












Igor Korotach
Head of FinTech at Quantum
Written by: Igor Korotach
Apache Spark is an open-source distributed general-purpose cluster-computing framework. Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance.
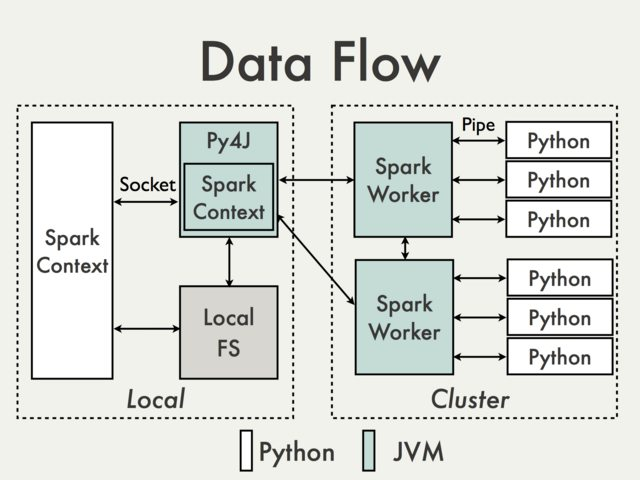
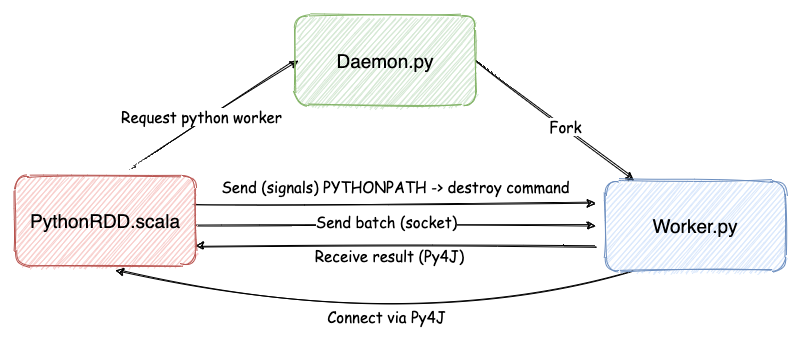
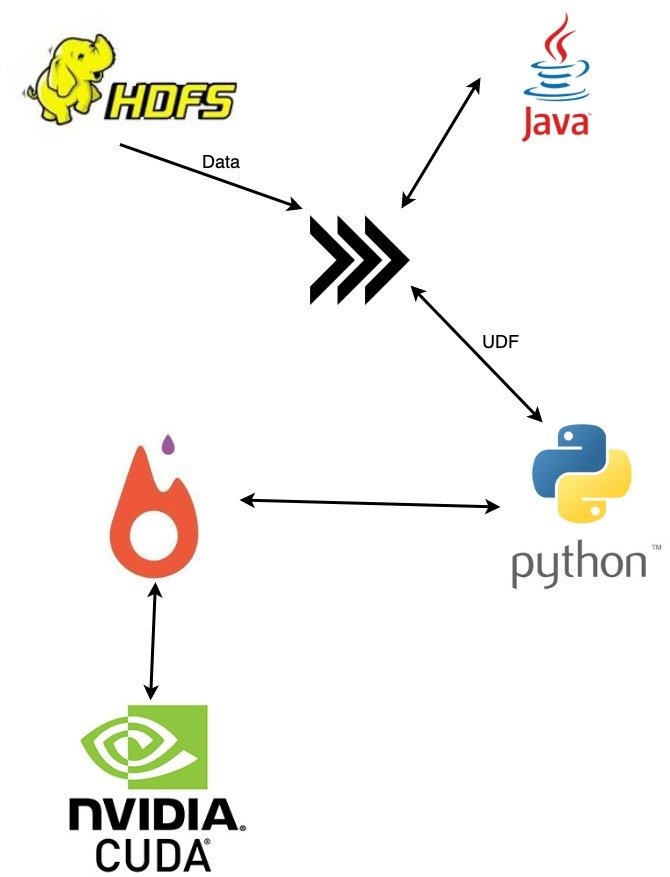
In the Python driver program, SparkContext uses Py4J to launch a JVM and create a JavaSparkContext. Py4J is only used by the driver for local communication between the Python and Java SparkContext objects; large data transfers are performed through a different mechanism. (sssshhhh HDFS)
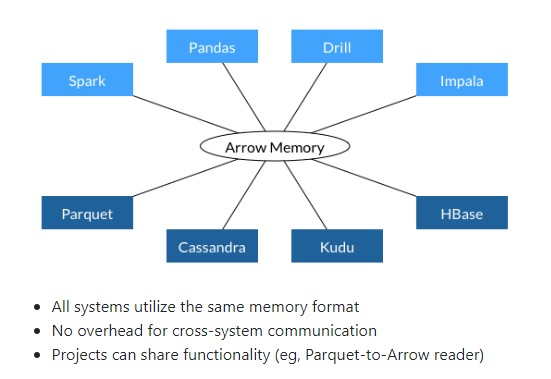
Apache Arrow is a cross-language development platform for in-memory data. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware.
# Setup the spark client
from pyspark.sql import SparkSession
warehouseLocation = "/wh"
spark = SparkSession\
.builder.appName("demo")\
.config("spark.sql.warehouse.dir", warehouseLocation)\
.enableHiveSupport()\
.getOrCreate()
# Create test Spark DataFrame
from pyspark.sql.functions import rand
df = spark.range(1 << 22).toDF("id").withColumn("id", rand())
df.printSchema()
# Benchmark time
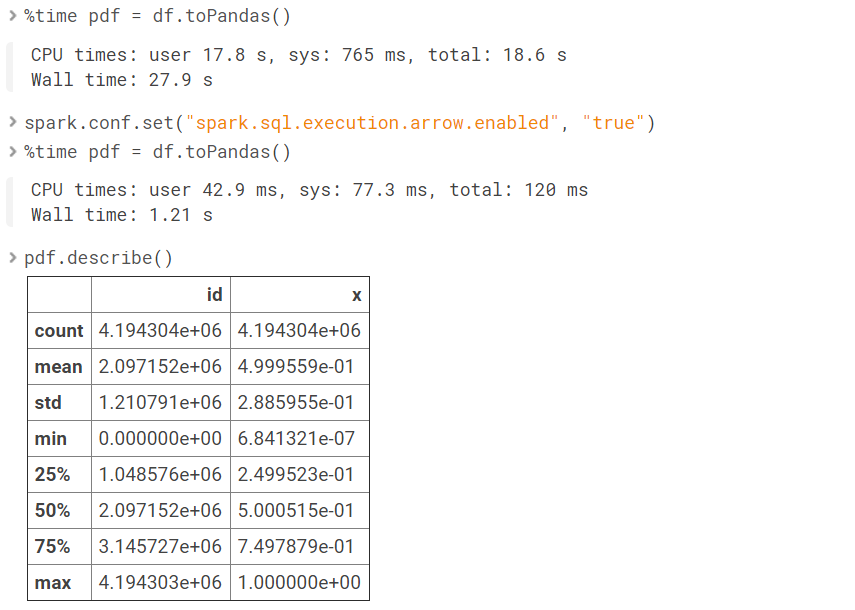
%time pdf = df.toPandas()
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
%time pdf = df.toPandas()
pdf.describe()# Do the imports
import os
import ...
# Enable Arrow support.
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
spark.conf.set("spark.sql.execution.arrow.maxRecordsPerBatch", "2048")
# Enable CUDA
cuda = True
use_cuda = cuda and torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")bc_model_state = sc.broadcast(models.resnet50(pretrained=True).state_dict())
def get_model_for_eval():
"""Gets the broadcasted model."""
model = models.resnet50(pretrained=True)
model.load_state_dict(bc_model_state.value)
model.eval()
return modelfiles_df = spark.createDataFrame(
map(lambda path: (path,), files), ["path"]
).repartition(10)
display(files_df.limit(10))class ImageDataset(Dataset):
def __init__(self, paths, transform=None):
self.paths = paths
self.transform = transform
def __len__(self):
return len(self.paths)
def __getitem__(self, index):
image = default_loader(self.paths[index])
if self.transform is not None:
image = self.transform(image)
return image
def predict_batch(paths):
transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
images = ImageDataset(paths, transform=transform)
loader = torch.utils.data.DataLoader(images, batch_size=500, num_workers=8)
model = get_model_for_eval()
model.to(device)
all_predictions = []
with torch.no_grad():
for batch in loader:
predictions = list(model(batch.to(device)).cpu().numpy())
for prediction in predictions:
all_predictions.append(prediction)
return pd.Series(all_predictions)# Set your model
predict_udf = pandas_udf(ArrayType(FloatType()),
PandasUDFType.SCALAR)(predict_batch)
# Make predictions.
predictions_df = files_df.select(col('path'),
predict_udf(col('path')).alias("prediction"))
predictions_df.write.mode("overwrite").parquet(output_file_path)
# Load and check the prediction results.
result_df = spark.read.load(output_file_path)
display(result_df)1) Demand for Java in PyTorch
https://github.com/pytorch/pytorch/issues/6570
2) PyTorch JNI bindings as gradle library
https://github.com/pytorch/pytorch/issues/28986
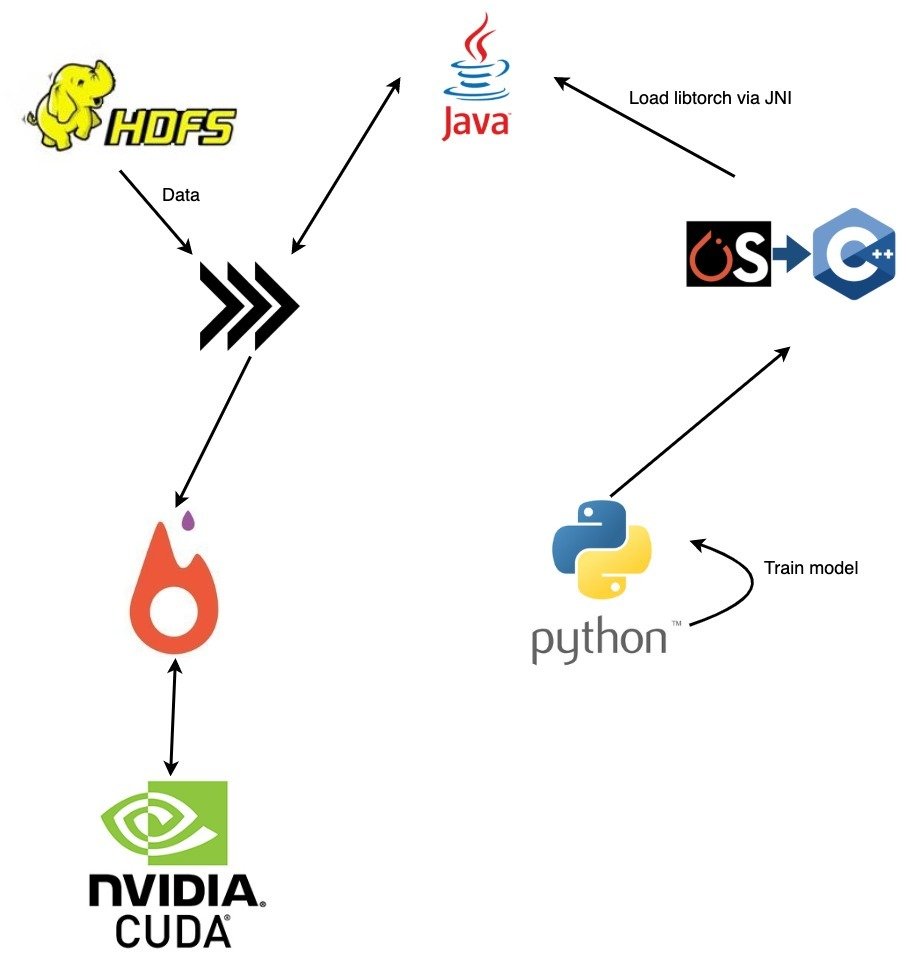
3) This is expected to arrive in
PyTorch 1.4!
That was quick!
The support indeed landed in PyTorch 1.4 https://github.com/pytorch/pytorch/issues/6570
Module mod = Module.load("demo-model.pt1");
Tensor data =
Tensor.fromBlob(
new int[] {1, 2, 3, 4, 5, 6}, // data
new long[] {2, 3} // shape
);
IValue result = mod.forward(IValue.from(data), IValue.from(3.0));
Tensor output = result.toTensor();
System.out.println("shape: " + Arrays.toString(output.shape()));
System.out.println("data: " + Arrays.toString(output.getDataAsFloatArray()));Path modelPath = Paths.get(LoadTensorflowModel.class.getResource("saved_model.pb").toURI());
byte[] graph = Files.readAllBytes(modelPath);
try (Graph g = new Graph()) {
g.importGraphDef(graph);
//open session using imported graph
try (Session sess = new Session(g)) {
float[][] inputData = {{4, 3, 2, 1}};
// We have to create tensor to feed it to session,
// unlike in Python where you just pass Numpy array
Tensor inputTensor = Tensor.create(inputData, Float.class);
float[][] output = predict(sess, inputTensor);
for (int i = 0; i < output[0].length; i++) {
System.out.println(output[0][i]);//should be 41. 51.5 62.
}
}
}private static float[][] predict(Session sess, Tensor inputTensor) {
Tensor result = sess.runner()
.feed("input", inputTensor)
.fetch("not_activated_output").run().get(0);
float[][] outputBuffer = new float[1][3];
result.copyTo(outputBuffer);
return outputBuffer;
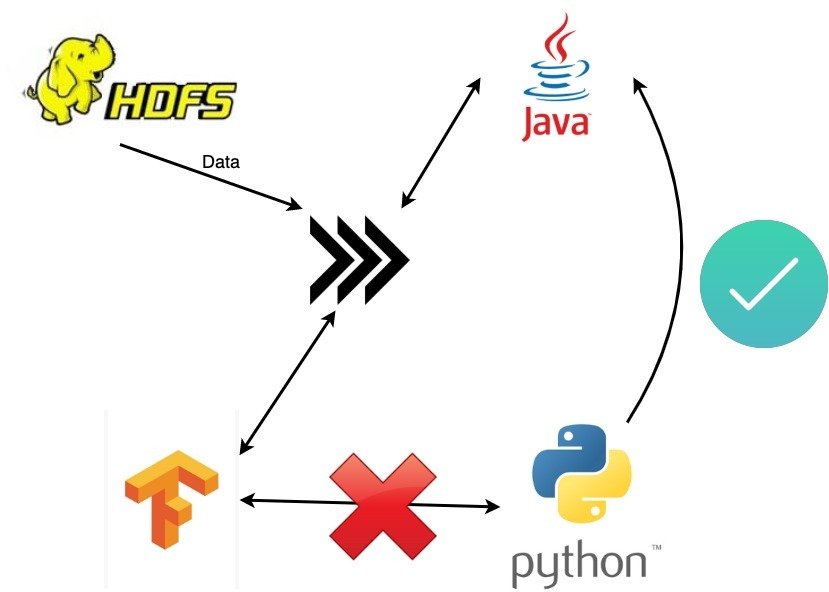
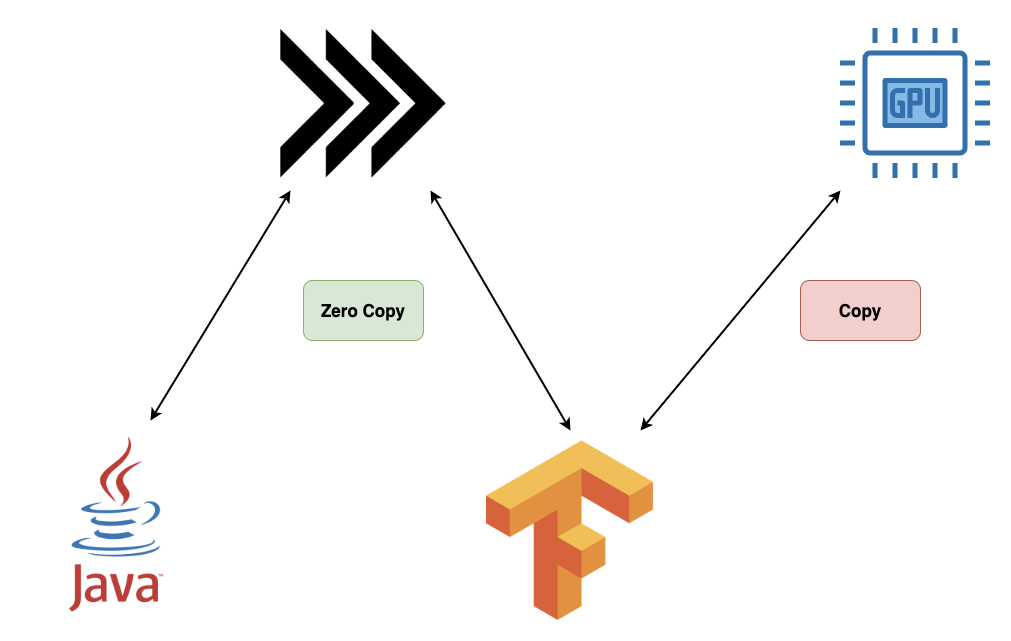
}Both Java APIs (PyTorch, TensorFlow) aren't considered stable, optimized or convenient
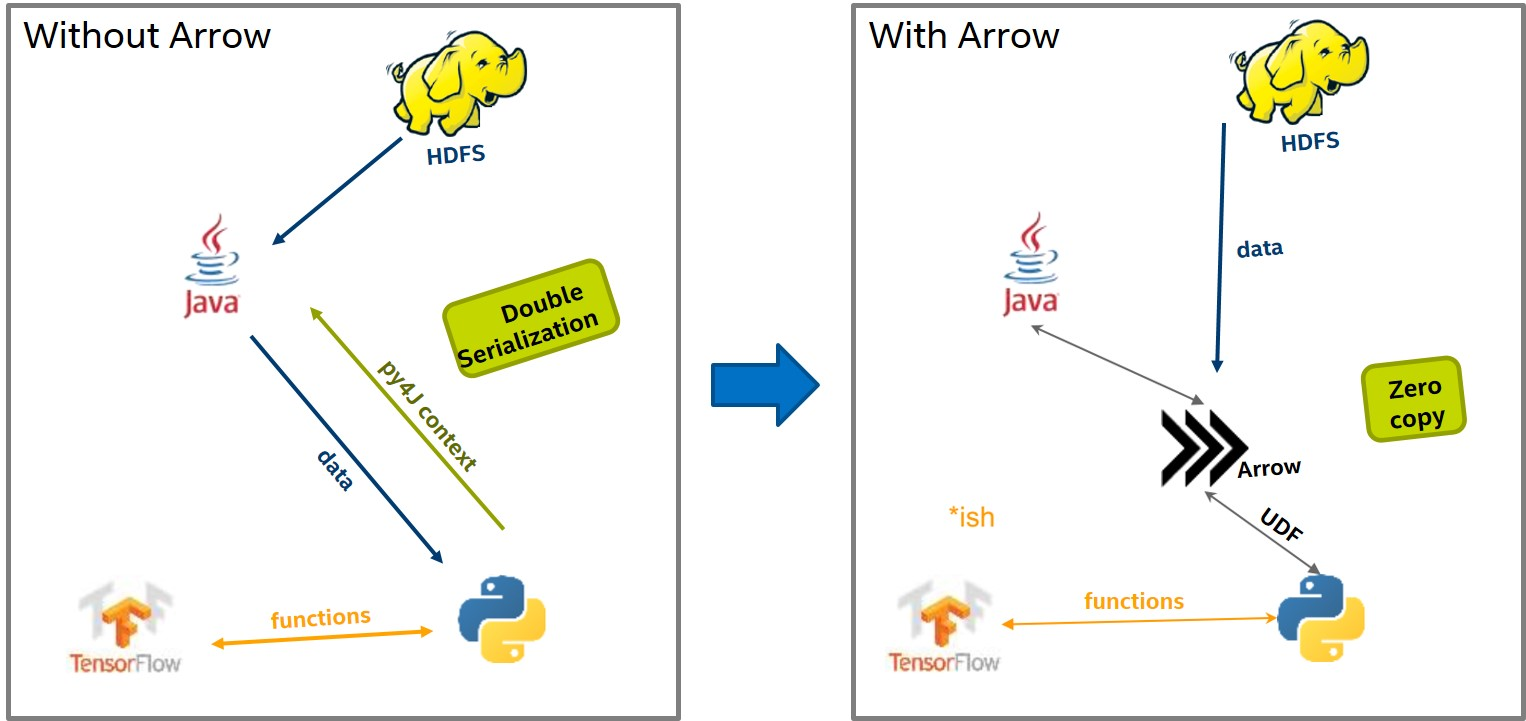
Though Apache Arrow provides an optimal storage and conversion format it doesn't cover the data transfer problem. Data is still sent over network. One solution would be using a shared memory object store like
Plasma Store.
Technically, zero copy situation is achieved if ALL of the following applies:
The granted speed up is 10%-58%, memory usage reduction is 50% on PX2 and TX2/AGX for example task (autoware and drone obstacle detection)
More technical info https://personal.utdallas.edu/~soroush/papers/RTAS2020.pdf
By Igor Korotach




