it be recovered? How fast is the recovery procedure?
Today, we mostly focus on speed and usability. We'll talk about reliability next time!
Sector: Smallest unit that the drive can read, usually 512 bytes large.
Blocks are the smallest unit which the software (usually) accesses the disk at, which is an integer number of contiguous sectors.
| Memory | Disk | |
|---|---|---|
| Smallest Unit of Data | bit | bit |
| Smallest unit addressable by hardware | byte | sector |
| Smallest unit usually used by software | machine word | block |
Sector 0
Sector 1
Sector 2
Block 1
Block 2
Metadata: the file header contains information that the operating system cares about: where the file is on the disk, and attributes of the file.
Metadata for all files is stored at a fixed location (something known by the OS) so that they can be accessed easily.
Data is the stuff the user actually cares about. It consists of sectors of data placed on disk.
Examples: file owner, file size, file permissions, creation time, last modified time, location of data blocks.
META
DATA
DATA
Logical layout of a file (not necessarily how it's placed on disk!)
META
DATA
DATA
Logical layout of a file (not necessarily how it's placed on disk!)
Assume we already know where the metadata is.
What sorts of files do we need to care about? Are most files large or small? Is most storage space used by large or small files? Do we need to worry about unusual files?
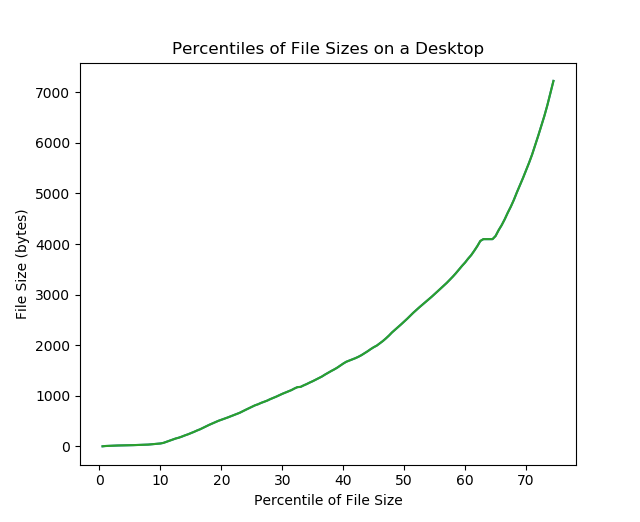
To answer these questions illustratively, I listed all the files on my desktop and ordered them by size, then plotted. The plot on the next slide shows percentile of file size. E.g. to find out the median file size, find the 50 point on the x-axis.
These systems are mine, but the trends we see tend to be true across a wide variety of systems.
Most files on a computer are small!
So we should have good support for lots of small files!
The user probably cares about accessing large files (they might be saved videos, or databases), so large file access shouldn't be too slow!
Most disk space is used by large files.
How many disk reads do we need to access a particular block?
CPU
We start knowing the block # of the appropriate file header
We have enough space in memory to store two blocks worth of data
Everything else has to be requested from disk.
The request must be in the form of a block#. E.g. we can request "read block 27", but we cannot request "read next block" or "read next file"
This is all just a game. In an actual system, you'll have millions of spots in memory to store billions of pages. This makes it very difficult to answer questions like "is this algorithm good for ____" because there's so many pieces to keep track of.
By simplifying down to two spots in memory, we make easy to immediately see the impacts that different file layouts have on the access speed. This is not terribly realistic, but you can repeat these exercises with more memory slots to see what things would look like in a large system.
How many disk reads do we need to access a particular block?
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
Note: Animation slides have been deleted in this version of the slides--see in-class version for a step-by-step breakdown.
How many disk reads do we need to access a particular block?
CPU
How many disk reads to access the first data block?
(We always start with the block# of the file header)
How many disk reads do we need to access a particular block?
Let's say I want to read only the third block.
The random access trick only works because allocation is contiguous: we KNOW that if the first block is at N, the third block is at N+2.
In later schemes, we'll see that this doesn't work nearly as well--in fact, contiguous allocation has the best performance for both sequential and random access. It's the other properties of this design that are problematic.
This method is very simple (this is good!)
How fast is sequential access? Great.
How fast is random access? Great.
What if we want to grow a file? If another file is in the way, we have to move and reallocate.
How bad is fragmentation? Lots of external.
The observant reader might wonder why we keep a pointer to the last block. After all, we don't have reverse-pointers (the list is singly-linked), so it can't help us traverse the linked list. It seems that the only thing that it helps us do is get the last block of the file.
In fact, this is exactly what we want! When growing the file, we need to get the last block of the file so that we can link another block to the end of it--the last-block pointer lets us grab that block quickly instead of having to scan the entire list.
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
CPU
How many disk reads to access the second block if we already have read the first block?
CPU
How many disk reads to access the third block without having read anything?
CPU
How many disk reads to access the third block?
(We always start with the block# of the file header)
How fast is sequential access? Is it always good? Generally good.
How bad is fragmentation? Only internal, maximum of 1 block.
What if we want to grow the file? No problems
How fast is random access? Functionally sequential access to the Nth block.
What happens if a disk block becomes corrupted? We can no longer access subsequent blocks.
File Allocation Table (FAT)
Started with MS-DOS (Microsoft, late 70s)
Descendants include FATX and exFAT
A very simple filesystem which is used in lots of locations, like optical media (DVDs), flash drives, and the Xbox console series.
With the appropriate resources, you could probably implement a program to read a FAT filesystem in a few weeks.
I really do mean "you" and not "some hypothetical programmer." Implementing a FAT filesystem is a surprisingly common project in undergraduate courses across the US.
Simple!
Universal: every OS supports it (probably due to that first point)
File header points to each data block directly (that's it!)
How fast is sequential access? How about random access?
How bad is fragmentation?
What if we want to grow the file?
Does this support small files? How about large files?
What if other file metadata takes up most of the space in the header?
One possible solution for large files is to allow file headers to be variable-sized.
This is a bad idea! With fixed-size file headers, it's possible to use indexing arithmetic to get the block of the current header, e.g. header 27 is located at FILE_HEADERS_START + sizeof(header) * 27.
If you decide to switch to variable sized headers, you have to scan the file headers from the beginning every time you want to access a header, e.g. accessing header 27 will take at least 27 disk accesses.
Disk access is expensive. Requiring 1 million disk accesses to even find out where the 1 million-th file is located is going to be slow.
Or: All About Directories
We know how to get the data associated with a file if we know where its metadata (file header) is. We also know how to identify file headers (by their index in the file header array).
To edit your shell configuration, open file 229601, unless you have Microsoft Word installed, in which case you need to edit file 92135113
To edit your shell configuration, open file 229601, unless you have Microsoft Word installed, in which case you need to edit file 92135113
Use one name space for the entire disk.
| File Name | inode number |
|---|---|
| .user1_bashrc | 27 |
| .user2_bashrc | 30 |
| firefox | 3392 |
| .bob_bashrc | 7 |
Early computers, which were single-user and had very little stable storage, used variants on this scheme. They were quickly replaced.
(Yeah, it's not that great of an improvement)
| File Name | inode number |
|---|---|
| .bashrc |
30 |
| Documents | 173 |
| File Name | inode number |
|---|---|
| .bashrc | 391 |
| failed_projects | 8930 |
| zsh |
3392 |
Note: the inumber (the index of the inode in the inode array, written "i#") in a directory entry may refer to another directory!
The OS keeps a special bit in the inode to determine if the file is a directory or a normal file.
There is a special root directory (usually inumber 0, 1, or 2).
| i# | Filename |
|---|---|
| 3226 | .bashrc |
| 251 | Documents |
| 7193 | pintos |
| 2086 | todo.txt |
| 1793 | Pictures |
2B
Example directory with 16B entries
14B
To find the data blocks of a file, we need to know where its inode (file header) is.
To find an inode (file header), we need to know its inumber.
To find a file's inumber, read the directory that contains the file.
The directory is just a file, so we need to find its data blocks.
There is actually not an infinite loop here.
The data blocks of the file at the beginning and the data blocks of the file at the end are *not* actually from the same file! One is the file we're trying to read, and one is the directory containing that file.
However, at some point, we're still going to need to have a way to find a file without needing to read its directory, else we will never be able to look up data blocks.
We can break the loop here by agreeing on a fixed inumber for a special directory.
It should be possible to reach every other file in the filesystem from this directory.
On most UNIX systems, the root directory is inumber 2
int config_fd = open("/home/user1/.bashrc", O_RDONLY);int config_fd = open("/home/user1/.bashrc", O_RDONLY);CPU
But we do have....what?
CPU
| 273 | Documents |
| 94 | .ssh |
| 2201 | .bash_profile |
| 23 | .bashrc |
| 61 | .vimrc |
int config_fd = open("/home/user1/.bashrc", O_RDONLY);B 537
We didn't even try to read anything out of the file--that was just an open() call!
Maintain the notion of a per-process current working directory.
Users can specify files relative to the CWD
We can't avoid this disk access...
OS caches the data blocks of CWD in the disk cache (or in the PCB of the process) to avoid having to do repeated lookups.
We now know how to do the following:
OS job: illusionist. Hide this complexity behind an interface.
Armed with what we know about files and directories, let's take a look at the classic UNIX Filesystem API.
But before we dive into it, we need to look at one last piece of the API and how it behaves...
Think about the following scenario:
Process A should get bytes 5-9 of the file
Process B should get bytes 0-4 of the file
"Open /var/logs/installer.log"
File
Descriptor
Open File Tracker
On-Disk File Tracker
On-Disk Data
User Memory
Per-Process Memory
Global System Memory
On Disk
The user gets everything to the left of the thick line and interacts with it via system calls (since they can't directly edit system memory). The OS is responsible for updating things to the right of the line.
+syscall
struct file
struct inode
Creates in-memory data structures used to manage open files. Returns file descriptor to the caller.
open(const char* name, enum mode);On open(), the OS needs to:
struct file {
struct file_header* metadata;
file_offset pos;
int file_mode; //e.g. "r" or "rw"
};File
Descriptor
On-Disk Data
User Memory
Per-Process Memory
Global System Memory
On Disk
struct file
struct inode
close(int fd);On close(), the OS needs to:
File
Descriptor
On-Disk Data
User Memory
Per-Process Memory
Global System Memory
On Disk
struct file
struct inode
read(int fd, void* buffer, size_t num_bytes)On read(), the OS needs to:
File
Descriptor
On-Disk Data
User Memory
Per-Process Memory
Global System Memory
On Disk
struct file
struct inode
Creates a new file with some metatdata and a name.
On create(), the OS will:
create(const char* filename);File
Descriptor
On-Disk Data
User Memory
Per-Process Memory
Global System Memory
On Disk
struct file
struct inode
Creates a hard link--a user-friendly name for some underlying file.
On link(), the OS will:
link(const char* old_name, const char* new_name);This new name points to the same underlying file!
File
Descriptor
On-Disk Data
User Memory
Per-Process Memory
Global System Memory
On Disk
struct file
struct inode
Removes an existing hard link.
To delete() a file, the OS needs to:
unlink(const char* name);The OS decrements the number of links in the file metadata. If the link count is zero after unlink, the OS can delete the file and all its resources.
File
Descriptor
On-Disk Data
User Memory
Per-Process Memory
Global System Memory
On Disk
struct file
struct inode
A. Yes, Yes
B. Yes, No
C. No, Yes
D. No, No
Without persistent storage, computers are very annoying to use.
Persistent storage requires a different approach to organizing and storing data, due to differences in its behavior (speed, resilience, request ordering). This leads naturally to the idea of a file system.
When designing filesystems, we care about three properties:
We should use these three properties to guide our design choices.
Use of the filesystem involves the filesystem API, in-memory bookkeeping structures, and the structure of data on disk. All three need to be considered when designing a filesystem.
By Kevin Song
This is the text-heavy version of the 1HR filesystem fundamentals lecture. Fragment-free and with extra text to explain imagery.



