














Danielle Navarro
I am a computational cognitive scientist at the University of New South Wales. My research focuses on human concept learning, reasoning and decision making.
11 June 2018, ALG meeting, Katoomba
Products don't stay on sale forever
Possible romantic partners move on
Houses go off the market
Images via pixabay
Images via pixabay
RSVP now to attend party later
Study now for a career later
Show up to the first date to get invited on a second
Images via unsplash
Pursuing too many options consumes time, effort and other scarce resources
The opportunity cost for maintaining poor options can be substantial
Yet... pursuing too few is risky... What if the world changes? What if your needs change?
"doors" problems
image source: flaticon
M1
M2
M3
M4
lose $5
win $2
lose $1
lose $1
win $2
lose $3
I've not used these machines recently, and someone else has taken them
I've concentrated recent bets on these machines
win $2
win $2
lose $5
1
2
3
4
5
6
7
8
chosen
viable option not chosen
someone takes the machine
someone takes the machine
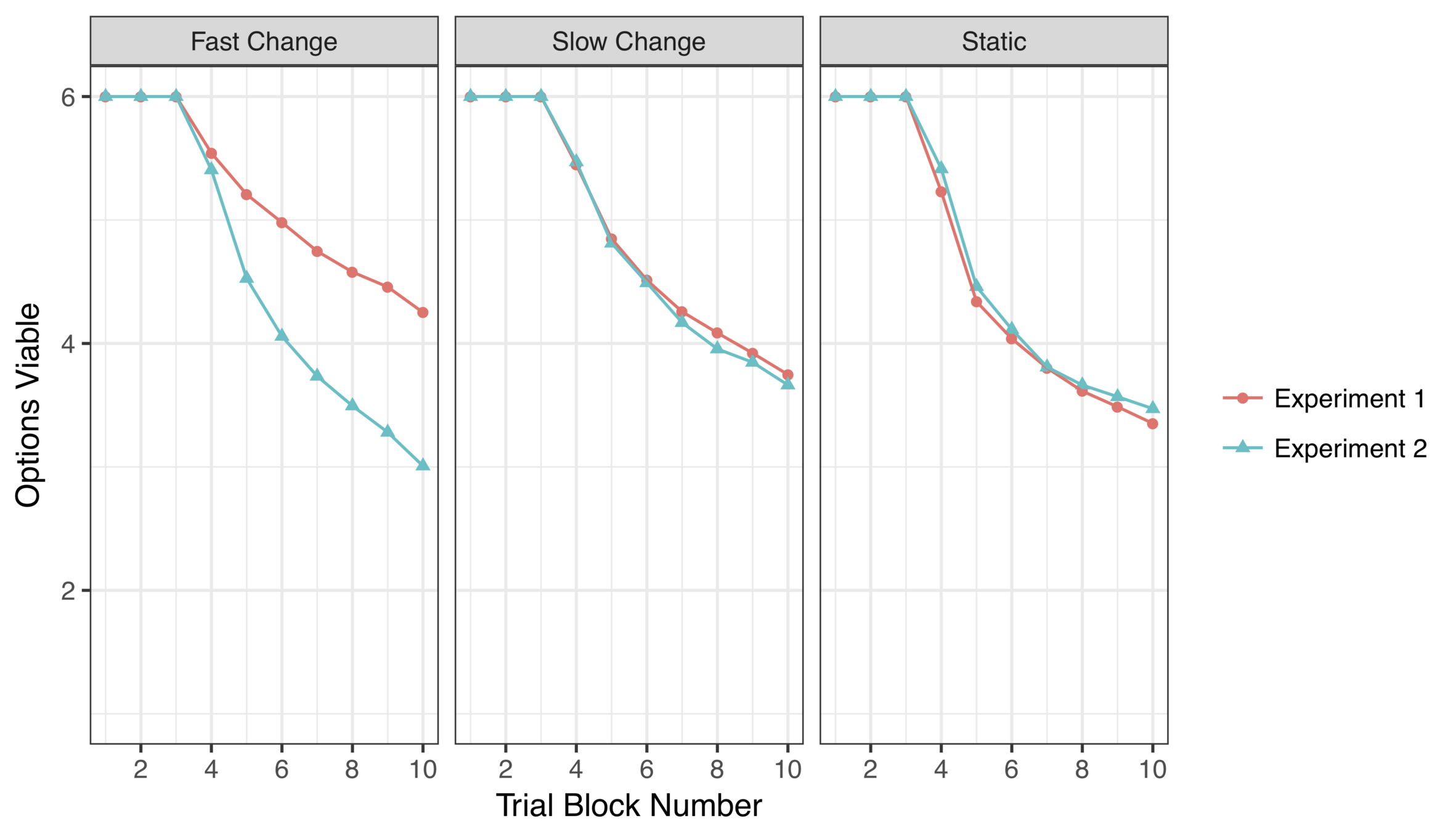
~ 3-4 options retained
(consistent with Ejova et al 2009)
(an unapologetically exploratory analysis!)
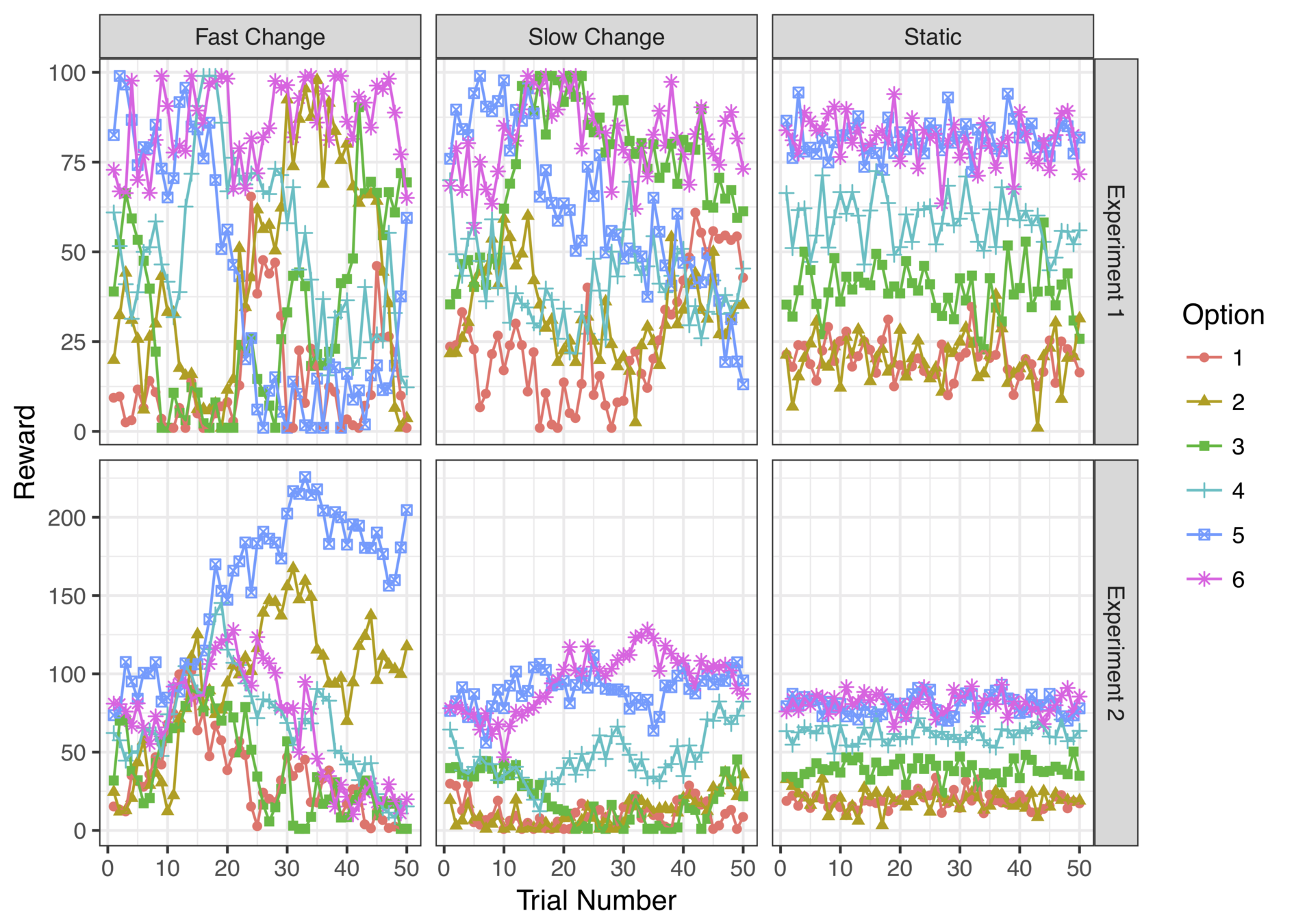
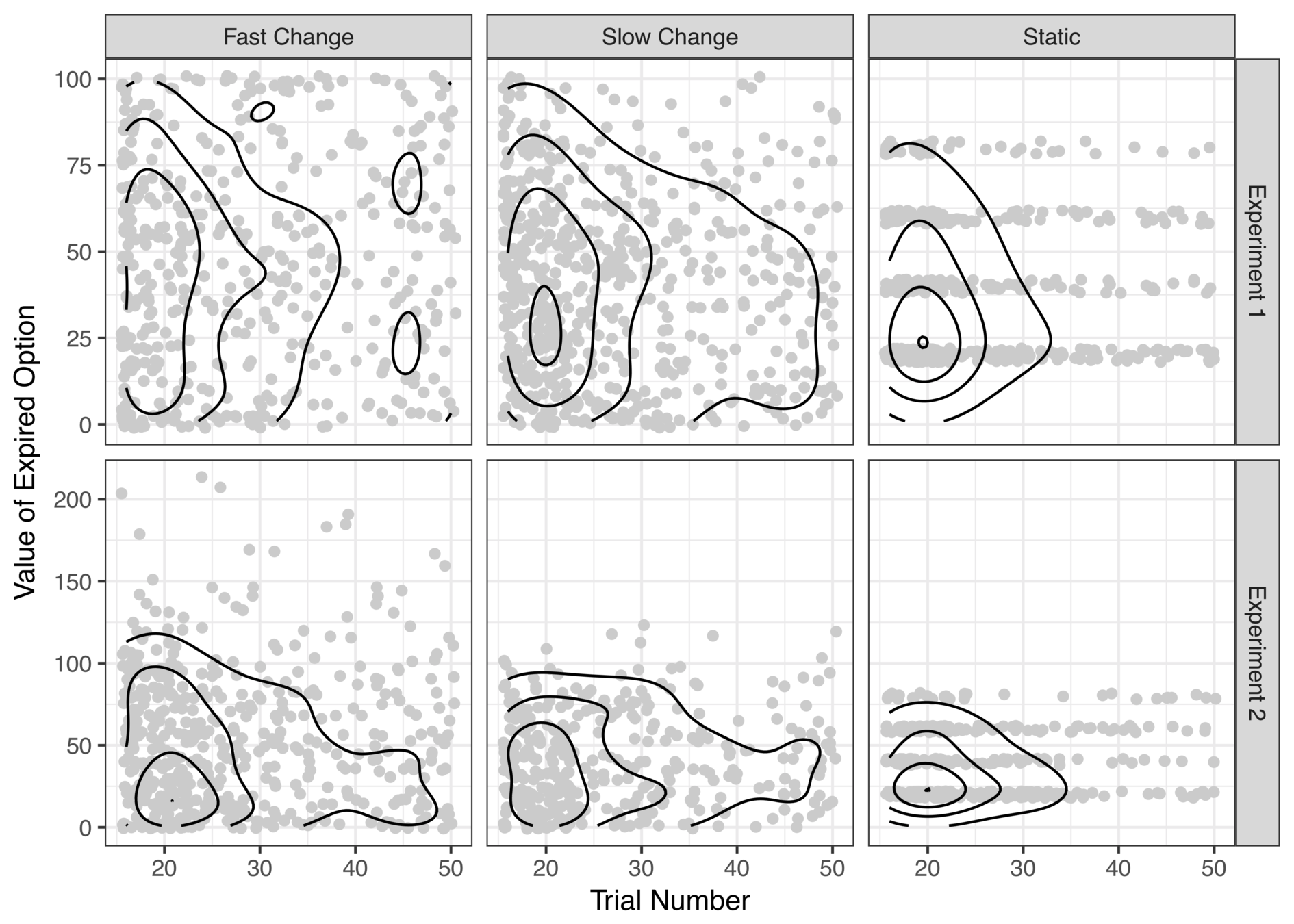
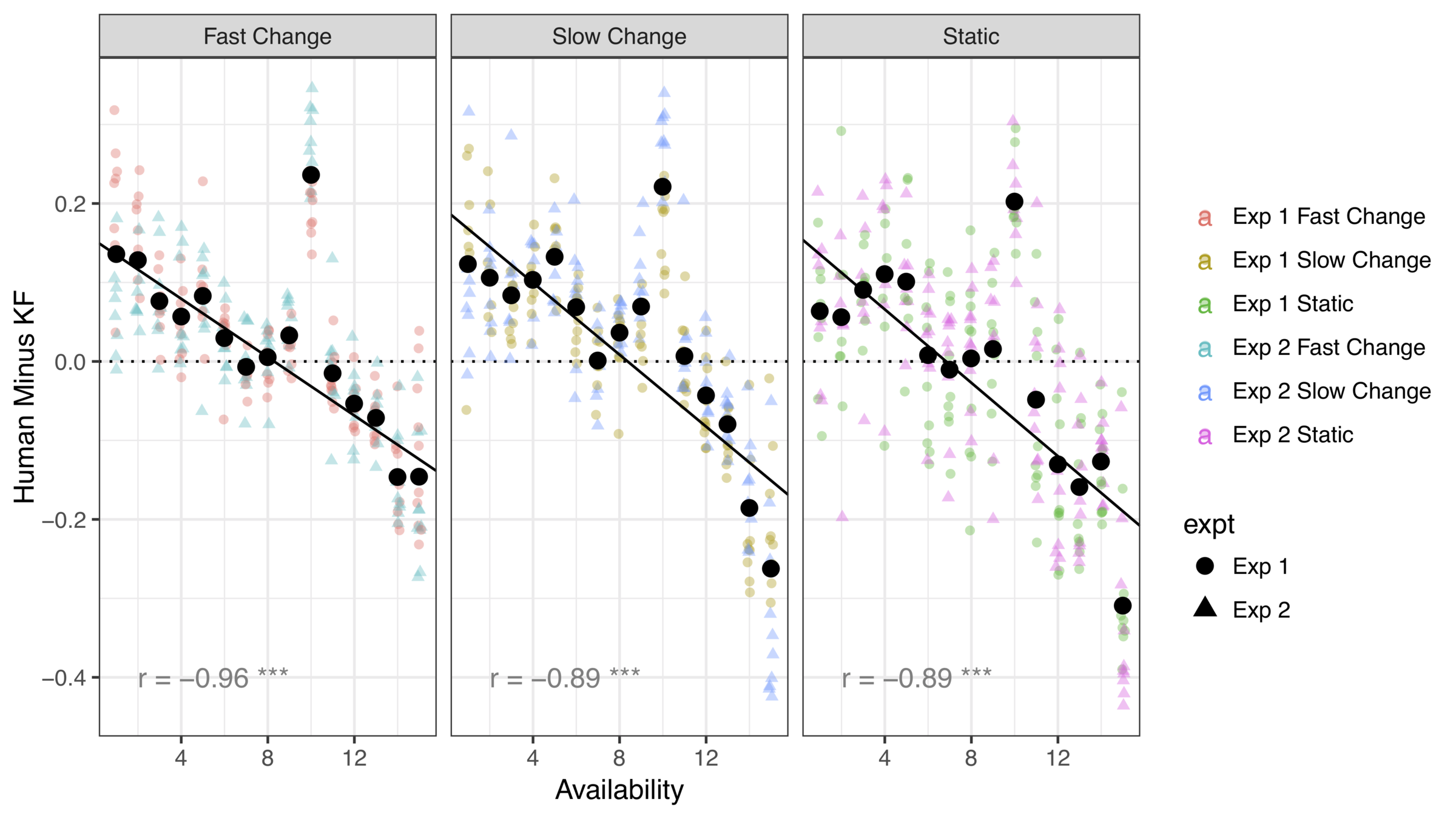
early expired options almost always low value
early expired options sometimes high value
Looks like people are "clinging" to a few suboptimal options only to let them expire right before the deadline?
Expected reward for option \(j\) on this trial
Uncertainty about reward for option \(j\) on this trial
Expected reward for option \(j\) on last trial
Uncertainty about reward for option \(j\) on last trial
Uncertainty drives Kalman gain
Kalman gain influences beliefs about expected reward and uncertainty
Predicted reward for choosing the option
Prediction error
(only update chosen option)
Amount of learning depends on the Kalman gain
KF updates uncertainty
Gain depends on uncertainty
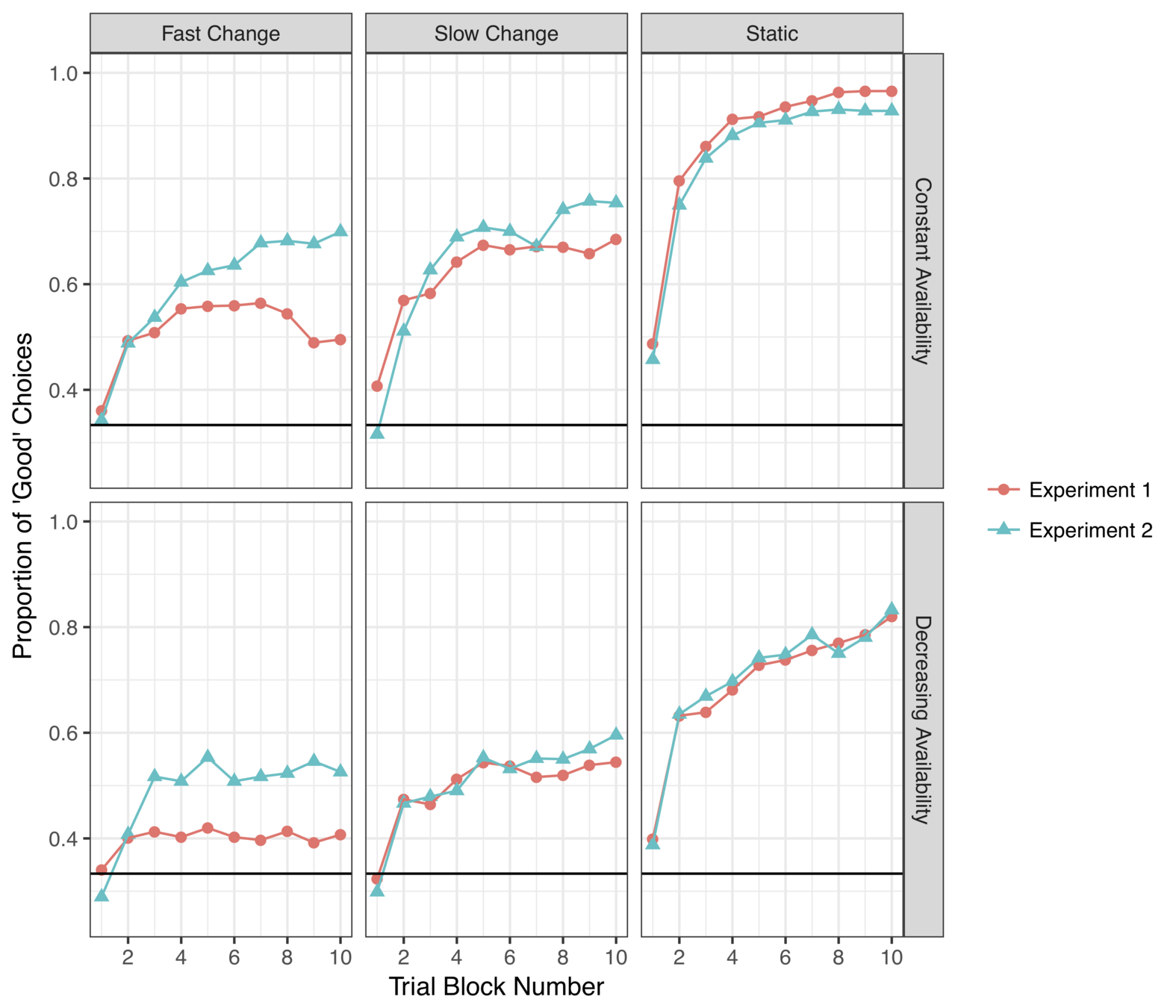
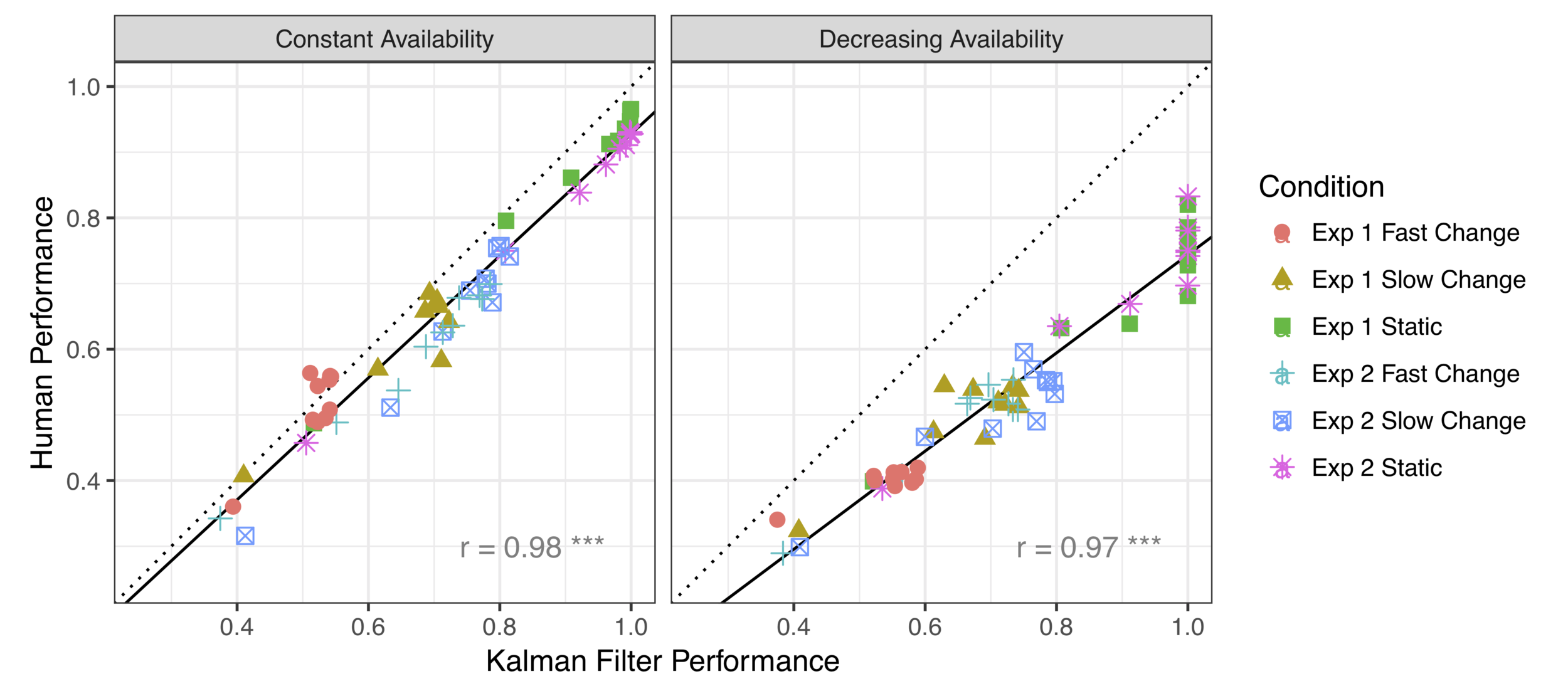
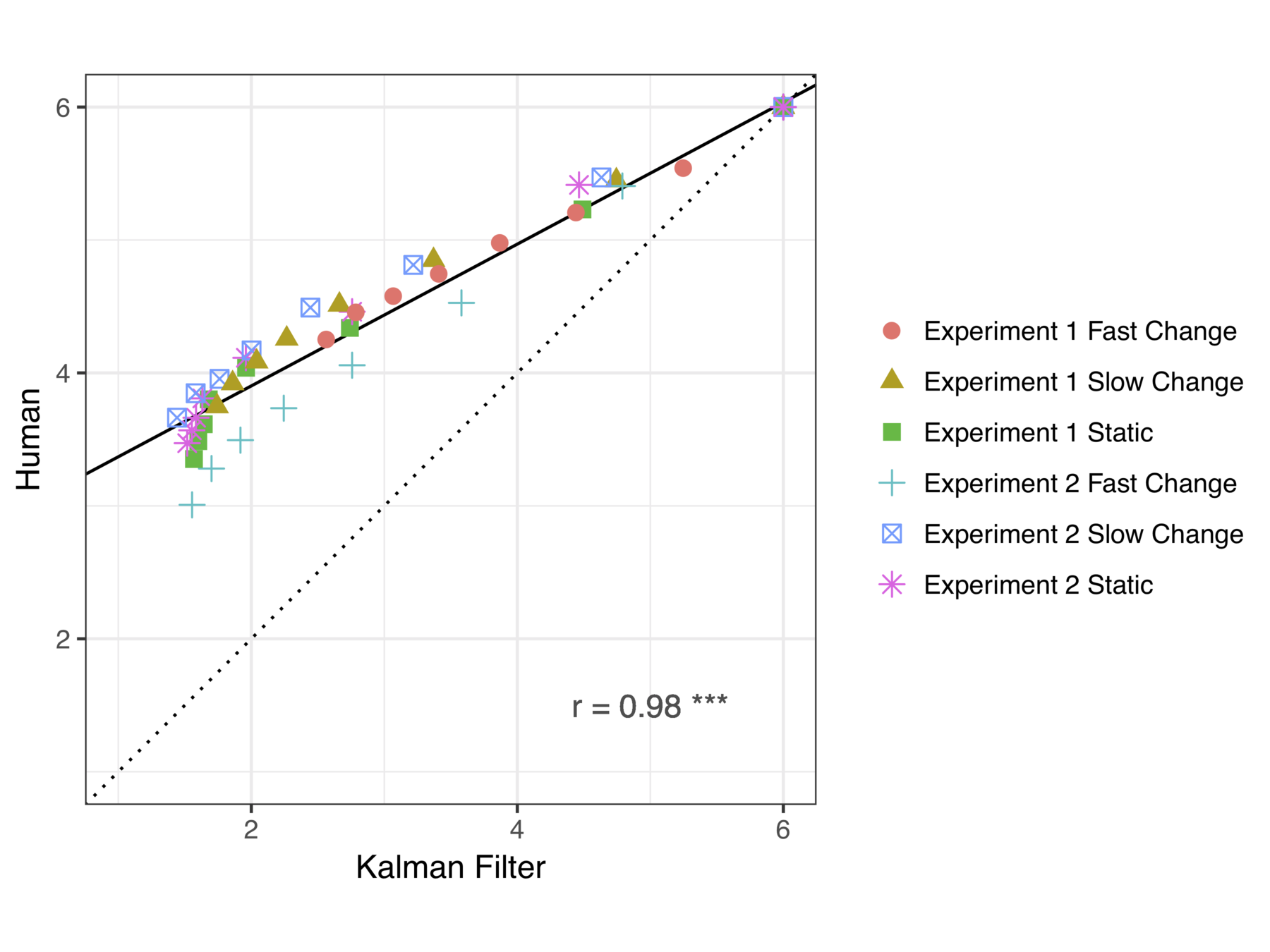
KF model provides an excellent account of choice behaviour when options do not expire
There is a systematic difference when option loss is a possibility
Human decision makers retain more options than the KF model
Project:
Support:
By Danielle Navarro
We present two experiments using multi- armed bandit tasks in both static and dynamic environments, in situations where options can become unviable and vanish if they are not pursued. A Kalman filter model provides an excellent account of human learning in a standard restless bandit task, but there are systematic departures in the vanishing bandit task. (Talk for the 2018 mid-year meeting of the Australian Learning Group. Preprint: https://psyarxiv.com/3g4p5/https://psyarxiv.com/3g4p5/




