

Daniel Himmelstein
Head of Data Integration at Related Sciences. Digital craftsman of the biodata revolution.
What does Project Cognoma do?
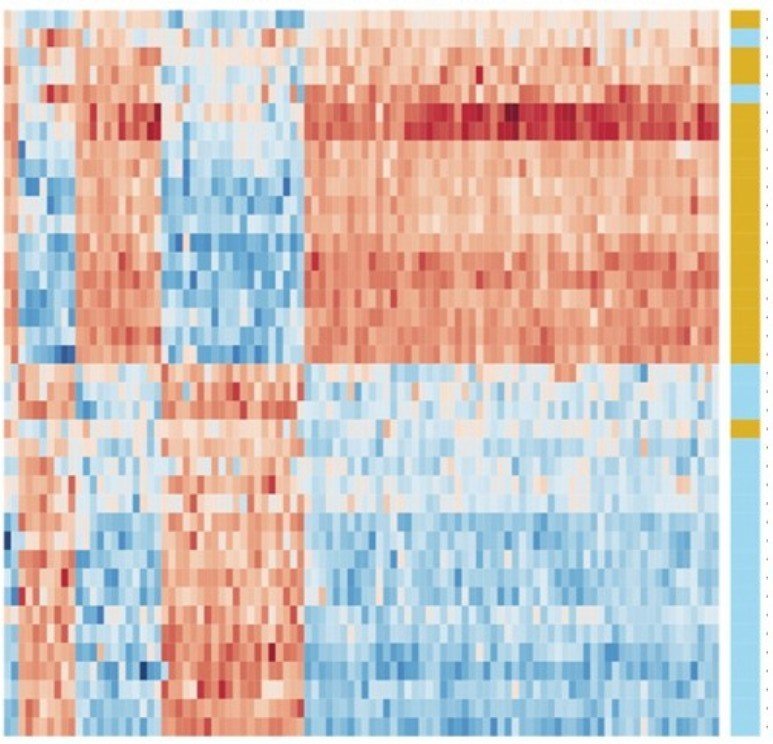
Image derived from https://doi.org/bmfx (CC BY)
genes / features / predictors / x
tumors / samples / observations
mutation / status / outcome / response /
y
Goal: Find "Hidden Responders"
- Pathology samples
- Cell lines
- PDX Models
Cares about classifier performance:
Time + $$$$
Project Cognoma:
Goals
Current Progress on GitHub
Structure of this Datathon
Tonight: Breakout Session
Data Group
Machine Learning Group
Backend Group
Frontend Group
Design Group
Community & Management
Happy Hacking!
See these slides at:
https://slides.com/dhimmel/cognomathon
By Daniel Himmelstein
Outline and tasks for the Cognoma Datathon Meetup on July 12, 2016 located at Industrious in Philadelphia. This presentation is released under CC0 unless otherwise noted.




