Flux.jl
Relax! Flux is the ML library that doesn't make you tensor http://fluxml.ai/
About Me
- Student

Why Julia?
Better performance
- JIT compiler
- faster pre- & post- processing
Better syntax
- multiple dispatch
- metaprogramming
Write elegant code with high performance
WARNING
Situation of v0.7
Julia v0.7 in rc- packages need to be update
- mess in document
Julia v1.0 Just Release!!
Other Frameworks
Dynamic
- Pytorch
- Tensorflow-eager
- Mxnet
Static
- Theano
- Tensorflow
- Caffe
- Mxnet
Static v.s. Dynamic
Automatic Differentiation
(AD)
Static
create computation graph beforehand
need to be specific, e.g. shape, graph ...
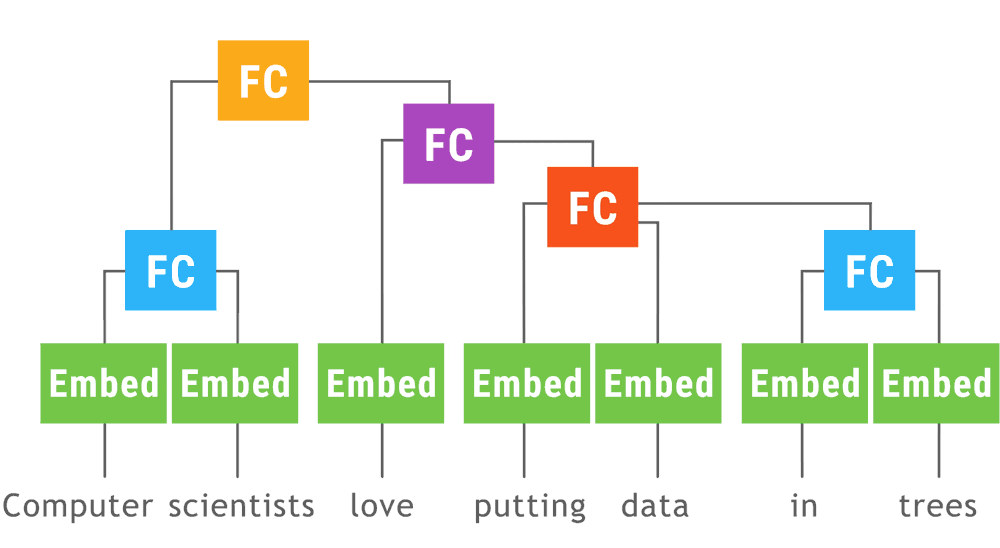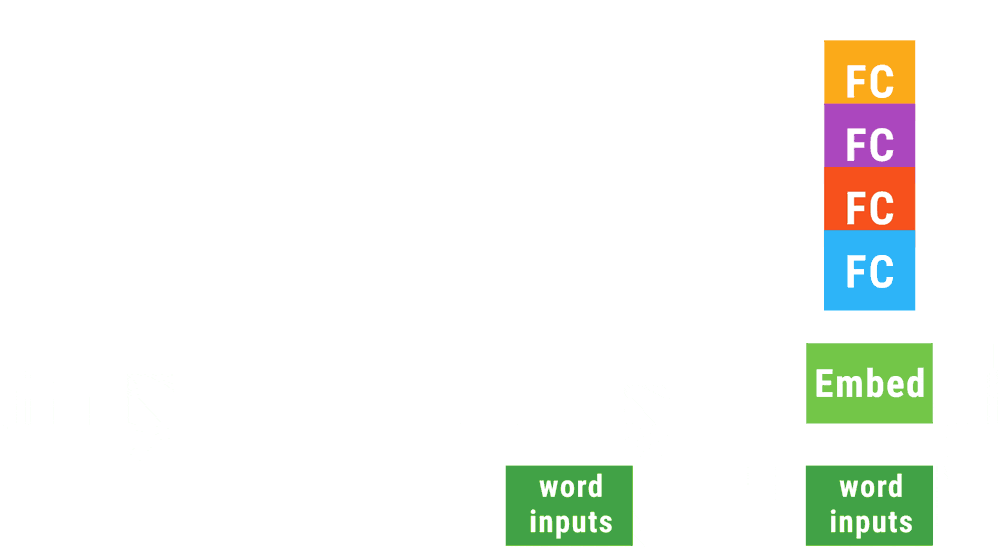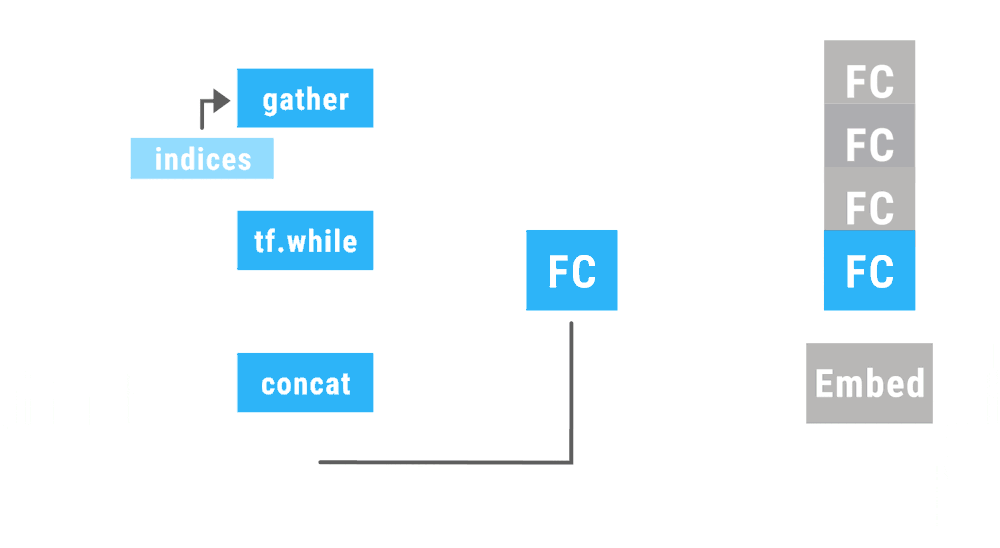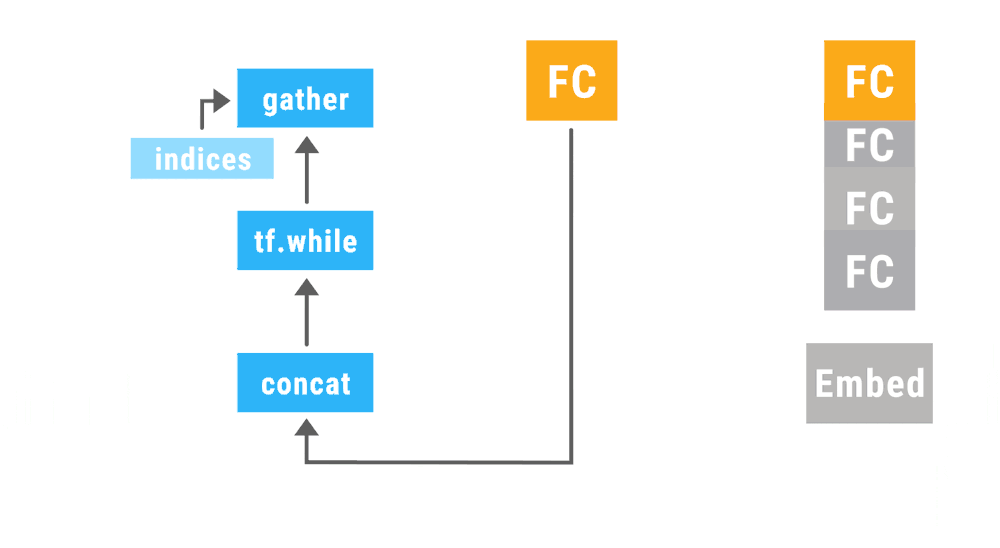
Dynamic
create computation as the data pass forward
everything could be dynamic
Dynamic
Why use Flux?
Advantages
- highly customizable
- make use of julialang's advantages
- dynamic model
- write model at ease
- FUN!
Take a look!
Flux in one block
using Flux
using Flux: throttle, @epochs
x = rand(784)
y = rand(10)
data = Iterators.repeated((x, y), 3)
m = Chain(
Dense(784, 32, σ),
Dense(32, 10), softmax)
loss(x, y) = Flux.mse(m(x), y)
opt = ADAM(params(m))
evalcb = () -> @show(loss(x, y))
@epochs 3 Flux.train!(loss, data, opt, cb = throttle(evalcb, 10))Flux in one block(dynamic)
using Flux
tree() = rand() < 0.5 ? rand(10) : (tree(), tree())
shrink = Dense(20, 10)
combine(a, b) = shrink([a; b])
model(x) = x
model(x::Tuple) = combine(model(x[1]), model(x[2]))
model(tree()) # Sample output
Flux on browser
From basic
(the internal)
Flux.Tracker
- The core module for computing AD
- reverse-mode AD
take derivative
using Flux.Tracker
Tracker.gradient((a, b) -> a*b, 2, 3) # (3.0 (tracked), 2.0 (tracked))
#= equivalent =#
using Flux.Tracker: forward
y, back = forward((a, b) -> a*b, 2, 3) # (6.0 (tracked), Flux.Tracker.#9)
back(1) # (3.0 (tracked), 2.0 (tracked))
take 2-order derivative
using Flux.Tracker
f(x) = 3x^2 + 2x + 1
# df/dx = 6x + 2
f′(x) = Tracker.gradient(f, x)[1]
f′(2) # 14.0 (tracked)
# d²f/dx² = 6
f′′(x) = Tracker.gradient(f′, x)[1]
f′′(2) # 6.0 (tracked)take derivative
(in place)
using Flux.Tracker: forward
y, back = forward((a, b) -> a*b, 2, 3) # (6.0 (tracked), Flux.Tracker.#9)
back(1) # (3.0 (tracked), 2.0 (tracked))
a, b = param(2), param(3)
c = a*b # 6.0 (tracked)
Tracker.back!(c)
Tracker.grad(a), Tracker.grad(b) # (3.0, 2.0)take derivative of matrix
W = param([1 2; 3 4])
x = param([5, 6])
y = W*x
#Tracked 2-element Array{Float64,1}:
# 17.0
# 39.0
c = sum(y)
Tracker.back!(c)
Tracker.grad(W), Tracker.grad(x) # ([5.0 6.0; 5.0 6.0], [4.0, 6.0])Customize gradient
using Flux
using Flux: data
using Flux.Tracker
using Flux.Tracker: TrackedReal, track, @grad, TrackedMatrix
foo(a, b) = a * b .+ 10
foo(a::TrackedMatrix, b::TrackedMatrix) = Tracker.track(foo, a, b)
@grad function foo(a, b)
f = foo(data(a),data(b))
x = similar(data(a))
y = similar(data(b))
for i ∈ 1:length(x)
x[i] = i
end
for i ∈ 1:length(y)
y[i] = i^2
end
return f, Δ -> (x, y)
end
Customize gradient
a = param([1 2; 4 5])
b = param([5 6 2; 7 8 1])
c = foo(a, b)
Flux.Tracker.back!(sum(c))
Tracker.grad(a)
#2×2 Array{Float64,2}:
# 1.0 3.0
# 2.0 4.0
Tracker.grad(b)
#2×3 Array{Float64,2}:
# 1.0 9.0 25.0
# 4.0 16.0 36.0let's build a model!
Outline
- prepare data
- model construction
- loss function & optimizer
- training!
Prepare Data
- batch should be at second Dimension
- utils.jl
- Flux.Data
- FluxML/model-zoo
data example
using Flux
using Flux: chunk, batch
xs = collect(Iterators.repeated(rand(10), 1000))
ck = chunk(xs, 50)
data = batch.(ck)Build a Model
- 1. `Chain` multiple Layers
- 2. write a custom function/layer
model example(1)
using Flux
using Flux: @treelike, glorot_uniform
struct Nalu{S}
W::S
M::S
G::S
end
function Nalu(in::Integer, out::Integer;
initW = glorot_uniform)
return Nalu(param(initW(out, in)), param(initW(out, in)),param(initW(out, in)))
end
@treelike Nalu
function (n::Nalu)(x)
W = @. tanh(n.W) * σ(n.M)
a = W * x
g = σ.(n.G * x)
m = ℯ .^ (W * log.(abs.(x) + 1e-7))
y = @. g * a + (1 - g) * m
return y
end
model example(2)
N = 300
embedding = param(randn(N, length(alphabet)))
W = Dense(2N, N, tanh)
combine(a, b) = W([a; b])
sentiment = Chain(Dense(N, 5), softmax)
function forward(tree)
if isleaf(tree)
token, sent = tree.value
phrase = embedding * token
phrase, crossentropy(sentiment(phrase), sent)
else
_, sent = tree.value
c1, l1 = forward(tree[1])
c2, l2 = forward(tree[2])
phrase = combine(c1, c2)
phrase, l1 + l2 + crossentropy(sentiment(phrase), sent)
end
end
loss(tree) = forward(tree)[2]Optimizer
- Pass all params to Optimizers
- `params()` collect all param in layers
Training!
function train!(loss, data, opt; cb = () -> ())
cb = runall(cb)
opt = runall(opt)
@progress for d in data
l = loss(d...)
@interrupts back!(l)
opt()
cb() == :stop && break
end
endSave model
saveing&loading
julia> using Flux
julia> using BSON: @save
julia> using BSON: @load
#save
julia> model = Chain(Dense(10,5,relu),Dense(5,2),softmax)
Chain(Dense(10, 5, NNlib.relu), Dense(5, 2), NNlib.softmax)
julia> @save "mymodel.bson" model
#load
julia> @load "mymodel.bson" model
julia> model
Chain(Dense(10, 5, NNlib.relu), Dense(5, 2), NNlib.softmax)ONNX support!
loading ONNX model
# Import the required packages.
julia> using Flux, ONNX
# If you are in some other directory, specify the entire path.
# This creates two files: model.jl and weights.bson.
julia> ONNX.load_model("model.onnx")
# Read the weights from the binary serialized file.
julia> weights = ONNX.load_weights("weights.bson")
# Loads the model from the model.jl file.
julia> model = include("model.jl")
Conclusion
Flux!
- writing elegant code on top of Julia
- dynamic model make you feel at ease
- easy&highly customizable
Q & A
Intro to Flux.jl
By Peter Cheng
Intro to Flux.jl
Relax! Flux is the ML library that doesn't make you tensor




