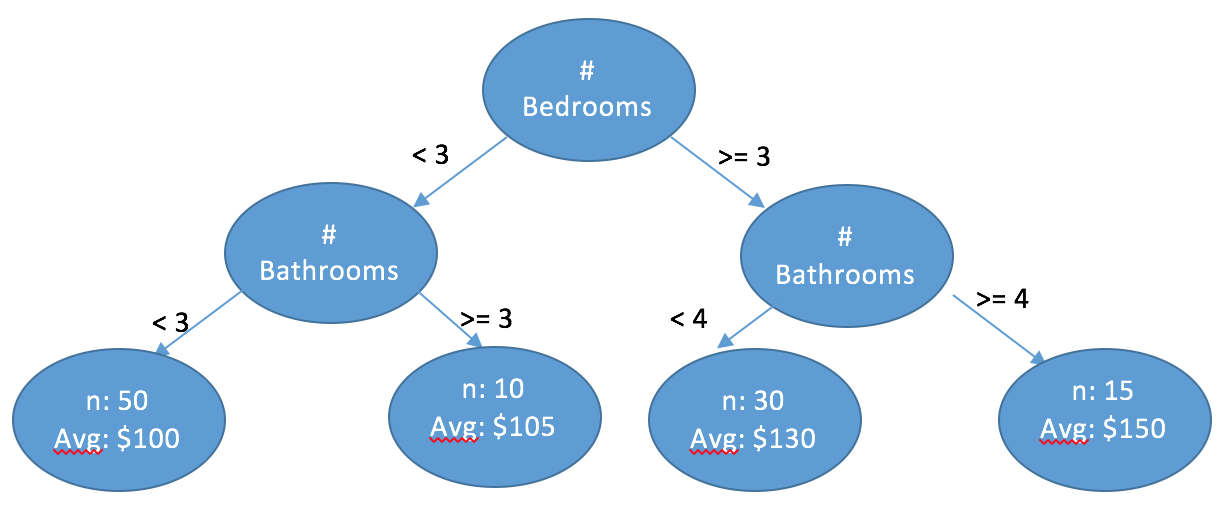
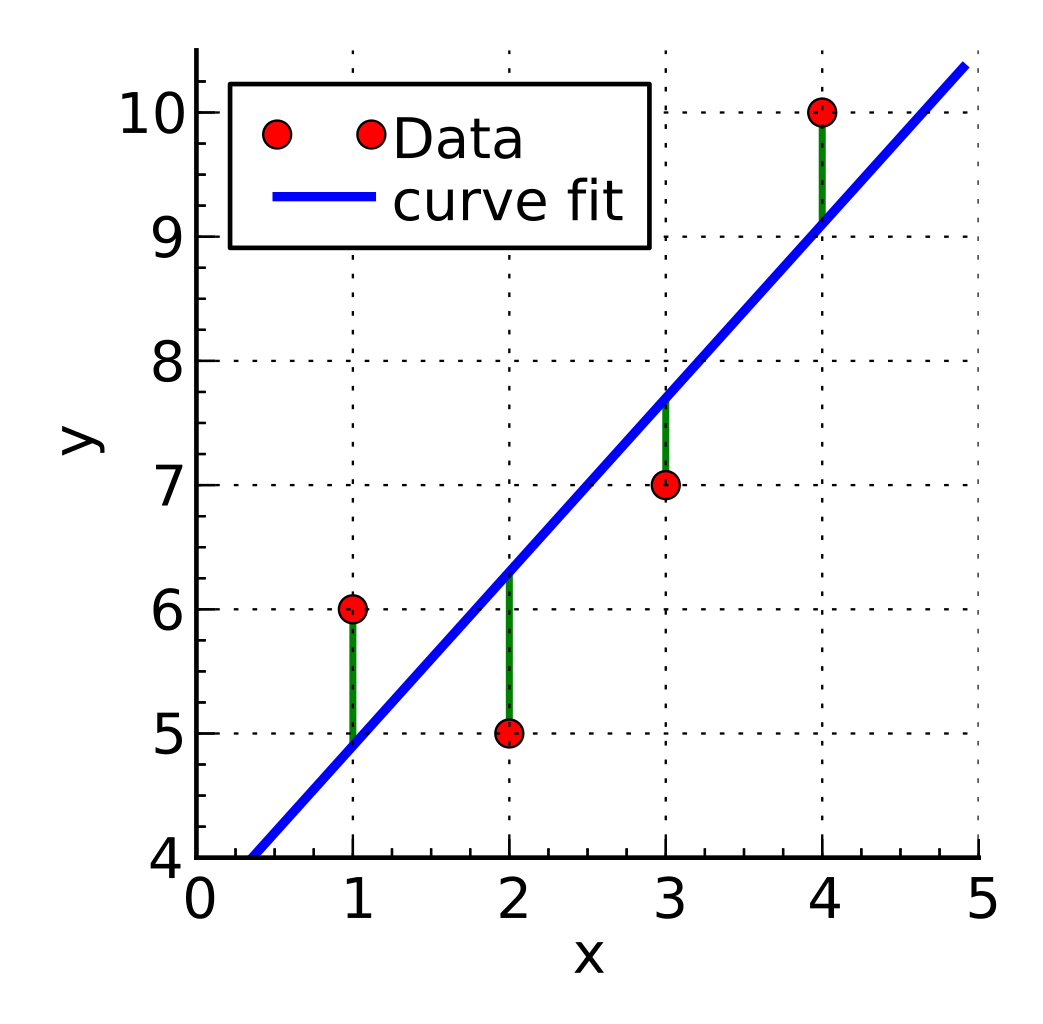
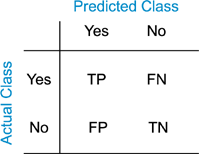
But I wanna know more!! What happens in there?
By Preston Parry
Data Scientist, Machine Learning Engineer, addicted cyclist and rock climber