


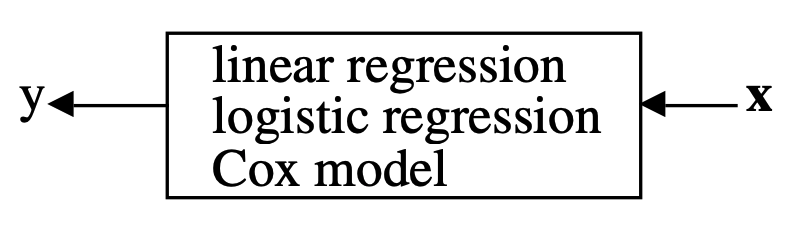







Karl Ho
Data Generation datageneration.io
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
Workshop prepared for International Society for Data Science and Analytics (ISDSA) Annual Meeting, Notre Dame University, June 2nd, 2022.
The ultimate goal of data modeling is to explain and predict the variable of interest using data. Machine learning is to achieve this goal using computer algorithms in particular to make the prediction and solve the problem.
According to Carnegie Mellon Computer Science professor,
"Machine learning is the study of computer algorithms that allow computer programs to automatically improve through experience."
1928 – 2005
| One assumes that the data are generated by a given stochastic data model. |
|---|
| The other uses algorithmic models and treats the data mechanism as unknown. |
|---|
| Data Model |
|---|
| Algorithmic Model |
|---|
| Small data |
|---|
| Complex, big data |
|---|
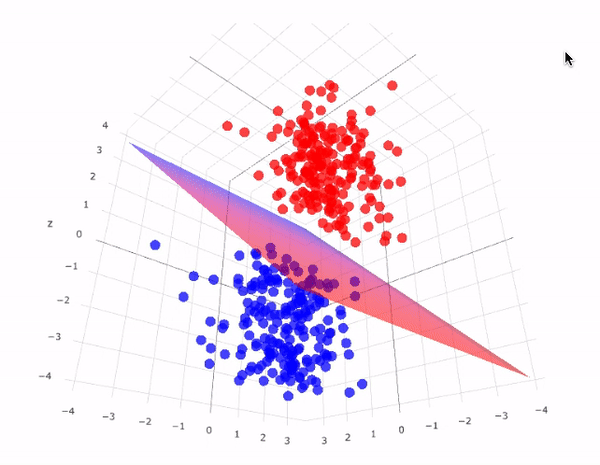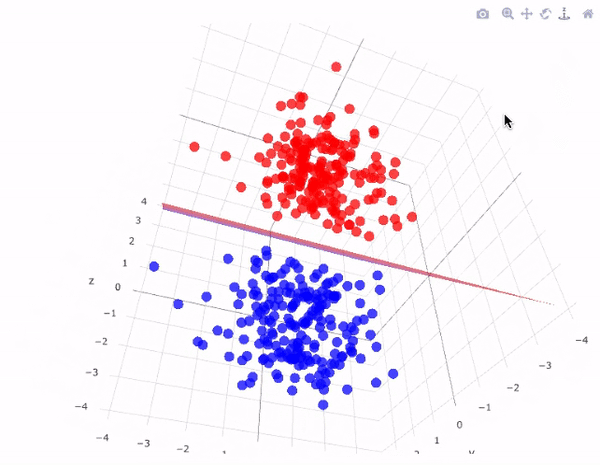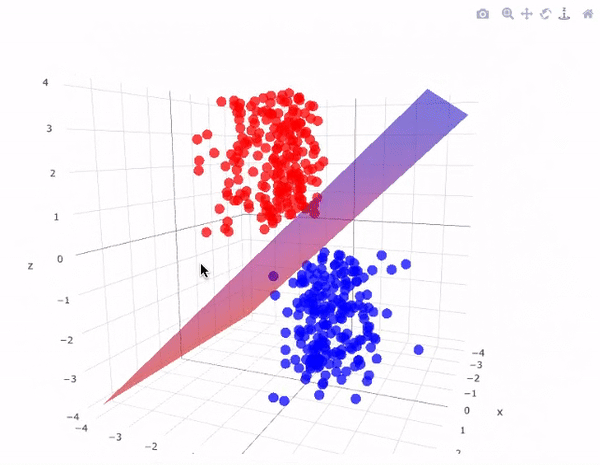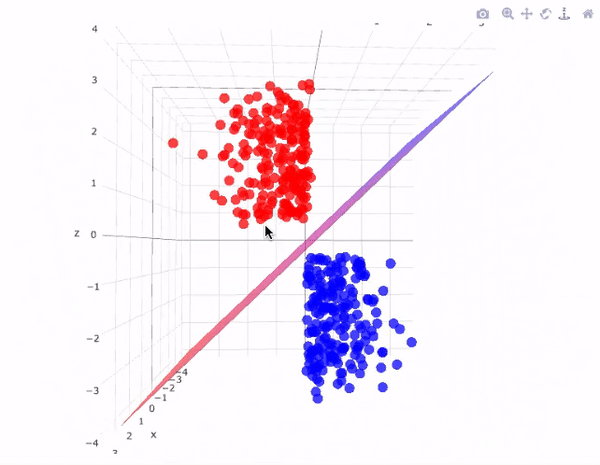
Data are generated in many fashions. Picture this: independent variable \(x\) goes in one side of the box-- we call it nature for now-- and dependent variable \(y\) come out from the other side.
The analysis in this culture starts with assuming a stochastic data model for the inside of the black box. For example, a common data model is that data are generated by independent draws from response variables.
\(Response Variable= f(Predictor variables, random noise, parameters) \)
Reading the response variable is a function of a series of predictor/independent variables, plus random noise (normally distributed errors) and other parameters.
The values of the parameters are estimated from the data and the model then used for information and/or prediction.
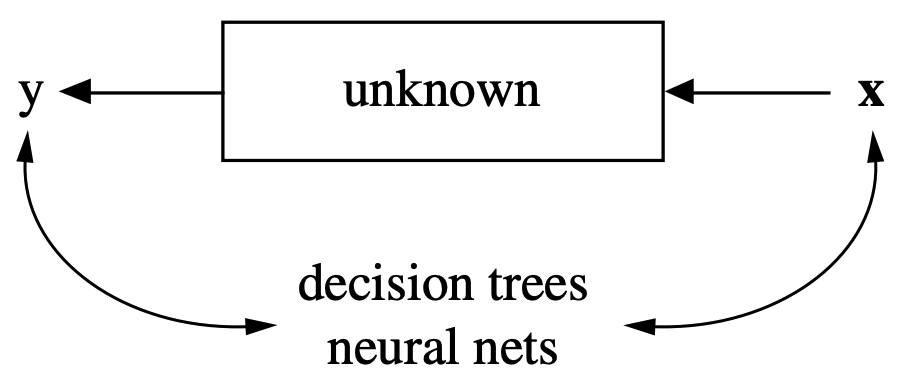
The analysis in this approach considers the inside of the box complex and unknown. Their approach is to find a function \(f(x)\)-an algorithm that operates on \(x\) to predict the responses \(y\).
The goal is to find algorithm that accurately predicts y.
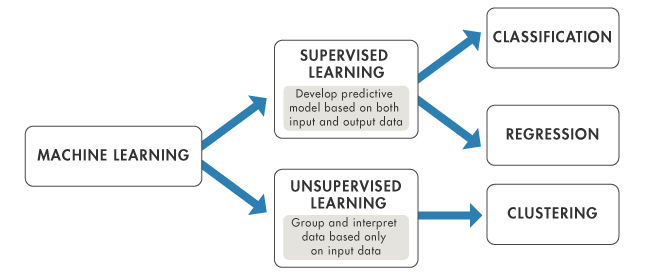
Unsupervised Learning
Supervised Learning vs.
Source: https://www.mathworks.com
Source: Attewell, Paul A. & Monaghan, David B. 2015. Data Mining for the Social Sciences: an Introduction, Table 2.1, p. 27
hypothesis confirmation
hypothesis formation
| Regression | Classification | Clustering | Q-Learning |
| Linear regression | Logistic regression | - K-Means Clustering | State Action Reward State Action (SARSA) |
| Polynomial regression | K-Nearest Neighbors | - Hierarchical Clustering | Deep Q-Network |
| Support vector regression | Support Vector Machines | Dimensionality Reduction | Markov Decision Processes |
| Ridge Regression | Kernal Support Vector Machines | Principal Component Analysis | Deep Deterministic Policy Gradient (DDPG) |
| Lasso | Naïve Bayes | Linear Discriminant Analysis | |
| ElasticNet | Decision Tree | Kernal PCA | |
| Decision tree | Random forest | ||
| Random forest |
| Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|
By Karl Ho
Gentle Introduction to Machine Learning Workshop Prepared for ISDSA 2022: Introduction 1/4




