




















Florian Dambrine
I am a Freelance DevOps Engineer graduated from UTC (University of Technology of Compiègne) in 2014. I am a DevOps enthusiast embracing Cloud computing technologies to build automated infrastructure at large scale.
Florian Dambrine
July 8th 2015
Los Angeles Ansible Meetup Group
@DambrineF
Hashtag for the event: #GumGumAnsible
Florian Dambrine
DevOps Engineer - Big Data Team - GumGum
Born and raised in France
Joined GumGum 15 months ago
About a year of experience with Ansible
Years ago, Bash was used to automate repeated tasks...
Later on, configuration management tools appeared...
Today...
> What is Ansible?
Static Inventory
Dynamic Inventory
### INI file format
[dbservers]
db-prod.meetup.com
db-test.meetup.com
[webservers]
foo.meetup.com
bar.meetup.com
...
{
...
"ansible_eth0": {
"active": true,
"device": "eth0",
"ipv4": {
"address": "REDACTED",
"netmask": "255.255.255.0",
"network": "REDACTED"
},
...
},
"ansible_kernel": "3.5.0-23-generic",
"ansible_lsb": {
"codename": "precise",
"description": "Ubuntu 12.04.2 LTS",
"id": "Ubuntu",
"major_release": "12",
"release": "12.04"
},
"ansible_machine": "x86_64",
...
}Linux commands
apt
Ansible modules
apt
ln
mkdir
touch
------------------------------>
---------------|
---------------|-------------->
|
files
|
---------------|
It is possible to leave off the ‘name’ for a given task, though it is recommended to provide a description about why something is being done instead. This name is shown when the playbook is run.
---
- name: Install Nginx
apt:
name: nginx
update_cache: yes
state: present---
- name: Create the scripts log folder
file:
state: directory
path: /var/log/gumgum-scripts
owner: gumgum
group: gumgum
mode: 644---
- name: Start an EC2 instance
local_action:
module: ec2
aws_access_key: 'AKIAXXXXXXXXX'
aws_secret_key: 'XXXXXXXXXXXXX'
key_name: 'mykeypair.pem'
instance_type: 'c3.large'
wait: yes
image: 'ami-XXXXXX'
count: 1
region: 'us-east-1'
zone: 'us-east-1b'
monitoring: yes
group: ['sshonly', 'webapp']
instance_tags:
Name: demo
Owner: 'Florian Dambrine'
volumes:
- device_name: /dev/sda1
volume_size: 30
ok
changed
skipped
failed
Return codes of a task
Example with an ad-hoc command
$ ansible webservers -s -m apt -a "name=nginx state=latest update_cache=yes"
foo.meetup.com | success >> {
"changed": true,
"stderr": "",
"stdout": "Reading package lists...\nBuilding dependency tree...\nReading state......"
}
bar.meetup.com | success >> {Example with the ansible-playbook command
### nginx-play.yaml
---
- hosts: webservers
sudo: yes
tasks:
- name: Install Nginx
apt:
name: nginx
update_cache: yes
state: present$ ansible-playbook nginx-play.yaml
PLAY [webserver] *************************************
TASK: [Install Nginx] ********************************
changed: [foo.meetup.com]
changed: [bar.meetup.com]
PLAY RECAP *******************************************
foo.meetup.com : ok=0 changed=1 unreachable=0 failed=0
bar.meetup.com : ok=0 changed=1 unreachable=0 failed=0
### nginx-playbook.yaml
---
- hosts: webservers
sudo: yes
tasks:
- name: Install Nginx
apt:
name: nginx
state: latest
update_cache: yes
- name: Cleaning apps-enabled
file:
state: absent
path: /etc/nginx/sites-enabled/default
- name: Cleaning apps-available
file:
state: absent
path: /etc/nginx/sites-available/default
- name: Restart Nginx
service:
name: nginx
state: restartedreceipe
manifest
rolename/
├── defaults/ ---> Lowest priority variables.
│ └── main.yaml
├── files/ ---> Contains static files that need to be deployed on remote server.
│ └── ...
├── handlers/ ---> Contains tasks that can be triggered by a notification event.
│ └── main.yaml
├── meta/ ---> Contains dependencies between roles.
│ └── main.yaml
├── tasks/ ---> Contains your soup.
│ ├── ...
│ ├── main.yaml
├── templates/ ---> Contains templates that will be fed with variables (facts, or role vars).
│ ├── ....j2
├── vars/ ---> Higher level of priority where default variables will be overriden.
│ ├── ...
│ ├── main.yaml
--------------------
└── vagrant/ ---> Vagrant testing environment
├── ansible.cfg
├── rolename.yaml
└── Vagrantfilecookbook
module
What we used to do a year ago....
cookbooks
AWS S3
AWS EC2 instances
2
1
3
4
upload
download at bootstrap
Python / Boto for Kickoff
Drawbacks:
THIS IS NOT AUTOMATION!
---
- hosts: cassandra
serial: 1
sudo: yes
tasks:
- name: Edit cassandra-env.sh
copy:
src: cassandra-env.sh
dest: /etc/cassandra/cassandra-env.sh
backup: yes
owner: root
group: opscenter-admin
mode:664
- name: Restart Cassandra
service:
name: cassandra
state: restarted
- name: Wait for the node to join the cluster back
shell: sleep 300
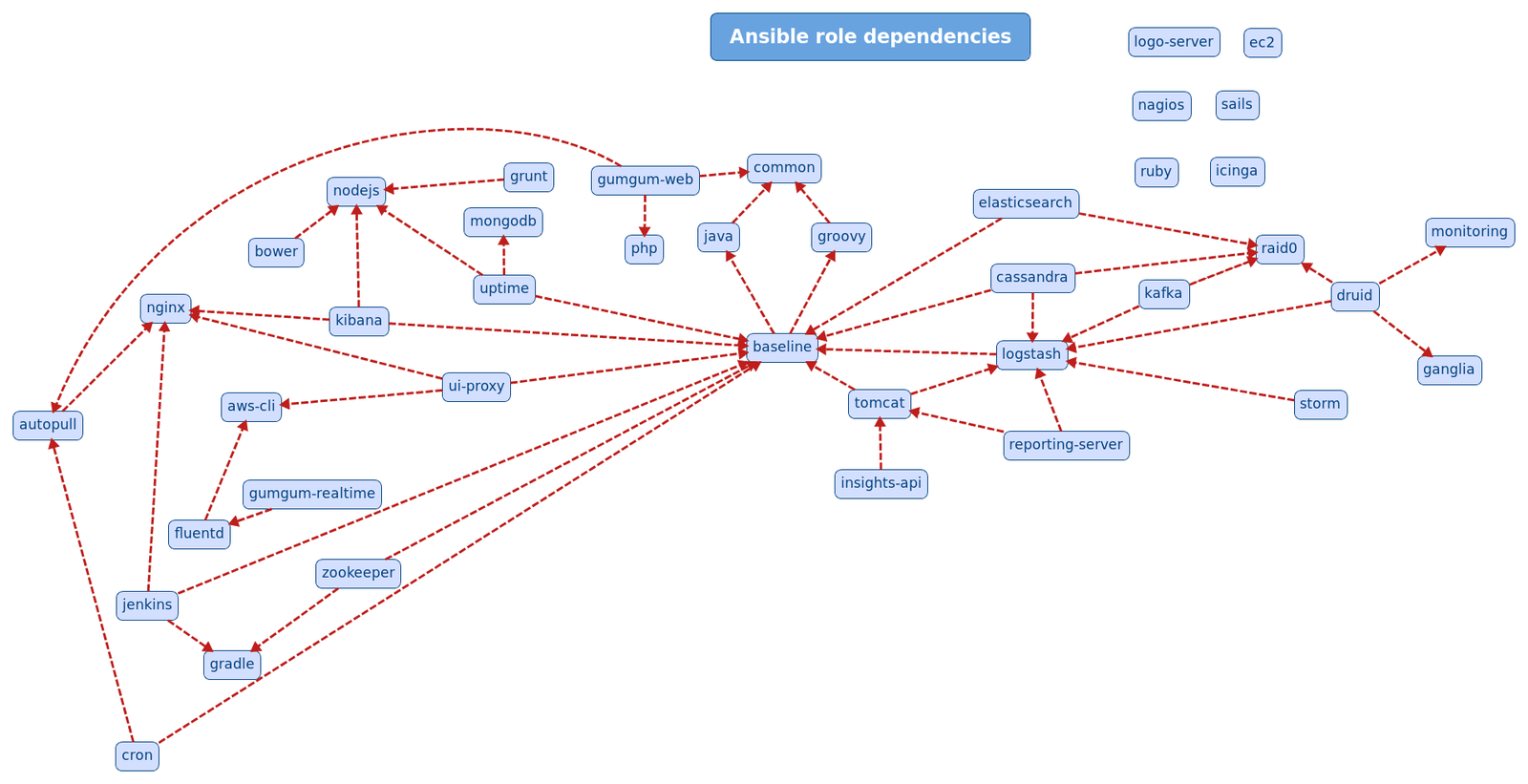
$ ls ~/workspace/ops/ansible/roles
ansible elasticsearch icinga mysql ruby
autopull fluentd icinga2 nagios sails
aws-cli forecasting-server insights-api nginx spark
baseline ganglia java nodejs spiderami
bower ganglia-server jenkins opscenter squid
cassandra gradle kafka php storm
common graphite kibana play-mantii tomcat
cron groovy logo-server postfix-client ui-proxy
django grunt logstash-client postfix-relay uptime
druid gumgum-adbuilder logstash-parser raid0 uwsgi
ec2 gumgum-realtime mongodb reporting-server zookeeper
ec2-ami gumgum-web monitoring role-skel
Ansible provides ~320 modules that can control system resources
Try to build idempotent roles
---
- hosts: all
sudo: yes
vars:
version: '2.4.2'
url: http://dl.bintray.com/groovy/maven
tasks:
- name: Install dependencies
shell: "apt-get update && apt-get -y install unzip openjdk-7-jdk"
- name: Download Groovy
shell: "wget -q -O /tmp/groovy-{{ version }}.zip {{ url }}/groovy-binary-{{ version }}.zip"
- name: Extract Groovy archive
shell: "unzip -u /tmp/groovy-{{ version }}.zip -d /opt"
- name: Export JAVA_HOME in profile.d
shell: "echo JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64 > /etc/profile.d/groovy-env.sh"
- name: Export GROOVY_HOME in profile.d
shell: "echo GROOVY_HOME=/opt/groovy-{{ version }} >> /etc/profile.d/groovy-env.sh"
- name: Setup the PATH in profile.d
shell: "echo PATH=$PATH:/usr/lib/jvm/java-1.7.0-openjdk-amd64/bin:/opt/groovy-{{ version }}/bin >> \
/etc/profile.d/groovy-env.sh"
- name: Run Groovy version
shell: "groovy -v"
environment:
PATH: "{{ ansible_env.PATH }}:/opt/groovy-{{ version }}/bin"
register: groovy_version
- debug:
var: groovy_version.stdout---
- hosts: all
sudo: yes
vars:
version: '2.4.2'
url: 'http://dl.bintray.com/groovy/maven'
tasks:
- name: Install dependencies
apt: "name={{ item }} update_cache=yes"
with_items: ['unzip', 'openjdk-7-jdk']
- name: Download Groovy
get_url:
url: "{{ url }}/groovy-binary-{{ version }}.zip"
dest: "/tmp/groovy-{{ version }}.zip"
- name: Extract Groovy archive
unarchive:
src: "/tmp/groovy-{{ version }}.zip"
dest: "/opt"
creates: "/opt/groovy-{{ version }}"
copy: no
- name: Deploy groovy-env in profile.d
template:
src: groovy-env.sh.j2
dest: '/etc/profile.d/groovy-env.sh'
- name: Run Groovy version
shell: "groovy -v"
environment:
PATH: "{{ ansible_env.PATH }}:/opt/groovy-{{ version }}/bin"
changed_when: false
register: groovy_version
- debug:
var: groovy_version.stdoutJAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64
GROOVY_HOME=/opt/groovy-{{ version }}
PATH=$PATH:/usr/lib/jvm/java-1.7.0-openjdk-amd64/bin:/opt/groovy-{{ version }}/bingroovy-env.sh.j2
This playbook is idempotent and leverages:
PLAY [all] **********************************
GATHERING FACTS *****************************
ok: [instance-1]
TASK: [Install dependencies] ****************
changed: [instance-1]
TASK: [Download Groovy] *********************
changed: [instance-1]
TASK: [Extract Groovy archive] **************
changed: [instance-1]
TASK: [Export JAVA_HOME in profile.d] *******
changed: [instance-1]
TASK: [Export GROOVY_HOME in profile.d] *****
changed: [instance-1]
TASK: [Setup the PATH in profile.d] *********
changed: [instance-1]
TASK: [Run Groovy version] ******************
changed: [instance-1]
TASK: [debug ] ******************************
ok: [instance-1] => {
"var": {
"groovy_version.stdout": "Groovy Version: 2.4.2"
}
}
PLAY RECAP **********************************
instance-1:
ok=9
changed=7
unreachable=0
failed=0
PLAY [all] **********************************
GATHERING FACTS *****************************
ok: [instance-1]
TASK: [Install dependencies] *****************
ok: [instance-1] => (item=unzip,openjdk-7-jdk)
TASK: [Download Groovy] **********************
ok: [instance-1]
TASK: [Extract Groovy archive] ***************
ok: [instance-1]
TASK: [Deploy groovy-env in profile.d] *******
ok: [instance-1]
TASK: [Run Groovy version] *******************
ok: [instance-1]
TASK: [debug ] *******************************
ok: [instance-1] => {
"var": {
"groovy_version.stdout": "Groovy Version: 2.4.2"
}
}
PLAY RECAP ***********************************
instance-1
ok=7
changed=0
unreachable=0
failed=0 Shell style play
Ansible style play
default variables are the most "defaulty" variables and they lose in priority to everything
# This file includes Java default variables
---
# Override this variable if you need to
# switch from java 7 to 8
java_default_version: 7
# S3 bucket from where the JDK will be downloaded
java_jdk_bucket: ansible
java_jdk_bucket_path: distribution/jdk
# List of jdk to deploy (needs to be in the S3 bucket)
java_versions:
- jdk1.7.0_80
- jdk1.8.0_45
# Aliases will be build as following:
# java-X-oracle -> jdk1.X.y_zz
# java-7-oracle -> jdk1.7.0_80
java_aliased_versions:
- jdk1.7.0_80
- jdk1.8.0_45
# Where the .tar.gz will be dropped
java_download_folder: /tmp
# Where the JDK will be installed
java_root_folder: /optansible/ ### Ansible Repository Structure
├── java.yaml
│
└── roles/java/
└── defaults/
└── main.yamlflorian@instance-1:/opt$ ls
java-7-oracle@ java-8-oracle@ jdk1.7.0_80 jdk1.8.0_45
florian@instance-1:/etc/profile.d$ cat java-env.sh
#!/bin/bash
export JAVA_HOME=/opt/java-7-oracle
export PATH=$PATH:$JAVA_HOME/binflorian@instance-2:/usr/lib/jvm$ ls
java-7-oracle@ java-8-oracle@ jdk1.7.0_80 jdk1.8.0_45
florian@instance-2:/etc/profile.d$ cat java-env.sh
#!/bin/bash
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export PATH=$PATH:$JAVA_HOME/binansible-playbook java.yaml \
--limit webservers \
--extra-vars "@override_java"##################################
### Create a variable file
vim override_java.json
##################################
### Override default behavior
---
java_default_version: 8
java_root_folder: /usr/lib/jvmLookup plugins allow access of data in Ansible from outside sources (files, ENV vars)
---
aws_credentials_key_id: 'AKIA123456789'
aws_credentials_secret_key: '...'
ec2_image: ami-76b2a71e
ec2_region: us-east-1
ec2_az:
- us-east-1a
- us-east-1b
- us-east-1c
- us-east-1d
- us-east-1e
ec2_count:
- 0 # How many in us-east-1a ?
- 1 # How many in us-east-1b ?
- 0 # How many in us-east-1c ?
- 0 # How many in us-east-1d ?
- 0 # How many in us-east-1e ?
ec2_key: keypair-1
ec2_sg: va-ops---
aws_credentials_key_id: 'AKIAABCDEFGHI'
aws_credentials_secret_key: '...'
ec2_image: ami-b97a12ce
ec2_region: eu-west-1
ec2_az:
- eu-west-1a
- eu-west-1b
- eu-west-1c
ec2_count:
- 0 # How many in eu-west-1a ?
- 1 # How many in eu-west-1b ?
- 0 # How many in eu-west-1c ?
ec2_vpc_subnet:
- undefined
- subnet-56b01521
- undefined
ec2_key: keypair-2
ec2_sg: ie-ops
roles/ec2/vars/virginia/ec2.yaml
roles/ec2/vars/ireland/ec2.yaml
- hosts: 127.0.0.1
sudo: yes
vars_files:
# Load EC2 account vars
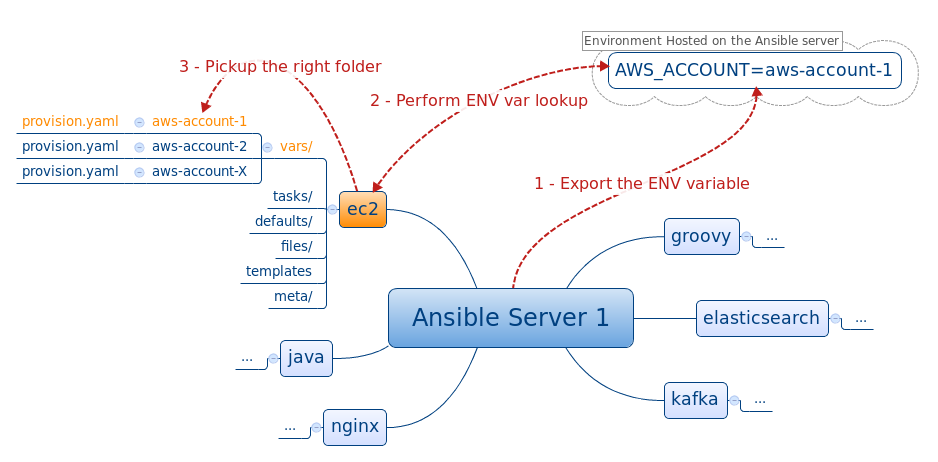
- "roles/ec2/vars/{{ lookup('env','AWS_ACCOUNT') }}/provision.yaml"
roles:
- { role: ec2, tags: ['provision'] }
- hosts: 127.0.0.1
sudo: yes
vars:
instance: elasticsearch
vars_files:
# Load EC2 account vars
- "roles/ec2/vars/{{ lookup('env','AWS_ACCOUNT') }}/{{ instance }}-provision.yaml"
roles:
- { role: ec2, tags: ['provision'] }
florian@instance-1$ ls ansible/roles/ec2/vars/virginia/
elasticsearch-provision.yaml
cassandra-provision.yaml
cron-provision.yaml
nginx-provision.yaml
...---------------------------------------------------------
Ansible provides cloud modules that allows you to interact with your cloud instances.
Use case:
June 2014, the DevOps team started a 25 node Cassandra cluster:
------------
In March 2015, 3 instances are scheduled for retirement by AWS because of running on degraded hardware...
Do you remember how you started your instances a year ago?
- hosts: 127.0.0.1
sudo: yes
vars:
instance: elasticsearch
vars_files:
# If the first file exists use it, otherwise fallback to default
- [
"roles/ec2/vars/{{ lookup('env','AWS_ACCOUNT') }}/{{ instance }}-{{ lookup('env','INSTANCE_ID') }}.yaml",
"roles/ec2/vars/{{ lookup('env','AWS_ACCOUNT') }}/{{ instance }}-provision.yaml"
]
roles:
- { role: ec2, tags: ['provision'] }
florian@instance-1$ ls ansible/roles/ec2/vars/virginia/
cassandra-provision.yaml
cassandra-realtime.yaml
cassandra-analytics.yaml
...
elasticsearch-provision.yaml
elasticsearch-logstash.yaml
elasticsearch-main.yaml
elasticsearch-test.yaml
...---
- name: Adding Elasticsearch public GPG key
shell: wget -O - http://packages.elasticsearch.org/GPG-KEY-elasticsearch | apt-key add -
- name: Adding Elasticsearch source.list.d
apt_repository: "repo='deb http://packages.elasticsearch.org/elasticsearch/{{ elasticsearch_version }}/debian stable main' state=present"
- name: Install Elasticsearch
apt: "update_cache=yes name=elasticsearch={{ elasticsearch_version }}"
- name: Deploy the elasticsearch.yml configuration file
template: "src=elasticsearch.yml.j2 dest={{ elasticsearch_config_folder }}/elasticsearch.yml owner=root group=root mode=0744"
- name: Deploy default configuration used by the startup script
template: src=elasticsearch-default.j2 dest=/etc/default/elasticsearch owner=root group=root mode=0644
tags: configuration---
- name: Adding Elasticsearch public GPG key
shell: wget -O - http://packages.elasticsearch.org/GPG-KEY-elasticsearch | apt-key add -
- name: Adding Elasticsearch source.list.d
apt_repository:
repo: "deb http://packages.elasticsearch.org/elasticsearch/{{ elasticsearch_version }}/debian stable main"
state: present
- name: Install Elasticsearch
apt:
update_cache: yes
name: "elasticsearch={{ elasticsearch_version }}"
- name: Deploy the elasticsearch.yml configuration file
template:
src: elasticsearch.yml.j2
dest: "{{ elasticsearch_config_folder }}/elasticsearch.yml"
owner: root
group: root
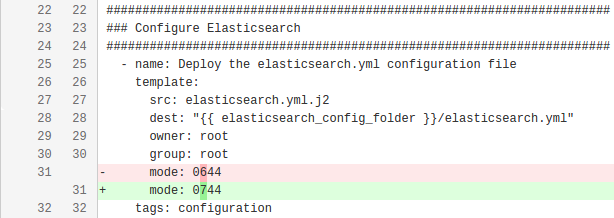
mode: 0744 #--------------------------> Change introduced here
- name: Deploy default configuration used by the startup script
template:
src: elasticsearch-default.j2
dest: /etc/default/elasticsearch
owner: root
group: root
mode: 0644
Feedback: Especially with technologies like Cassandra or Elasticsearch, new versions come with new settings ...
### /etc/ansible/ansible.cfg
...
# list any Jinja2 extensions:
jinja2_extensions = jinja2.ext.do
...---
- hosts: all
sudo: yes
vars:
ec2_tags:
Name: 'webserver-instance'
Owner: 'Unkown-owner'
AnsibleId: 'webserver'
ec2_extra_tags:
Owner: 'Florian Dambrine'
tasks:
- name: Merge the two EC2 tag dictionaries
local_action:
module: set_fact
ec2_tags: "{% do ec2_tags.update(ec2_extra_tags) %}{{ ec2_tags }}"
- debug:
var: ec2_tags
TASK: [Merge the two EC2 tag dictionaries]
ok: [instance-1 -> 127.0.0.1]
TASK: [debug ] ***************************
ok: [instance-1] => {
"var": {
"ec2_tags": {
"AnsibleId": "webserver",
"Name": "webserver-instance",
"Owner": "Florian Dambrine"
}
}
}
erb
erb
################################### Cluster ###################################
# Cluster name identifies your cluster for auto-discovery. If you're running
# multiple clusters on the same network, make sure you're using unique names.
#
cluster.name: {{ elasticsearch_cluster_name }}
################################## Logstash optimizations ####################
#Tunning performances for restarts
cluster.routing.allocation.node_initial_primaries_recoveries: {{ elasticsearch_cluster_routing_allocation_node_initial_primaries_recoveries }}
cluster.routing.allocation.node_concurrent_recoveries: {{ elasticsearch_cluster_routing_allocation_node_concurrent_recoveries }}
indices.recovery.max_bytes_per_sec: {{ elasticsearch_indices_recovery_max_bytes_per_sec }}
indices.recovery.concurrent_streams: {{ elasticsearch_indices_recovery_concurrent_streams }}
...---
elasticsearch_cluster_routing_allocation_node_initial_primaries_recoveries: 4
elasticsearch_cluster_routing_allocation_node_concurrent_recoveries: 8
elasticsearch_indices_recovery_max_bytes_per_sec: 100mb
elasticsearch_indices_recovery_concurrent_streams: 5templates/elasticsearch.yaml.j2
vars/elasticsearch-logstash.yaml
###
### elaticsearch.yaml configuration file
###
{% set elasticsearch_yaml_sorted = elasticsearch_yaml | dictsort() %}
{% for key, val in elasticsearch_yaml_sorted %}
{{ key }}: "{{ val }}"
{% endfor %}---
elasticsearch_yaml: {
'cluster.name': "logstash",
'routing.allocation.node_initial_primaries_recoveries': 4,
'routing.allocation.node_concurrent_recoveries': 8,
'discovery.zen.ping.multicast.enabled': 'false'
}templates/elasticsearch.yaml.j2
vars/elasticsearch-logstash.yaml
cluster.name: "logstash"
discovery.zen.ping.multicast.enabled: 'false'
routing.allocation.node_concurrent_recoveries: 8
routing.allocation.node_initial_primaries_recoveries: 4Output
---
dependencies:
- role: common
tags: ['common']
- role: nginx
tags: ['nginx']
- role: php
tags: ['php']
- role: aws-cli
tags: ['aws-cli']
- role: mysql
tags: ['mysql']
- role: graphite
tags: ['graphite']icinga2/meta/main.yaml
- hosts: all
sudo: yes
roles:
# Configuration part
- { role: common, tags: ['common', 'logstash-client'] }
- { role: java, tags: ['java', 'logstash-client'] }
- { role: logstash-client, tags: ['logstash-client'] }
# Monitoring part
- { role: nagios, tags: ['nagios', 'logstash-client'] }
- { role: icinga2-reload, tags: ['icinga2-reload', 'logstash-client'] }logstash-client-playbook.yaml
florian~/ansible/roles$ ls -1 | grep java
java ---> Legacy Java version
java-001 ---> Latest Java role- hosts: all
sudo: yes
roles:
# Configuration part
- { role: common, tags: ['common', 'logstash-client'] }
- { role: java, tags: ['java', 'logstash-client'] }
- { role: logstash-client, tags: ['logstash-client'] }
# Monitoring part
- { role: nagios, tags: ['nagios', 'logstash-client'] }
- { role: icinga2-reload, tags: ['icinga2-reload', 'logstash-client'] }logstash-client-playbook.yaml
- hosts: all
sudo: yes
roles:
# Configuration part
- { role: common, tags: ['common', 'logstash-client'] }
- { role: java-001, tags: ['java', 'logstash-client'] }
- { role: logstash-client, tags: ['logstash-client'] }
# Monitoring part
- { role: nagios, tags: ['nagios', 'logstash-client'] }
- { role: icinga2-reload, tags: ['icinga2-reload', 'logstash-client'] }logstash-client-001-playbook.yaml
000
001
######################################################################
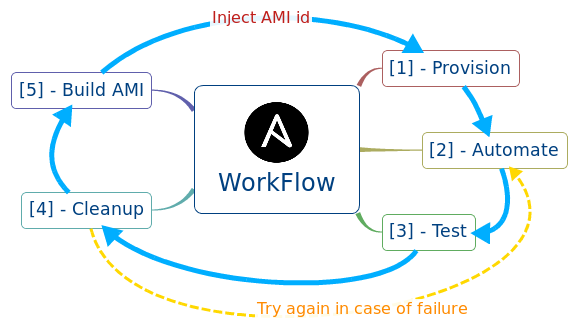
### Full stack play from provision to AMI
- hosts: 127.0.0.1
sudo: yes
vars:
- instance: forecasting-server
roles:
- { role: ec2-001, tags: ['provision'] }
- hosts: all
sudo: yes
vars:
- instance: forecasting-server
- ami_prefix_name: "{{ instance }}"
roles:
# Playbook dependencies
- { role: common-001, tags: ['configure', 'test', 'cleanup', 'create-ami', 'test-ami'] }
- { role: java-001, tags: ['configure', 'test', 'cleanup', 'create-ami', 'test-ami'] }
- { role: groovy-001, tags: ['configure', 'test', 'cleanup', 'create-ami', 'test-ami'] }
# Main Role that can be called with 'configure', 'test' and 'cleanup'
- { role: forecasting-server-001, tags: ['create-ami', 'test-ami'] }
# These two following roles allow you to create and test an AMI of the automated system
- { role: ec2-ami-001, tags: ['create-ami', 'test-ami'] }
- { role: ec2-001, tags: ['test-ami'] }
---
- include: configure.yaml tags=configure
- include: test.yaml tags=test
- include: cleanup.yaml tags=cleanuproles/forecasting-server-001/tasks/main.yaml
forecasting-server-001-playbook.yaml
What you think your automation is doing...
What your automation is really doing...
- name: Make sure Nginx is started
service:
name: nginx
state: started
- name: Wait for the service to be ready
wait_for:
host: "localhost"
port: 8080
delay: 5
timeout: 320
- name: Make sure MySql is reachable from the outside
wait_for:
host: "{{ inventory_hostname }}"
port: 3306
delegate_to: tag_Name_webserver-1- name: Make sure one API endpoint can be reached
shell: "curl -XGET --head --silent \
http://localhost:8080/hearbeat"
register: res_request
until: res_request.stdout.find("200 OK") != -1
retries: 10
delay: 10- name: Collect info about java-7-oracle
stat:
path: '/opt/java-7-oracle'
register: stat_jdk
- name: Make sure java-7-oracle exists
assert:
that:
- "stat_jdk.stat.exists"
- "stat_jdk.stat.isdir"
release-0
release-1
x5
x5
x5
x5
x5
...
...
...
### ELB Deregister tasks
- name: Gathering ec2 facts
ec2_facts:
- name: Taking the instance out of the ELB
local_action: ec2_elb
args:
aws_access_key: "{{ aws_credentials_key_id }}"
aws_secret_key: "{{ aws_credentials_secret_key }}"
region: "{{ elb_region }}"
instance_id: "{{ ansible_ec2_instance_id }}"
state: 'absent'
### Release process
- name: Restarting the Fluentd td-agent process
service: name=td-agent state=restarted
- name: Waiting for Fluentd input ports to be available
wait_for: "port={{ item.value.source.port }} delay=0"
with_dict: fluentd_forwarder_conf
### ELB register tasks
- name: Putting the instance back into the ELB
local_action: ec2_elb
args:
aws_access_key: "{{ aws_credentials_key_id }}"
aws_secret_key: "{{ aws_credentials_secret_key }}"
region: "{{ elb_region }}"
instance_id: "{{ ansible_ec2_instance_id }}"
ec2_elbs: "{{ item }}"
state: 'present'
wait_timeout: 330
with_items: ec2_elbs---
- hosts: all
serial: '5%'
sudo: yes
role:
- fluentd-forwarder-release
By Florian Dambrine
Florian Dambrine (floriandambrine.com) from GumGum will share tips, tricks, best practices, observations, and feedback from using Ansible at GumGum. GumGum's operations team manages over 500 EC2 instances using over 60 Ansible roles that touch technologies like Cassandra, Elasticsearch, Storm, and Kafka among others. The talk will include a brief overview of Ansible along with plenty of great content from working with Ansible in the trenches, followed by Q and A, making this event ideal for both newbies and veterans. This is a special treat as Florian is in Los Angeles for just a brief time before returning to France. A BIG "thank you" goes to GumGum (gumgum.com) for sponsoring both the venue and food. Please RSVP on meetup.com for this event. general directions and parking: http://smpl.org/mainlibrary.aspx venue particulars: http://smpl.org/Services/Meeting_and_Study_Rooms/Multipurpose_Room.aspx Another special thank you to GumGum for hosting this event! GumGum is the leading in-image and in-screen advertising platform, driving brand engagement for advertisers and increased revenue for publishers across every screen. Our commitment to making brand advertising work better through technology and media drives higher viewability, relevance and brand engagement than standard display advertising.




