




Karl Ho
Data Generation datageneration.io
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
2. Harvard
Certain assignments in this course will permit or even encourage the use of generative artificial intelligence (AI) tools, such as ChatGPT. When AI use is permissible, it will be clearly stated in the assignment prompt posted in Canvas. Otherwise, the default is that use of generative AI is disallowed. In assignments where generative AI tools are allowed, their use must be appropriately acknowledged and cited. For instance, if you generated the whole document through ChatGPT and edited it for accuracy, your submitted work would need to include a note such as “I generated this work through Chat GPT and edited the content for accuracy.” Paraphrasing or quoting smaller samples of AI generated content must be appropriately acknowledged and cited, following the guidelines established by the APA Style Guide. It is each student’s responsibility to assess the validity and applicability of any AI output that is submitted. You may not earn full credit if inaccurate on invalid information is found in your work. Deviations from the guidelines above will be considered violations of CMU’s academic integrity policy. Note that expectations for “plagiarism, cheating, and acceptable assistance” on student work may vary across your courses and instructors. Please email me if you have questions regarding what is permissible and not for a particular course or assignment.
3. Carnegie Mellon University
You are welcome to use generative AI programs (ChatGPT, DALL-E, etc.) in this course. These programs can be powerful tools for learning and other productive pursuits, including completing some assignments in less time, helping you generate new ideas, or serving as a personalized learning tool.
However, your ethical responsibilities as a student remain the same. You must follow CMU’s academic integrity policy. Note that this policy applies to all uncited or improperly cited use of content, whether that work is created by human beings alone or in collaboration with a generative AI. If you use a generative AI tool to develop content for an assignment, you are required to cite the tool’s contribution to your work. In practice, cutting and pasting content from any source without citation is plagiarism. Likewise, paraphrasing content from a generative AI without citation is plagiarism. Similarly, using any generative AI tool without appropriate acknowledgement will be treated as plagiarism.
4. UTD (some courses)
Cheating and plagiarism will not be tolerated.
The emergence of generative AI tools (such as ChatGPT and DALL-E) has sparked large interest among many students and researchers. The use of these tools for brainstorming ideas, exploring possible responses to questions or problems, and creative engagement with the materials may be useful for you as you craft responses to class assignments. While there is no substitute for working directly with your instructor, the potential for generative AI tools to provide automatic feedback, assistive technology and language assistance is clearly developing. Course assignments may use Generative AI tools if indicated in the syllabus. AI-generated content can only be presented as your own work with the instructor’s written permission. Include an acknowledgment of how generative AI has been used after your reference or Works Cited page. TurnItIn or other methods may be used to detect the use of AI. Under UTD rules about due process, referrals may
be made to the Office of Community Standards and Conduct (OCSC). Inappropriate use of AI may result in penalties, including a 0 on an assignment.
Using generative AI may not save time, but will improve quality and deepen thought process.
ipsa scientia potestas est"
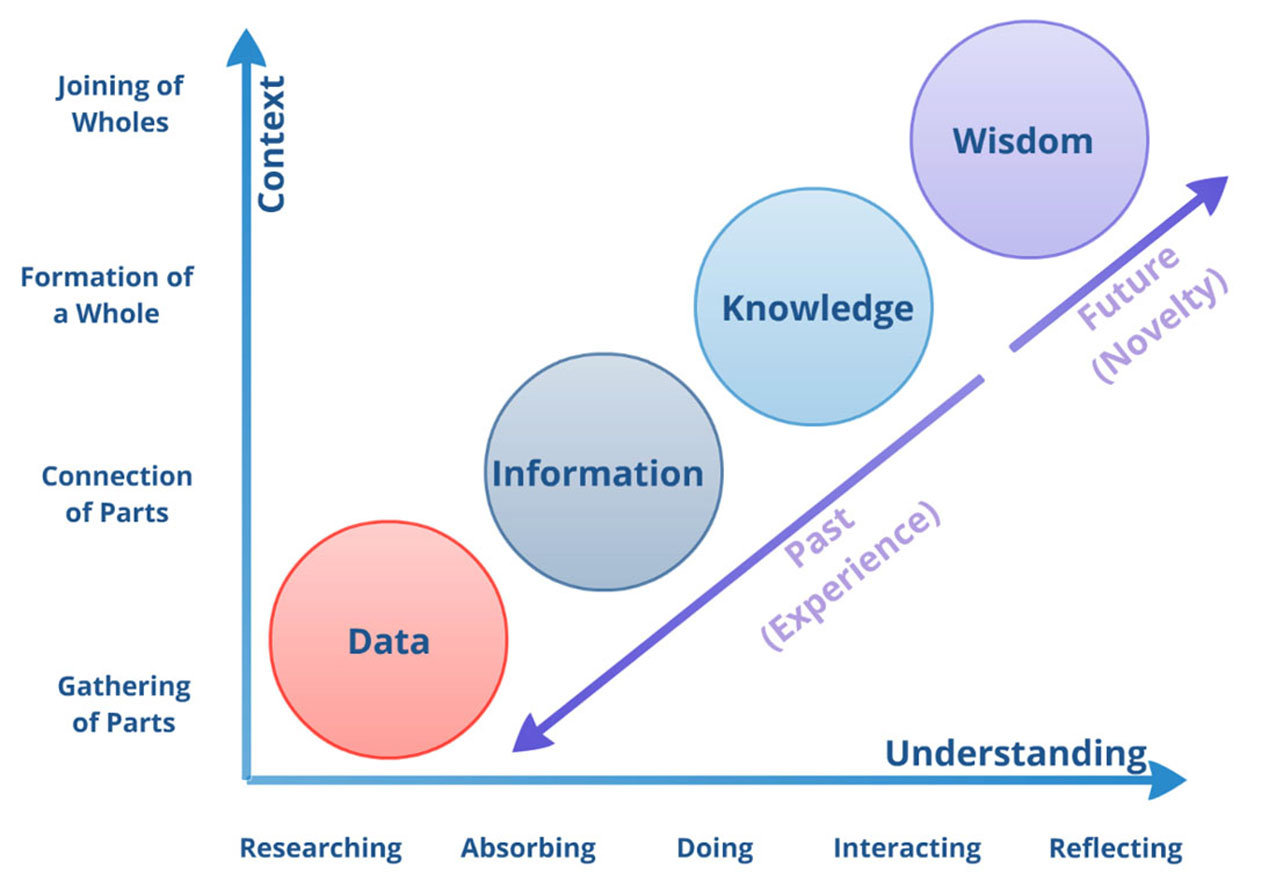
Ackoff, R.L., 1989. From data to wisdom. Journal of applied systems analysis, 16(1), pp.3-9.
facts and statistics collected together for reference or analysis"
- Oxford dictionary
the representation of facts, concepts, or instructions in a formalized manner suitable for communication, interpretation, or processing by humans or by automatic means"
- McGraw-Hill Dictionary of Scientific and Technical Terms, 2003
a reinterpretable representation of information in a formalized manner suitable for communication, interpretation, or processing"
- ISO/IEC 2382-1:1993
a set of values of qualitative or quantitative variables"
- Mark A.Beyer, 2014
the basis for:
Beyer, M. A. 2014. "Gartner Says Solving 'Big Data' Challenge Involves More Than Just Managing Volumes of Data." Gartner Research.
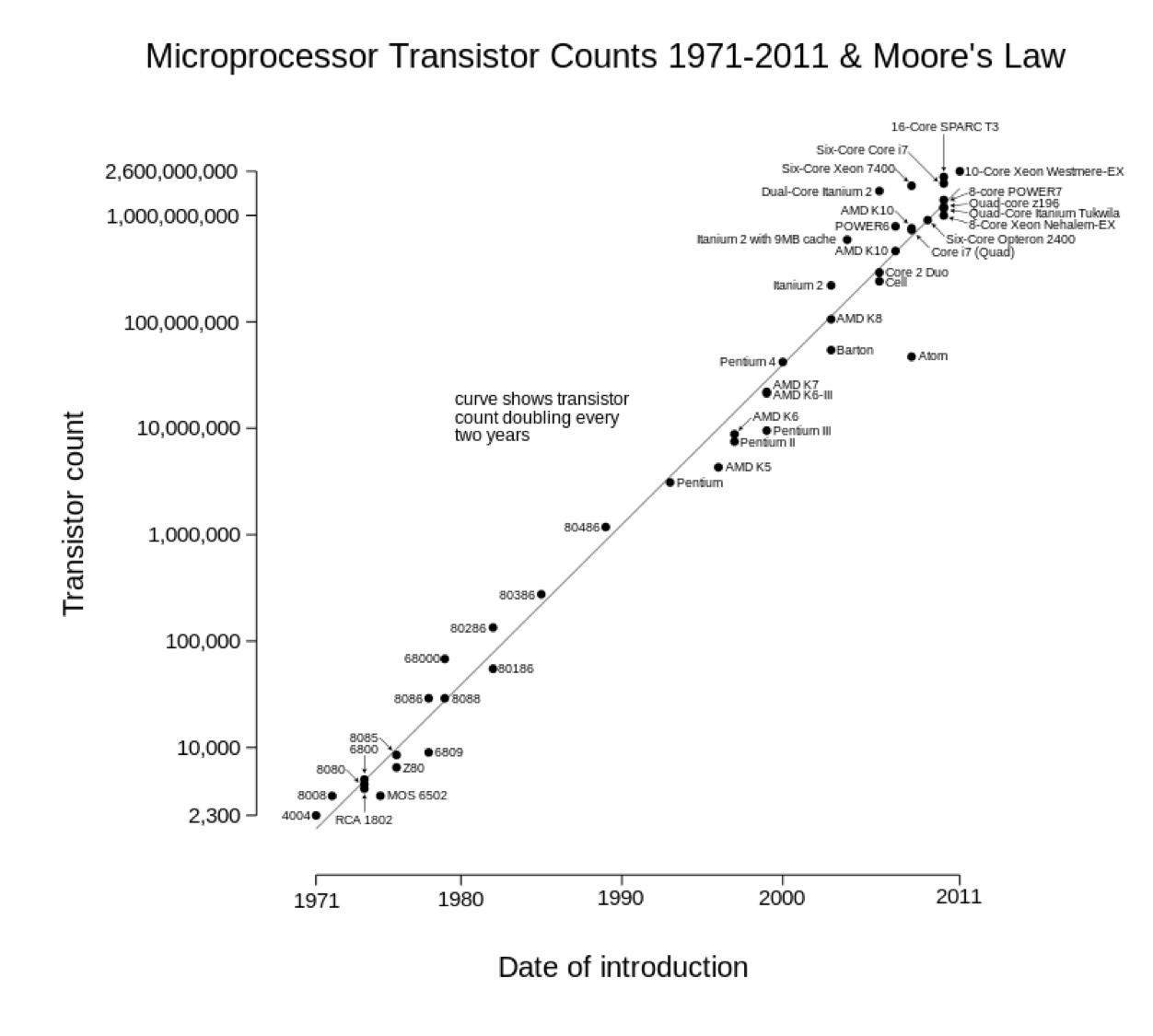
Hilbert, M. and López, P., 2011. The world's technological capacity to store, communicate, and compute information. science, p.1200970.
Bits: 8 bits = 1 byte
Bytes: 1024 bytes = 1 KB (1 to 3 digits)
Kilobytes: 1024 KB = 1 MB (4 to 6 digits)
Megabytes: 1024 MB = 1 GB (7 to 9 digits)
Gigabytes: 1024 GB = 1 TB (10 to 12 digits)
Terabytes: 1024 TB = 1 PB (13 to 15 digits)
Petabytes: 1024 PB = 1 EB (16 to 18 digits)
Exabytes: 1024 EB = 1 ZB (19 to 21 digits)
Zettabytes: 1024 ZB = 1 YB (22 to 24 digits)
Yottabytes: more than enough... (25 to 27 digits)
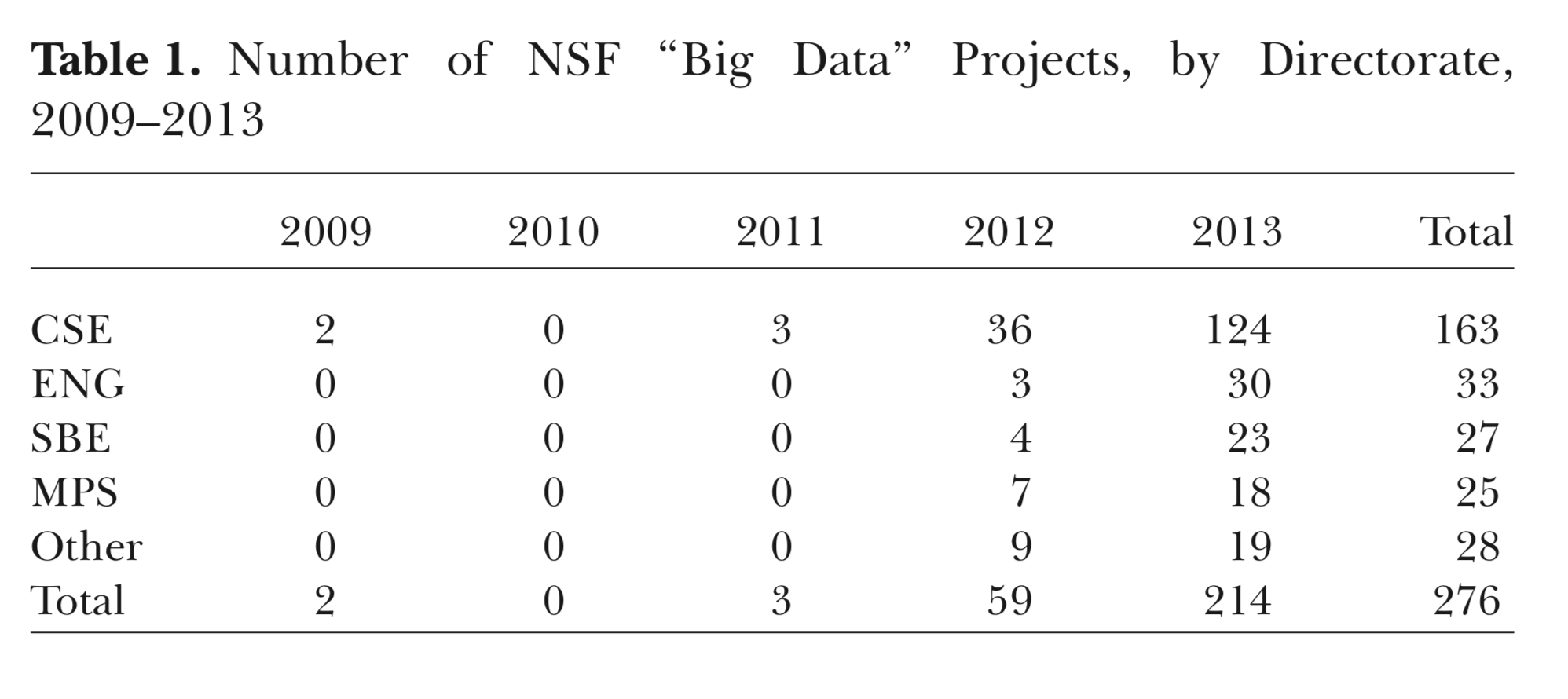
CSE - Computer and Information Science and Engineering
ENG - Engineering
SBE - Social Behavioral and Economic Sciences
Mathematics and Physical Science
Office of Behavioral and Social Sciences (OBSSR)
The National Archive of Computerized Data on Aging (NACDA)
program advances research on aging by helping researchers to profit from the under-exploited potential of a broad range of
datasets. NACD preserves and makes available the largest library of electronic data on aging in the United States
Data Sharing for Demographic Research (DSDR) provides data archiving, preservation, dissemination and other data infrastructure services. DSDR works toward a unified legal,
technical and substantive framework in which to share re
search data in the population sciences.
The USGS John Wesley Powell Center for Analysis and Synthesis
just announced eight new research projects for transforming big data sets and big ideas about earth science theories into
scientific discoveries. At the Center, scientists collaborate to perform state of the art synthesis to leverage comprehensive, long-term data.
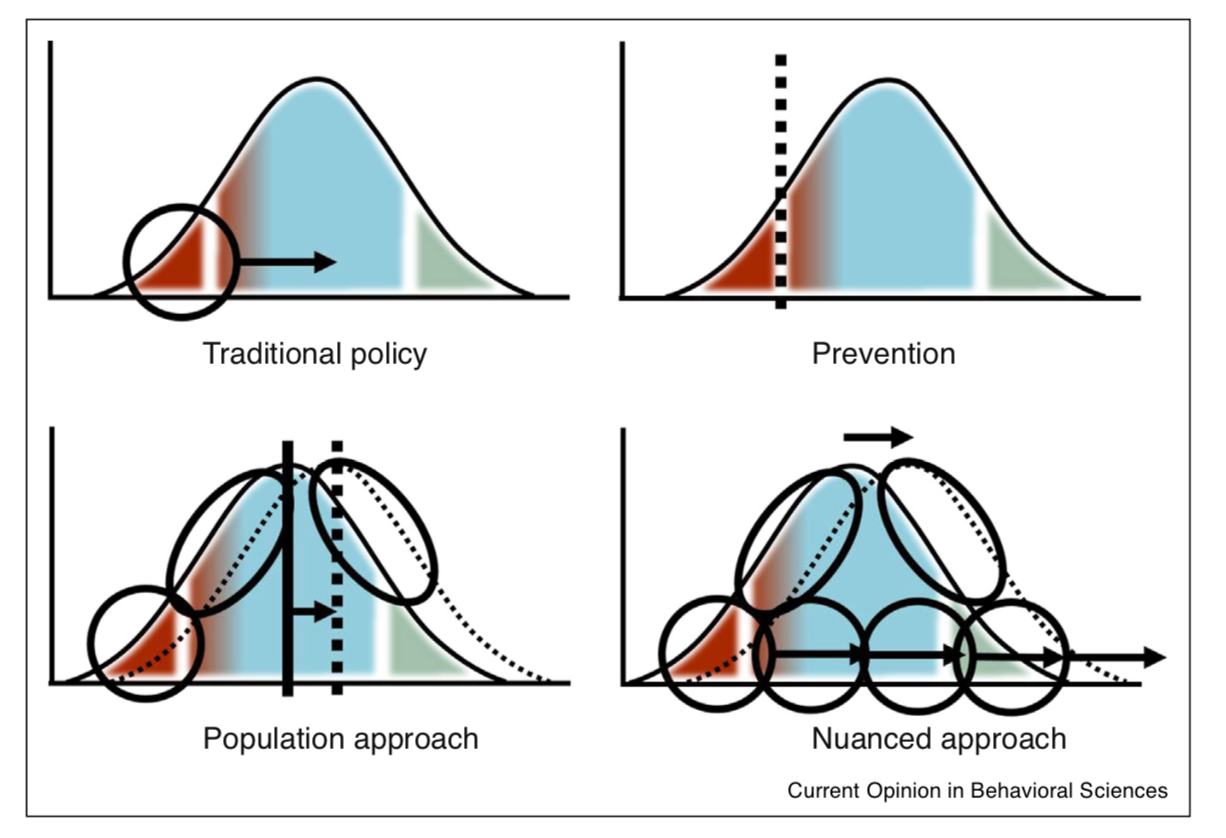
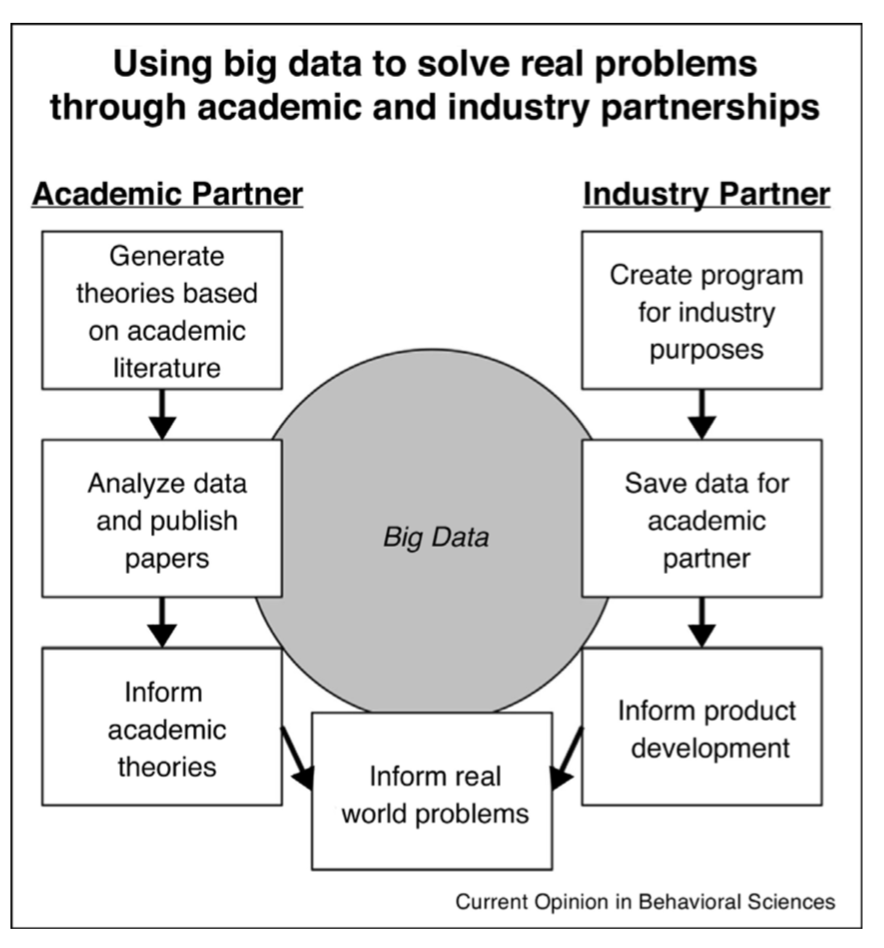
Mitroff, S.R. and Sharpe, B., 2017. Using big data to solve real problems through academic and industry partnerships. Current Opinion in Behavioral Sciences, 18, pp.91-96.
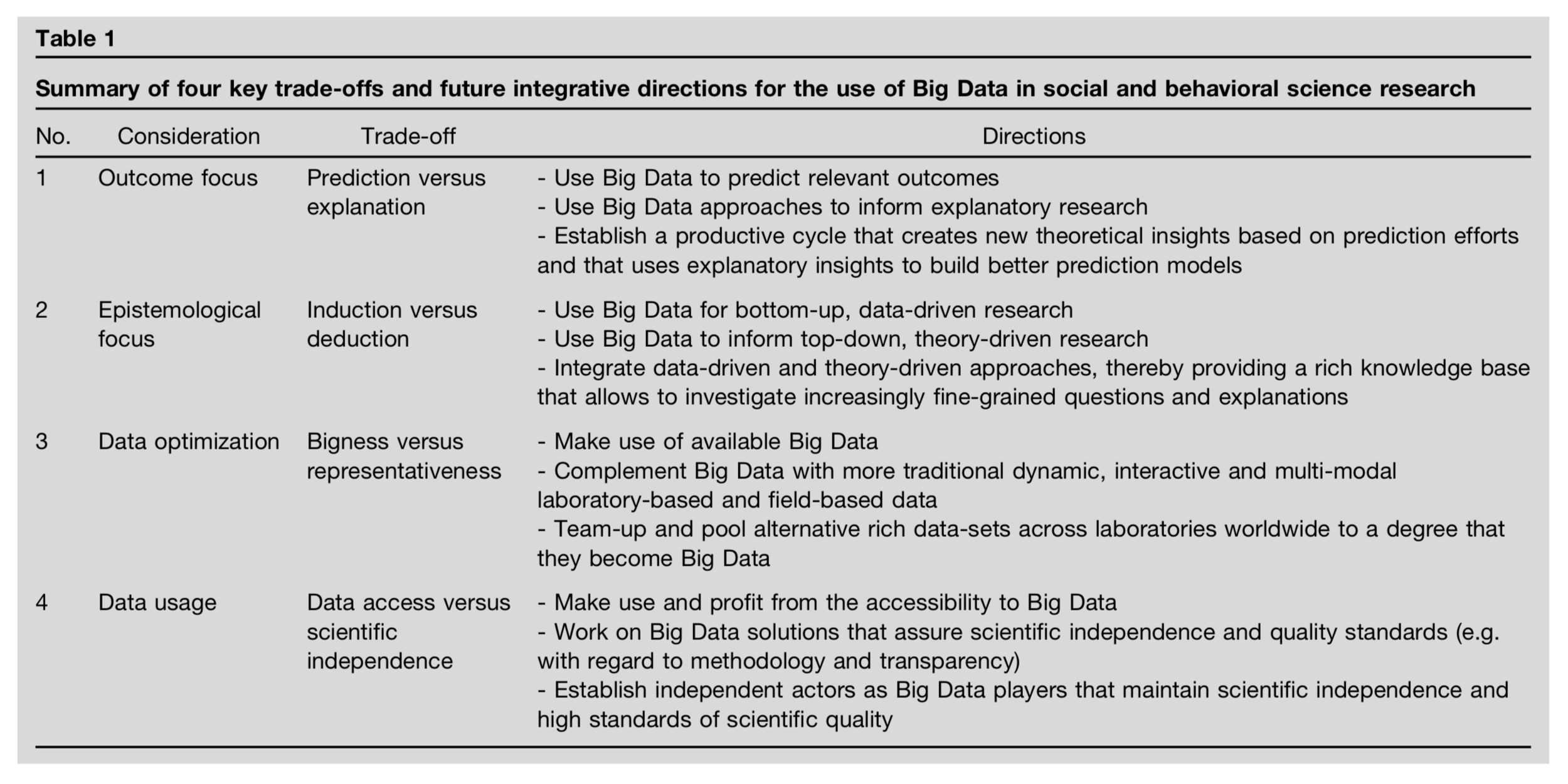
Mahmoodi, J., Leckelt, M., van Zalk, M.W., Geukes, K. and Back, M.D., 2017. Big Data approaches in social and behavioral science: four key trade-offs and a call for integration. Current Opinion in Behavioral Sciences, 18, pp.57-62.
Mahmoodi, J., Leckelt, M., van Zalk, M.W., Geukes, K. and Back, M.D., 2017. Big Data approaches in social and behavioral science: four key trade-offs and a call for integration. Current Opinion in Behavioral Sciences, 18, pp.57-62.
Science of Data
Understand Data Scientifically
CRMs
- InsideBigdata.com
Davenport, Thomas H., and Jeanne G. Harris. 2007. Competing on analytics: The new science of winning. Harvard Business Press.
- Monroe, Pan, Roberts, Sen and Sinclair 2015
Grimmer, J., 2015. We are all social scientists now: how big data, machine learning, and causal inference work together. PS: Political Science & Politics, 48(1), pp.80-83.
| One assumes that the data are generated by a given stochastic data model. |
|---|
| The other uses algorithmic models and treats the data mechanism as unknown. |
|---|
| Data Model |
|---|
| Algorithmic Model |
|---|
| Small data |
|---|
| Complex, big data |
|---|
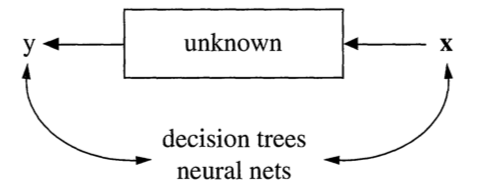
Data are generated in many fashions. Picture this: independent variable x goes in one side of the box-- we call it nature for now-- and dependent variable y come out from the other side.
The analysis in this culture starts with assuming a stochastic data model for the inside of the black box. For example, a common data model is that data are generated by independent draws from response variables.
Response Variable= f(Predictor variables, random noise, parameters)
Reading the response variable is a function of a series of predictor/independent variables, plus random noise (normally distributed errors) and other parameters.
The values of the parameters are estimated from the data and the model then used for information and/or prediction.
The analysis in this approach considers the inside of the box complex and unknown. Their approach is to find a function f(x)-an algorithm that operates on x to predict the responses y.
The goal is to find algorithm that accurately predicts y.
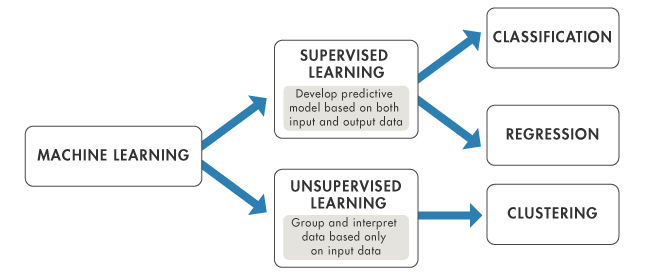
Unsupervised Learning
Supervised Learning vs.
Source: https://www.mathworks.com
Chief Economist, Google
Professor of Economics, University of California, Berkeley.
Big Data: New Tricks for Econometrics
Machine Learning and Econometrics
Introduction - Data theory
Data methods
Statistics
Programming
Data Visualization
Information Management
Data Curation
Spatial Models and Methods
Machine Learning
NLP/Text mining
Introduction - Data theory
Fundamentals
Data concepts
Data Generation Process (DGP)
Algorithm-based vs. Data-based approaches
Taxonomy
Data methods
Passive data
Data at will
Qualitative data
Complex data
Text data
Statistics
Sample and Population
Inference
Size and power
Representation
Programming
Data Visualization
Information Management
Data curation
Spatial Models and Methods
Machine Learning
NLP/Text Mining
By Karl Ho
Overview: This is a data method course introducing the theory, practices and issues of data collection and production. It aims at providing a comprehensive framework in understanding data, and how social scientists conduct research starting from the data generation process. We will cover data methods, data management, big data trends and how to prepare data for next phrases of research including modeling and reporting. This survey course is designed to equip social scientists with data generation concepts, tools and best practices. Topics on new developments and tools of big data in social science research will also be covered.



