Persian MNIST
an attempt to recreate the famous MNIST data set training (so called the hello world of AI) for Farsi text.
Kian Peymani
Computational Artificial Intelligence Course
Dr. Behrouz Minaee
What we will see:
1- Technical stuff
2- Data sets
3- Results
Language and framework
Models used for training
- MultiLayerPercepton
- ConvolutionalNeuralNetwork
- with different widths, depths and stopping criteria
More on Lasagne
- Very Easy to use, high level framework for working with neural nets
- Example of creating a MLP with two hidden layers:
l_in = lasagne.layers.InputLayer(shape=(None, 1, 30,30 )
# initializing weights with Glorot's scheme (which is the default anyway):
l_hid1 = lasagne.layers.DenseLayer(
l_in_drop, num_units=800,
nonlinearity=lasagne.nonlinearities.rectify,
W=lasagne.init.GlorotUniform())
l_hid1_drop = lasagne.layers.DropoutLayer(l_hid1, p=0.5)
l_hid2 = lasagne.layers.DenseLayer(
l_hid1_drop, num_units=800,
nonlinearity=lasagne.nonlinearities.rectify)
l_hid2_drop = lasagne.layers.DropoutLayer(l_hid2, p=0.5)
l_out = lasagne.layers.DenseLayer(
l_hid2_drop, num_units=CLASS_DIM,
nonlinearity=lasagne.nonlinearities.softmax)More on Lasagne
- Easily Create Each layer focusing only on important parameters, rather than implementation
- Passing each layer to the next layer as input, and so on ..
- l_out is now a reference to fully configurable mlp created in less than 15 lines!
More on Lasagne
- GPU Acceleration is supported by Theano
- as an example, each epoch ( 50,000 samples ) took almost 50 seconds on CPU, less than 10 seconds on GPU
- Host Device: Intel i5 CPU, NVIDIA GEFORCE 710M GPU
Data set Generation
- The MNIST database of handwritten digits, available from this page, has a training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger set available from NIST. The digits have been size-normalized and centered in a fixed-size image.
- Creating Something similar for Farsi could be challenging
Data set Generation
- Machine Generated Farsi Text
- Each Consisting of one character
- Using a set of 1700 different Farsi Fonts,
- Later reduced to 1275 for more accuracy

-
Data set PreProcessing
- Each Image will pass the following pipeline to be prepared for training:
- Pixel density Conversion : each pixel value will be shifted to the range of [0,1]
- Cropping : all of the white space around each character will be cropped of
- Resizing : since both MLP and CNN require fix dimension size of input vector, each image will be resized to a fixed dimension
Data set Representation
- Inspired By how MNIST is usually parsed as input vecotor, each image with fix dimention of w*h is represented as an vector of length w*h (each cell representing a pixel)
- each pixel has a floating point value in range [0,1] representing its density
- numpy arrays are used for faster vector calculations
- Numpy compression is used to save generated image into file
Data set Sharding
- The entire 61,000 Images are separated into three sections:
- Train Data : Used only for training, the model will not see anything else other that Train data
- Validation Data : after each epoch, validation epoch is evaluated into model to find the error rate. the model never learns this data directly
- Test data : after the last iteration, the model will be evaluated again, with another set of data which it has never seen
- in our example, Test data = 51,000 - Validation and Test data = 5,000 each
Data set Shuffeling
- Since the data was generated sequentially, the train data was also fed into the model sequentially
- This reduced the accuracy,
- To reduced this effect, we used Shuffling and mini batches.
- on each epoch, data is fed into the model as iterations of 500 shuffled mini batches, not the entire set all at once!
Results
- the result of each training is represented by a chart
- MLP networks have different width and depth
- as shown below, both cnn and mlp reach a similar accuracy, but cnn is much faster and smoother
- Early results showed no hope, less than 20% accuracy
- Shuffling and more accurate image preprocessing improved the model entirely
- Best Results are:
Results
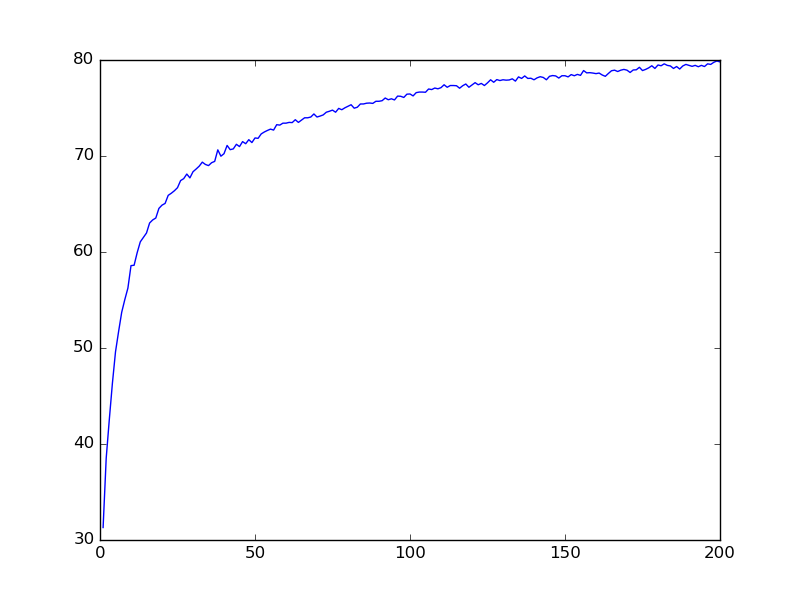
MLP network example
200 epochs
4 hidden layers
1600 neuron/layer
79% Accuracy on Validation Data
81% Accuracy on Test Data
Results
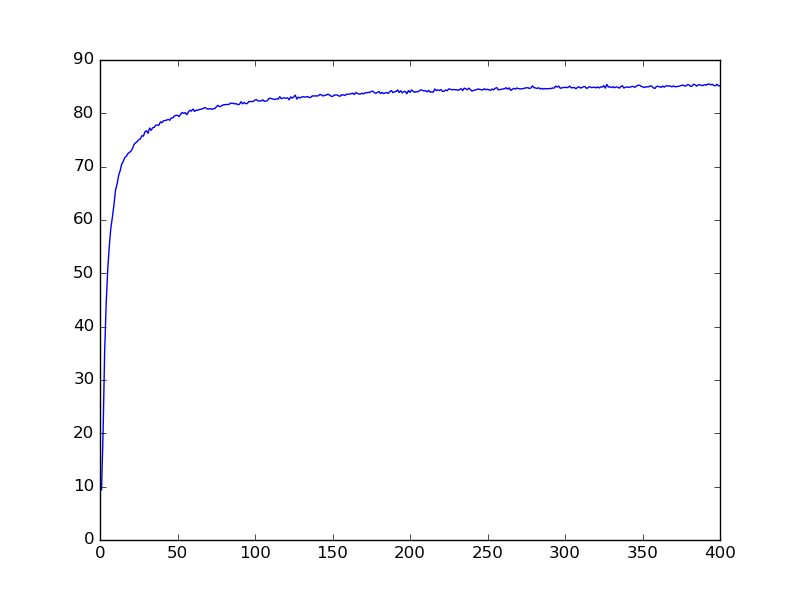
CNN network example
400 epochs
81% Accuracy on Validation Data
84% Accuracy on Test Data
More MLP Results
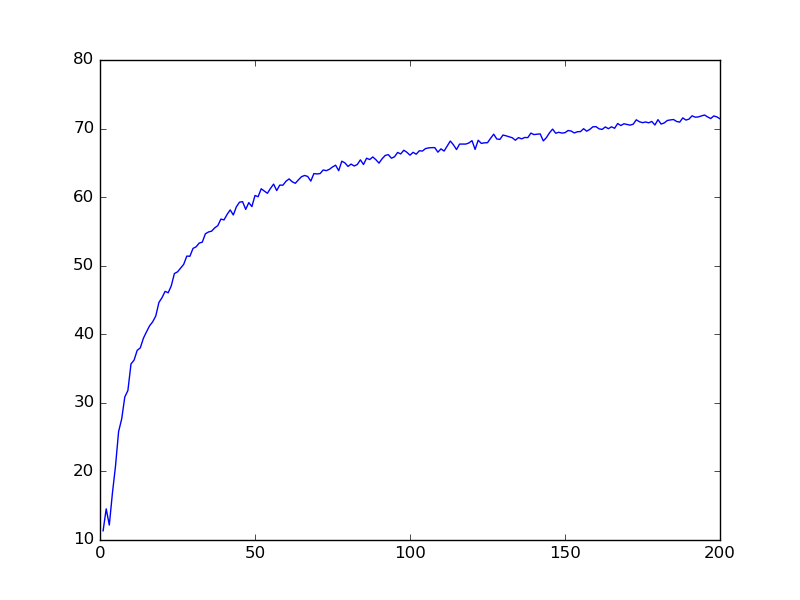
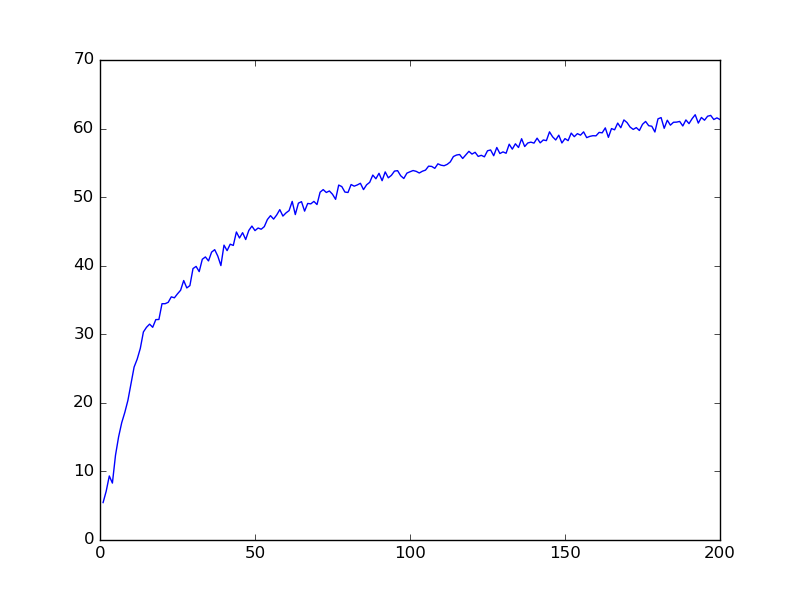
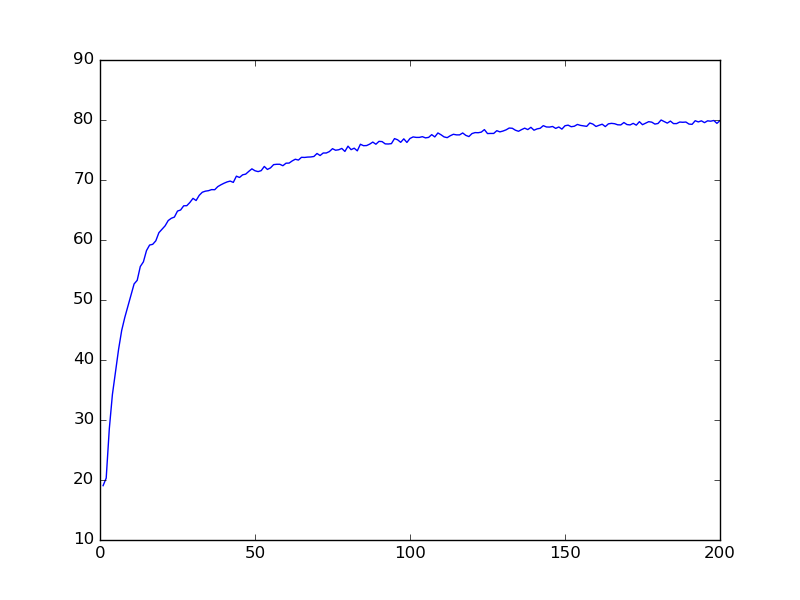
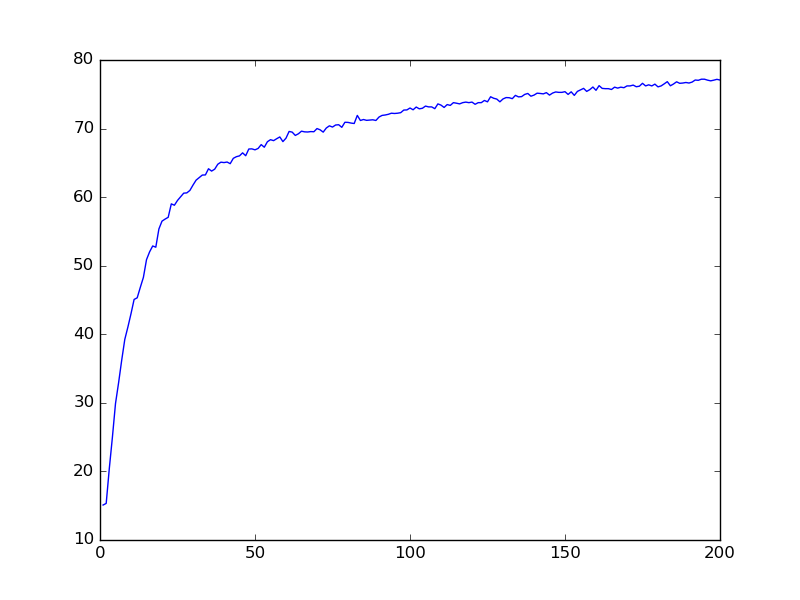
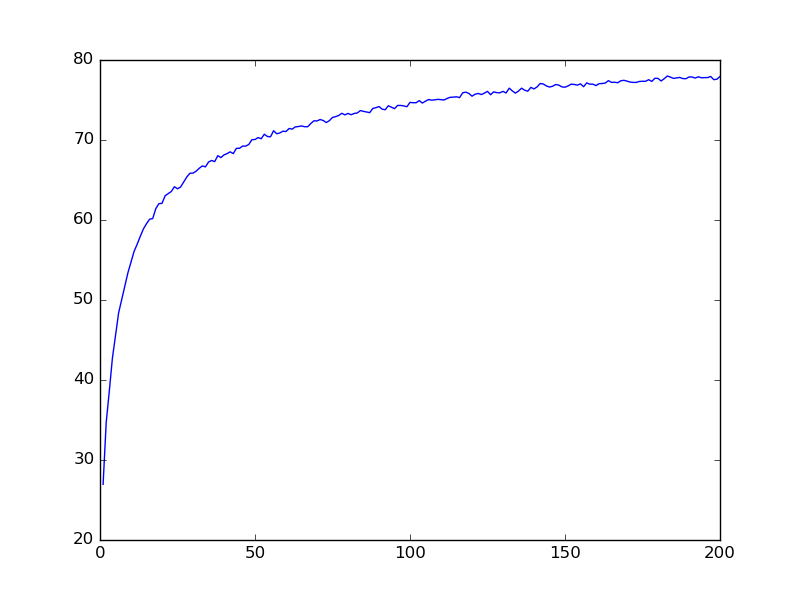
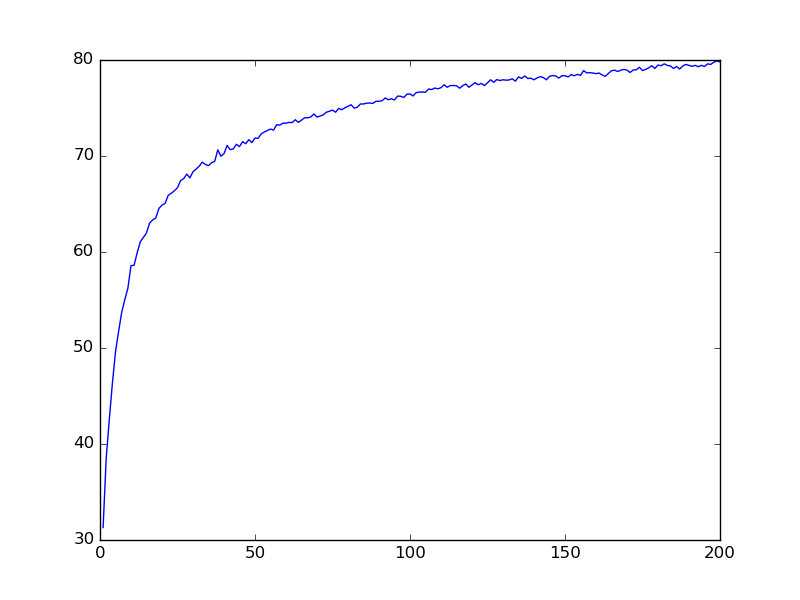
MLP-DEPTH4-WIDTH400-69%
MLP-DEPTH4-WIDTH200-64%
MLP-DEPTH4-WIDTH800-79%
MLP-DEPTH4-WIDTH1600-80%
MLP-DEPTH2-WIDTH800-78%
MLP-DEPTH2-WIDTH1600-82%
only 200 epochs for each set
More CNN Results
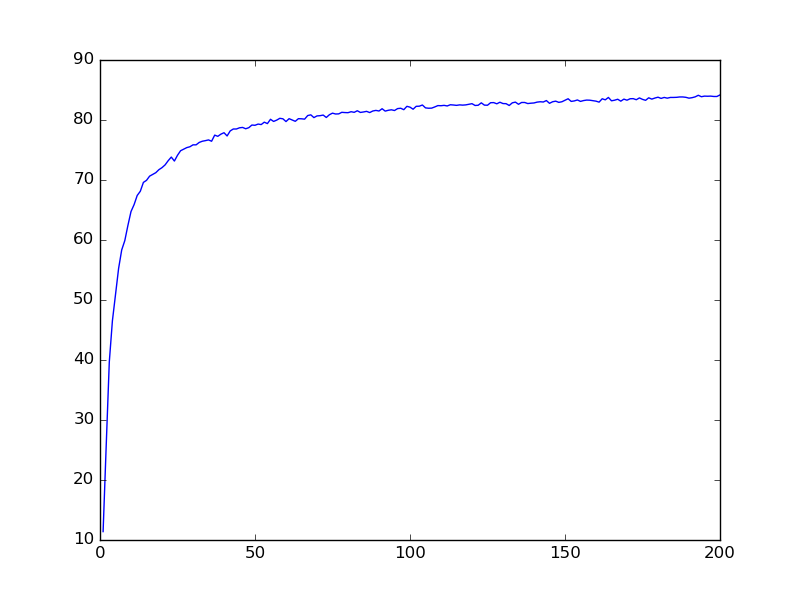
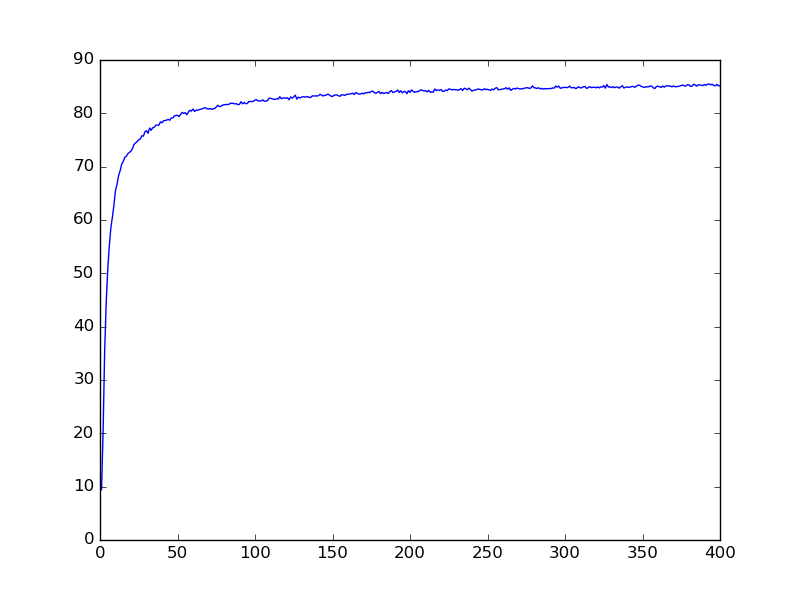
CNN-200EPOCHS-81%
CNN-400EPOCHS-86%
Try the code!
- Extract compressed fonts folder alongside mnist.py
- Run the following
~ python mnist.py --gen
# will generate the entire Farsi alphabet with all fonts placed inside ./fonts
# a folder named `data` will be used for storing the image
# .npz files store the images as numpy arrays for faster loading
~ python mnist.py mlp 500
# Train and evaluate a mlp model for 500 epochs
~ python mnist.py cnn 500
# Train and evaluate a cnn model for 500 epochs
~ python mnist.py custom_mlp:4,200,.2,.5 200
# Train and evaluate a mlp with 4 hidden layers, 200 neurons per layer,
# .2 drop input and .5 drop_out ( input / output connection ) FMNIST
By Kian Peymani



