Messaging with Kafka in asyncio
Taras Voinarovskiy
voyn1991@gmail.com
Follow slides realtime at:
What's on today's program
- Why do we need it?
- Kafka components: Producers, brokers and consumers.
- Where's asyncio in this?
- Questions
It all starts from 1 data pipeline...
App
Hadoop
App
App
Other service
Real time analytics
Monitoring
Data Wharehouse
Literally in a Web
Solution is quite simple
App
Hadoop
App
App
Other service
Real time analytics
Monitoring
Data Wharehouse
Broker
- Cluster
- Can reread data
- Persistent by design
- Website activity tracking
- Messaging
- External Commit log
- Metrics
- Log aggregation
- Stream Processing
- Event sourcing
When:
Numbers
- 80k/s on single desktop
- 2 million/s on 3 cheap server machines (6 disks 7200 RPM, JBOD style)
- 1.4 trillion messages per day at LinkedIn (1400 brokers as of april 2016)
Yea in Java. What about Python?
Simple benchmark with 0 configuration local machine
- 12k per sec produce with 1Kb messages
- 130k per sec consume with 1Kb messages
Kafka overview
Kafka is similar to Logs...

Publish-subscribe messaging rethought as a distributed commit log
Kafka messaging mechanics
- Publish messages to topics
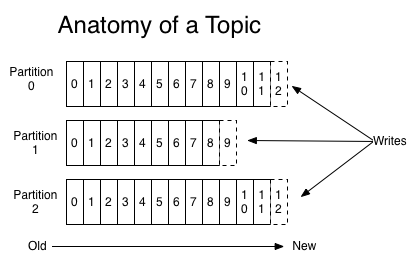
- Topic splitted by partitions
- Partition is ordered
- Every message has a sequential unique offset
Publisher replication and load balancing
Broker 1
P1
P2
Broker 2
P2
P3
Broker 3
P1
P3
Producer
replication factor: 2; partitions: 3
Kafka consuming mechanics
- producer push; consumer - pull
- no state held by broker
- commit can only save position for partition
- fetch bulk for several partitions
- broker sends data directly to socket using sendfile system call
Consumer group coordination in Kafka 9.0
- Node goes down
- Heartbeat fails
- Perform rebalance
Broker cluster
P1
P2
P3
Consumer group 1
group 2
B1
A1
A2
A3
A3
Plusses
- It's fast, scalable and cheap
- Guarantied messages order
- Multi-consumer delivery without message duplication
- Very large persistent backlog of messages (size of your HDD)
- Coordinated consumers, with auto partition reassignment
Minuses
- Thick client with full cluster visibility
- No random message ACK's, only sequential consumption commit points.
- It's for high load... Many configuration and knobs. Really just use RabbitMQ or Redis for 100msg/s
And where's asyncio in this?
We just released aiokafka driver for asyncio:
Code hosted on GitHub
https://github.com/aio-libs/aiokafka
Read the docs:
- Bad documentation on protocol, but some info here: http://kafka.apache.org/protocol.html
-
TCP based binary protocol
- Packet's are versionized
- Strictly sequential request-reply, controlled by correlation_id
- Batching is used everywhere
- Fetch and Produce requests must go to Leader Node. Many error checks to refresh metadata
- Error handling is tedious
What can we say after writing it
Produce messages
producer = AIOKafkaProducer(
loop=loop, bootstrap_servers='localhost:9092')
# Get cluster layout and topic/partition allocation
await producer.start()
# Produce messages.
await producer.send_and_wait(
"my_topic", b"Super message")
# Don't forget to close.
# This will flush all pending messages!
await producer.close()- start() gets metadata from one of bootstrap nodes, so we can determine the leaders for partitions
-
send_and_wait() will:
- select partition (round robin by default)
- append message to pending batch for this partition
- Background task will send batch data as soon as last request to this node finished processing.
- close() will wait for all pending messages to be sent or timed out
Behind the scenes
Consume messages
consumer = AIOKafkaConsumer(
"my_topic", loop=loop, group_id="worker_group",
bootstrap_servers='localhost:9092')
# Get cluster layout and topic/partition allocation
await consumer.start()
async for msg in consumer:
# Process message
print(msg.value)
# Optionally commit
consumer.commit()
# Don't forget to close.
# This will commit last offset in AutoCommit mode.
await consumer.stop()- start() bootstrap like in producer case
- Cluster metadata will have a coordination node
-
Send JoinGroup request to coordination node
- heartbeat config is sent here
- blocks until one of consumers selected as leader
-
Send SyncGroup request as follower or leader
- leader sends partition assignment data
- blocks until all consumers call SyncGroup
- Send Fetch requests for assigned partitions in background
-
close() will commit in autocommit mode
Behind the scenes
Questions?
Taras Voinarovskiy
voyn1991@gmail.com
slides available:
yea, I know, Zookeeper... I only had 40 minutes =)
Messaging with Kafka
By Taras Voinarovskyi
Messaging with Kafka
Kafka presentation for UA PyCon2016




