Transformers
淺介
What is Transformer
Origin
- Attention is all you need
Why
- RNN (seq2eq) 句子間有相依性
- 翻譯時 decoder 需要前一個字的輸出
- 對平行不有善
Proposed Solution
- Transformer encoder/decoder
- Self Attention
Transformer Architecture
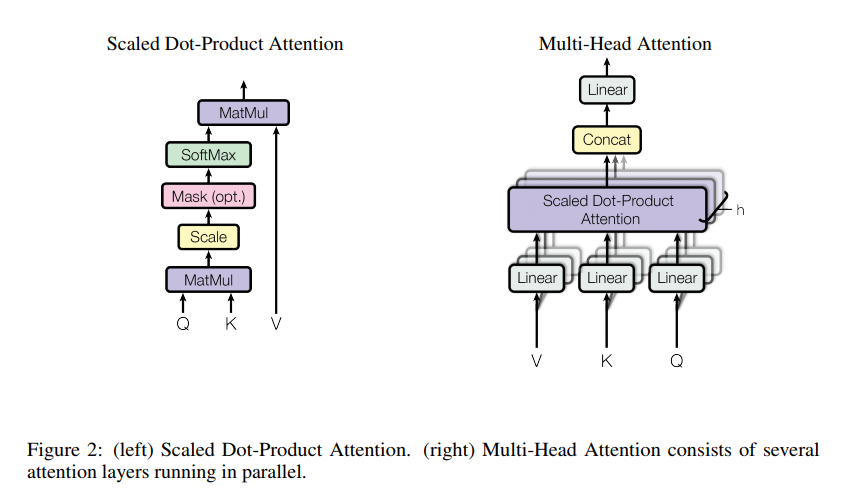
- Self Attention
- Positionwise Feed Forward
- Position encoding
Architecture (Cont.)
Attention
x_i \ \forall i \in [1, length] \newline
h_i = f(x_i) \newline
\alpha_{i} = score(y, h_i) \newline
z = \sum_{i}^{length} \alpha_{i} h_i
Simple Self Attention
x_i \ \forall i \in [1, length] \newline
h_i = f(x_i) \newline
\alpha_{ij} = score(h_i, h_j) \newline
y_i = \sum_{j}^{length} \alpha_{ij} h_j
Self Attention
(SA)
x_i \ \forall i \in [1, length] \newline
q_i = f_1(x_i) \newline
k_i = f_2(x_i) \newline
v_i = f_3(x_i) \newline
\alpha_{ij} = score(q_i, k_j) \newline
y_i = \sum_{j}^{length} \alpha_{ij} v_j
Self Attention (Cont.)
Positionwise Feed Forward
(PWFFN)
x_i \ \forall i \in [1, length] \newline
y_i = f(x_i) \newline
where \ f \ is \ a \ \text{two layer MLP}
Position Encoding
- SA & PWFFN 並沒有順序(位置)的概念
- 透過而外得向量提供位置資訊
- 可用 trained weight 也可用定值
Transformer en/decoder
- 透過 transformer (TRF) 取代 seq2seq 中的 RNN 架構
- TRF encoder 將 source sentence 轉成 sequence of latent variable (memory)
- TRF decode 透過 target sentence 存取 memory
Transformer en/decoder (Cont.)
Benefit
- 每一層的第 i 個輸出 h_i 不需要等 h_{i-1} 算完,直接透過 X 的 attention 決定,可以平行加速
Variant
Non-sequence data
- Source: Image Transformer
- 使用 TRF 在 image 上,取代 PixelCNN
Decoder-only TRF
- Source: GENERATING WIKIPEDIA BY SUMMARIZING LONG SEQUENCES
- TRF en/decoder 之間也是透過 attention 交換資訊,不需要分 encoder 或 decoder
- Also known as: TRF encoder
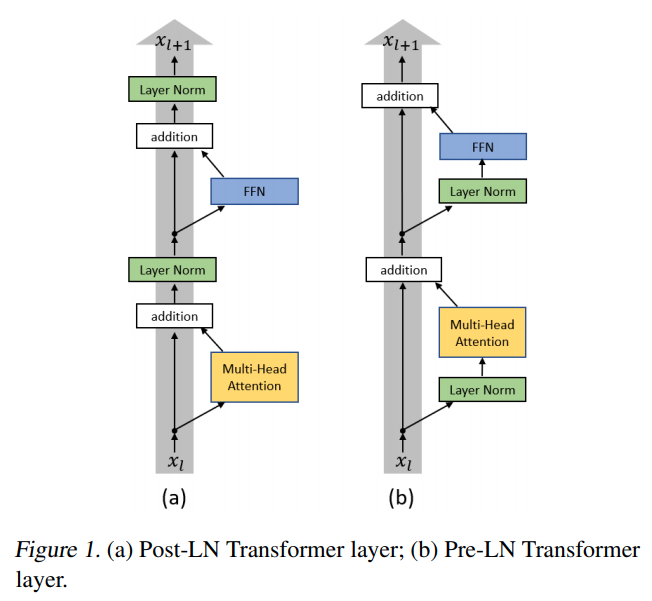
Pre-LN TRF
- Source: On Layer Normalization in the Transformer Architecture
- 將原本在 SA 以及 PWFFN 之後的 LN 移到 layer 之前
- 據證是會讓 TRF 內部的 gradient 更穩定,幫助收斂
Pre-LN TRF
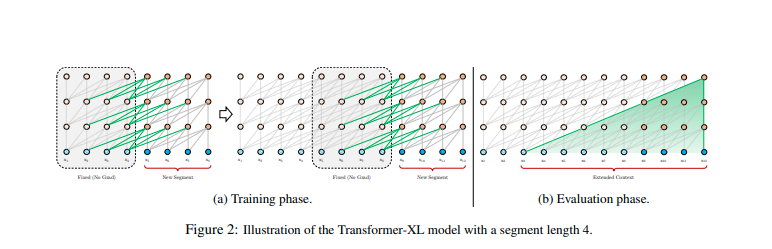
TRF-XL
- Source: Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- 為解決 TRF 長度問題
- 在 TRF 外再包一層 recurrent
- 使用 related position encoding
TRF-XL (Cont.)
More variant
- Attention scheme
- position embedding design
- ...
Pretrain TRF
Origin
- Improving Language Understanding by Generative Pre-Training (GPT1)
- 第一篇使用 pretrain TRF 的論文
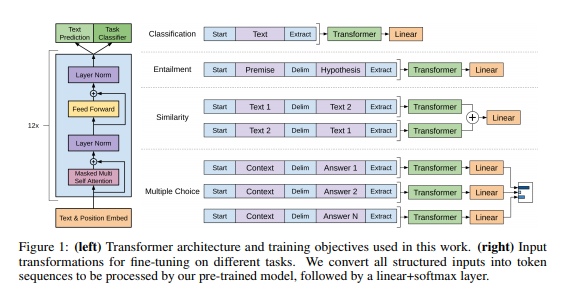
GPT1
- Pre-train Language Modeling
- autoregressive model
GPT1 (Cont.)
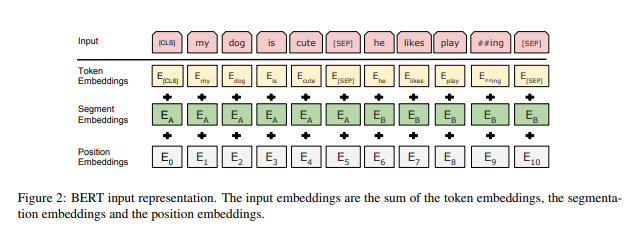
Bert
- Source: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 為解決 GPT1 只有單向輸入的問題,將 Language Modeling 換成 Masked Language Modeling (MLM)
- 提出 next sentence prediction task
Bert (Cont.)
GPT2
- Source: Language Models are Unsupervised Multitask Learners
- 將 GPT1 從 Post-LN TRF 換成 Pre-LN TRF 並使用更多資料以及更大的模型
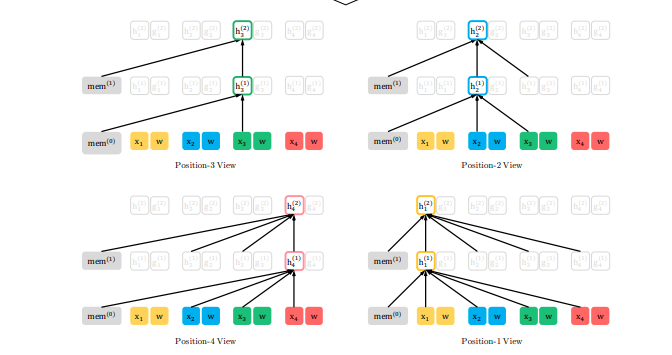
XLNet
- Source: XLNet: Generalized Autoregressive Pretraining for Language Understanding
- 以 TRF-XL 作為基底
- 為解決 GPT 單向而 Bert 輸入有 mask token 的問題
- 同使用 MLM 但輸入只使用 subsequence
XLNet
ALBert
- Source: ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
- 解決 Bert 模型過大問題,大量的 share weight
- 提出 Sentence ordering prediction task,預測兩句先後順序
More pretrain arch.
- Source: PALM: Pre-training an Autoencoding&Autoregressive Language Model for Context-conditioned Generation
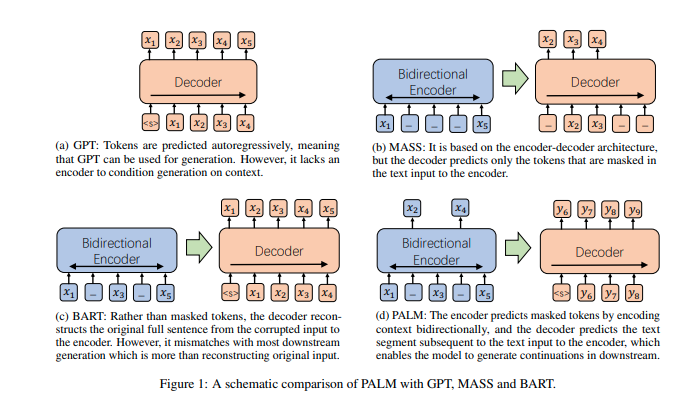
Q&A
TRF
By Peter Cheng




