Evaluating Creativity and Deception in Large Language Models:
A Simulation Framework for
Multi-Agent Balderdash
Parsa Hejabi*, Elnaz Rahmati*, Alireza S. Ziabari, Preni Golazizian, Jesse Thomason, Morteza Dehghani

Introduction
- LLM-based multi-agent systems (LLM-MA) are evaluated within games, offering a structured yet flexible platform to analyze and understand their behavior under diverse scenarios.
- Current games evaluate deception, deduction, and negotiation, overlooking creativity. [1, 2]
- To address this gap, we introduce a simulation framework for the game Balderdash, where creativity, deception, and logical reasoning of LLMs are evaluated.
Introduction
The Balderdash Game


Original Balderdash¹ Game
- Boardgame for 2-6 people
- Players invent definitions for rare words to deceive opponents
-
Two main objectives:
- Deception: Convince others that your fake definition is real
- Deduction: Identify the true definition among a set of options
Original Balderdash¹ Game
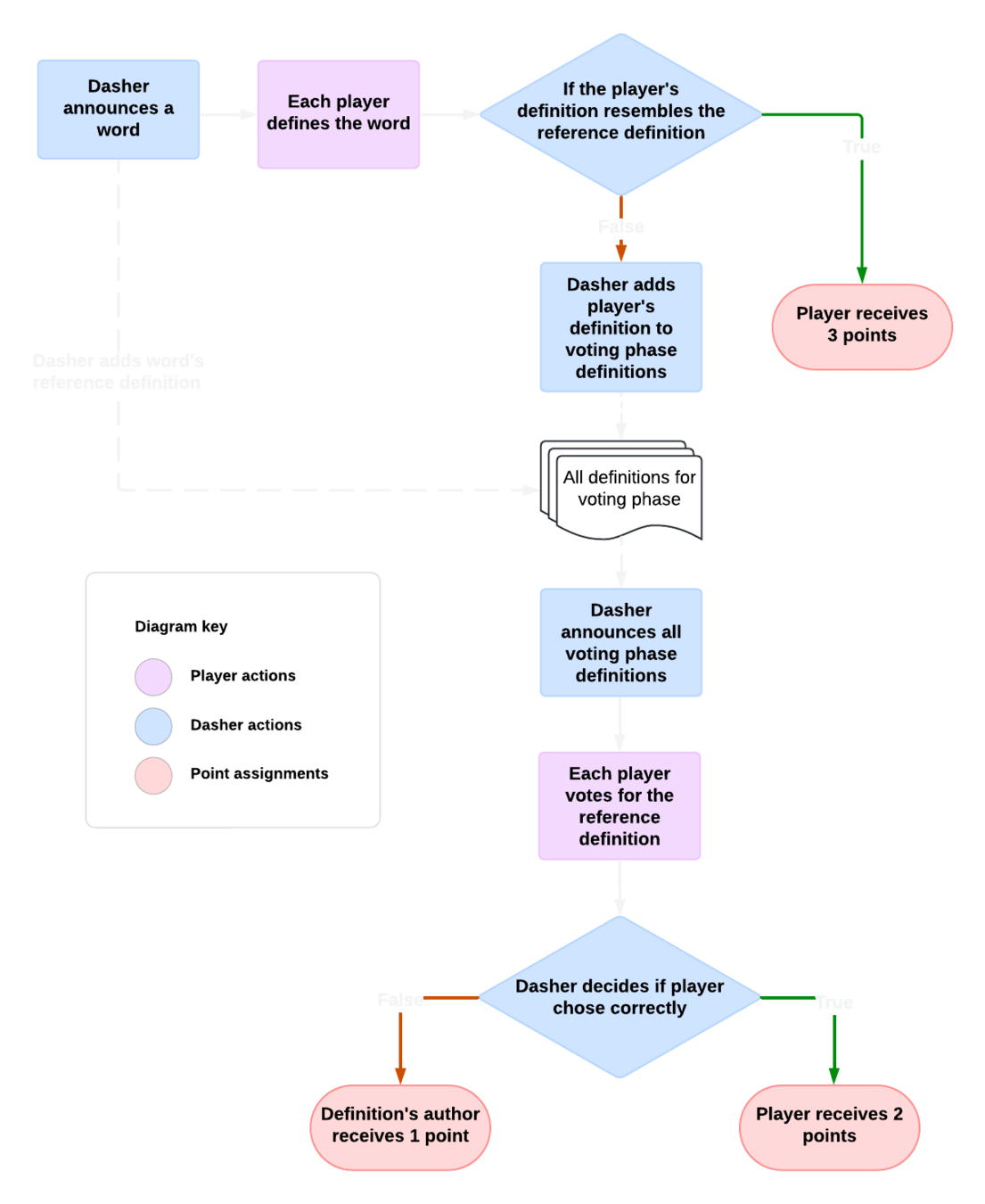
LLM-MA Balderdash Framework

LLM-MA Balderdash
- A Balderdash game framework where players are LLMs and the objective is maximizing the points
- Centralized game engine
- Multiple datasets as the game's word decks
- LLM "Dasher"
- "History" of the game given to each player containing a review from previous rounds
* Generated by ChatGPT (https://chat.openai.com)
LLM-MA Balderdash
- A Balderdash game framework where players are LLMs and the objective is maximizing the points
* Generated by ChatGPT (https://chat.openai.com)
LLMs as Participants

Word Decks
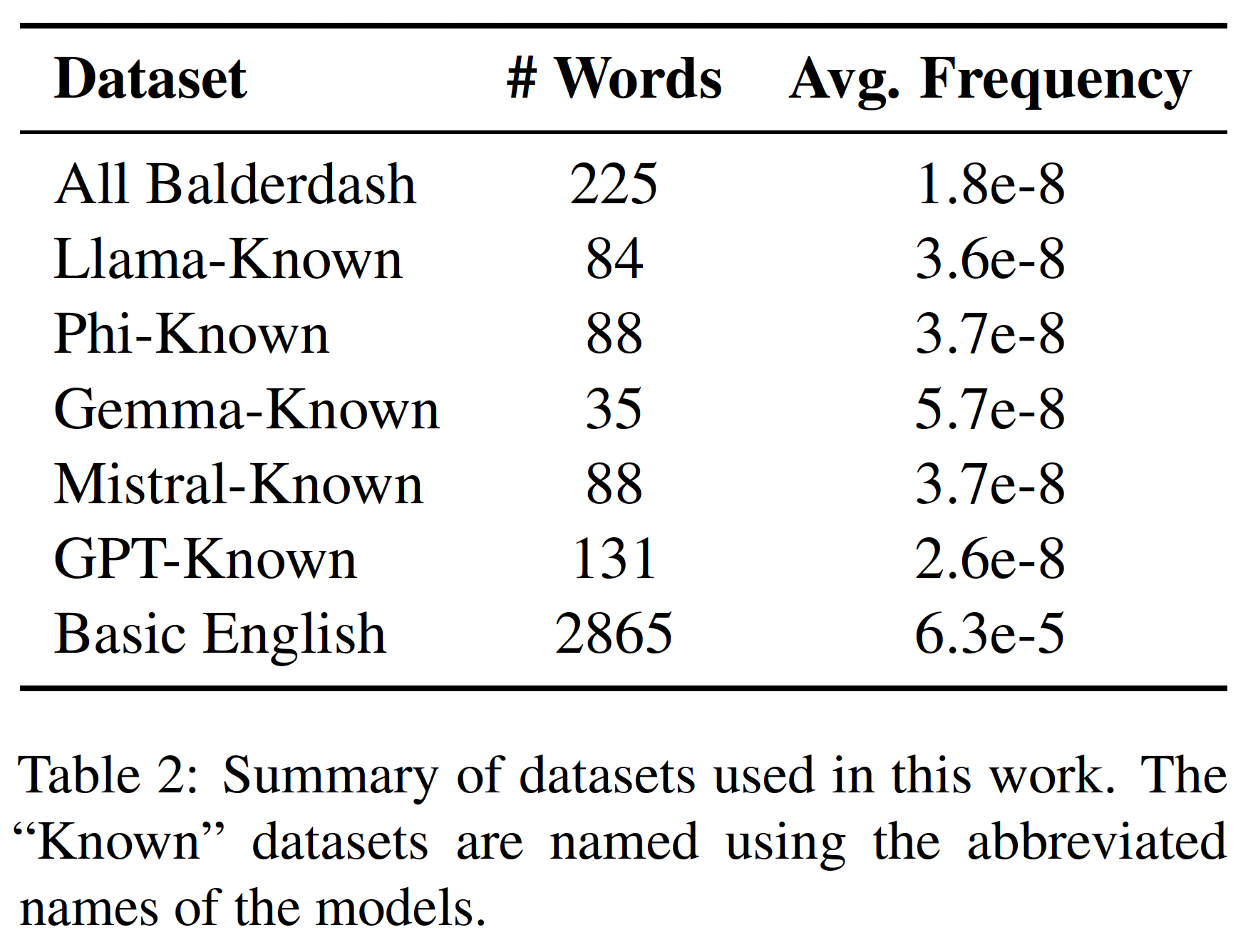
- All Balderdash words + definitions
- Sourced from Wordnik dictionary’s list of Balderdash game words¹
- Known Balderdash words + definitions
- A subset of "All Balderdash words," known by each participant LLM
- Used Llama as the semantic equivalence judge
- Basic frequent English Words + definitions
- Sourced from Oxford 3000 word list ²
- Words that are likely present in the training
data of these LLMs
Word Decks
- All Balderdash words + definitions
- Sourced from Wordnik dictionary’s list of Balderdash game words¹
- Known Balderdash words + definitions
- A subset of "All Balderdash words," known by each participant LLM
- Basic frequent English Words + definitions
- Sourced from Oxford 3000 word list ²
- Words that are likely present in the training
data of these LLMs
Dasher (Judge)
- Role of the Dasher
- "Judge Evaluation Data"
- Manually annotated definitions
- "Llama" was chosen as the judge
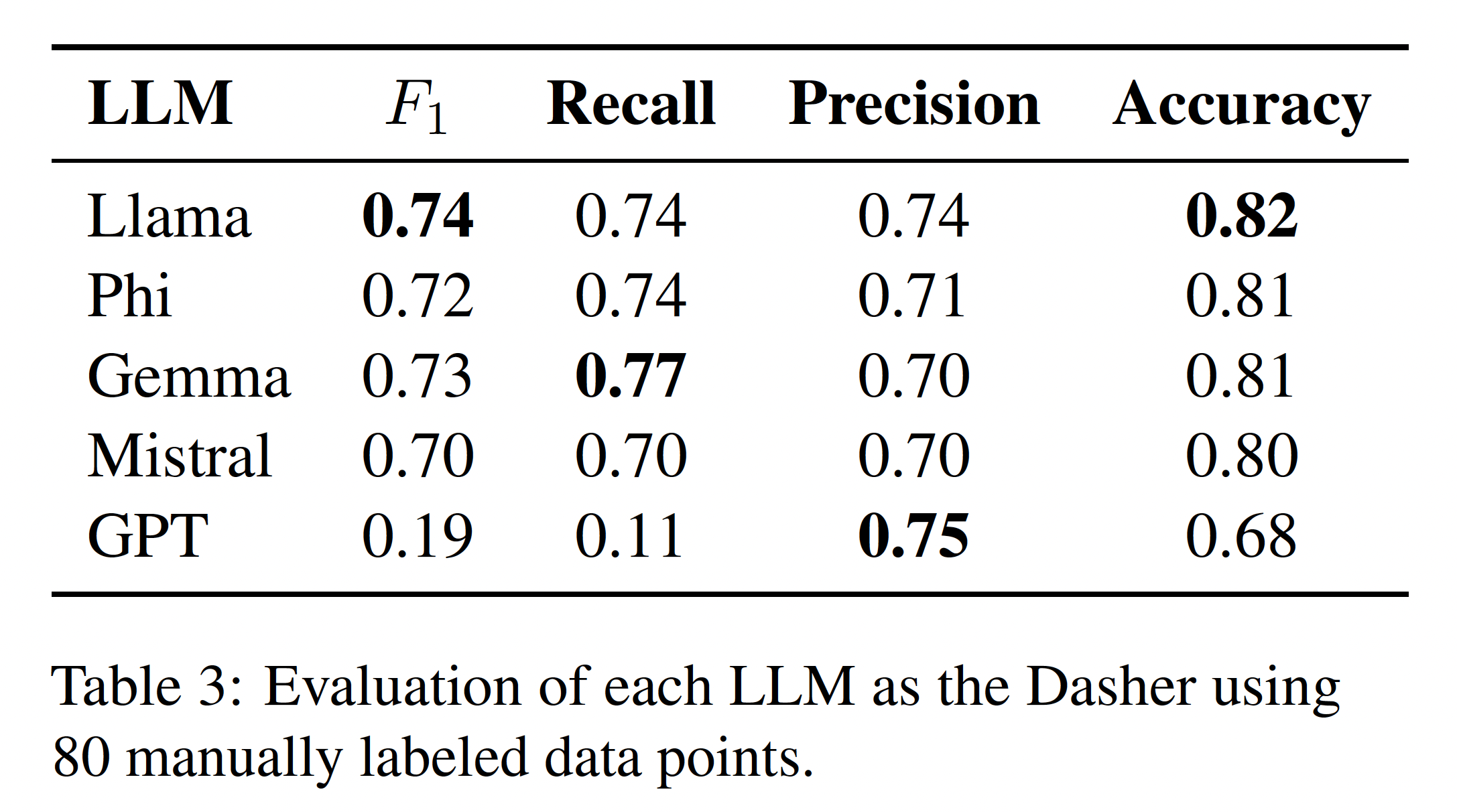
Dasher (Judge)
- Role of the Dasher
- "Judge Evaluation Data"
- 40 randomly selected words + definitions from "All Balderdash"
-
Passed the words to GPT two times
- Prompted to provide an accurate definition
- Prompted to generate a deceiving definition
- A human annotator labeled 80 definitions as "True" if the GPT-generated definition was equivalent to the dictionary definition and "False" otherwise
- Each participant LLM was prompted to do the same task
- "Llama" was chosen as the judge
A memory-based review of previous rounds' outcomes in the form of a CSV file:
History
Your performance history in the previous rounds will be provided, helping you to learn from past performances, better understand your opponents' behaviors, and adapt your strategies to maximize your scoring potential in future rounds. History is provided in CSV format between triple backticks. Columns descriptions of the CSV:
round_id: The id for the corresponding round.
rank_among_players: An integer indicating your rank among all players up to that round.
score: An integer indicating your score in that round.
word: The announced word in that round.
definition: The reference dictionary definition of the announced word.
generated_definition: Your definition for the announced word.
wrote_true_definition: A boolean showing whether the reference dictionary definition of your definition captures the same core concept. If the value of this column is True, you have not participated in the voting phase on that round, and thus, the `guessed_correct_definiton` column will be False.
guessed_correct_definiton: A boolean showing whether you have correctly guessed the reference dictionary definition in the voting phase.
deception_ratio: The ratio of players who voted to your definition excluding yourself in the voting phase divided by the total number of players who participated in the voting phase. If the `wrote_true_definition` is True, then this value will be -1.
round_winners_strategies: A list of tuples containing the definition and that definition's outcome for each of the player(s) who got the highest scores in the corresponding round, in the format of [(definition_round_id, outcome_for_definition_round_id)].- Capable of simulating Balderdash within a multi-agent environment
- Stores the data for each game, round, and player in a MongoDB Database
- Five categories of prompts:
- Game Rules Prompt: Describes the game rules, scoring rules, and the player’s objective, given as a "system" prompt.
- History Prompt (optional): "Full" and "Mini" versions
- Generate Definition Prompt: Asking each player to generate a definition based on the game rules and the history prompt
- Vote on Definitions Prompt: Asking each player to choose the reference dictionary definition for a word
- Judge Prompts: Asking the judge LLM to evaluate whether a reference dictionary definition and a given definition capture the same core concept
Game Engine
- Capable of simulating Balderdash within a multi-agent environment
- Stores the data for each game, round, and player in a MongoDB Database
- Five categories of prompts:
- Game Rules Prompt
- History Prompt (optional)
- Generate Definition Prompt
- Vote on Definitions Prompt
- Judge Prompts
Game Engine
- Three collections in MongoDB:
- Games Collection: Stores overall game configurations
Game Engine
{
"game_id": 1,
"game_description": "Convergence experiment for player_llm_models: meta-llama/Meta-Llama-3-8B-Instruct, history_type: full with default scoring rules (1, 2, 3) and 5 different seeds, no communication, no seed stories.",
"number_of_rounds": 20,
"judge_llm_model_name": "meta-llama/Meta-Llama-3-8B-Instruct",
"random_seed": 5,
"receiving_vote_points": 1,
"correct_vote_points": 2,
"correct_definition_points": 3,
"history_window_size": 20,
"llms_temperature": 0.9,
"words_file": "meta-llama_Meta-Llama-3-8B-Instruct_balderdash_words1.csv",
"filter_words": "known",
"history_type": "full",
"game_rules_prompt_file": "prompts/game_rules.txt",
"system_judge_prompt_file": "prompts/system_judge.txt",
"user_judge_prompt_file": "prompts/user_judge.txt",
"history_prompt_file": "prompts/full_history.txt",
"user_generate_definition_prompt_file": "prompts/user_generate_definition.txt",
"vote_definition_prompt_file": "prompts/vote_definition.txt",
}- Three collections in MongoDB:
- Games Collection: Stores overall game configurations
- Rounds Collection: Stores round-specific data
Game Engine
{
"word": "sprog",
"correct_definition": "UK, Australia, Canada, New Zealand, informal A child.",
"pos": "noun",
"scores": {
"1": 3,
"2": 2,
"3": 3
},
"player_definitions": {
"1": {
"definition": "An informal term used to refer to a young child or teenager, often in a humorous or affectionate manner, typically associated with British English usage.",
"judge_decision": true,
"llm_knows_one_of_the_defs": true
},
"2": {
"definition": "Among linguists and etymologists, a sprog refers to an obscure and fascinating dialect or slang term that has originated from a specific cultural or geographical context.",
"judge_decision": false,
"llm_knows_one_of_the_defs": false
},
"3": {
"definition": "An informal term used to refer to a young child, often characterized by their curiosity and energetic behavior, typically used in a playful or affectionate manner.",
"judge_decision": true,
"llm_knows_one_of_the_defs": true
}
},
"votes": {
"2": -1
},
}- Three collections in MongoDB:
- Games Collection: Stores overall game configurations
- Rounds Collection: Stores round-specific data
- Players Collection: Stores player details
Game Engine
{
"player_id": 1,
"llm_name": "meta-llama/Meta-Llama-3-8B-Instruct",
"game_id": 1,
"name": "Player 1",
"score": 52,
"score_history": {
"1": 3,
"2": 4,
"3": 4,
"4": 7,
"5": 9,
},
"rank_history": {
"1": 1,
"2": 2,
"3": 3,
"4": 2,
"5": 2,
},
}Evaluation
- True Definition Ratio (TDR): The ratio of true definitions generated for the announced word
- LLM Knows Ratio (LKR): The ratio of instances where the LLM aims to generate the true definition
- Deception Ratio (DR): The success ratio of LLMs in deceiving other players
- Correct Guess Ratio (CGR): The LLMs’ ability to identify the reference dictionary definition amidst deceiving ones
- Average Score (AS): The average score achieved by an LLM
Evaluation Metrics
Experiments
&
Results
-
Goal: comparing LLMs (Llama, Phi, Gemma, Mistral)
- To keep the game fair, only models of comparable size are used
-
Setup:
- history: none, mini, full
- word decks: basic frequent English words, all Balderdash words
-
Results:
- History size affects the results for basic frequent English words.
- Models' performance is unpredictable with all Balderdash words.
- Phi, best lie detector
- Mistral, best liar
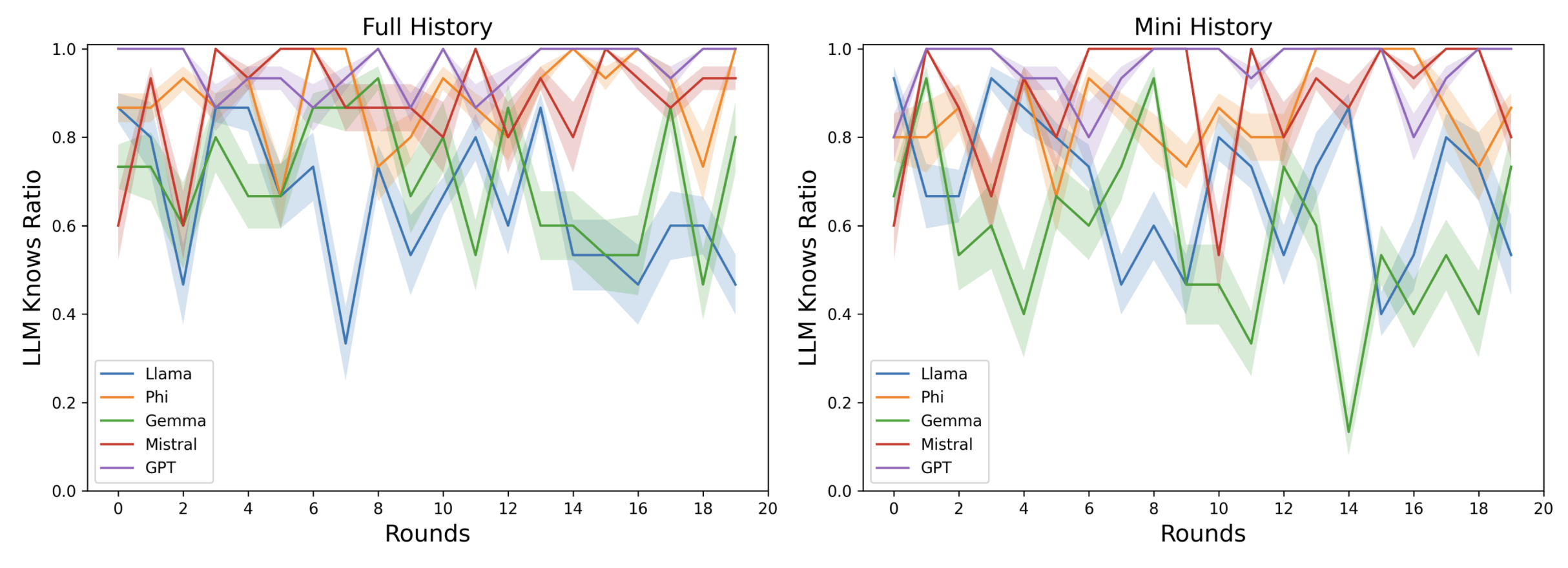
Leaderboard Experiment
- Goal: evaluating LLMs’ reasoning and strategy in an environment where a dominant method for maximizing scores exists based on the history of past rounds
-
Setup:
- History type: "mini", "full"
- Word decks: "known Balderdash words"
-
Hypothesis: LLMs will converge to generate the correct definition
Convergence Experiment
\overline{LKR_n} > 1 - \epsilon, \quad \forall n > T
Convergence Experiment
Game Rules Experiment
- Goal: assessing LLM's ability to understand and reason over the game rules without providing history
- History type: "none"
- Word decks: "known Balderdash words"
-
Game Rules:
- 50 points for generating the correct definition.
- 0 points for generating the correct definition.
Game Rules Experiment
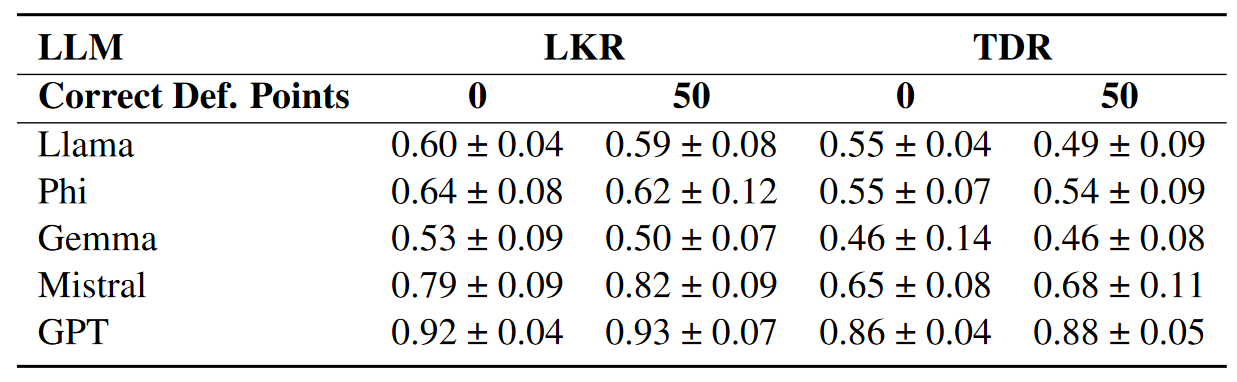
Conclusion
- Initial Assumptions vs. Findings:
- Assumption: LLMs are familiar with Balderdash words and can generate correct definitions
- Finding: LLMs are unfamiliar with over half of the Balderdash words and struggle in the voting phase
- LLMs do not show correct reasoning or strategy convergence
- More pronounced failures with infrequent words compared to frequent words.
- Model Performance:
- Best Judge: Llama aligns best with human labels
- Correct Definition: Phi excels in identifying correct definitions, indicating potential for disinformation detection
- Deception: Mistral is the most effective in deceiving opponents, showcasing creativity
References
-
[1] Wang, S., Liu, C., Zheng, Z., Qi, S., Chen, S., Yang, Q., … Huang, G. (2023). Avalon’s Game of Thoughts: Battle Against Deception through Recursive Contemplation. arXiv [Cs.AI]. Retrieved from http://arxiv.org/abs/2310.01320
-
[2] Xu, Z., Yu, C., Fang, F., Wang, Y., & Wu, Y. (2024). Language Agents with Reinforcement Learning for Strategic Play in the Werewolf Game. arXiv [Cs.AI]. Retrieved from http://arxiv.org/abs/2310.18940
Thank you!

Parsa Hejabi





Elnaz Rahmati
Alireza S. Ziabari
Morteza Dehghani
Jesse Thomason
Preni Golazizian
Evaluating Creativity and Deception in Large Language Models: A Simulation Framework for Multi-Agent Balderdash
By Parsa Hejabi




