Data scraping with Python3
Anna Keuchenius
PhD candidate Sociology
@AKeuchenius
Javier Garcia-Bernardo
PhD candidate Political Science
@JavierGB_com
Computational Social Science Amsterdam
CSSamsterdam.github.io
Slides available at
slides.com/jgarciab/web_scraping
github.com/jgarciab/web_scraping
Notebook available at
https://CSSamsterdam.github.io/

Structure
- Beginners (10:00-14:30):
- What is data scraping
- Static websites.
- HTML
- Libraries: requests and beautifulSoup
- Extracting tables from websites
- Dynamic websites
- APIs and Javascript
- Behaving like a human: selenium
- Tapping into the APIs: requests and ad-hoc libraries
- Legality and morality of data scraping
Structure
-
Advanced (15:00-17:00):
- Tapping into hidden APIs: requests
- Session IDs
- Setting up crawlers:
- CRON jobs
- Processes
- scrapy
- Common problems when scraping:
- Proxies
- Speed up requests
- Selenium problems (scroll down, ElementNotVisible exception etc.)
- Robust scraping
- CREA (17:00 onwards)
What is data scraping?
- Easy
- Great return on investment
- A very powerful experience
- Extracting data from the web in an automatic manner
Part 1: Static websites
https://www.boulderhumane.org/animals/adoption/dogs
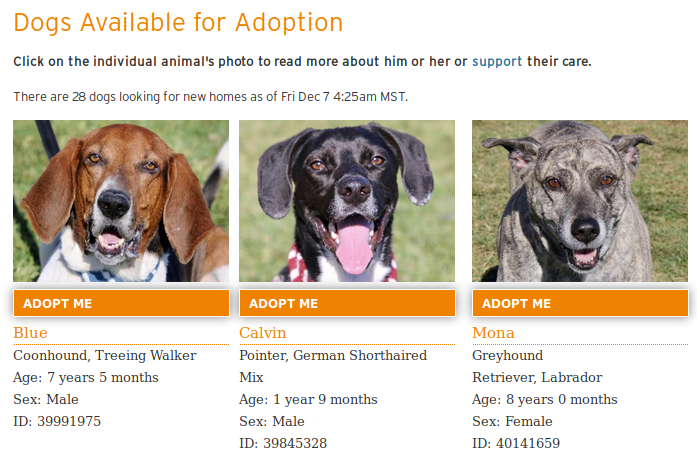
https://www.boulderhumane.org/animals/adoption/dogs

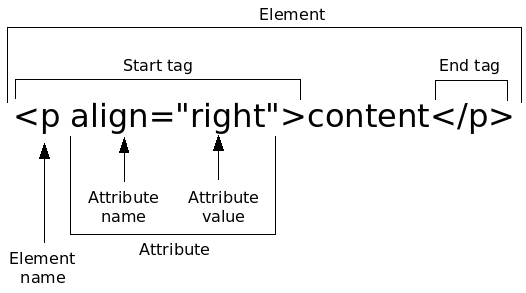
1.1 HTML
Drawing from: http://www.scriptingmaster.com/html/basic-structure-HTML-document.asp

html tag tells the browser that it's a website
metadata, style, title...
content
1.1 HTML: Tree structure
1.1 HTML: Tree structure
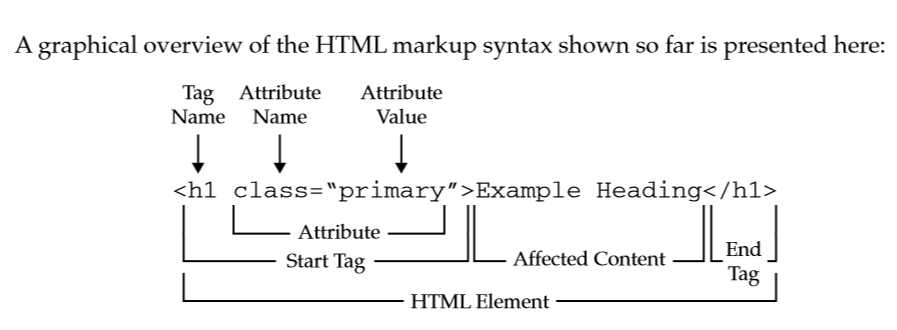
Tag list:
- div → basic container
- a → link to url
- p → paragraph
- h1/h2/h3/h4/h5/h6 → titles
- img → image
- table → tables
Attribute names:
- href → url
- src → source of image
- class → usually sets the style
- align / color... → gives style
- id / name → names
- title → text on hover
1.2 How to extract the information?
Step 1: Download data --> library requests
Step 2: Parse data --> library beautifulSoup
1.2.1 Requests
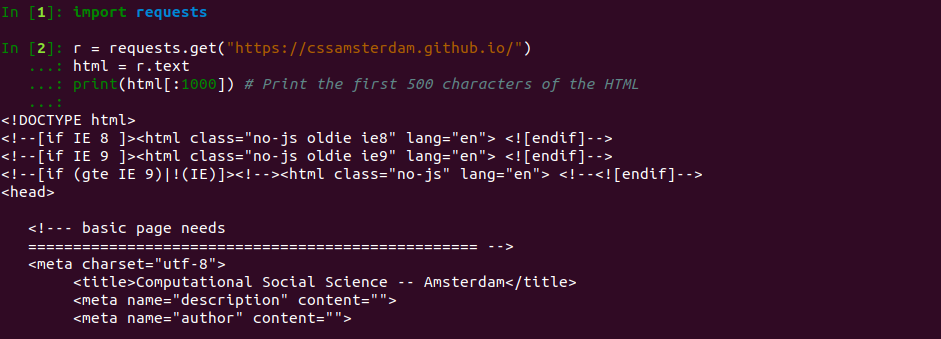
1.2.1 Requests
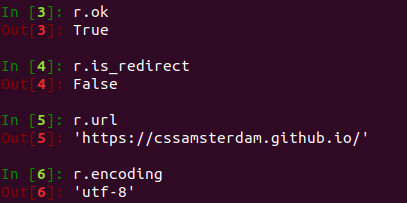
More info at http://docs.python-requests.org
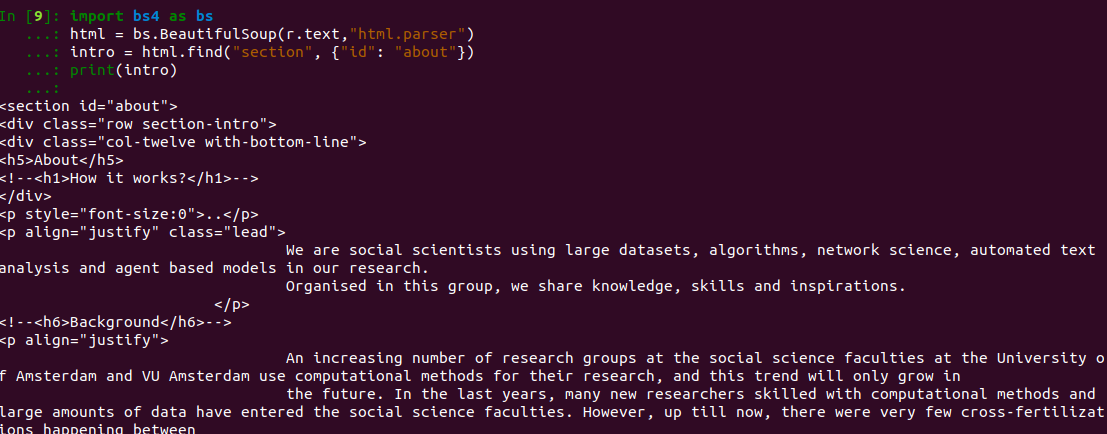
1.2.2 BeautifulSoup

Let's get the intro from
CSSamsterdam.github.io
1.2.2 BeautifulSoup
1.2.2 BeautifulSoup


find returns an HTML element
Some useful things to do with it

find_all returns a list of HTML elements
1.2.2 Finding the right tag: Inspect element
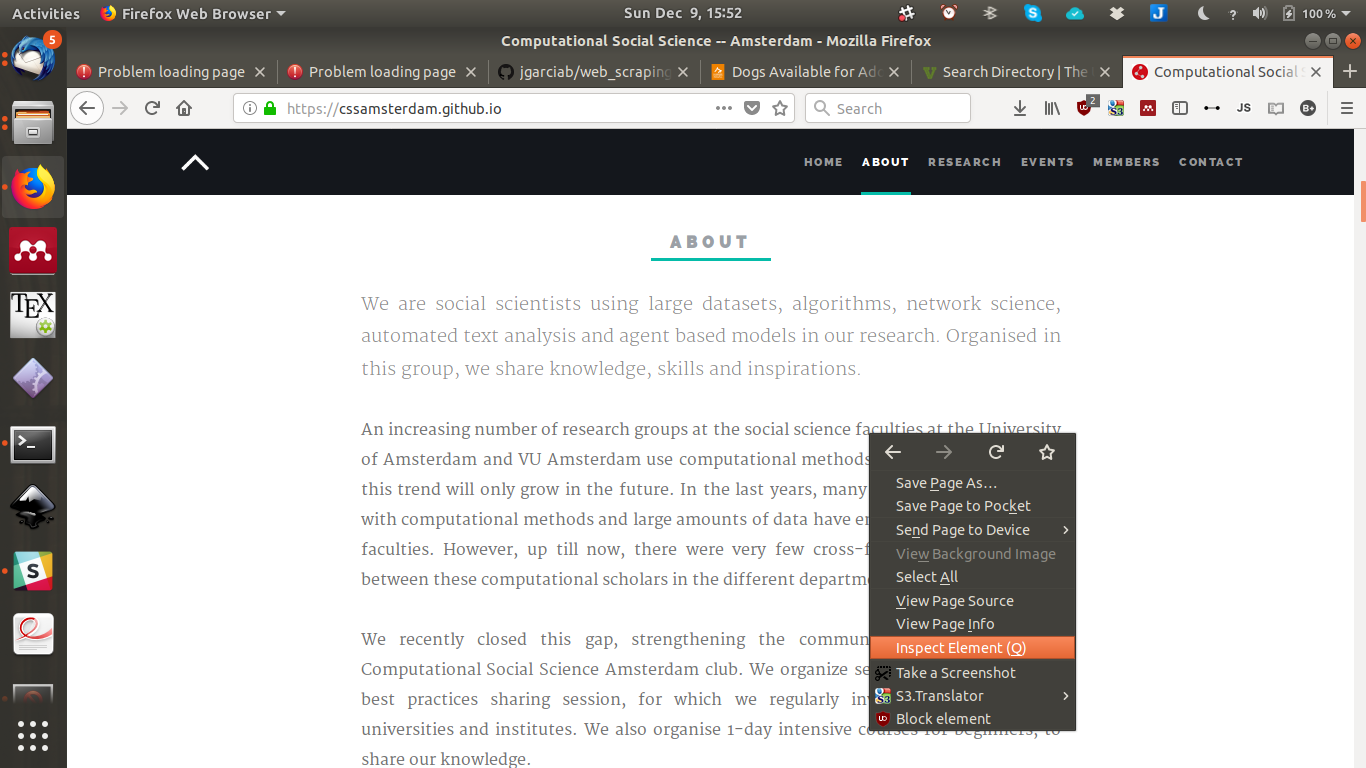
1.2.2 Finding the right tag: Inspect element
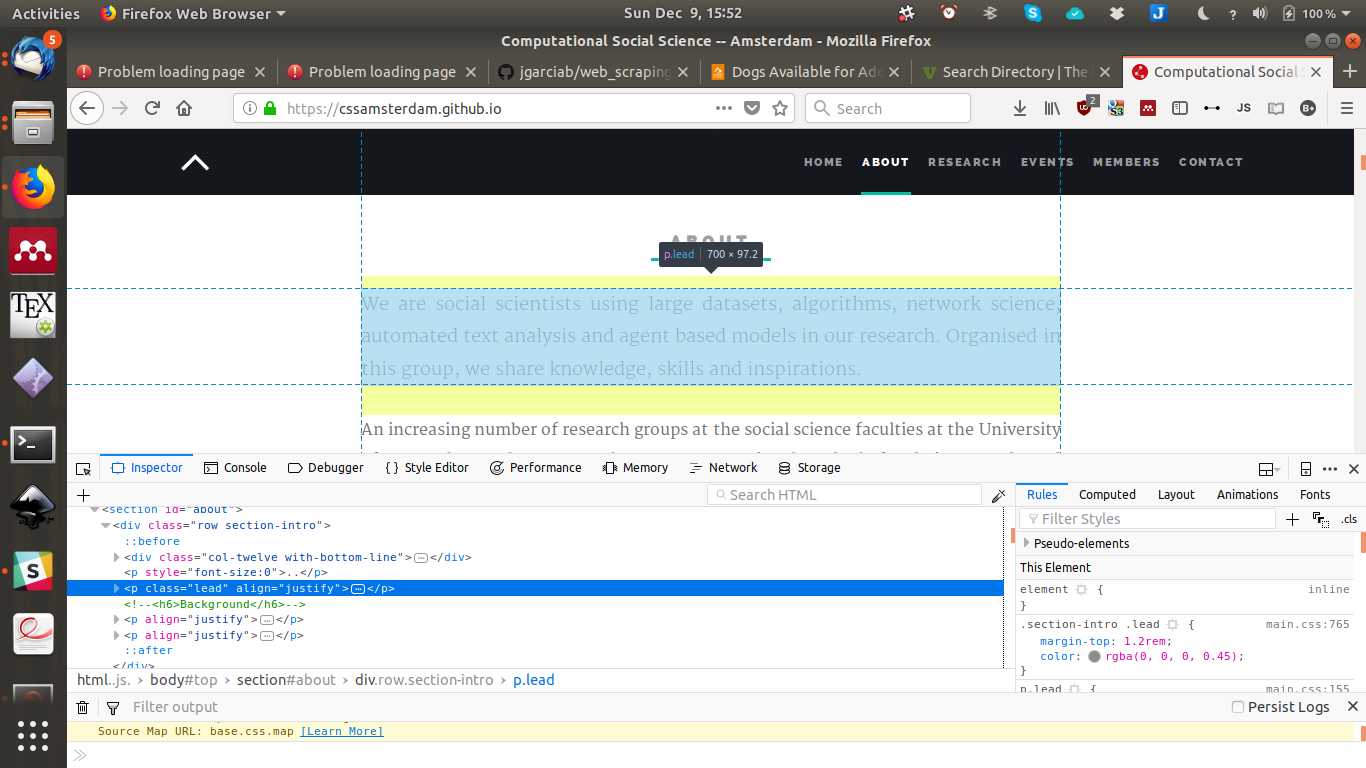
Time to play
1.3: Tables from websites
https://en.wikipedia.org/wiki/List_of_sandwiches
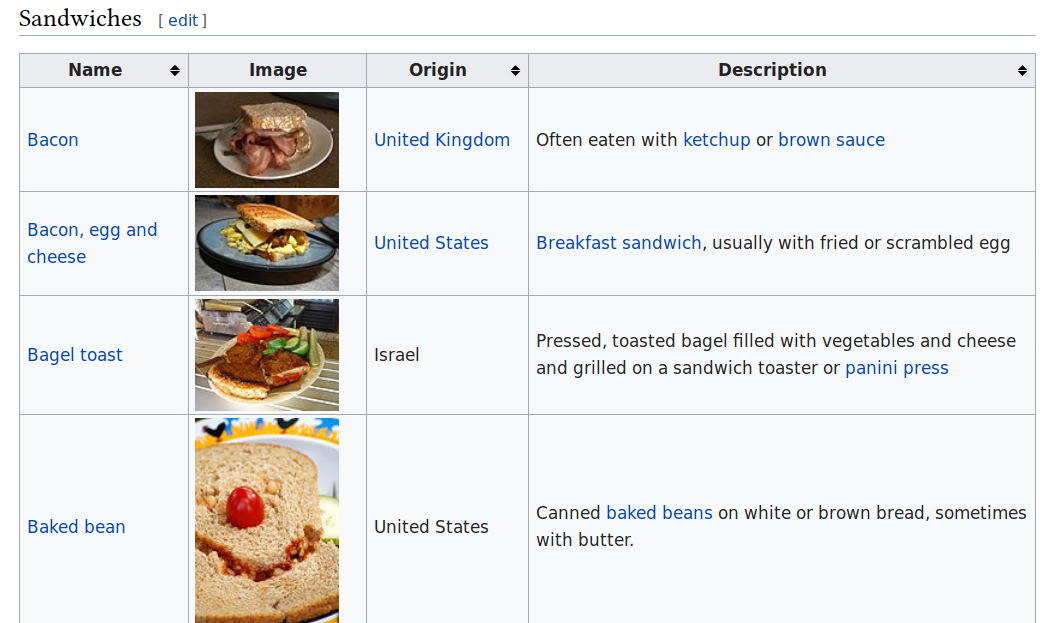
table = pd.read_html("https://en.wikipedia.org/wiki/List_of_sandwiches",
header=0)[0]
URL
read_html returns a list, keep the first table
The first line is the header
Part 2: Dynamic websites
- 2.1: APIs/Javascript
- 2.2: Behaving like a human
- 2.3: Tapping into the API
- 2.3.1 Explicit APIs
- Part 4: "Hidden" APIs (advanced)
2.1 API/JavaScript
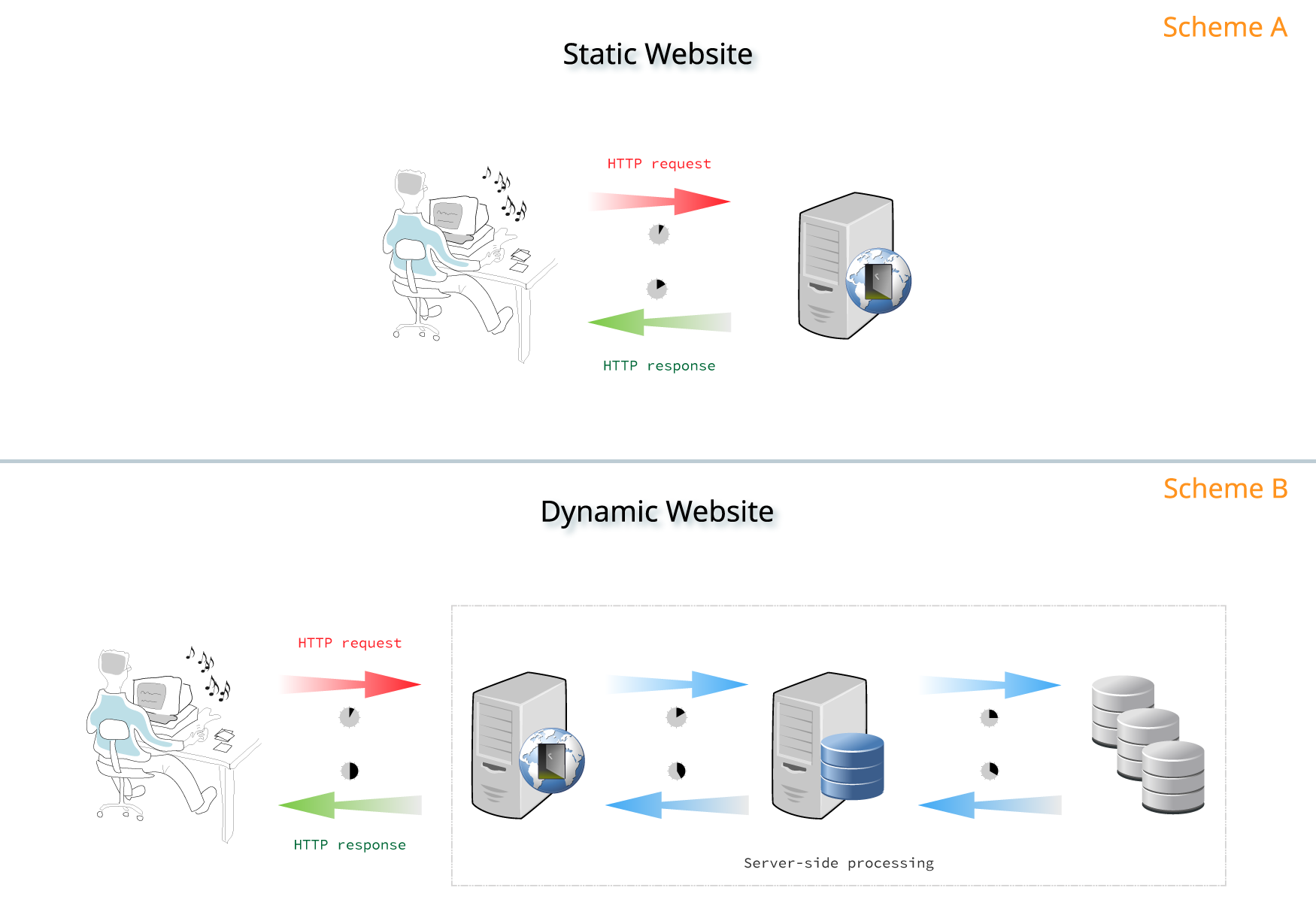
Source: https://about.gitlab.com/2016/06/03/ssg-overview-gitlab-pages-part-1-dynamic-x-static/
API
2.1 API/JavaScript
HTTP request
HTTP request
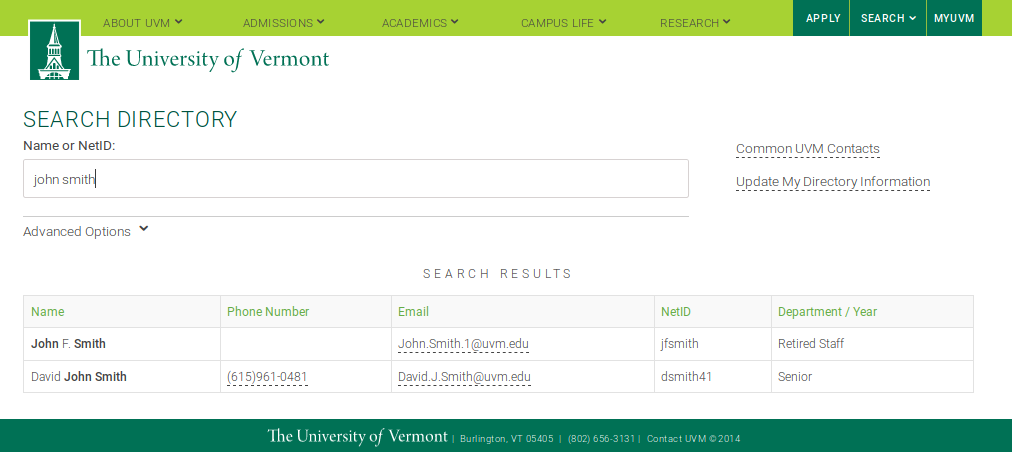
https://www.uvm.edu/directory


Part 4 (advanced)
2.2 Behaving like a human

selenium
Requirements (one of the below):
- Firefox + geckodriver (https://github.com/mozilla/geckodriver/releases)
- Chrome + chromedriver (https://sites.google.com/a/chromium.org/chromedriver/)
Some characteristics of HTML scraping with Selenium it:
- (b) can handle javascript
- (c) gets HTML back after the Javascript has been rendered
- (d) can behave like a person
- (a) can be slow
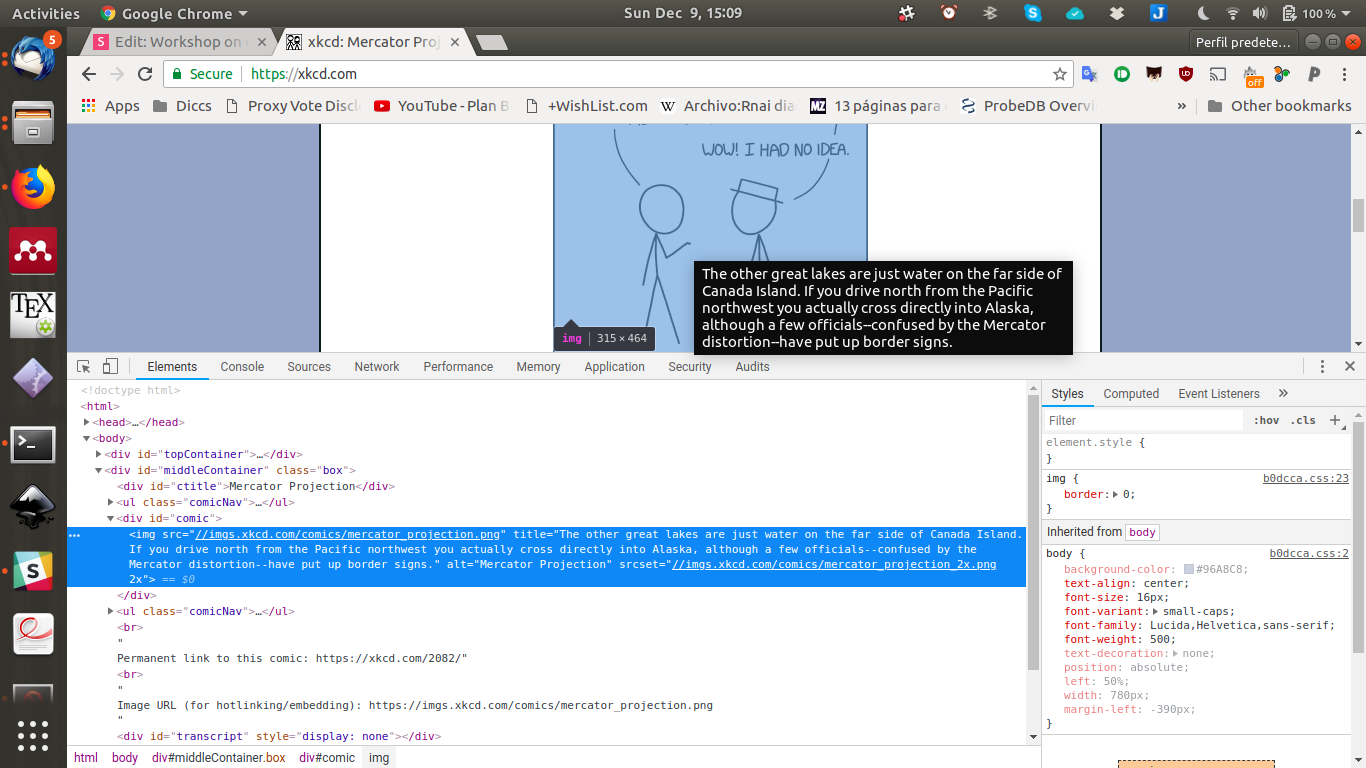
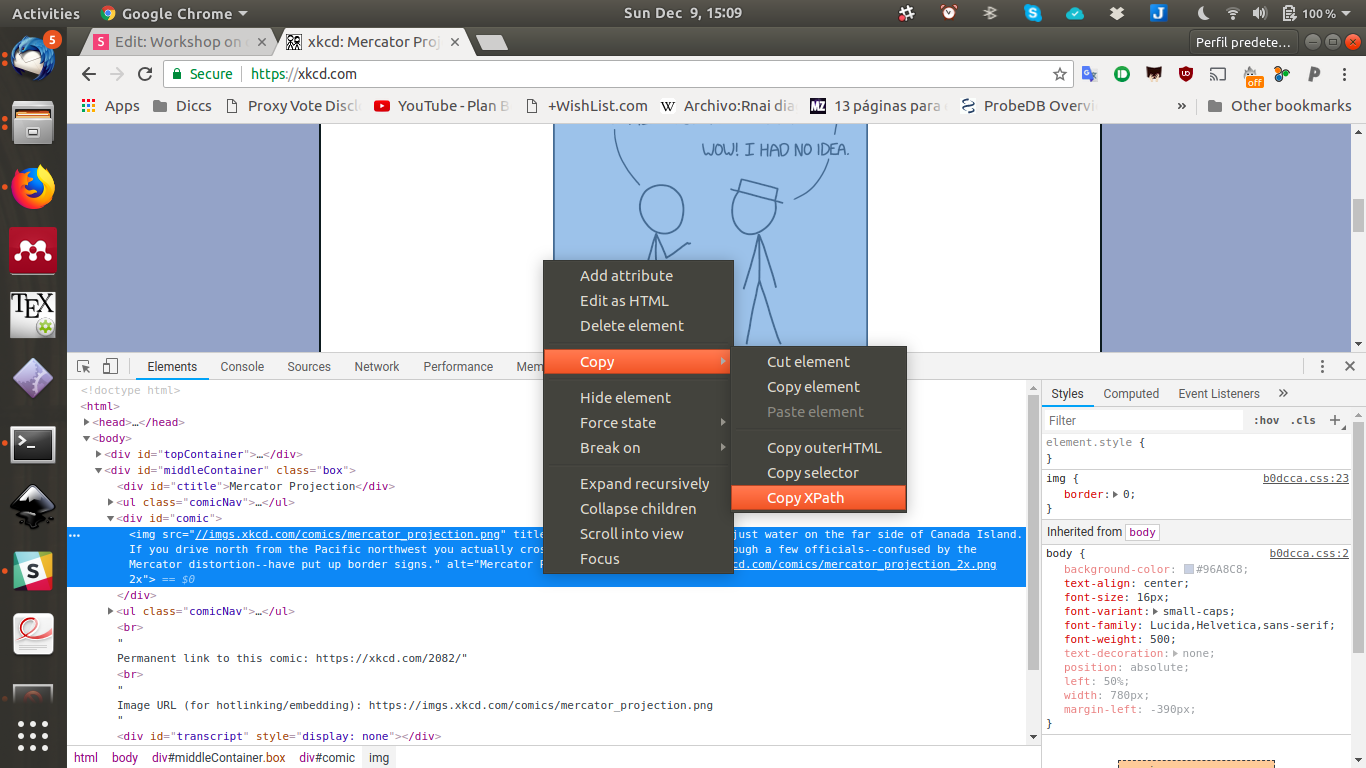
2.2 selenium
# Get the xkcd website
driver.get("https://xkcd.com/")
# Find the title of the image
element = driver.find_element_by_xpath('//*[@id="comic"]/img')
element.get_attribute("title")
Time to play
2.3: Tapping into the API
Source: https://about.gitlab.com/2016/06/03/ssg-overview-gitlab-pages-part-1-dynamic-x-static/
API
2.3 working with APIs
API
- The company tells you the language of the server (the API)
- You communicate with the server through HTTP requests
- Usually sets up some restrictions
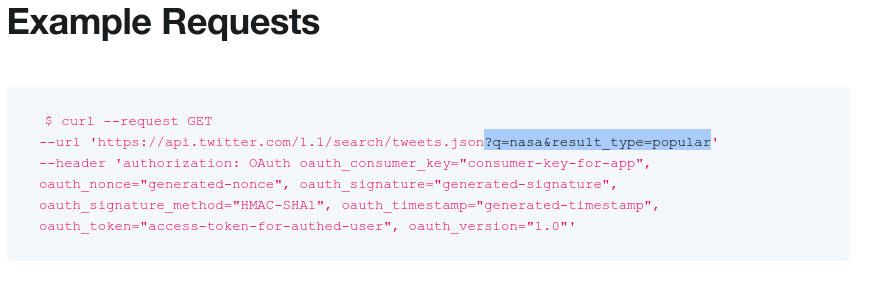
- Example: Twitter API
- https://developer.twitter.com/en/docs/tweets/search/overview
2.3.1 Explicit APIs


Practice:
- Find a library: https://dev.twitter.com/resources/twitter-libraries
- We'll use https://github.com/tweepy/tweepy
2.3.1 Explicit APIs
Theory:
Time to play
3: Ethics and legality
3: Ethics and legality
Is it legal?:
- Possibly... recent court cases have supported the accused, even when the Terms of Use disallowed data scrapping
- Personal data cannot be protected by copyright (but... consult a lawyer)
- Read the Terms of Use of the website
- When dealing with personal data make sure to comply with the EU General Data Protection Regulation (GDPR)
- Data processing is lawful, fair and transparent.
- For research: You are required to go through ethics review (IRB) before collecting the data.
- Consult a lawyer in case of doubt
3: Ethics and legality
Is it ethical?
- For personal use or research is typically ethical to scrape data (in my opinion)
-
Use rule #2: Don't be a dick:
- Use an API if one is provided, instead of scraping data
- Use a reasonable crawl rate (~2 request per minute, or whatever says in robots.txt) and scrape at night.
- Identify your web scraper (e.g. headers = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5); myproject.github.io; Javier Garcia-Bernardo (garcia@uva.nl)"})
-
Ask for permission:
- If the ToS or robots.txt disallows scraping
- Before republishing the data
Adapted from: https://benbernardblog.com/web-scraping-and-crawling-are-perfectly-legal-right/
Break
Advanced workshop
4. Tapping into "hidden" APIs

Advantage: Very fast and more reliable
4: Finding the API: HTTP Requests
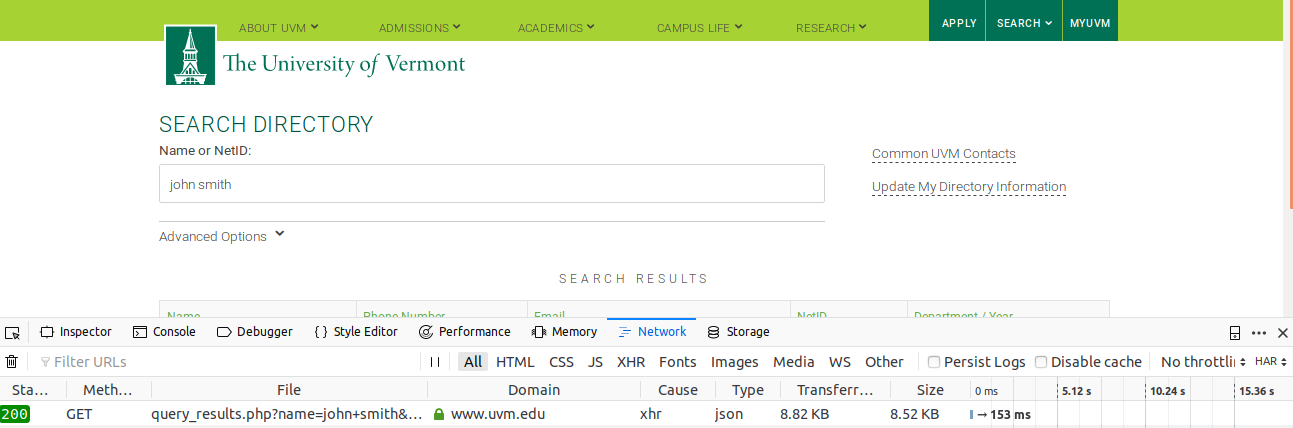
4: Finding the API: HTTP Requests

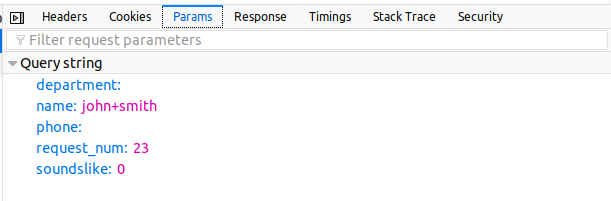
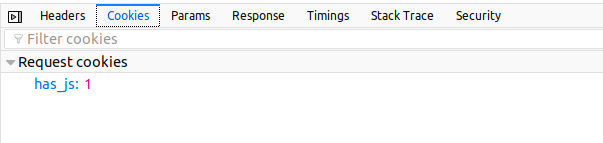
HEADER
PARAMETERS
COOKIES
- Usually not needed, but you should identify yourself just in case the website owner wants to contact you
- user-agent is many times used to restrict the person
- You can change it in every request. Problem: ethics
- Sometimes the website only works if you are redirected from another site (more on that later)
Usually not needed
- Here is the "language" of the API, the field name is what we want here
- Sometimes you just add the parameters in the url:
https://www.uvm.edu/directory/api/query_results.php?name=john+smith&department=
4: Create queries
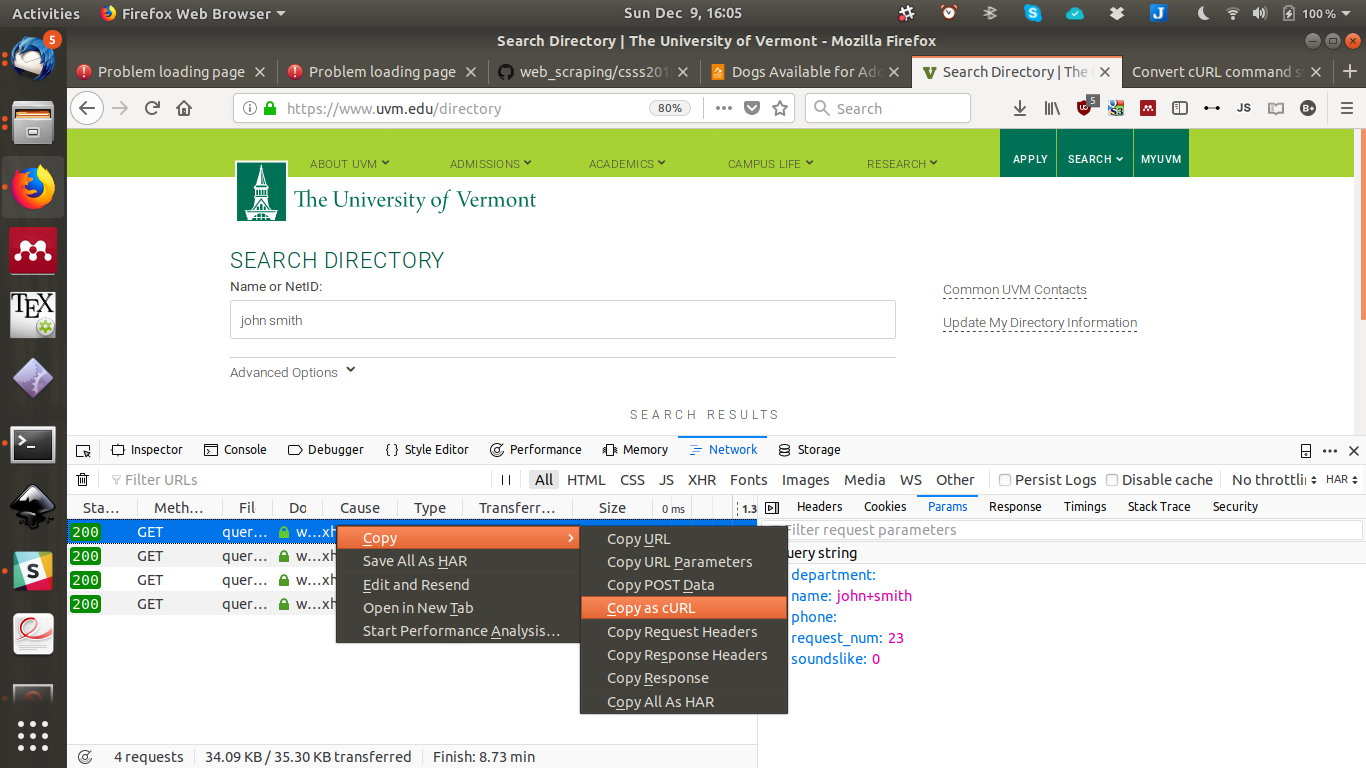
Step 1: Find the cULR command
4: Create queries
Step 2: Create the Python requests: http://curl.trillworks.com/

Step 3: Get the data remembering rule #2
Session ID's
Easiest way to deal with session IDs: behave like a human >> use selenium
If that is too slow, use 'hidden api' method with variable parameters.
selenium
Detect session id from page
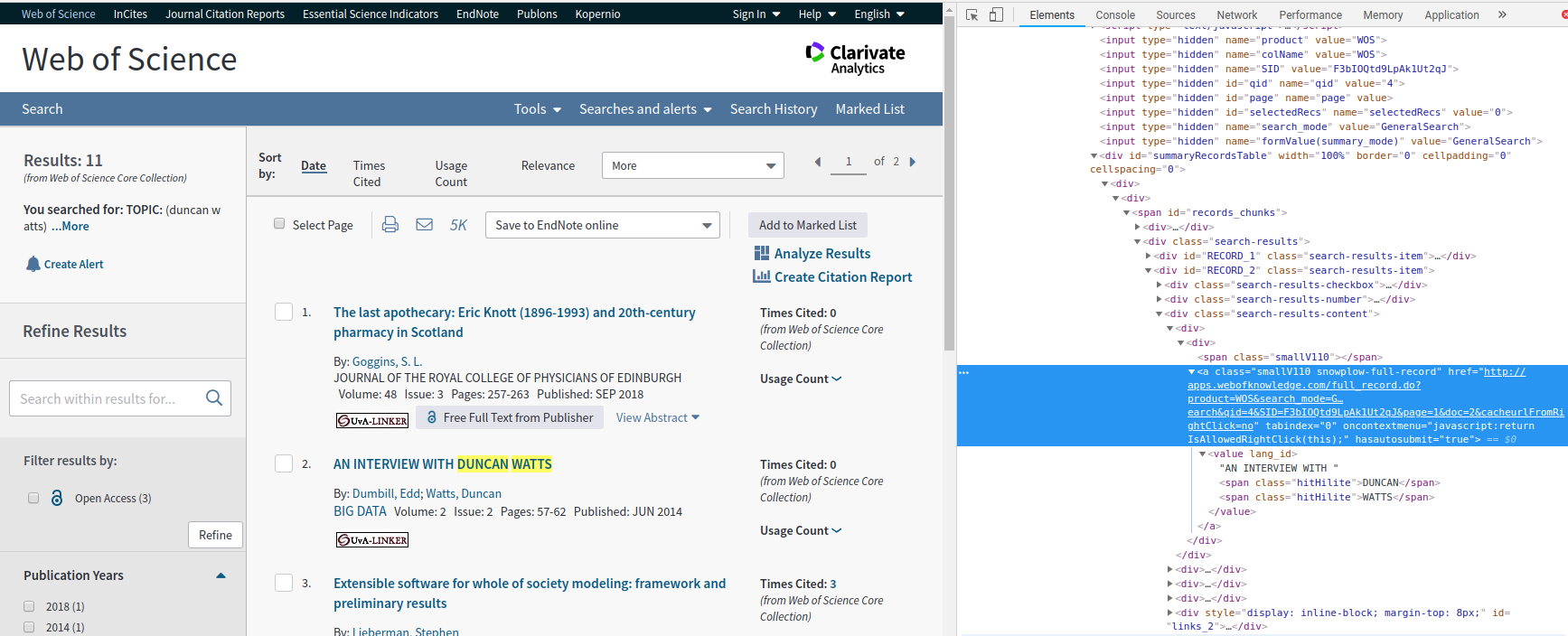
Again, use https://curl.trillworks.com/ and add SID as variable
5. Crawlers
5.1: CRON jobs
- The software utility cron is a time-based job scheduler in Unix-like computer operating systems. - Easy, robust
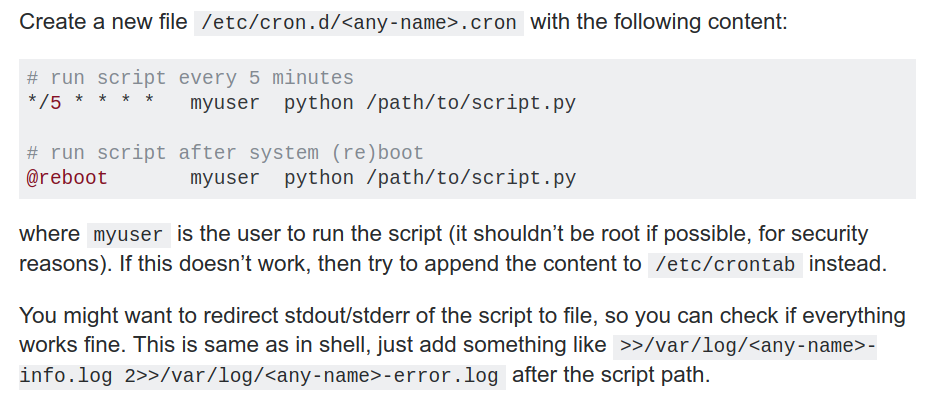
https://stackoverflow.com/questions/21648410/write-python-script-that-is-executed-every-5-minutes
5.2: Processes
- All run within Python
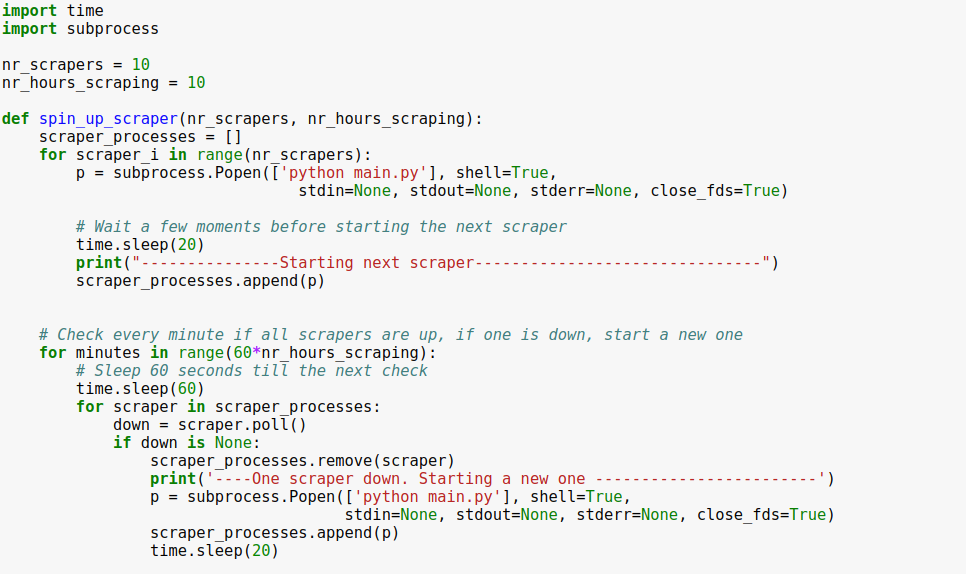
5.3: Scrapy
- An open source and collaborative framework for extracting the data you need from websites. In a fast, "simple", yet extensible way.
- Best solution, but steep learning curve
6. Advanced topics
6.1A: Proxies
from http_request_randomizer.requests.proxy.requestProxy import RequestProxy
# Collects the proxys and log errors
req_proxy = RequestProxy()
req_proxy.set_logger_level(logging.CRITICAL)
# Request a website
r = req_proxy.generate_proxied_request(link)
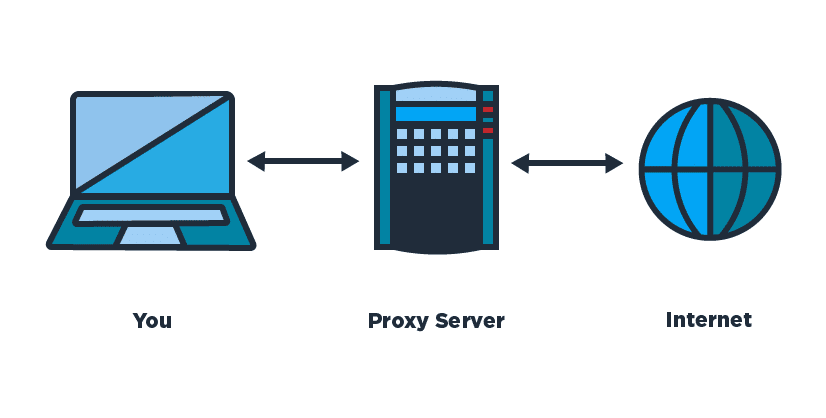
-
Library: http_request_randomizer
-
Uses public proxy websites:
-
Many will be blocked already
-
-
Don't use it for evil (rule #2)
6.1B: Proxies
from tor_control import TorControl
import requests
tc = TorControl()
print(requests.get("https://api.ipify.org?format=jso").text)
> 163.172.162.106
tc.renew_tor()
print(requests.get("https://api.ipify.org?format=jso").text)
> 18.85.22.204
-
Use TOR
-
Instructions to configure it: https://github.com/jgarciab/tor
-
Don't use it for evil (rule #2)
6.2: Speed up requests
-
Use: Want to collect info from many different websites.
-
Problem: requests is blocking (it waits until the website responds )
-
Solution: run many threads
-
But not straightforward
-
Best: grequests: asynchronous HTTP Requests
-
import grequests
urls = [
'http://www.heroku.com','http://python-tablib.org', 'http://httpbin.org',
'http://python-requests.org', 'http://fakedomain/','http://kennethreitz.com'
]
rs = (grequests.get(u) for u in urls)
grequests.map(rs)
[<Response [200]>, <Response [200]>, <Response [200]>, <Response [200]>, None, <Response [200]>]
6.3: Dealing with selenium
We get this when the element is destroyed or hasn't been completely loaded. Possible solutions: Refresh the website, or wait until the page loads
## Option1: import selenium.common.exceptions import selenium.webdriver import selenium.webdriver.common.desired_capabilities import selenium.webdriver.support.ui from selenium.webdriver.support import expected_conditions #Define a function to wait for an element to load def _wait_for_element(xpath, wait): try: polling_f = expected_conditions.presence_of_element_located((selenium.webdriver.common.by.By.XPATH, xpath)) elem = wait.until(polling_f) except: raise selenium.common.exceptions.TimeoutException(msg='XPath "{}" presence wait timeout.'.format(xpath)) return elem def _wait_for_element_click(xpath, wait): try: polling_f = expected_conditions.element_to_be_clickable((selenium.webdriver.common.by.By.XPATH, xpath)) elem = wait.until(polling_f) except: raise selenium.common.exceptions.TimeoutException(msg='XPath "{}" presence wait timeout.'.format(xpath)) return elem #define short and long timeouts wait_timeouts=(30, 180) #open the driver (change the executable path to geckodriver_mac or geckodriver.exe) driver = selenium.webdriver.Firefox(executable_path="./geckodriver") #define short and long waits (for the times you have to wait for the page to load) short_wait = selenium.webdriver.support.ui.WebDriverWait(driver, wait_timeouts[0], poll_frequency=0.05) long_wait = selenium.webdriver.support.ui.WebDriverWait(driver, wait_timeouts[1], poll_frequency=1) #And this is how you get an element element = _wait_for_element('//*[@id="selFundID"]',short_wait)
6.3.1 Stale Element Exception
6.3: Dealing with selenium
Sometimes not all elements are loaded (e.g. by AJAX) and we need to wait. We could use time.sleep() but for how long? Response time can be highly unstable.
Alternative solution: Wait until a specific element is loaded on the page:
6.3.2 ElementNotVisibleException

More info at https://selenium-python.readthedocs.io/waits.html
6.3: Dealing with selenium
def scroll_down(SCROLL_PAUSE_TIME = 0.5):
# Get scroll height
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# Scroll down to bottom
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait to load page
time.sleep(SCROLL_PAUSE_TIME)
# Calculate new scroll height and compare with last scroll height
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height: break
last_height = new_height
6.3.3 scrolling down to load all site
6.3: Dealing with selenium
options = webdriver.ChromeOptions()
profile = {"plugins.plugins_list":
[{"enabled": False, "name": "Chrome PDF Viewer"}], # Disable Chrome's PDF Viewer
"download.default_directory": "./download_directory/" ,
"download.extensions_to_open": "applications/pdf"}
options.add_experimental_option("prefs", profile)
driver = webdriver.Chrome("./chromedriver",chrome_options=options)
6.3.4 downloading files without asking
6.3: Dealing with selenium
def enable_download_in_headless_chrome(driver, download_dir):
# add missing support for chrome "send_command" to selenium webdriver
driver.command_executor._commands["send_command"] = ("POST", '/session/$sessionId/chromium/send_command')
params = {'cmd': 'Page.setDownloadBehavior', 'params': {'behavior': 'allow', 'downloadPath': download_dir}}
command_result = driver.execute("send_command", params)
[...]
options.add_experimental_option("prefs", profile)
options.add_argument("--headless")
driver = webdriver.Chrome("./chromedriver",chrome_options=options)
enable_download_in_headless_chrome(driver,"./download_directory/))
6.3.5 headless chrome (not opening more windows)
6.3: Dealing with selenium
#Click somewhere
driver.find_element_by_xpath("xxxx").click()
#Switch to the new window
driver.switch_to_window(driver.window_handles[1])
#Do whatever
driver.find_element_by_xpath('xxxxxx').click()
#Go back to the main window
driver.switch_to_window(driver.window_handles[0])
6.3.6 pop up windows (e.g. to log in)
6.4: Robust scraping
-
Don't make your scraper language dependent
-
Save raw html
-
Use drilldown method to identify/extract elements on the page
-
Avoid xpath (my opinion)
- Track your progress, st scraper can crash and start from where it left off
Discussion time
Workshop on data scraping - Amsterdam CSS
By Javier GB
Workshop on data scraping - Amsterdam CSS
Workshop on data scraping



