

cirquit
PhD student with a focus on machine learning, distributed systems and functional programming.
Gliederung
Problemstellung
Gegeben: Punktemenge , wobei
Gesucht: Teilmenge von Punkten, die von keinem anderen Punkt
dominiert werden
Problemstellung
dominiert , g.d.w.
das bedeutet: ist bezüglich aller Eigenschaften mindestens "so gut" wie
Problemstellung
Wir suchen also Punkte, die optimal sind bezüglich der Kombination ihrer Eigenschaften
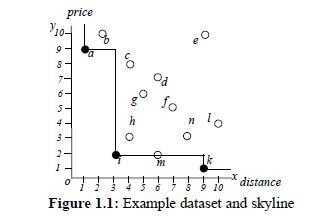
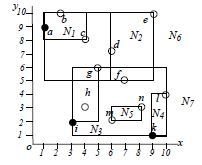
Beispiel
Liste von Hotels (Punkte) a,...,n mit 2 Eigenschaften
(Dimensionen) von Interesse
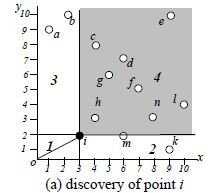
Nearest Neighbor (NN)
Nearest Neighbor (NN)
Nearest Neighbor (NN)
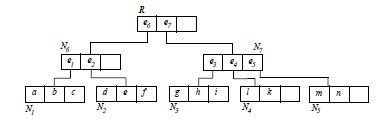
Problem für höhere Dimensionen (d>2): überlappende Partitionen redundante Zugriffe
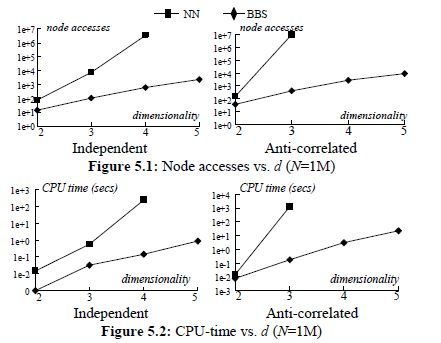
Anzahl an Knoten-Zugriffen:
Verbesserung durch...
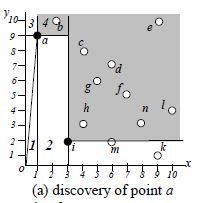
Branch and Bound Skyline Algorithmus (BBS)
Branch and Bound Skyline Algorithmus
Idee: Teile Raum in MBRs (Minimum Bounding Rectangles) auf und prune Bereiche, die von einem Skyline-Punkt dominiert werden disjunkte Partitionierung
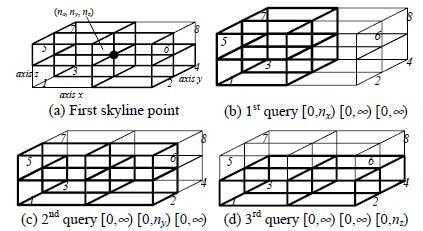
Branch and Bound Skyline Algorithmus
Branch and Bound Skyline Algorithmus
action
heap contents
S
Branch and Bound Skyline Algorithmus
Branch and Bound Skyline Algorithmus
Anzahl an Knoten-Zugriffen auf Level i
Wahrscheinlichkeit, dass
für einen Knoten auf Level i
Branch and Bound Skyline Algorithmus
Anzahl an Knoten-Zugriffen auf Level i
Wahrscheinlichkeit, dass
für einen Knoten auf Level i
Anzahl an Knoten auf Level i (f ist durchschnittliche Knotenkapazität)
Dann ist
und
Branch and Bound Skyline Algorithmus und Nearest Neighbor im Vergleich
Bewertung
By cirquit




