

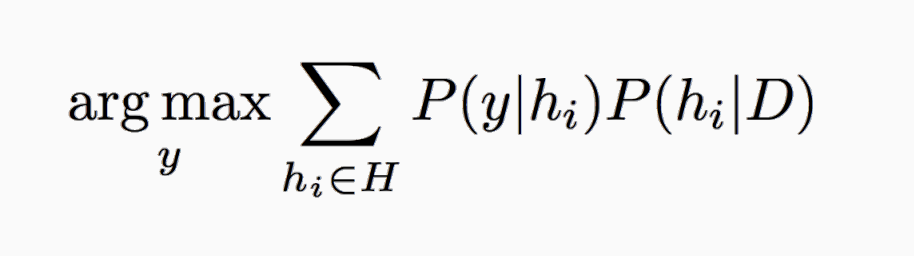
federica bianco PRO
astro | data science | data for good
dr.federica bianco | fbb.space | fedhere | fedhere
K-NN - CART
this slide deck:
Extraction of features
1
Consider a classification task:
if I want to use machine learning methods I need to choose:
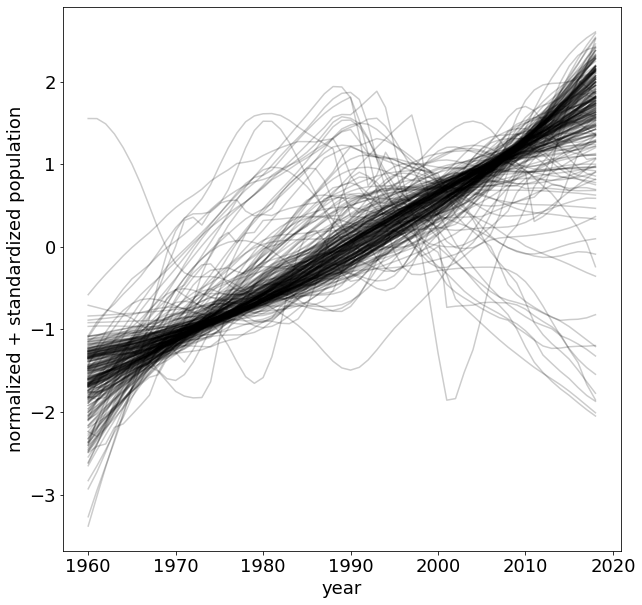
use raw representation:
e.g. clustering:
1) take each time series and standardize it
(mean 0 standard 1).
2) for each time stamps compare them to the expected value (mean and stdev)
essentially each datapoint is treated as a feature
Consider a classification task:
if I want to use machine learning methods (e.g. clustering) I need to choose:
use raw representation
1) take each time series and standardize it (μ=0 ; σ=1).
2) for each time stamps compare them to the expected value (μ & σ)
problems:
(in small dataset you can optimize over warping and shifting but in large dataset this solution is computationally limited)
essentially each datapoint is treated as a feature
Consider a classification task:
if I want to use machine learning methods (e.g. clustering) I need to choose:
choose a low dimensional representation
essentially each datapoint is treated as a feature
Extract features that describe the time series:
simple descriptive statistics (look at the distribution of points, regardless of the time evolution:
parametric features (based on fitting model to data):
Consider a classification task:
the learned representations should:
2
classification
prediction
feature selection
supervised learning
understanding structure
organizing/compressing data
anomaly detection dimensionality reduction
unsupervised learning
classification
supervised learning methods
(nearly all other methods you heard of)
learns by example
used to:
classify, predict (regression)
supervised learning methods
(nearly all other methods you heard of)
learns by example
used to:
classify, predict (regression)
x
y
observed features:
(x, y)
models typically return a partition of the space
target features:
(color)
goal is to partition the space so that the unobserved variables are
separated in groups
consistently with
an observed subset
x
y
observed features:
(x, y)
if x**2 + y**2 <= (x-a)**2 + (y-b)**2 :
return blue
else:
return orangetarget features:
(color)
A subset of variables has class labels. Guess the label for the other variables
SVM
finds a hyperplane that optimally separates observations
x
y
observed features:
(x, y)
Tree Methods
split spaces along each axis separately
A subset of variables has class labels. Guess the label for the other variables
split along x
if x <= a :
if y <= b:
return blue
return orangethen
along y
target features:
(color)
x
y
observed features:
(x, y)
KNearest Neighbors
Assigns the class of closest neighbors
A subset of variables has class labels. Guess the label for the other variables
split along x
k = 4
if (label[argsort(distance((x,y), trainingset))][:k] == "blue").sum() > (labels[argsort(distance((x,y), trainingset))][:k] == "orange").sum():
return blue
return orangetarget features:
(color)
3
Calculate the distance d to all known objects Select the k closest objects Assign the most common among the k classes:
# k = 1
d = distance(x, trainingset)
C(x) = C(trainingset[argmin(d)])Calculate the distance d to all known objects Select the k closest objects
Classification:
Assign the most common among the k classes
Regression: Predict the average (median) of the k target values
Good
non parametric
very good with large training sets
Cover and Hart 1967: As n→∞, the 1-NN error is no more than twice the error of the Bayes Optimal classifier.
Good
non parametric
very good with large training sets
Cover and Hart 1967: As n→∞, the 1-NN error is no more than twice the error of the Bayes Optimal classifier.
Let xNN be the nearest neighbor of x.
For n→∞, xNN→x(t) => dist(xNN,x(t))→0
Theorem: e[C(x(t)) = C(xNN)]< e_BayesOpt
e_BayesOpt = argmaxy P(y|x)
Proof: assume P(y|xt) = P(y|xNN)
(always assumed in ML)
eNN = P(y|x(t)) (1−P(y|xNN)) + P(y|xNN) (1−P(y|x(t))) ≤
(1−P(y|xNN)) + (1−P(y|x(t))) =
2 (1−P(y|x(t)) = 2ϵBayesOpt,
Good
non parametric
very good with large training sets
Not so good
it is only as good as the distance metric
If the similarity in feature space reflect similarity in label then it is perfect!
poor if training sample is sparse
poor with outliers
using Kaggle data programmatically https://www.kaggle.com/docs/api
PROS:
Because the model does not need to provide a global optimization the classification is "on-demand".
This is ideal for recommendation systems: think of Netflix and how it provides recommendations based on programs you have watched in the past.
CONS:
Need to store the entire training dataset (cannot model data to reduce dimensionality).
Training==evaluation => there is no possibility to frontload computational costs
Evaluation on demand, no global optimization - doesn’t learn a discriminative function from the training data but “memorizes” the training dataset instead.
By federica bianco
k-NN and CARTS



