
Preston Parry
Data Scientist, Machine Learning Engineer, addicted cyclist and rock climber
image credit: mlwave.com
image credit: mlwave.com
image credit: mathworks.com
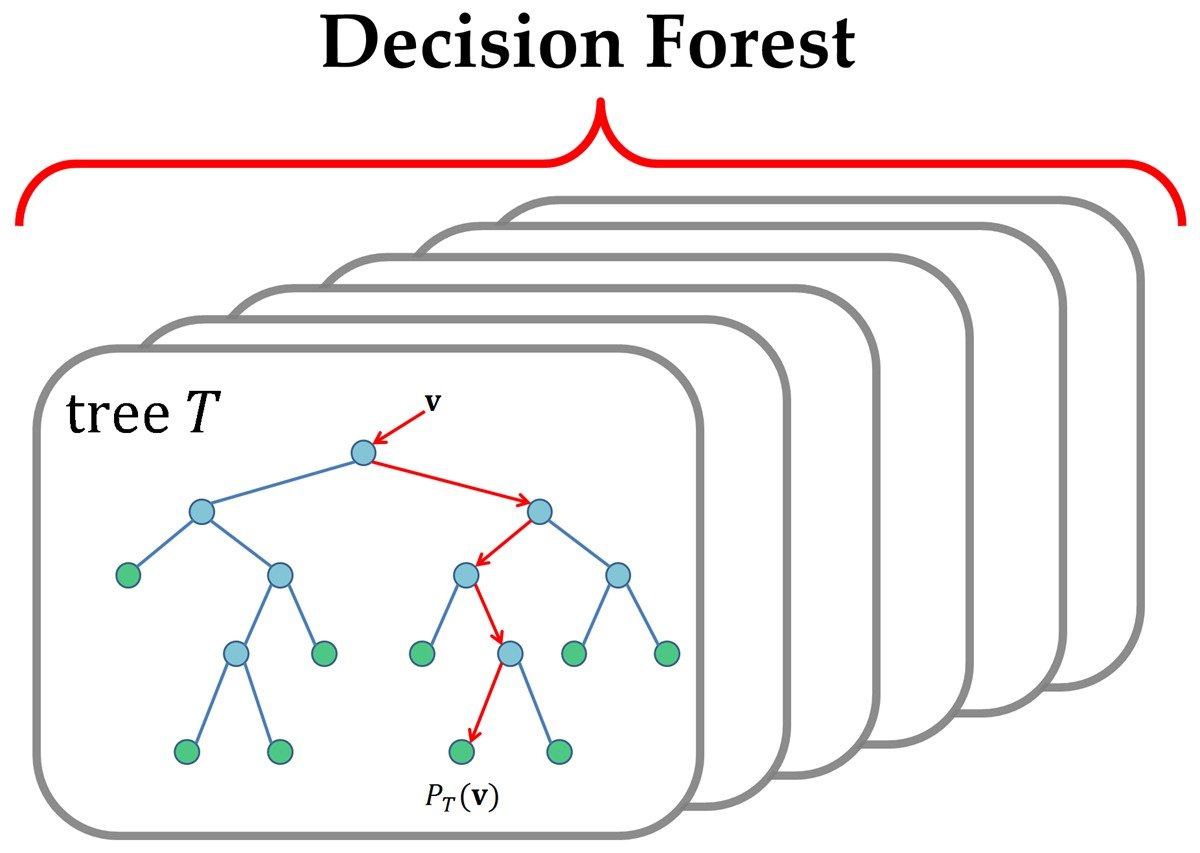
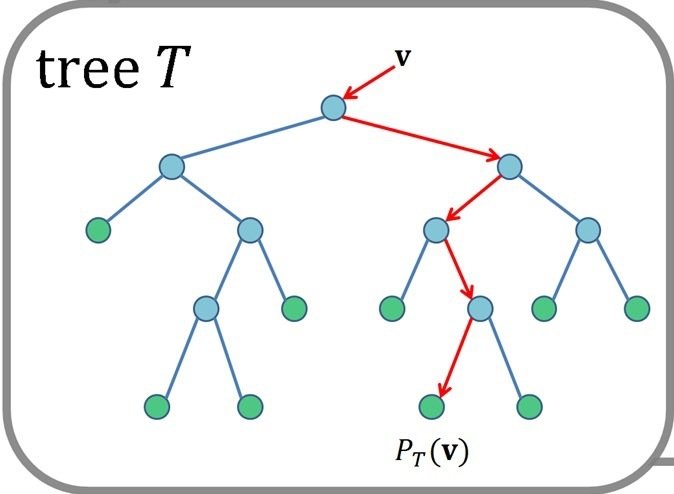
How Deep?
How Many Ways to Split?
Right now these are all splitting two different ways
How Many Trees?
https://github.com/ClimbsRocks/machineJS
By Preston Parry
What goes into finding your ideal machine learning algorithm?




