learning
Elasticsearch

garygaowork@gmail.com
Agenda
- Introduction
- Setup & Run
- Data Indexing(REST API)
- Data Searching(REST API)
- Cluster
- Plugins
- Monitoring
- Internals
- Optimization
Introduction
Elasticsearch
Based on Lucene, Written in Java
Real time analytics
Full Text Search Engine
Distributed, Easy to Scale
High Availability
Multi tenant architecture
Document oriented(Json)
Schema Free
Restful API,Json over HTTP
Open Source:Apache License 2.0
Easy to Configure
Plugins & Community Support
Real time analytics
Full Text Search Engine
Distributed, Easy to Scale
High Availability
Multi tenant architecture
Document oriented(Json)
Schema Free
Restful API,Json over HTTP
Open Source:Apache License 2.0
Easy to Configure
Plugins & Community Support
Introduction
Scenario & Use Case
(1) Analytics engine
(2) Aggregate repository

Introduction
Use Case : Github Search
![]()
- search repositories, users, issues, pull requests
-
search 130 billion lines of code
-
track all alerts, events, logs
Introduction
Use Case : Stackoverflow
![]()
-
combines full text search with geolocation
-
uses more-like-this to find related questions and anwsers
Sina
Sina Edge
Sina S3
TODO
Introduction
Elasticsearch Basic Concepts
- What is a Document?
- What is a Document Type?
- What is an Index ?
- What is Analysis ?
- What is a Shard?
- What is a Replica?
- What is a Mapping?
- What is a Node?
- What is a Cluster?
Introduction
What is a Document ? {
"@timestamp": "2014-02-27T08:42:13.000+08:00",
"sip": "172.16.8.51",
"domain": "paikeapp.video.sina.com.cn",
"cip": "114.244.55.67",
"taketime": "0.042",
"hit": "TCP_MISS:DIRECT",
"verb": "GET",
"uripath": "/8/paikeapp.video.sina.com.cn/sport/img/884.png",
"httpversion": "1.1",
"httpcode": "404",
"bytes": "278",
"agent": "livesport/1.3 CFNetwork/672.0.8 Darwin/14.0.0",
}A type is like a table in a relational database. Each type has a list of fields that can be specified for documents of that type. The mapping defines how each field in the document is analyzed.
Introduction
What is an Index ?- ElasticSearch stores its data in logical Indices.It has a mapping which defines multiple types.Think of a table, collection or a database.
- An Index has at least 1 primary Shard, and 0 or more Replicas.
- Under the hood, ElasticSearch uses Apache Lucene library to write and read the data from the index.
Introduction
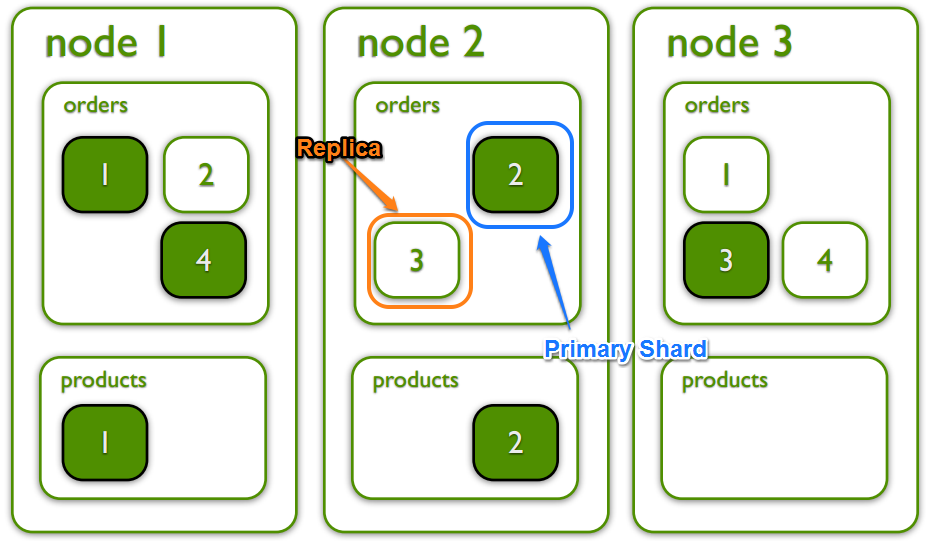
What is a Shard?- a single Lucene index
- automatically managed by elasticsearch
- distributed amongst all nodes in the cluster
What is a Replica?
- a copy of the primary shard
- Each primary shard can have zero or more replicas
Introduction
What is Analysis ?Analysis is the process of converting full text to terms.
Analysis in Indexing
Analysis in Query
"FOO BAR"
"Foo-Bar" ------> "foo" , "bar"
"foo,bar"
Introduction
What is a Mapping?
Each
index has a mapping, which defines each type
within the index, plus a number of index-wide settings.
A mapping can either be defined explicitly, or it will be generated
automatically when a document is indexed.
curl es_host:9200/my_index_name/_mapping"tweet" : {
"properties" : {
"message" : {
"type" : "string"
}
}
}
Introduction
Analogy of Elasticsearch and Relational Database
Index <---> Database
Mapping <---> Schema
Index.Type <---> Table
Document <---> Table.Row
Document.Field <---> Table.Column
Mapping <---> Schema
Index.Type <---> Table
Document <---> Table.Row
Document.Field <---> Table.Column
Introduction
Lucene basics
full text search library
Inverted Index
ElasticSearch uses Lucene to
(1) handle document indexing
(2) perform search against the indexed documents.
Introduction
Inverted Index
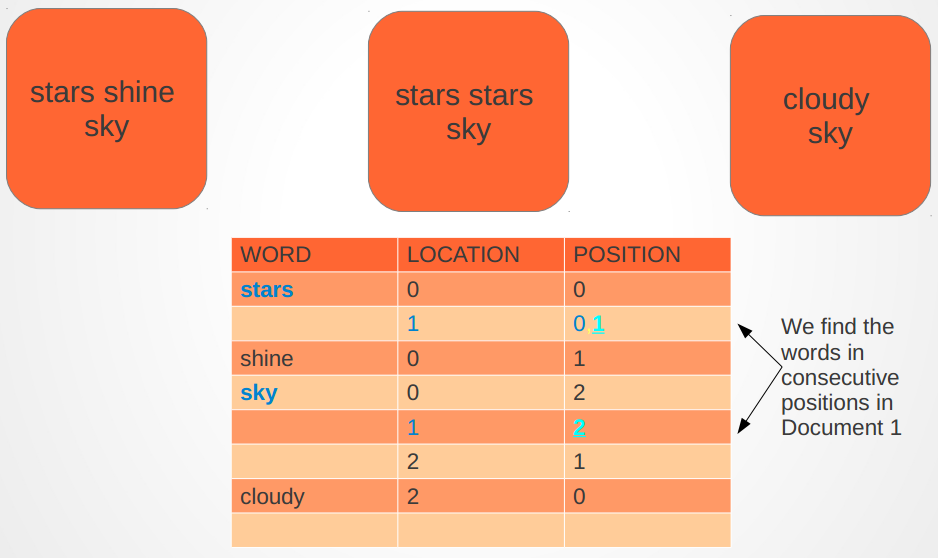
Introduction
Lucene query language
Lucene 4.6 Query Parser Syntax
TODO
Setup & Run
Elasticsearch Setup & Run
Download and unzip the latest Elasticsearch distribution
$ ./bin/elasticsearch$ curl -XGET http://es_host:9200/
{
"ok" : true,
"status" : 200,
"name" : "Slasher",
"version" : {
"number" : "0.90.11",
"build_hash" : "11da1bacf39cec400fd97581668acb2c5450516c",
"build_timestamp" : "2014-02-03T15:27:39Z",
"build_snapshot" : false,
"lucene_version" : "4.6"
},
"tagline" : "You Know, for Search"
}
Index Processing
Mapping
- define how each field of a document should be mapped to
the Search Engine and how you will eventually search your data
- dynamic mapping : automatically created and registered when a new type or new field is introduced
Index Processing
Mapping - Field Types
Mapping:
{
"type" : "string"
...
}Core Field Types:
- Strings : string
- Datetimes: date
- Numbers : byte, short, integer, log
- Floats : float, double
- Booleans : boolean
- Objects : object
Index Processing
Mapping - Type Detection
- "Trying out Elasticsearch" string
- "2014-01-09" date
- 10 byte, short, integer, long
- 3.14 float, double
- true boolean
- {corp:"sina"} object
- ["stefen", "elena"] No special mapping.Any field can have multi values
Index Processing
Mapping - Full Text vs Exact String
Mapping:
{
"type" : "string"
"index" : "analyzed"
...
}# full text(default) : "Trying out Elasticsearch" => ["Trying", "out", "Elasticsearch"] Mapping:
{
"type" : "string"
"index" : "not_analyzed"
...
}# exact string : "Trying out Elasticsearch" => ["Trying out Elasticsearch"] Mapping:
{
"type" : "string"
"index" : "no"
...
}# Not Searchable : "Trying out Elasticsearch" => []
Index Processing
Mapping - Analyzer
Mapping:
{
"type" : "string"
"index" : "analyzed"
"analyzer" : "default"
...
}or
Mapping:
{
"type" : "string"
"index" : "analyzed"
"index_analyzer" : "default"
"search_analyzer" : "default"
...
}
Index Processing
Mapping - Analyzer
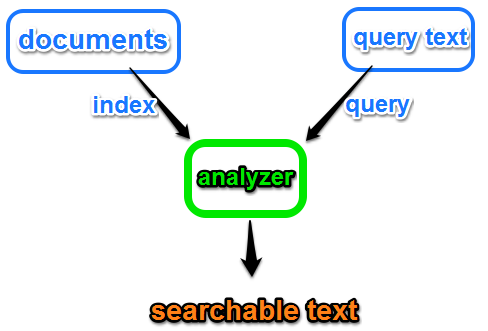
Index Processing
Mapping - Analyzer
- Standard Analyzer
- Simple Analyzer
- Whitespace Analyzer
- Stop Analyzer
- Keyword Analyzer
- Pattern Analyzer
- Language Analyzers
- Snowball Analyzer
-
Custom Analyzer(customize your analyzer)
Index Processing
Mapping - Analyzer
"The quick brown fox jumped over the lazy dogs,123-456"
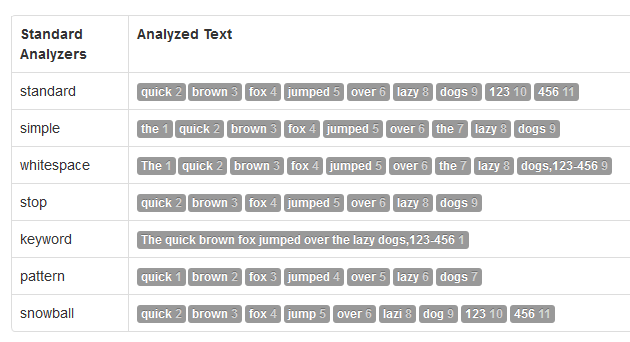
Analyze API:
$ curl -XGET 'elasticsearch_host:9200/_analyze?analyzer=standard' -d 'this is a test'
Data Indexing
Basic CRUD
Create an index named 'log':
$ curl -XPUT 'http://es_host:9200/log'{
"ok": true,
"acknowledged": true
}Delete the index 'log':
$ curl -XDELETE 'http://es_host:9200/log'{
"ok": true,
"acknowledged": true
}
Data Indexing
Basic CRUD
Create a type named 'http_log':
$ curl -XPUT 'http://es_host:9200/log/http_log/_mapping' -d '
{
"http_log": {
"properties": {
"httpcode": {
"type": "string"
},
"verb": {
"type": "string"
},
"timestamp": {
"type": "date"
},
"domain": {
"type": "string"
},
"uripathparam": {
"type": "string"
}
}
}
}'
{
"ok": true,
"acknowledged": true
}
Data Indexing
Basic CRUD
Also you can put a document without:
(1) putting an index
or
(2) putting a mapping
dynamic mapping
Data Indexing
Basic CRUD
PUT /index/type/id
Create a document(Indexing):
$ curl -XPUT 'http://es_host:9200/log/http_log/1' -d '
{
"domain":"www.sina.com.cn",
"httpcode":"404",
"verb":"GET",
"uripathparam":"/logo.png",
"timestamp":"2014-02-27T12:20:05.000+08:00"
}'
{
"ok": true,
"_index": "log",
"_type": "http_log",
"_id": "1",
"_version": 1
}
Data Indexing
Basic CRUD
Bulk Indexing:
$ curl -XPOST 'http://es_host:9200/log/_bulk' -d '
{
"index" :{
"_index": "log",
"_type":"http_log",
"_id":"1"
}
}
{
"domain": "weibo.com",
"httpcode": "404",
"verb":"GET",
"uripathparam": "/logo.png",
"timestamp": "2014-02-27T12:20:05.000+08:00"
}
{
"index" : {
"_index":"log",
"_type":"http_log",
"_id":"2"
}
}
{
"domain": "weibo.com",
"httpcode": "404",
"verb": "GET",
"uripathparam": "/logo_48_48.png",
"timestamp": "2014-02-27T12:20:05.000+08:00"
}'
Data Indexing
Basic CRUD
You get:
{
"took": 12,
"items": [
{
"index": {
"_index": "log",
"_type": "http_log",
"_id": "1",
"_version": 1,
"ok": true
}
},
{
"index": {
"_index": "log",
"_type": "http_log",
"_id": "2",
"_version": 1,
"ok": true
}
}
]
}
Data Indexing
Basic CRUD
Retrieve the document:
$ curl -XGET 'http://es_host:9200/log/http_log/1'
{
"_index": "log",
"_type": "http_log",
"_id": "1",
"_version": 1,
"exists": true,
"_source": {
"domain": "www.sina.com.cn",
"httpcode": "404",
"verb": "GET",
"uripathparam": "/logo.png",
"timestamp": "2014-02-27T12:20:05.000+08:00"
}
}
Data Indexing
Basic CRUD
Update the document's 'domain' field:
$ curl -XPOST 'http://es_host:9200/log/http_log/1/_update' -d '
{
"doc": {
"domain": "weibo.com"
}
}'
{
"ok": true,
"_index": "log",
"_type": "http_log",
"_id": "1",
"_version": 2
}
Data Indexing
Basic CRUD
Delete the document:
$ curl -XDELETE 'http://es_host:9200/log/http_log/1'
{
"ok": true,
"found": true,
"_index": "log",
"_type": "http_log",
"_id": "1",
"_version": 3
}
Data Searching
Search Data:Search API & Query DSL
-
How to query ElasticSearch using its Query DSL ?
- How to use basic queries ?
- How to use compound queries ?
- How to filter your results and why it is important ?
- How to change the sorting of your results ?
- How to use scripts in ElasticSearch ?
Data Searching
Search Data:Search API & Query DSL
Search Endpoint:
GET elasticsearch_host:9200/ index/type/ _search
Data Searching
Search Data:Search API & Query DSL
Query DSL:
queries:
term query terms query match query multi match query
query string query prefix query fuzzy query
wildcard query range query ......
Filters:
query filter range filter term filter terms filter
and filter or filter not filter bool filter
missing filter prefix filter exists filter ......
Data Searching
Search Data:Search API & Query DSL
Basic Queries
Data Searching
Search Data:Search API & Query DSL
Simplest Query:
$ curl -XGET 'localhost:9200/twitter/tweet/_search?q=user:linken
This is acturally term query :
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"query" : {
"term" : { "user" : "linken" }
}
}
'
/\
||
||
Query DSL
Term Query:
Matches documents that have fields that contain a term (not analyzed).
Matches documents that have fields that contain a term (not analyzed).
Data Searching
Search Data:Search API & Query DSL
Terms Query:
A query that match on any (configurable) of the provided terms.
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"query" : {
"terms" : {
"tags" : [ "novel", "book" ],
"minimum_should_match" : 1
}
}
}
'
# returns all the documents that have one or both of the searched terms in the "tags" field.
"minimum_should_match" : 1 # one term should be matched
"minimum_should_match" : 2 # both term should be matched
Data Searching
Search Data:Search API & Query DSL
Match Query:
accepts text/numerics/dates, analyzes it, and constructs a query out of it.
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"query" : {
"match" : {
"tweet" : "duck dog cat"
}
}
}
'
# match all the documents that have the terms "duck" or "dog" or "cat" in the "title" field.
Data Searching
Search Data:Search API & Query DSL
Multi Match Query:
The multi_match query builds on the match query to allow multi-field queries.
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"query" : {
"multi_match" : {
"query": "this is a test",
"fields": [ "subject", "message" ]
}
}
}
'
# query on "subject" and "message" fields.Warning : Deprecated in 1.1.0. Replaced by multi_query .
Data Searching
Search Data:Search API & Query DSL
TODO, Query String Query:
A query that uses a query parser in order to parse its content.
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"query" : {
"multi_match" : {
"query": "this is a test",
"fields": [ "subject", "message" ]
}
}
}
'
# query on "subject" and "message" fields.
Data Searching
Search Data:Search API & Query DSL
Prefix Query:
Matches documents that have fields containing terms with a specified prefix (not analyzed).
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"query" : {
"prefix" : {
"user" : "ki"
}
}
}
'
# matches documents where the "user" field contains a term that starts with "ki"
Data Searching
Search Data:Search API & Query DSL
Match All Query:
matches all documents.
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"query" : {
"match_all" : { }
}
}
'
# matches all documents of "tweet" type of "twitter" index.
Data Searching
Search Data:Search API & Query DSL
Wildcard Query:
allows us to use the * and ? wildcards in the values we search for(not analyzed).
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"query" : {
"wildcard" : {
"user" : "kimi*"
}
}
}
'
# matches documents start with "kimi".* : 0-n character sequence
? : any single character
Data Searching
Search Data:Search API & Query DSL
Range Query:
Matches documents with fields that have terms within a certain range.
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"query" : {
"range" : {
"age" : {
"gte" : 10,
"lte" : 20
}
}
}
}
'
# matches all documents where age is between 10 and 20.gte Greater-than or equal to
gt Greater-than
lte Less-than or equal to
lt Less-than
Data Searching
Search Data:Search API & Query DSL
Filtering your results
Data Searching
Search Data:Search API & Query DSL
Range Filter:
Filters documents with fields that have terms within a certain range.
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"filter" : {
"range" : {
"age" : {
"gte": 10,
"lte": 20
}
}
}
}
'
# matches all documents where age is between 10 and 20.gte Greater-than or equal to
gt Greater-than
lte Less-than or equal to
lt Less-than
Data Searching
Search Data:Search API & Query DSL
Script Filter:
A filter allowing to define scripts as filters.
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{ "filter" : { "script" : { "script" : "doc['year'].value = param1" "params" : { "param1" : 2014 } } } }
'
# matches all documents where "year" field is 2014.# "param1" is a custom parameter.
Data Searching
Search Data:Search API & Query DSL
Type Filter:
Filters documents matching the provided document / mapping type.
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"filter" : {
"type" : {
"value" : "my_type"
}
}
}
'
# matches all documents where mapping type is "my_type".
Data Searching
Search Data:Search API & Query DSL
Ids Filter:
Filters documents that only have the provided ids.
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"filter" : {
"ids" : {
"type" : "my_type",
"values" : ["1", "4", "100"]
}
}
}
'
# matches documents where mapping type is "my_type" and value of "_uid" field in "1", "4", "100".
Data Searching
Search Data:Search API & Query DSL
Query Filter:
Wraps any query to be used as a filter.
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"filter" : {
"query" : {
"query_string" : {
"query" : "this AND that OR thus"
}
}
}
}
'
# query "query_string" acts as a filter.
Data Searching
Search Data:Search API & Query DSL
You don't have to wrap
Term Query/Range Query
because we have
Term Filter/Range Filter
Data Searching
Search Data:Search API & Query DSL
Term Filter:
Filters documents that have fields that contain a term (not analyzed).
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"filter" : {
"term" : {
"user" : "kimchy"
}
}
}
'
# matches documents where "user" field is "kimchy". Similar to term query, except that it acts as a filter:
(1) cached by default
(2) no scoring
(2) no scoring
Data Searching
Search Data:Search API & Query DSL
Range Query vs Range Filter ?
Term Query vs Term Filter ?
-
The only difference in the result will be in the scoring.
-
Every document returned by a filter will have a score of 1.0.
Data Searching
Search Data:Search API & Query DSL
To make it even more complicated:
Queries can contain other queries.
Some queries can contain filters, and others can contain both queries and filters.
Data Searching
Search Data:Search API & Query DSL
Compound queries & filters
Data Searching
Search Data:Search API & Query DSL
Bool Query:
A query that matches documents matching boolean combinations of other queries.
It is built using one or more boolean clauses, each clause with a typed occurrence:
must The clause (query) must appear in matching documents. should The clause (query) may or may not appear in the matching document. must_not The clause (query) must not appear in the matching documents.
For example, if you want to
- find all the documents that have the term "crime" in the "title" field.
- In addition, they may or may not have a range of 1900 to 2000 in the "year" field
- and must not have the term "nothing" in the "otitle" field.
Data Searching
Search Data:Search API & Query DSL
The query may looks like:
$ curl -XGET 'localhost:9200/library/books/_search -d '
{
"query" : {
"bool" : {
"must" : {
"term" : {
"title" : "crime"
}
},
"should" : {
"range" : {
"year" : {
"from" : 1900,
"to" : 2000
}
}
},
"must_not" : {
"term" : {
"otitle" : "nothing"
}
}
}
}
}
'
Data Searching
Search Data:Search API & Query DSL
Constant Score Query:
Wraps another query (or filter) and return a constant score for each document returned by the wrapped query (or filter).
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"user" : "kimchy"
}
},
"boost" : 1.2
}
}
}
'
# if we want to have a score of 1.2 for all the documents that have the term "kimchy" in the "user" field.
Data Searching
Search Data:Search API & Query DSL
bool filter: Similar in concept to Boolean query, except that the clauses are other filters.
and filter: Take an array of filters and return every document that matches all of them.
or filter: Take an array of filters and return every document that matches at least one of them.
not filter: Returned documents are the ones that were not matched by the enclosed filter
All these filters are not cached by default.
Data Searching
Search Data:Search API & Query DSL
These filters also can be combined together:
{
"filter": {
"not": {
"and": [
{
"term": {
"title": "Catch-22"
}
},
{
"or": [
{
"range": {
"year": {
"from": 1930,
"to": 1990
}
}
},
{
"term": {
"available": true
}
}
]
}
]
}
}
}
Data Searching
Search Data:Search API & Query DSL
Queries VS Filters
TODO
relationships among Query ,Filter,Facets?
Data Searching
Search Data:Search API & Query DSL
See more queries and filters at:
http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl.html
Data Searching
Search Data:Search API & Query DSL
Paging:
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"from" : 9,
"size" : 20,
"query" : {
"term" : { "user" : "linken" }
}
}
'
/\
||
||
Query DSL
- from : the offset from the first result you want to fetch.
- size : the maximum amount of hits to be returned.
Data Searching
Search Data:Search API & Query DSL
Choose the fields we want to return:
$ curl -XGET 'localhost:9200/twitter/tweet/_search -d '
{
"fields" : [ "content", "upvotes" ],
"query" : {
"term" : { "user" : "linken" }
}
}
'
/\
||
||
Query DSL
Data Searching
Search Data:Multi-Index, Multi-Type
- we can search on all documents across all types within the twitter index:
$ curl -XGET 'http://localhost:9200/twitter/_search?q=user:kimchy'
- We can also search within specific types:
$ curl -XGET 'http://localhost:9200/twitter/tweet,user/_search?q=user:kimchy'
- We can also search all tweets with a certain tag across several indices:
$ curl -XGET 'http://localhost:9200/kimchy,elasticsearch/tweet/_search?q=tag:wow'
- Or we can search all tweets across all available indices using _all placeholder:
$ curl - XGET 'http://localhost:9200/_all/tweet/_search?q=tag:wow'
- Or even search across all indices and all types:
$ curl -XGET 'http://localhost:9200/_search?q=tag:wow'
Data Searching
Search Data:Facets
-
Terms - counts by distinct terms (values) in a field
-
Range - counts for a given set of ranges in a field
-
Histogram and Date Histogram - counts by constant interval ranges
-
Statistical - statistical summary of a field (mean, sum etc)
-
Terms Stats - statistical summary on one field (stats field) for distinct terms in another field. For example, spending stats per department or per region.
-
Geo Distance: counts by distance ranges from a given point
Distributed Elasticsearch
Elasticsearch Cluster
TODO:Setup, Configuration, Deployment,Upgrade Cluster
Routing
Elasticsearch Plugins
What can plugins do ?
Node discovery
Analysis Monitoring
River
Transport
Scripting
Snapshot/Restore
Elasticsearch Plugins
Popular Plugins
AWS Cloud Plugin Redis River Plugin
BigDesk Plugin Elasticsearch Head Plugin
Inquisitor Plugin Paramedic Plugin
See more plugins:
http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/modules-plugins.html
Elasticsearch Plugins
Install & Remove Plugin
#####INSTALL
# elasticsearch_dir/bin/plugin --install <org>/<user/component>/<version>
#For example:
$ cd elasticsearch_dir
$ bin/plugin --install mobz/elasticsearch-head
$ bin/plugin --install lukas-vlcek/bigdesk
##installed elasticsearch-head plugin and bigdesk plugin.
#####REMOVE
# plugin --remove <pluginname>
#For example:
$ bin/plugin --remove head
$ bin/plugin --remove bigdesk
Elasticsearch Monitoring
We are monitoring:
Cluster State
CPU,Memory,Disk
Index Size
Request Rate
......
TODO
Elasticsearch Monitoring
Useful Tools
Elasticsearch Marvel
Bigdesk
Head
Curator:https://github.com/elasticsearch/curator
......
TODO
Elasticsearch Monitoring
Elasticsearch Marvel
metrics, screenshots.....
TODO
Internals
Lucene
ElasticSearch is based on Apache’s Lucene and borrows many concepts.
Lucene:
Segments and merge
Analysis
Indexing and querying
Internals
Analysis
References
[1] Elasticsearch References
http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/index.html
[2] Your Data, Your Search
http://www.slideshare.net/karmi/your-data-your-search-elasticsearch-euruko-2011
[2] Getting Down and dirty with Elasticsearch
http://www.slideshare.net/clintongormley/down-and-dirty-with-elasticsearch
[3] Elastic Search Training#1 (brief tutorial)-ESCC#1
http://www.slideshare.net/medcl/elastic-search-training1-brief-tutorial
[4] Elasticsearch :Search made easy for (web) developers (some contents are out dated)
http://spinscale.github.io/elasticsearch/2012-03-jugm.html#/
[5] Elasticsearch :Pluggable architecture under the hood
http://spinscale.github.io/elasticsearch-intro-plugins/#/
[6] Learning ElasticSearch — Fifth Elephant 2013, Bangalore.Anurag Patel Red Hat
http://www.slideshare.net/gnurag/workshop-learning-elasticsearch
References
[7] Elasticsearch References: Glossary of terms
http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/glossary.html#glossary
[8] Exploring Elasticsearch
http://exploringelasticsearch.com/
[9] Beginner's guide to ElasticSearch
http://stackoverflow.com/questions/11593035/beginners-guide-to-elasticsearch
[10] What is an ElasticSearch Index?
http://euphonious-intuition.com/2013/02/what-is-an-elasticsearch-index/
[11] An introduction to mapping in elasticsearch
http://euphonious-intuition.com/2012/07/an-introduction-to-mapping-in-elasticsearch/
[12] Elasticsearch Aggregations Overview
http://chrissimpson.co.uk/elasticsearch-aggregations-overview.html
References
[13] Querying ElasticSearch - A Tutorial and Guide
http://okfnlabs.org/blog/2013/07/01/elasticsearch-query-tutorial.html
[13] Terms of endearment - the ElasticSearch Query DSL explained
http://www.slideshare.net/clintongormley/terms-of-endearment-the-elasticsearch-query-dsl-explained
[14] Elasticsearch Facets
http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/search-facets.html
[15] Mastering Elasticserach
http://www.PacktPub.com
[16] Elasticsearch Search API
http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/search.html
[17] Lucene Scoring and elasticsearch’s _all Field
http://jontai.me/blog/2012/10/lucene-scoring-and-elasticsearch-_all-field/
[18] Advanced Scoring in elasticsearch
http://jontai.me/blog/2013/01/advanced-scoring-in-elasticsearch/
References
[19] Collect & visualize your logs with Logstash, Elasticsearch & Redis
http://michael.bouvy.net/blog/en/2013/11/19/collect-visualize-your-logs-logstash-elasticsearch-redis-kibana/
[20] elasticsearch resources
http://www.elasticsearch.org/resources/
[21] Apache Lucene - Query Parser Syntax
http://lucene.apache.org/core/4_6_0/queryparser/org/apache/lucene/queryparser/classic/package-summary.html#Overview
The following articles are about Elasticsearch Optimization:
[22] elasticsearch configuration
http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/setup-configuration.html#setup-configuration-memory
[23] Bigdesk - Live charts and statistics for elasticsearch cluster.
http://bigdesk.org/
[24] ElasticSearch and Logstash Tuning
http://jablonskis.org/2013/elasticsearch-and-logstash-tuning/
References
[25] Elasticsearch Configuration and Performance Tuning
http://weiweiwang.github.io/elasticsearch-configuration-and-performance-tuning.html
[26] Scaling Massive Elasticsearch Clusters
http://www.slideshare.net/sematext/scaling-massive-elasticsearch-clusters
[27] Elasticsearch Java Virtual Machine settings explained
http://jprante.github.io/2012/11/28/Elasticsearch-Java-Virtual-Machine-settings-explained.html
[28] ElasticSearch Training#2 (advanced concepts)-ESCC#1
http://www.slideshare.net/medcl/elastic-search-training2-advanced-concepts
[29] All about Elasticsearch Filter BitSets
http://euphonious-intuition.com/2013/05/all-about-elasticsearch-filter-bitsets/
Q & A
Learning Elasticsearch
By Gary Gao
Learning Elasticsearch
Learn Elasticsearch basic concepts,setup & conf,rest api and optimization.



