
\text{Oral Qualifying Exam}
\textbf{Naresh Kumar Devulapally}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Dr. Vishnu Lokhande }\textit{(Ph.D. Supervisor)}
\text{Dr. Junsong Yuan}
\text{Dr. Siwei Lyu}
\textbf{\underline{Committee Members:}}

- Student's Portfolio
- Accepted First Author Papers
- First Author Papers - Under Review
- Collaboration (co-author) Papers - Under Review
- Course Instructor Experience
- RNNs, Transformers, Diffusion Models - Recap
- Paper 1: Large Language Diffusion Model
- Takeaways for future research in this area
- Paper 2: Immiscible Diffusion - Accelerating Diffusion Training.
- Paper 3: State Space Models, Mamba and LinOSS
- Q & A
\( \text{Contents of this Presentation:}\)
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Oral Qualifying Exam}
- Enhancing Privacy and Control in Generative Models
- Focus: Text to Image Diffusion Models
- Projects:
- ICCV 2025: Watermarking AIGC.
- ACM MM 2025: Unlearnable Sample Generation.
- NeurIPS 2025: Controlling hallucinations in Diffusion Models.
- NeurIPS 2025: Mitigating Catastrophic forgetting in LDMs.
- WACV 2026: De-biasing Latent Diffusion Models.
\( \text{Theme of Research so far:}\)
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Oral Qualifying Exam}
Accepted first author paper in BOLD.
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{ICCV 2025 - Object-Level Watermarking}
\( \textbf{Your Text Encoder Can Be An Object-Level Watermarking Controller}\)
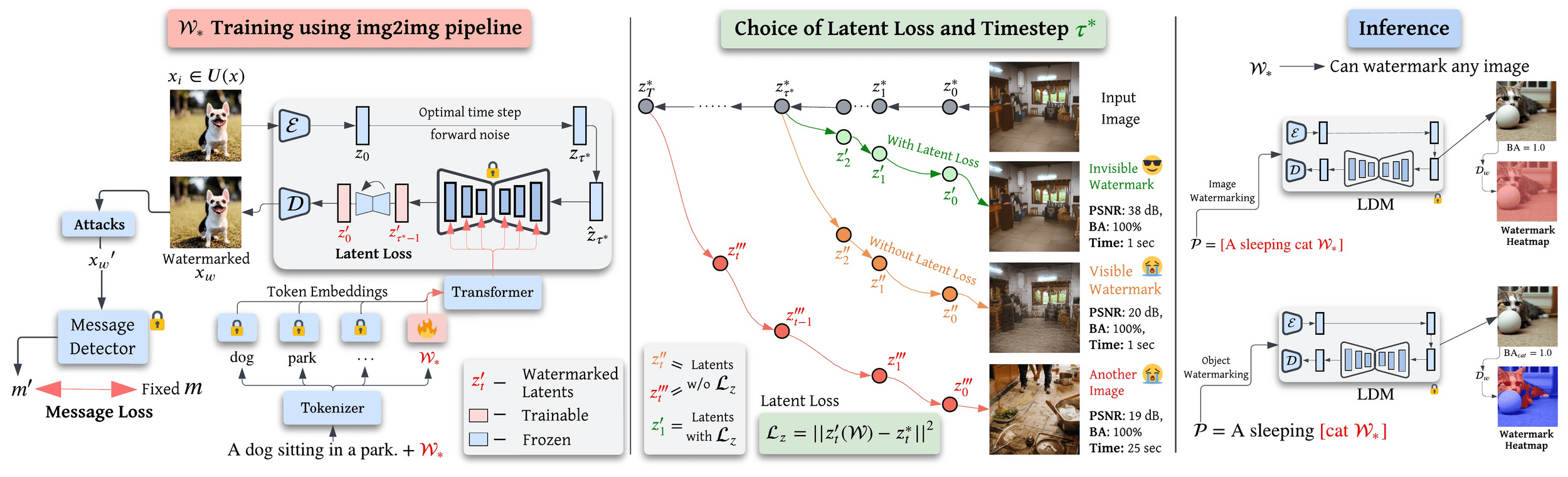

Train Single Token Text Embeddings for Watermarking
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{ICCV 2025 - Object-Level Watermarking}
\( \textbf{Your Text Encoder Can Be An Object-Level Watermarking Controller}\)
Latent Loss for Minimal Trajectory Adjustment to enable imperceptible watermarking
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{ICCV 2025 - Object-Level Watermarking}
\( \textbf{Your Text Encoder Can Be An Object-Level Watermarking Controller}\)
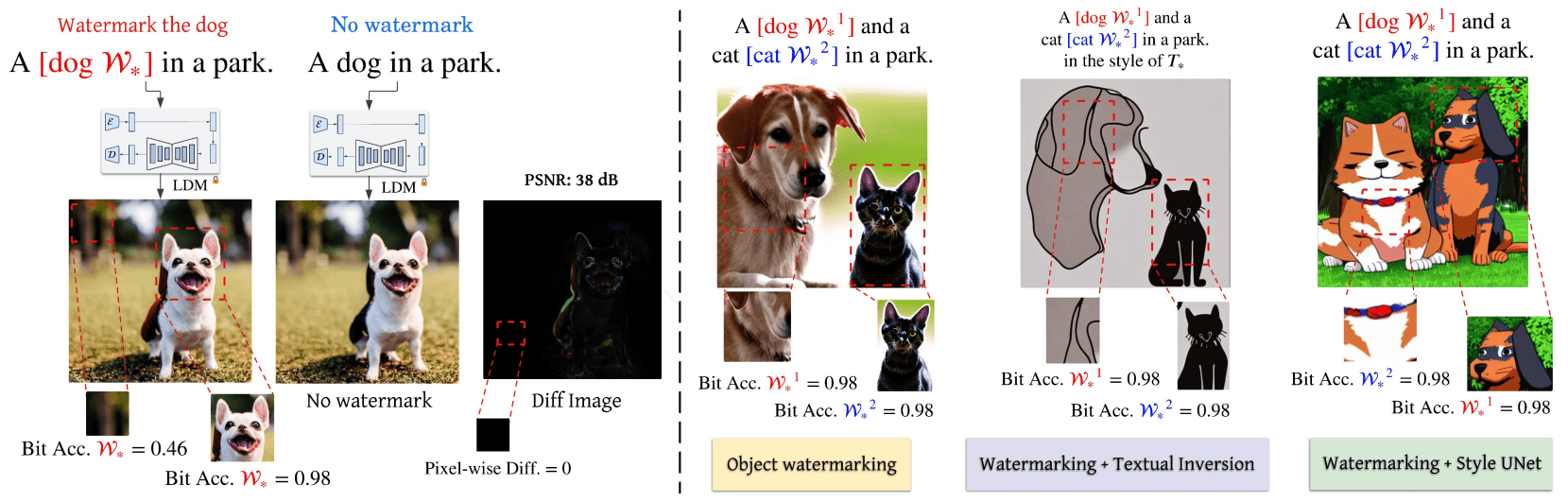
Same Token Embedding can be used for both Full-image and Object-Level Watermarking
(utilizing Cross-Attention Maps)
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{ICCV 2025 - Object-Level Watermarking}
\( \textbf{Your Text Encoder Can Be An Object-Level Watermarking Controller}\)

\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{ICCV 2025 - Object-Level Watermarking}

\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{ACM MM 2025 - Unlearnable Samples}

\( \textbf{Personalization through Trajectory Shifted Perturbations}\)
\( \textbf{Latent Diffusion Unlearning: Protecting against Unauthorized}\)
Shift Start of the Diffusion Denoising Trajectory for Latent-Level Unlearnable Sample.
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{ACM MM 2025 - Unlearnable Samples}
\( \textbf{Personalization through Trajectory Shifted Perturbations}\)
\( \textbf{Latent Diffusion Unlearning: Protecting against Unauthorized}\)
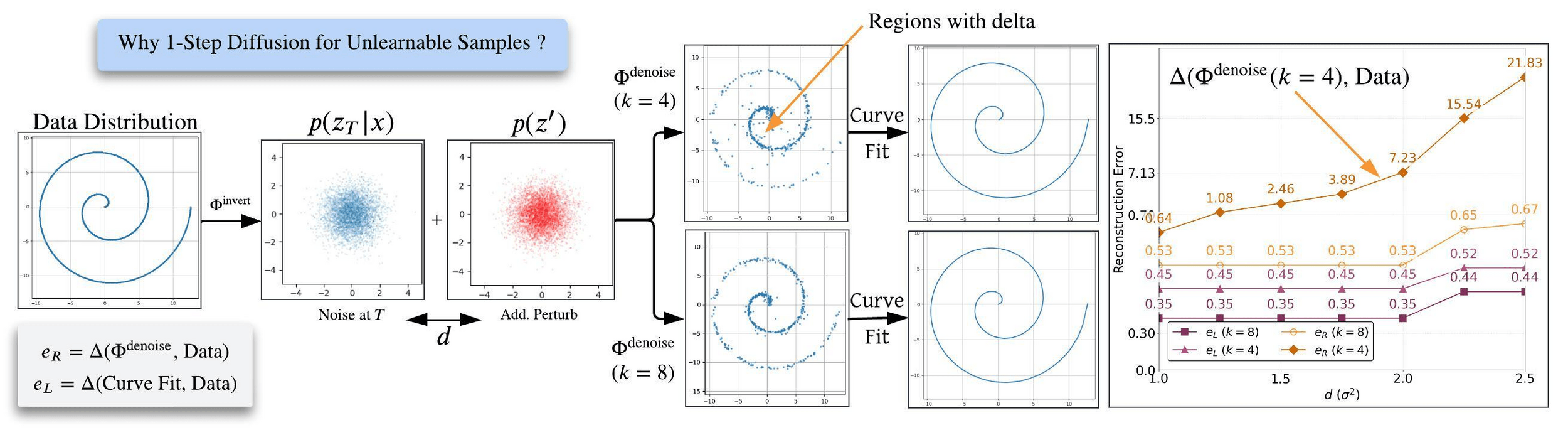
Shortcut Diffusion Models for Unlearnable Perturbation Propagation
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{ACM MM 2025 - Unlearnable Samples}
\( \textbf{Personalization through Trajectory Shifted Perturbations}\)
\( \textbf{Latent Diffusion Unlearning: Protecting against Unauthorized}\)
Artifact-Free
Unlearnable Samples

Visible Perturbation Overlay
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{ACM MM 2025 - Unlearnable Samples}
\( \textbf{Personalization through Trajectory Shifted Perturbations}\)
\( \textbf{Latent Diffusion Unlearning: Protecting against Unauthorized}\)

Resistance to Strong DiffPure Attack
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Student's Portfolio}
\( \textbf{Submitted First Author Papers - Under Review:}\)
\( \textbf{Controlling Hallucinations in Diffusion Models: A Case Study on Chess}\)
Mahesh Bhosale*, Naresh Kumar Devulapally*, Abdul Wasi Lone, Vishnu Suresh Lokhande, David Doermann
\( \textbf{Submitted to NeurIPS 2025:}\)
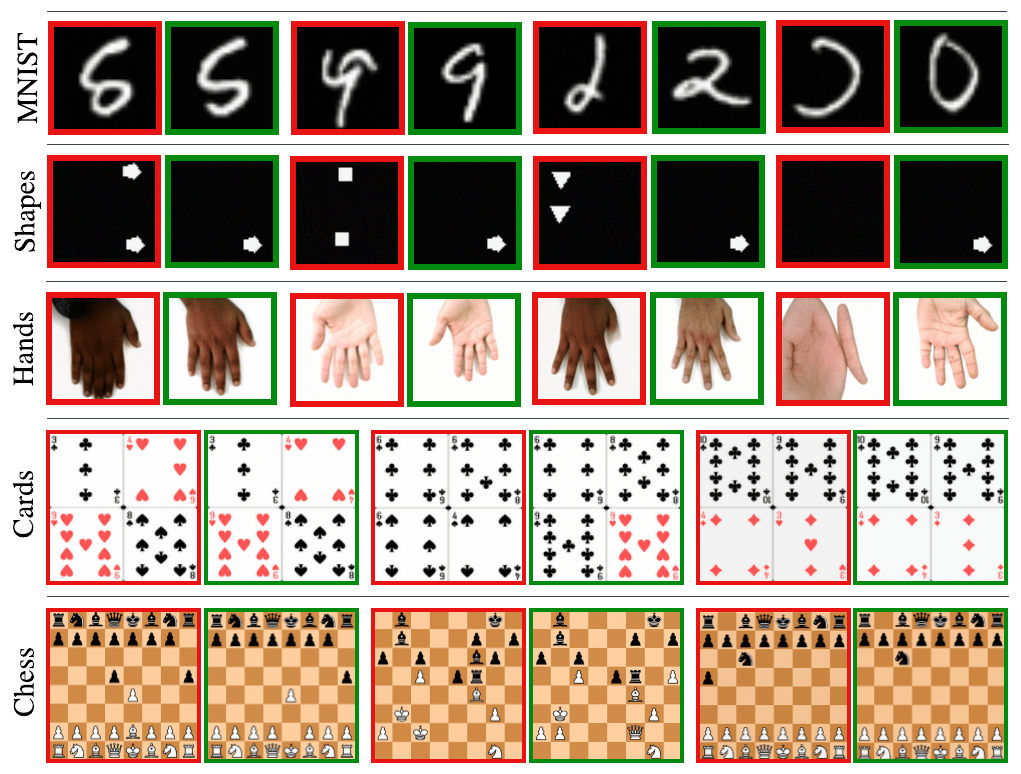
Variance Learning
and
Score Amplification
for
Hallucination Reduction
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Student's Portfolio}
\( \textbf{Teaching Experience:}\)
\( \text{Course Instructor:} \textbf{ Computer Vision and Image Processing}\)
\( \text{Summer - 2025} \)
\( \text{Number of Students: } \textbf{71}\)
\( \text{Variational AutoEncoders} \)
\( \text{Diffusion Models}\)
\( \text{Generative Adversarial Networks}\)
\( \text{Reading Group Summer 2025} \)
\( \text{Discuss Recent GenAI papers}\)
\( \text{PhD Students at UB}\)
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{CSE 4/573: CVIP - Summer 2025}
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{CSE 4/573: CVIP - Summer 2025}

\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Papers for Presentation}
- Large Language Diffusion Models
- ArXiV Preprint
- Accelerating Diffusion Training with Noise Assignment
- NeurIPS 2024
- Oscillary State-Space Models and Mamba
- ICLR 2025 (Oral)
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models}
Generative Modeling Principles
\max_{\theta} \mathbb{E}_{p_{\text{data}}(x)} [\log p_{\theta}(x)] \iff \min_{\theta} \mathrm{KL}(p_{\text{data}}(x) \|\| p_{\theta}(x))
unknown
• Generative modeling aims to learn a model \( p_\theta(x) \) that closely matches the real data distribution \( p_{\text{data}}(x) \) by minimizing their KL divergence or equivalently maximizing log-likelihood.
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Diffusion Loss}
Forward Diffusion
q(x_t \mid x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t} x_{t-1}, (1 - \alpha_t) I)
Reverse Diffusion
p_\theta(x_{t-1} \mid x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))
Training via ELBO
\mathcal{L}_{\text{ELBO}} = \mathbb{E}_q \left[ \log p(x_0) - D_{\text{KL}}(q(x_{1:T} \mid x_0) \parallel p_\theta(x_{1:T} \mid x_T)) \right]
Noise Matching Term
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Diffusion Loss}
Training via ELBO
\mathcal{L}_{\text{ELBO}} = \mathbb{E}_q \left[ \log p(x_0) - D_{\text{KL}}(q(x_{1:T} \mid x_0) \parallel p_\theta(x_{1:T} \mid x_T)) \right]
Noise Matching Term
\mathcal{L}_{\text{ELBO}} = \mathbb{E}_{q(x_0)} \left[ D_{\text{KL}}(q(x_T \mid x_0) \| p(x_T)) + \sum_{t=1}^T D_{\text{KL}}(q(x_{t-1} \mid x_t, x_0) \| p_\theta(x_{t-1} \mid x_t)) - \log p_\theta(x_0 \mid x_1) \right]
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Diffusion Loss}
Training via ELBO
\mathcal{L}_{\text{ELBO}} = \mathbb{E}_q \left[ \log p(x_0) - D_{\text{KL}}(q(x_{1:T} \mid x_0) \parallel p_\theta(x_{1:T} \mid x_T)) \right]
Noise Matching Term
\mathcal{L}_{\text{ELBO}} = \mathbb{E}_{q(x_0)} \left[ D_{\text{KL}}(q(x_T \mid x_0) \| p(x_T)) + \sum_{t=1}^T D_{\text{KL}}(q(x_{t-1} \mid x_t, x_0) \| p_\theta(x_{t-1} \mid x_t)) - \log p_\theta(x_0 \mid x_1) \right]
Parallel Decoding
Fixed-Time Sampling
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - AR Loss}
Autoregressive Formulation in Traditional LLMs
p_\theta(x) = p_\theta(x^1) \prod_{i=2}^{L} p_\theta(x^i \mid x^1, \ldots, x^{i-1})
Each token prediction depends on previous tokens.
Sequential sampling
No parallelism
Error compounding
Sequential sampling
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Question}
Is the autoregressive paradigm the only viable path to achieving the intelligence exhibited by LLMs?
Research Question:
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Method}
Large Language Diffusion Models
Pre-training
Supervised Finetuning
Sampling
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Method}
Large Language Diffusion Models - Contributions
- Scalability
- In-Context Learning
- Instruction-Following
- Reversal Resoning
- Outperforms GPT-4o
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Method}
Large Language Diffusion Models - Loss
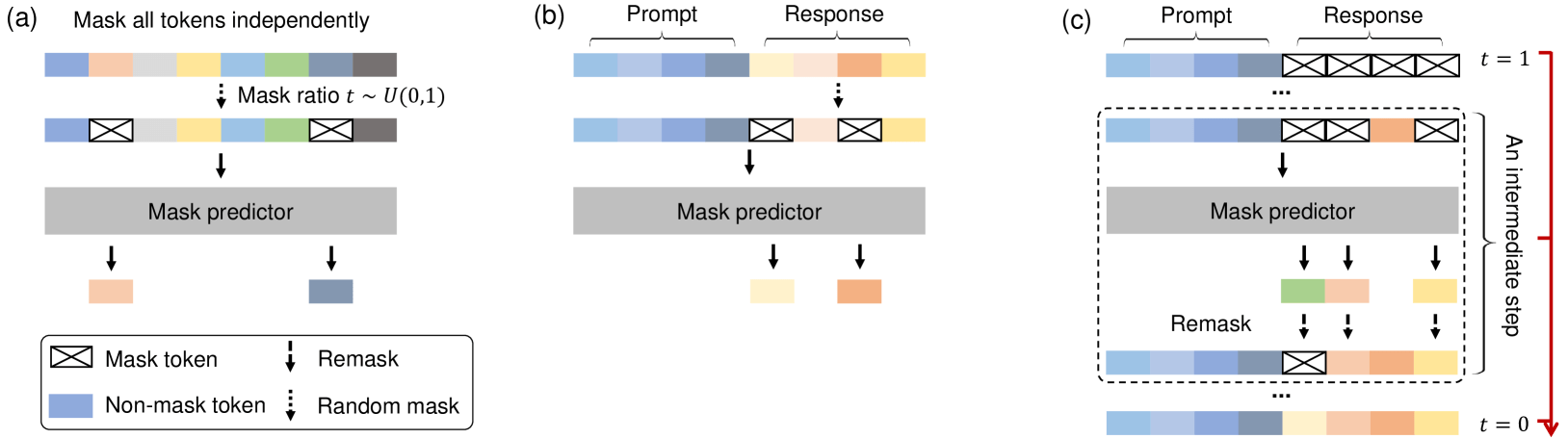
\mathcal{L}(\theta) \triangleq - \mathbb{E}_{t, x_0, x_t} \left[ \frac{1}{t} \sum_{i=1}^{L} \mathbf{1}[x_t^i = \text{M}] \log p_\theta(x_0^i \mid x_t) \right]
LLaDA’s core is a mask predictor: a model \( p_\theta(\cdot \mid x_t) \) that takes a masked sequence \( x_t \) and predicts all masked tokens (set \( M \)) simultaneously.
Pre-trained on 2.3 trillion tokens took 0.13 milion H800 GPU hours.
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Method}
Large Language Diffusion Models - SFT Loss
\mathcal{L}_{(SFT)} \triangleq - \mathbb{E}_{t, p_0, r_0, r_t} \left[ \frac{1}{t} \sum_{i=1}^{L'} \mathbb{1}[r_t^i = \text{M}] \log p_\theta(r_0^i \mid p_0, r_t) \right]
\( L' \) - dynamic length response.
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
Large Language Diffusion Models - Inference
Initialization: The input sequence is constructed as [prompt tokens] + [MASK tokens] of target length.
Block-wise Iterative Denoising: The generation proceeds block-by-block. At each step, the model predicts logits for all masked positions in the current block.
Confidence-based Remasking Loop: This denoising loop is repeated for a fixed number of steps. Enables parallel yet progressive refinement of the full sequence.
\text{Paper 1: Large Language Diffusion Models - Method}
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Method}
Evaluation Metrics
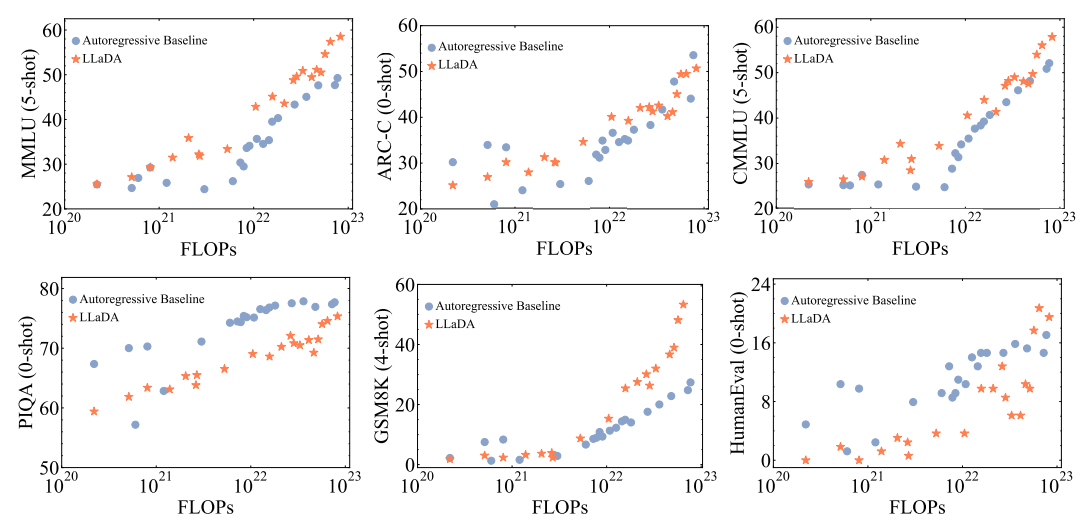
- Scalability - (FLOPs v/s Performance)
- In-Context Learning - (Few-shot accuracy curves)
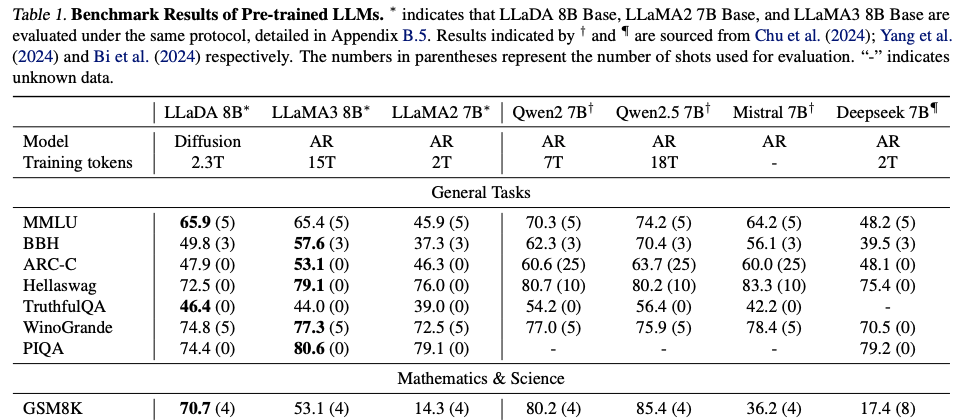
- Instruction-Following - (Supervised Fine-Tuning (SFT) accuracy)
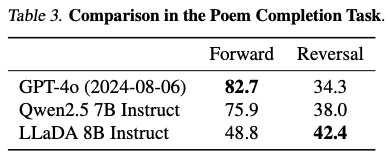
- Reversal Reasoning - Poem Completion Task
- Outperforms GPT-4o
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Method}
Scalability
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Method}
Performance compared to baselines
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Method}
Reversal Reasoning
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Method}
Limitations: Inference Time (No KV Caching)
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 1: Large Language Diffusion Models - Method}
Accelerating Diffusion Large Language Models with SlowFast Sampling


\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
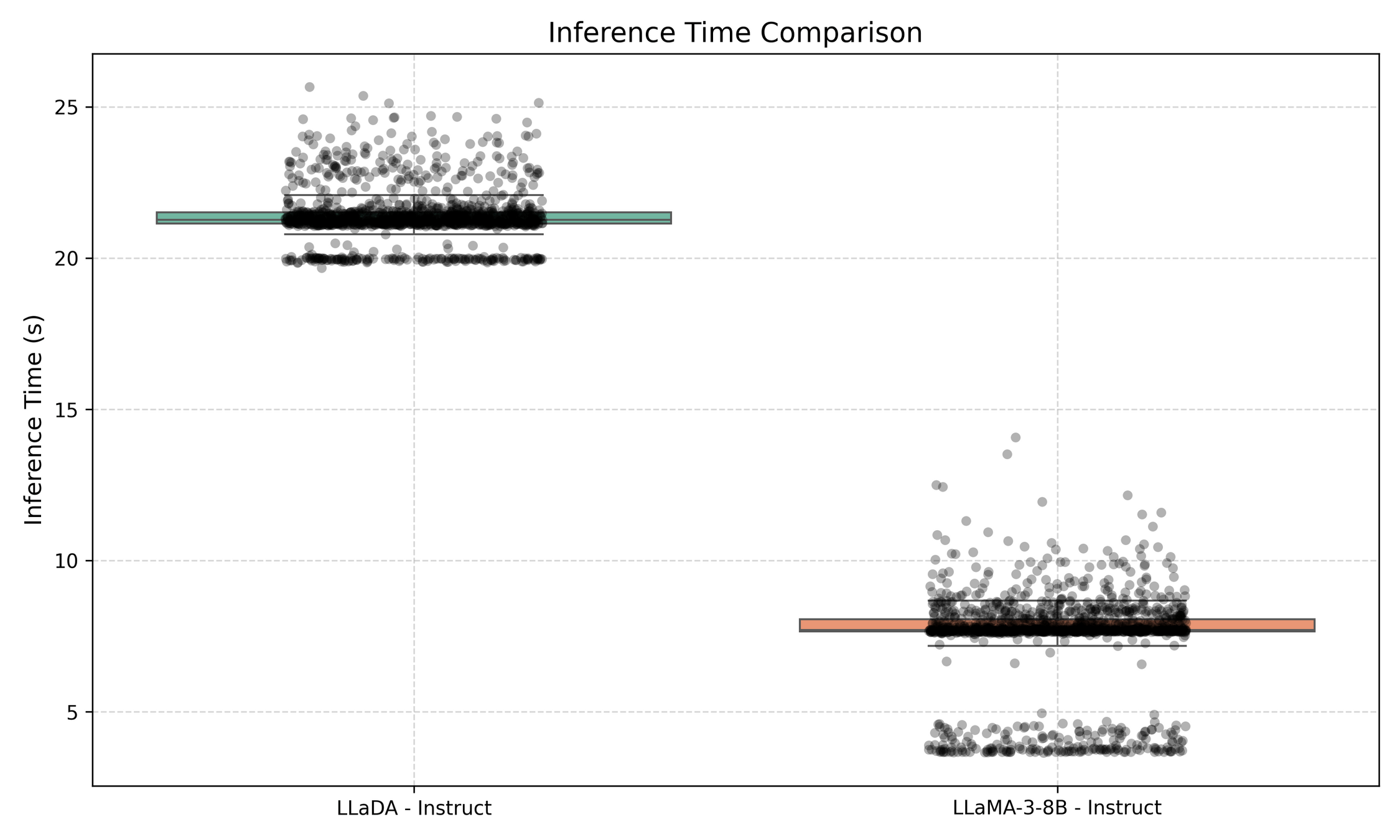
\text{Experiments - Large Language Diffusion Models}
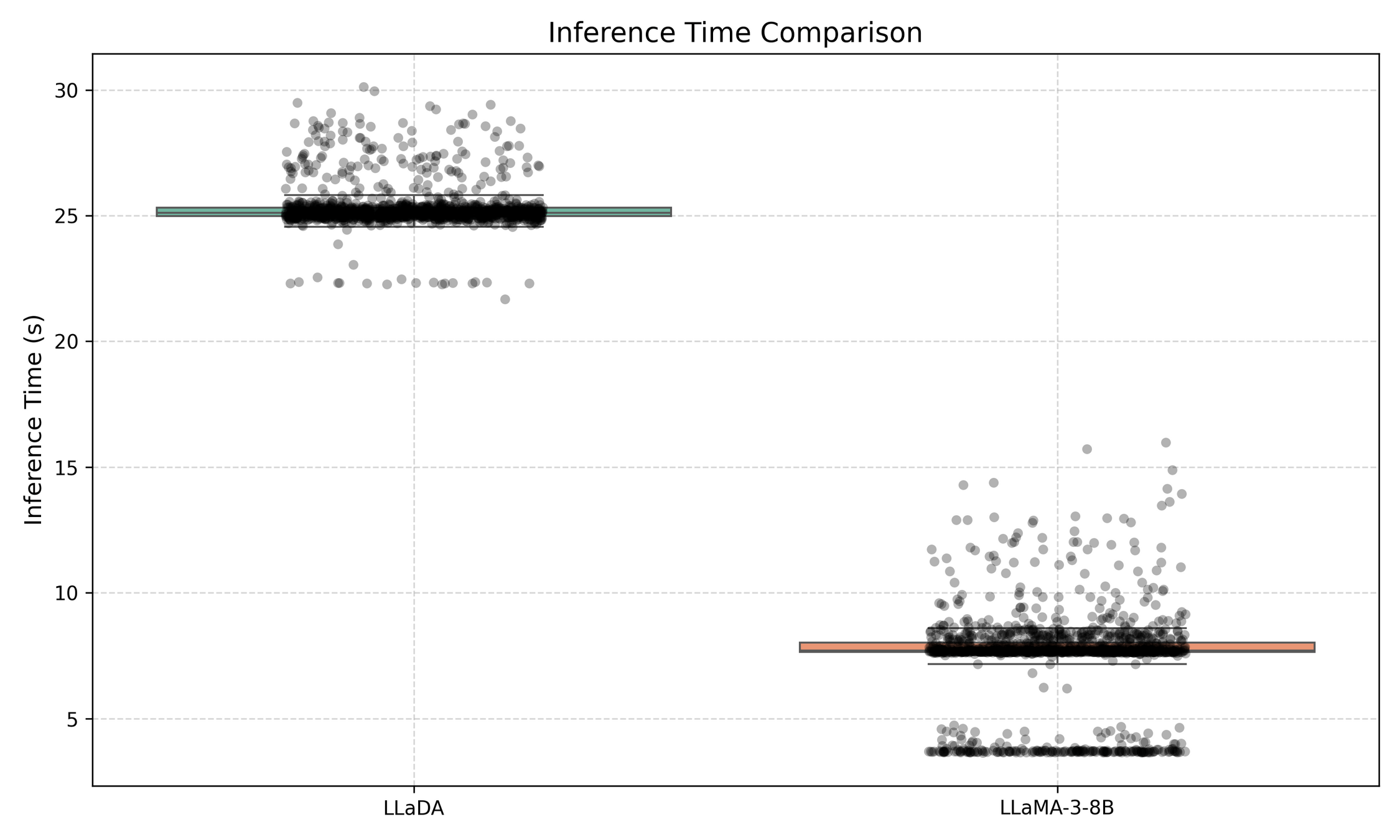
LLaDA Acc: 50.19%, LLaMA: 41.09% (GSM8k)
LLaDA Acc: 75.21%, LLaMA: 71.42% (GSM8k)
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
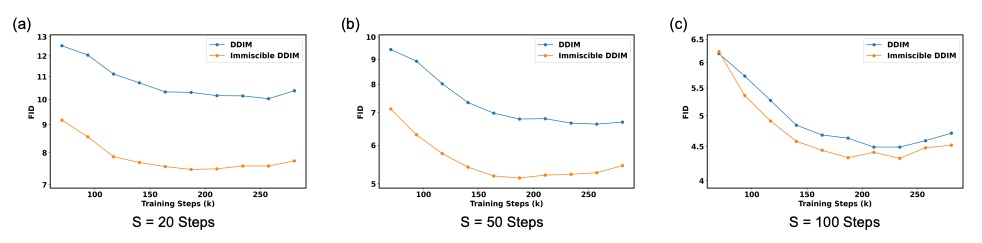
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
Problem Statement
- Diffusion models are powerful generative models that learn to denoise Gaussian noise into image samples.
- However, training is inefficient, especially in few-step settings like Consistency Models or DDIM.
Motivation
Accelerate Diffusion Training
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
Key Insight
- The random pairing of images and noise (miscibility) leads to uninformative gradients and optimization difficulty.
- Goal: Improve training by structuring image-noise mapping using Immiscible Diffusion.
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
Posterior Under Miscibility:
p(x_0 \mid x_T) = \frac{q(x_T \mid x_0) \cdot p(x_0)}{p(x_T)} \approx p(x_0)
Weak learning signal.
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
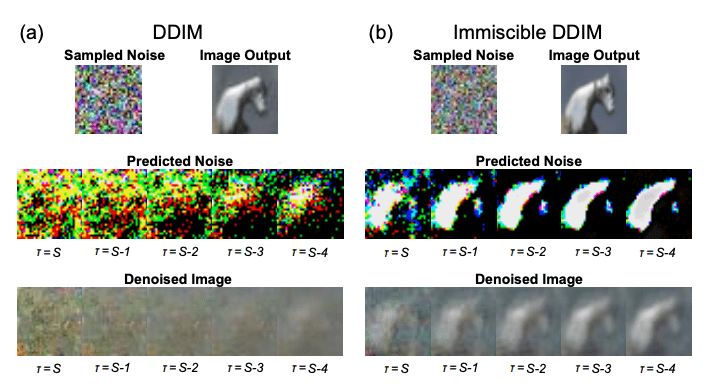
Noise Prediction in Vanilla DDIM:
\epsilon = \frac{x_T - \sqrt{\alpha_T} \, x_0}{\sqrt{1 - \alpha_T}} = a x_0 + b x_T
where:
a = -\frac{\sqrt{\alpha_T}}{\sqrt{1 - \alpha_T}}, \quad b = \frac{1}{\sqrt{1 - \alpha_T}}
\mathbb{E}[\epsilon(x_T, T)] = a \bar{x}_0 + b x_T
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
Immiscible Diffusion
Use linear assignment to optimally match each image in the batch with a noise sample:
\min_{\pi \in S_n} \sum_{i=1}^n \| x_0^i - \epsilon^{\pi(i)} \|_2
- This ensures each image gets closer noise.
- Prevents global mixing.
- Implemented in 1 line using Hungarian algorithm (scipy)
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
Conditional Distribution After Assignment
p(x_T \mid x_0) = f(x_T - x_0) \cdot \mathcal{N}(x_T; 0, I)
\( f(\cdot) \): Decaying function (e.g., Gaussian)
Each image diffuses to a local region in noise space
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
Posterior Becomes Informative
p(x_0 \mid x_T) \propto f(x_T - x_0) \cdot p(x_0)
The posterior is no longer uniform, it's peaked around assigned images.
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
Noise Prediction in Immiscible Diffusion
\epsilon(x_T, T) = a \sum_{x_0} f(x_T - x_0) \, x_0 \, p(x_0) + b x_T
Model now learns to predict noise that corresponds to a local cluster of images.
Enables strong gradients even at high noise levels.
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
Batch Assignment Algorithm
Inputs:
- \( x_b \): batch of images
- \( \epsilon_b \): batch of noise
- \( t_b \): batch of diffusion steps
\texttt{assign\_mat} \leftarrow \texttt{linear\_sum\_assignment}(\| x_b - \epsilon_b \|_2)
Output:
x_{t,b} = \sqrt{\alpha_t} x_b + \sqrt{1 - \alpha_t} \cdot \epsilon_b[\texttt{assign\_mat}]
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
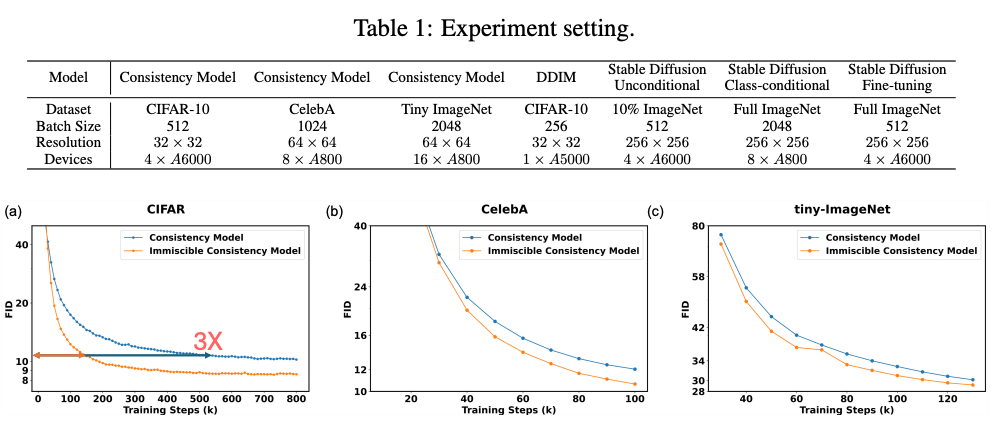
Contributions
- Identified miscibility issue in noise-image mapping.
- Proposed immiscible diffusion using optimal assignment.
- Theoretically derived effects via posterior + expected noise.
- Demonstrated 1-line code fix with broad applicability.
- Achieved up to 3× speedup without compromising quality
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 2: Immiscible Diffusion - Accelerating Diffusion Training}


\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 3: State Space Models and Mamba}
Motivation
-
Transformers: \( O(N^2) \) compute, autoregressive inference.
-
RNNs: constant-time inference but poor trainability
-
Goal: combine the best of both.
-
State Space Models (SSMs) + fast scan + physics-inspired dynamics = efficient LLMs
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 3: State Space Models and Mamba}
Motivation
-
Transformers: \( O(N^2) \) compute, autoregressive inference.
-
RNNs: constant-time inference but poor trainability
-
Goal: combine the best of both.
-
State Space Models (SSMs) + fast scan + physics-inspired dynamics = efficient LLMs
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
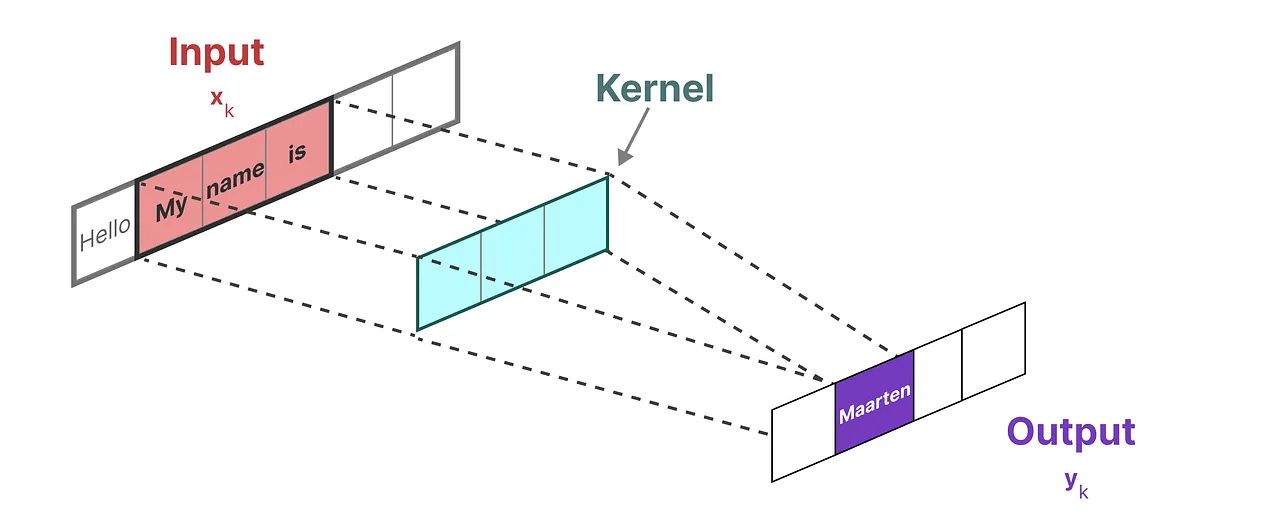
\text{Paper 3: State Space Models and Mamba}
Sequence Modeling
- Input: \( x_1, \dots, x_T \)
- Output: \( y_1, \dots, y_T \)
- Continuous signals: \( x(t) \rightarrow y(t) \)
- Discrete signals: NLP, genomics, etc.
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 3: State Space Models and Mamba}
Ideal Properties
-
\( O(1) \) inference.
-
\( O(N) \) training with parallelism
-
Linearly scalable with sequence length
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 3: State Space Models and Mamba}
Linear State-Space Models (SSMs)
\dot{h}(t) = Ah(t) + Bx(t) \\
y(t) = Ch(t) + Dx(t)

\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 3: State Space Models and Mamba}
Discretization via Euler / ZOH
h_{t+1} = (I + \Delta A) h_t + \Delta B x_t = \bar{A} h_t + \bar{B} x_t
Takeaway: Converts continuous dynamics to discrete steps
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 3: State Space Models and Mamba}
Recurrent Update
h_0 = \bar{B}x_0 \rightarrow y_0 = Ch_0 \\
h_1 = \bar{A}h_0 + \bar{B}x_1 \rightarrow y_1 = Ch_1
Efficient \( O(1) \) inference
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 3: State Space Models and Mamba}
Convolutional Reformulation
y_k = C \bar{A}^k \bar{B}x_0 + \cdots + C \bar{B}x_k
Training can be parallelized as convolution
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
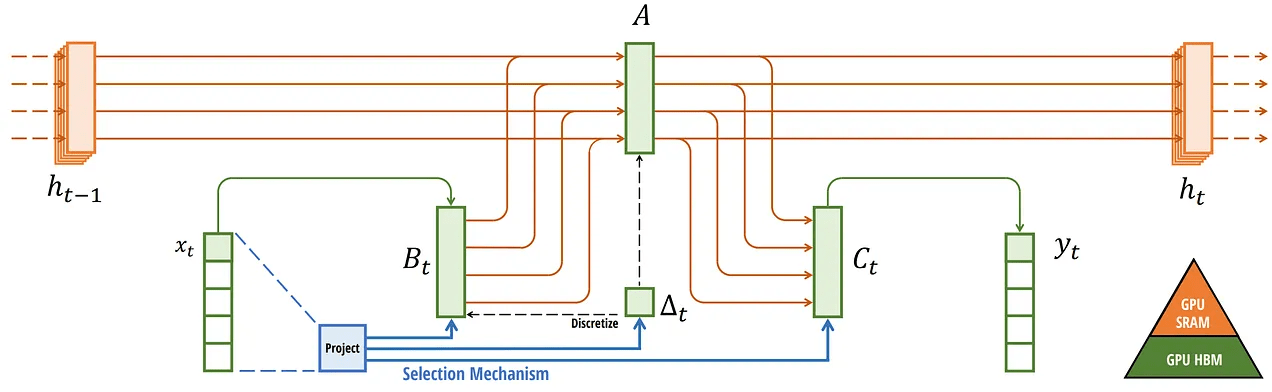
\text{Paper 3: State Space Models and Mamba}
Mamba

\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 3: Oscillatory State Space Models}
Oscillatory State Space Models (LinOSS)
Based on forced harmonic oscillators:
y''(t) = -Ay(t) + Bu(t) \\
x(t) = Cy(t) + Du(t)
Introduce auxiliary state: \( z = y' \)
Takeaway: Introduces second-order dynamics to capture oscillations
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 3: Oscillatory State Space Models}
Implicit Discretization of LinOSS
y''(t) = -Ay(t) + Bu(t) \\
x(t) = Cy(t) + Du(t)
Introduce auxiliary state: \( z = y' \)
Takeaway: Introduces second-order dynamics to capture oscillations
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
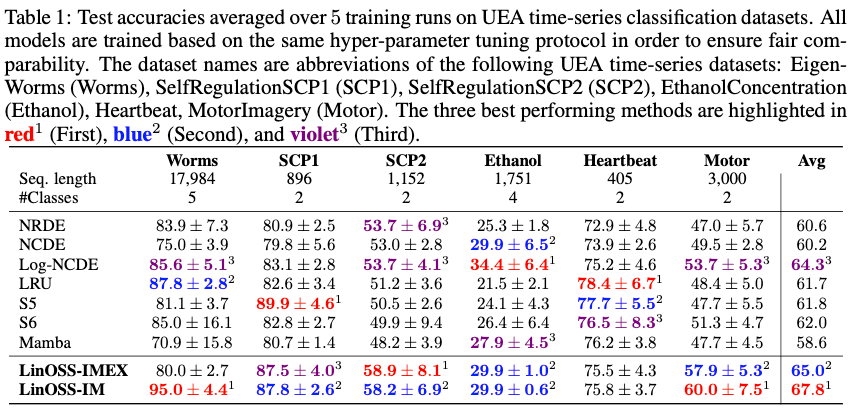
\text{Paper 3: Oscillatory State Space Models}
LinOSS
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Paper 3: Oscillatory State Space Models}
LinOSS - Why do the results matter?
- Fast Prefix-sum scan: \( O(log N) \) depth.
- Works well on GPU, supports backprop.
- Linear memory scaling with sequence length.
- No attention matrix ⇒ ideal for long-range processing
LinOSS is a enables long-sequence modeling at scale.
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Future Research}
Future Research on Large Language Diffusion Models
- Towards efficient inference in LLaDA models.
- Existing methods such as personalization in Diffusion Models to Large Language Diffusion Models.
- User-specific adaptation
- Domain-specific knowledge
- Task tuning: Improve performance on summarization, question-answering, etc., in narrow settings.
- Memory/Contextual grounding: Make the model “remember” previous interactions or documents.
Personalization:
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{Oral Qualifying Exam}
\text{July 18, 2025}
\text{Future Research}
References:
- https://github.com/ML-GSAI/LLaDA
- https://github.com/Gen-Verse/MMaDA
- https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mamba-and-state
- https://github.com/hkproj/mamba-notes
- https://github.com/yhli123/Immiscible-Diffusion
- https://arxiv.org/abs/2410.03943
Oral Qualifying Exam - Naresh
By Naresh Kumar Devulapally
Oral Qualifying Exam - Naresh
My PhD Oral Qualifying Exam slides




