Karl Ho
Data Generation datageneration.io
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
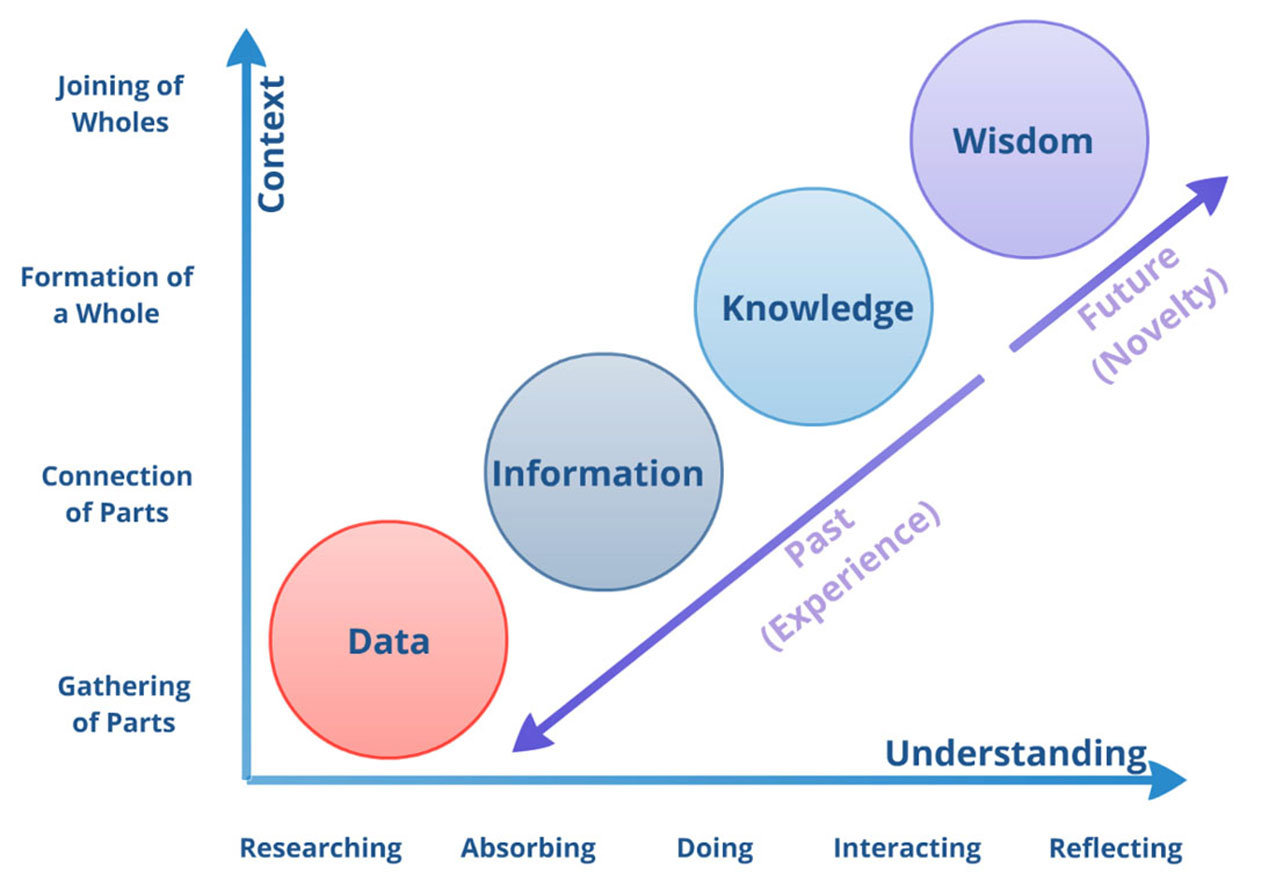
Ackoff, R.L., 1989. From data to wisdom. Journal of applied systems analysis, 16(1), pp.3-9.
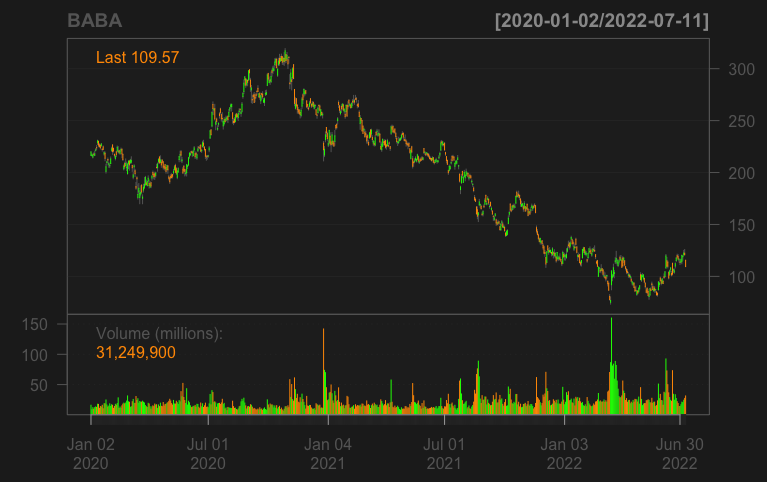
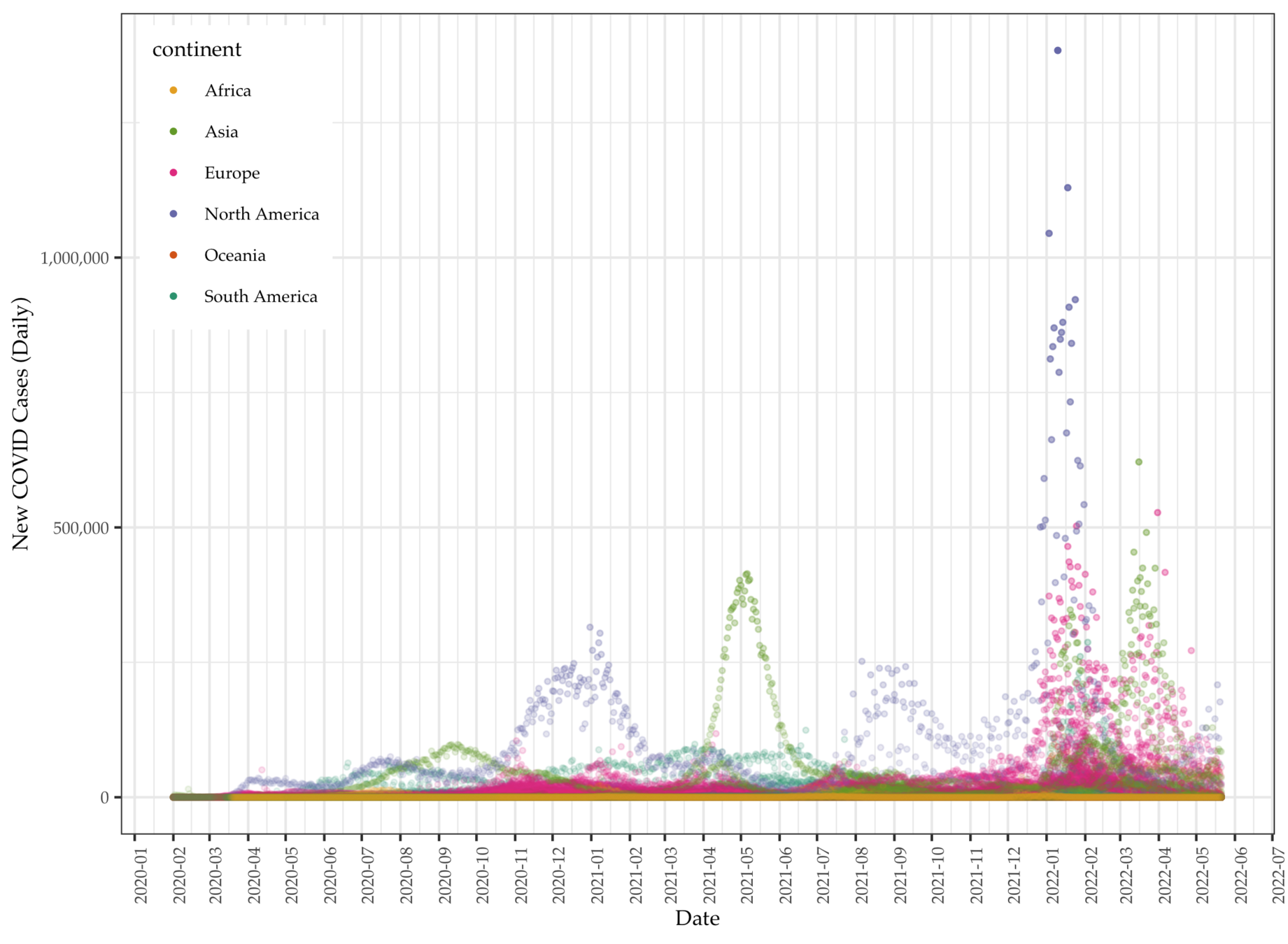
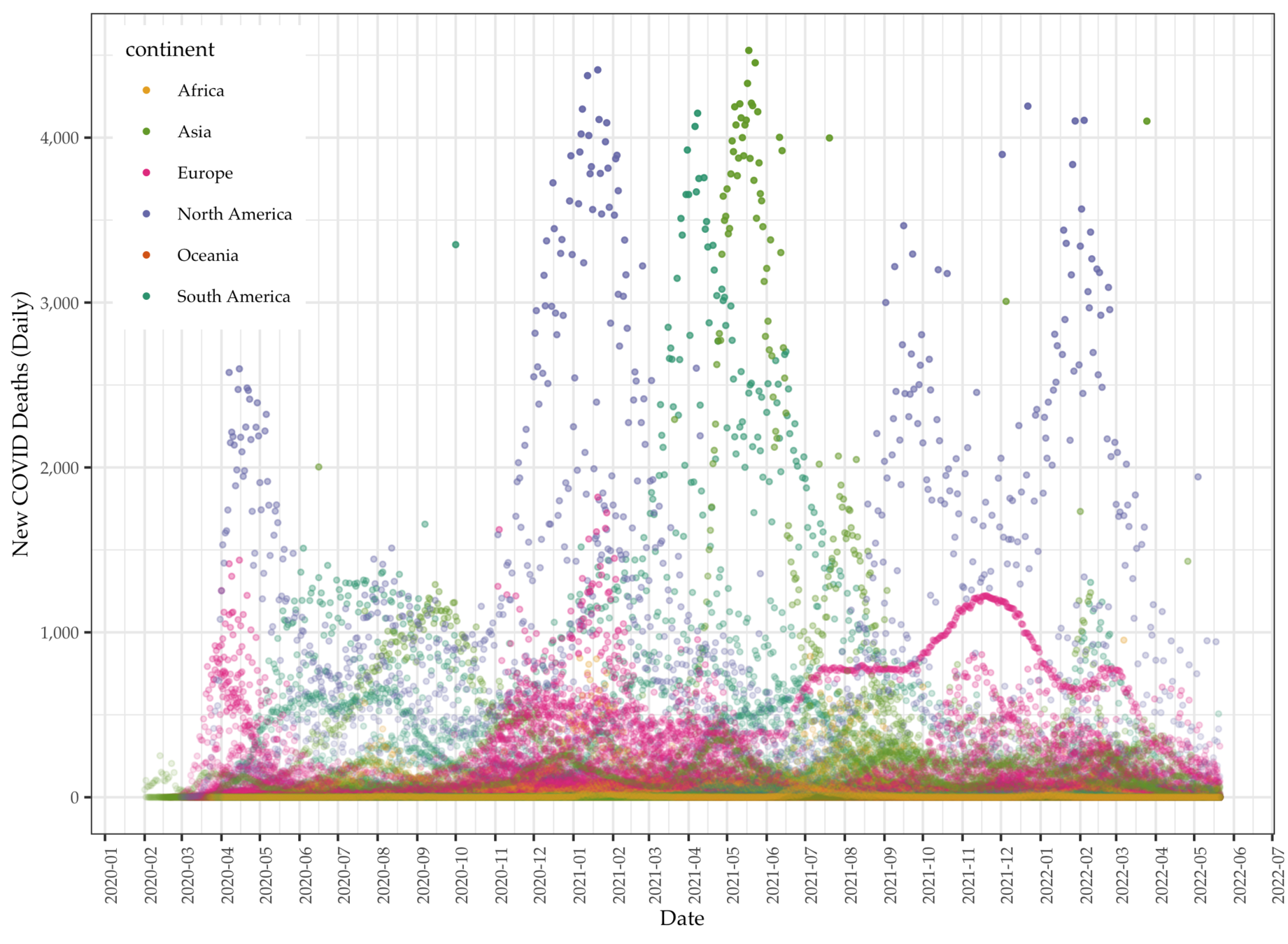
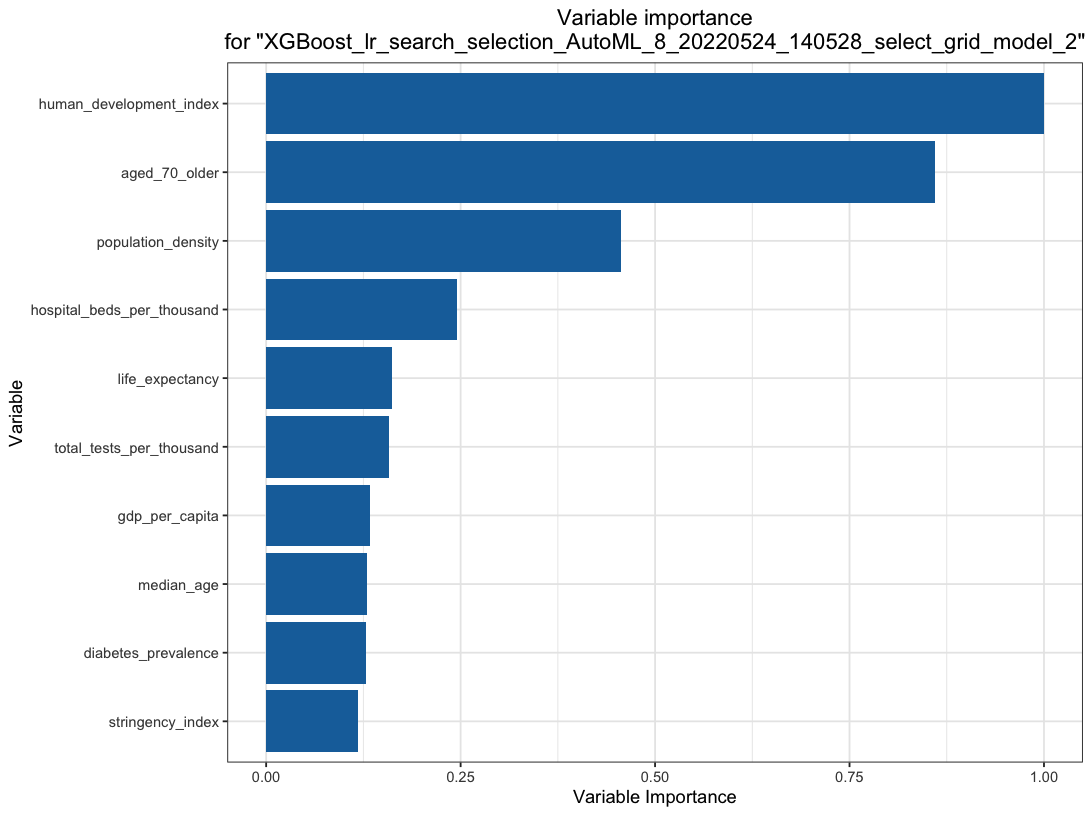
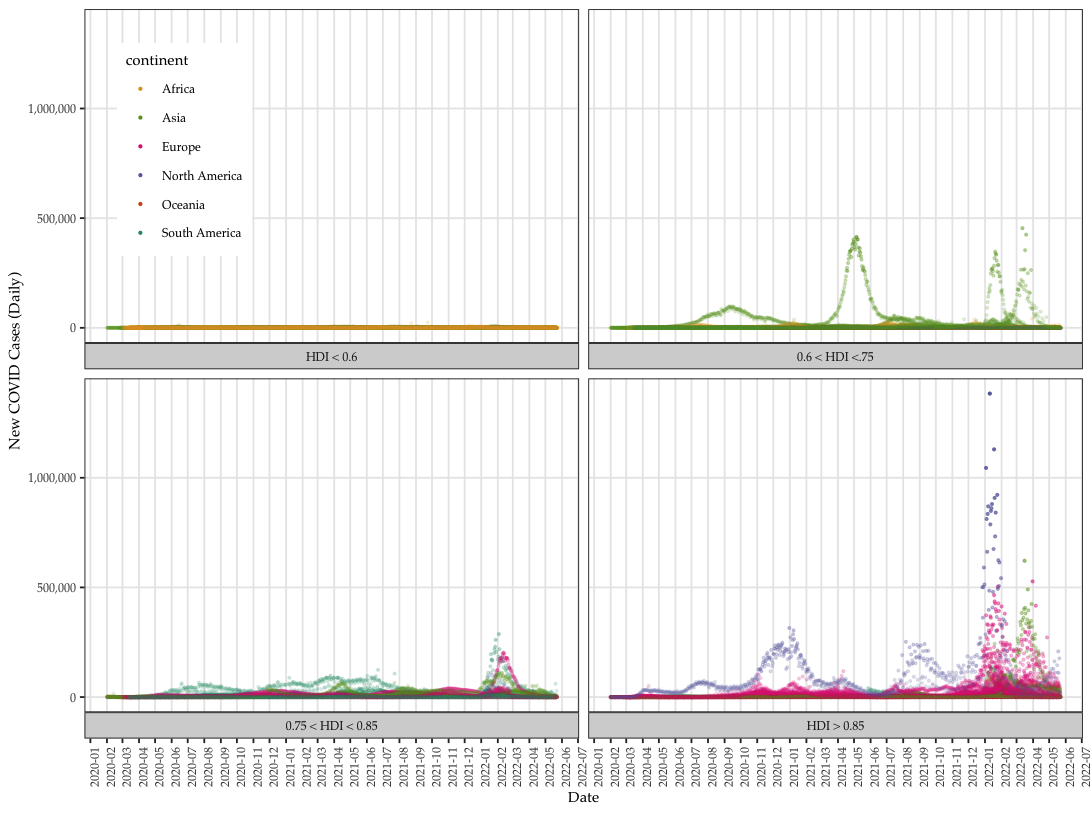
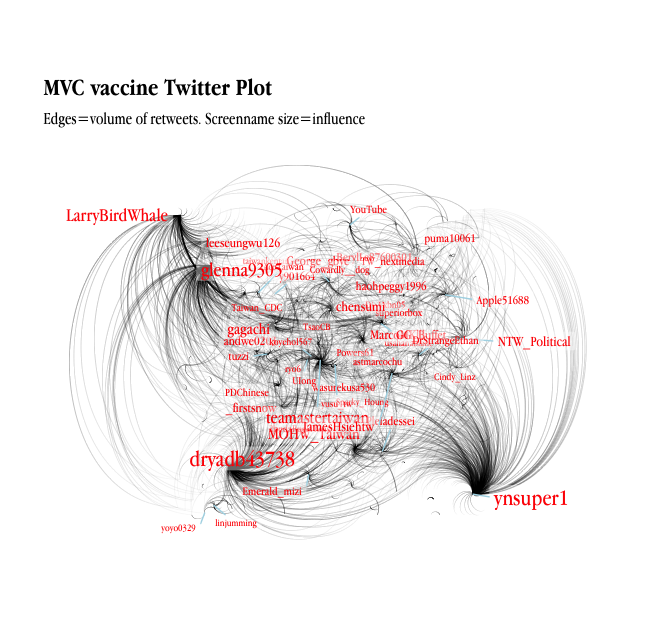
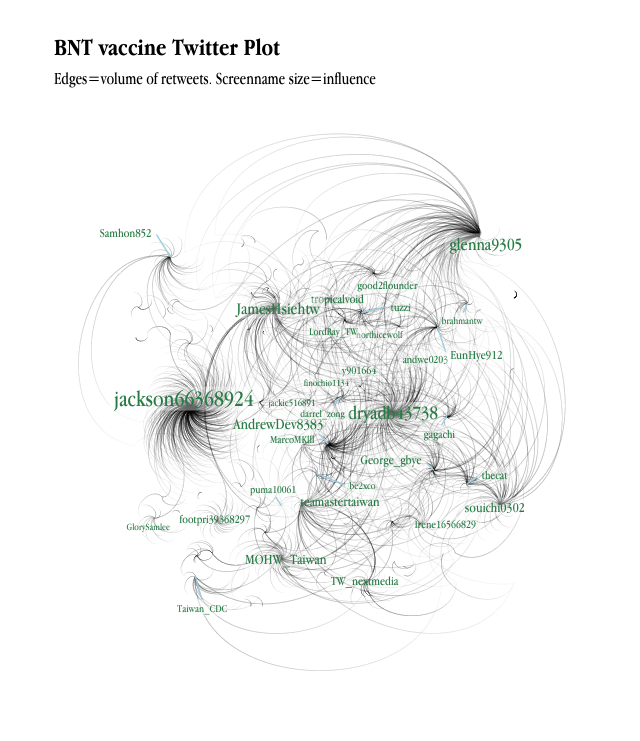
Kinds of Data
Quantitative vs. Qualitative
Structured vs. Semi/unstructured
Measurement
Nominal/ordinal/interval/ratio
metadata, paradata
YAML (Yet Another Markup Language or YAML Ain't Markup Language) is a data-oriented, human readable language mostly use for configuration files)
Undocumented with no or little information on sampling
Link to RStudio Cloud:
https://rstudio.cloud/project/4631380
- Need a GitHub and RStudio Account
Link to class GitHub:
https://github.com/datageneration/dataprogrammingwithr
By Karl Ho



