









Philo van Kemenade
Creating tools, stories and things in between to amplify human connection with arts and culture.
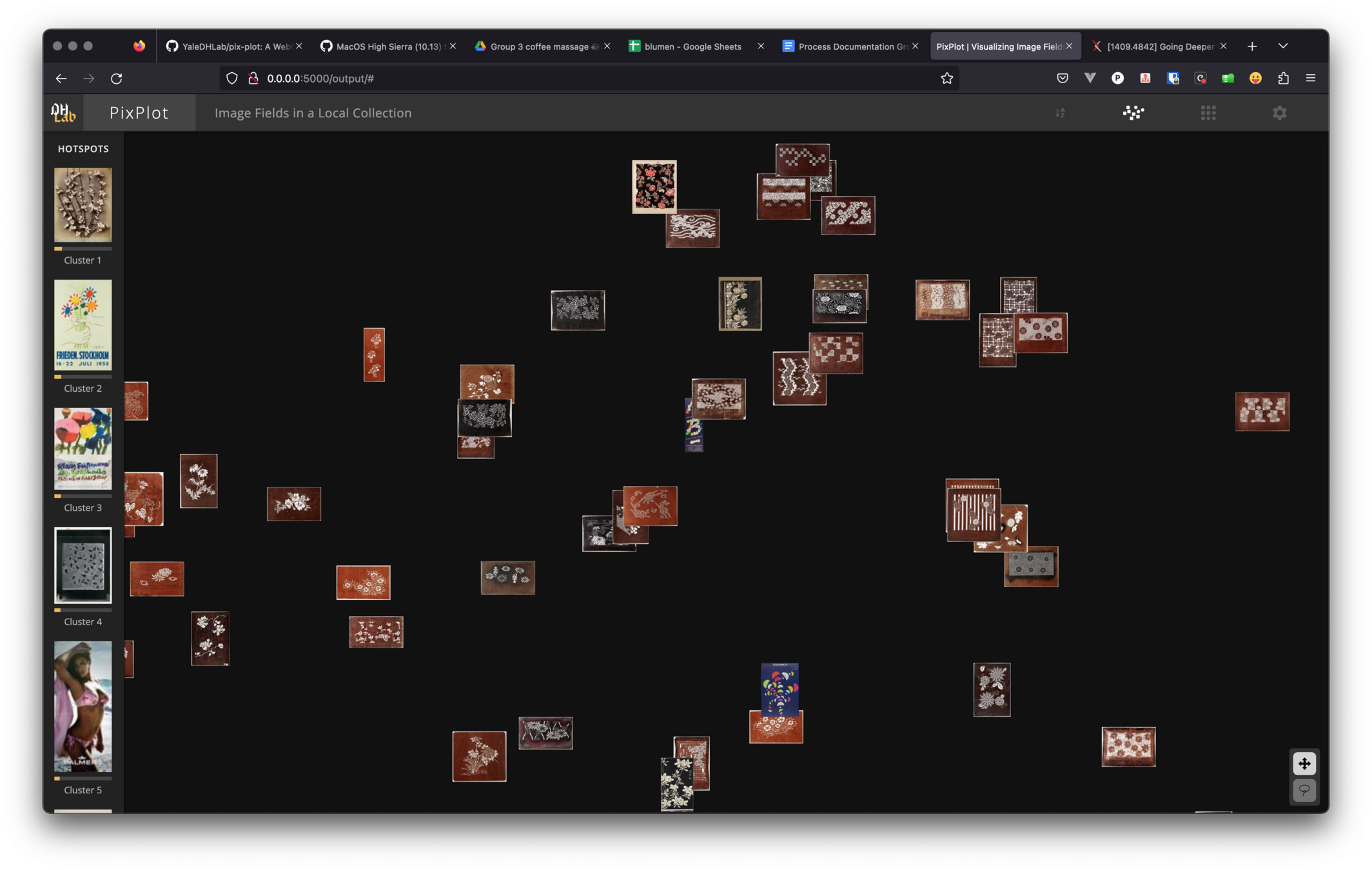
non-deterministic data exploration
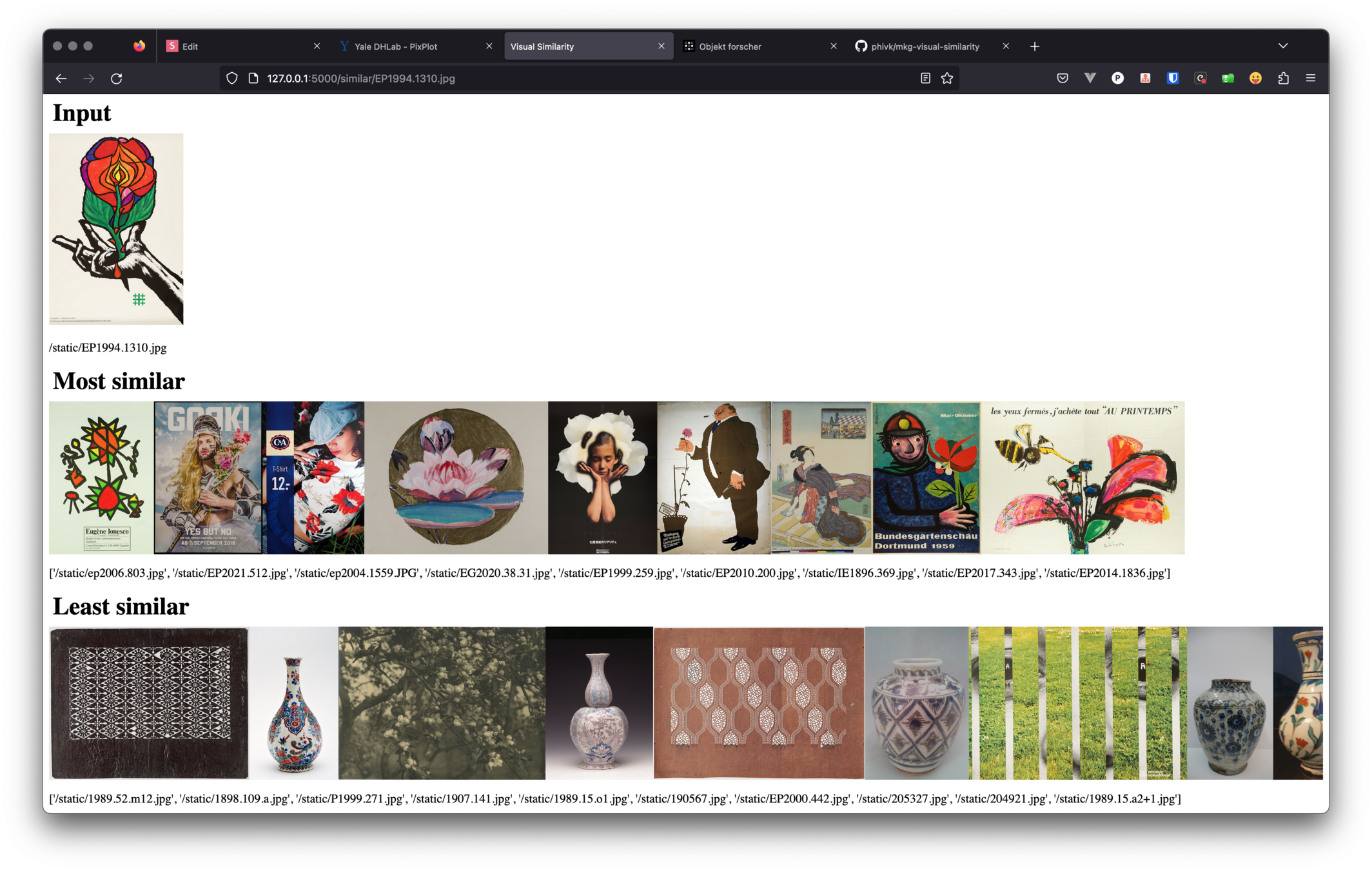
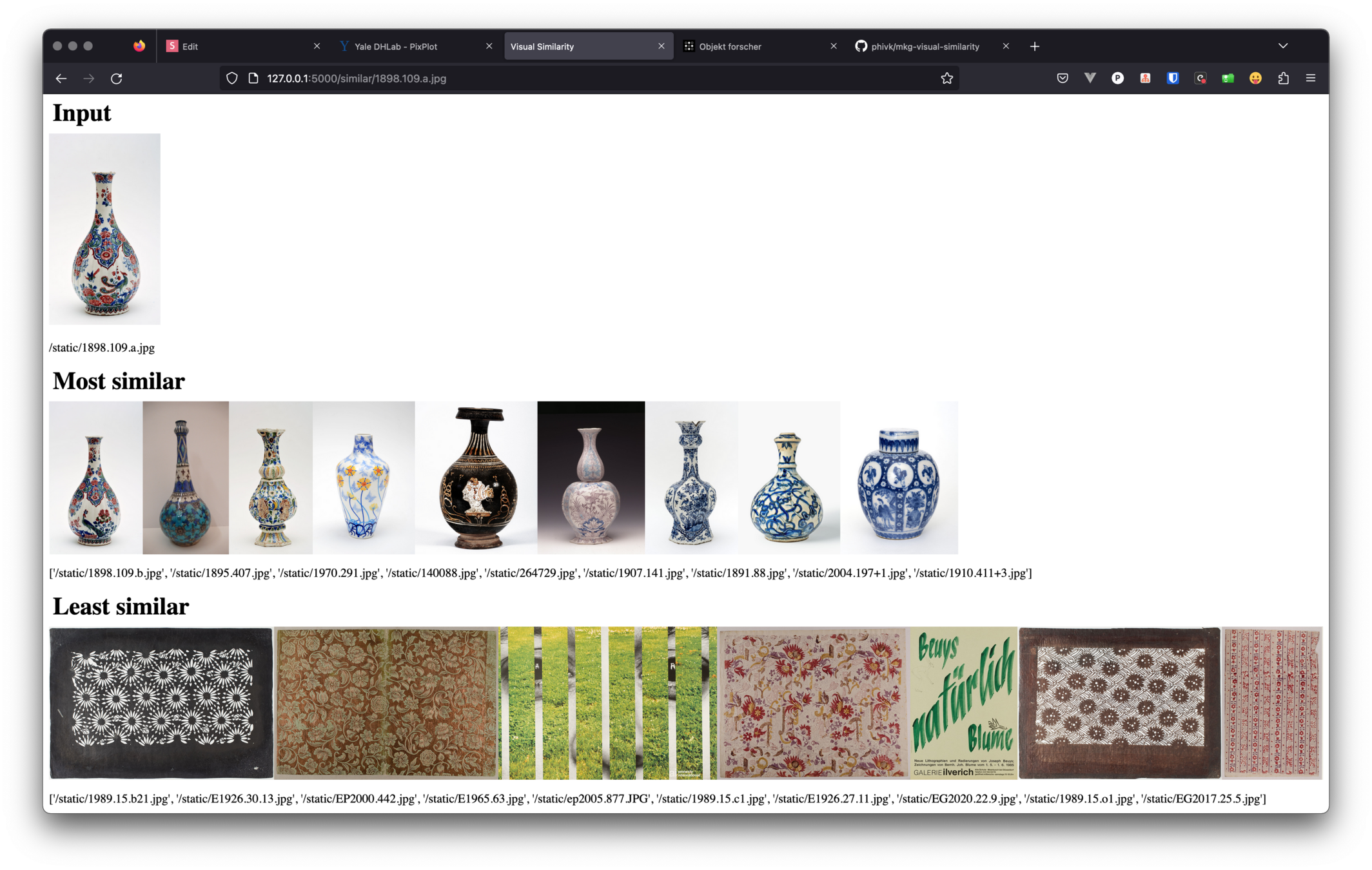
visual search
unflattening metadata
find object by feeling
generous
interfaces / queries
where to start?
personalised collections
multimodal
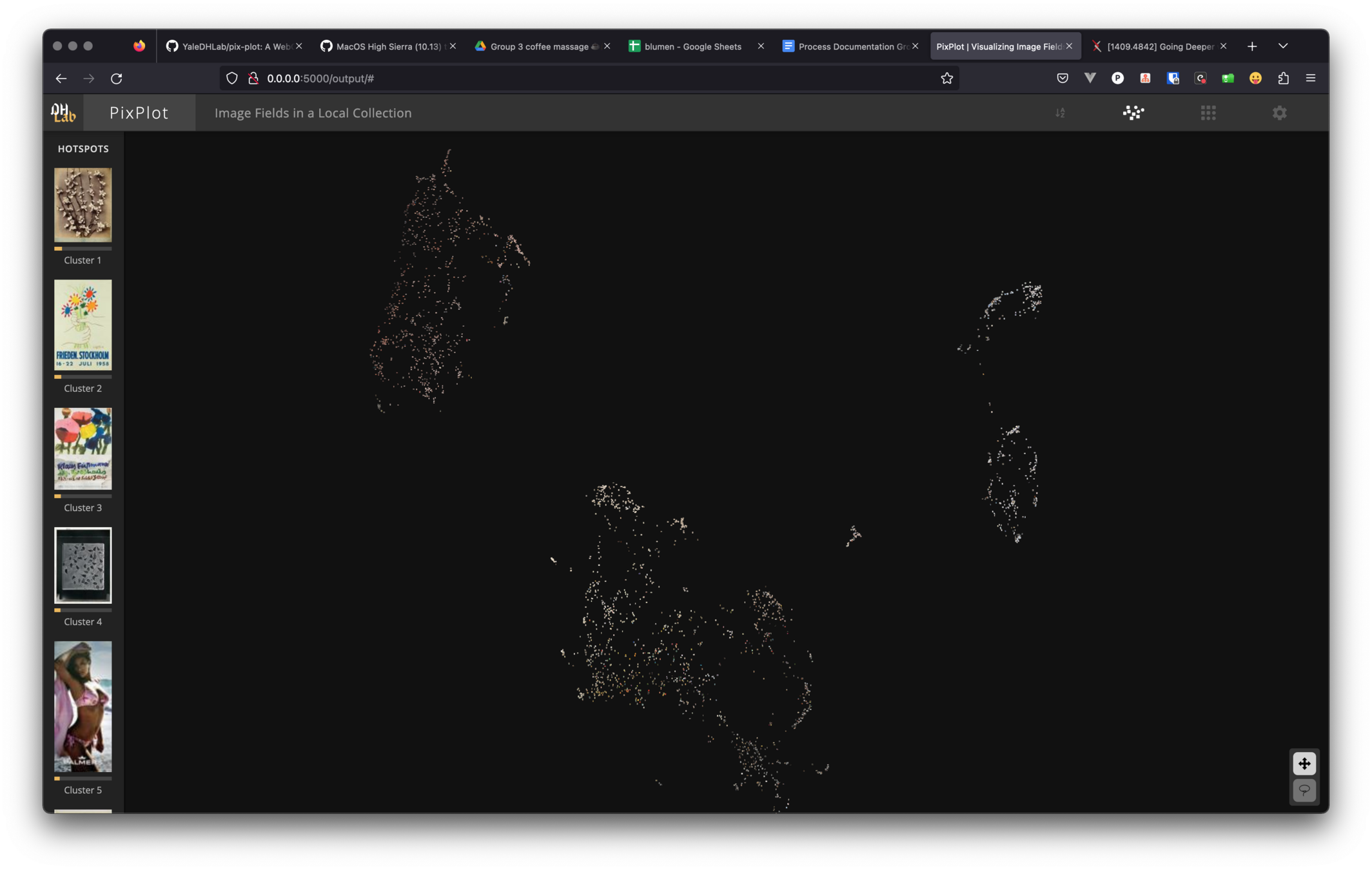
similarity
clustering interests
spring
views
looking for photographs
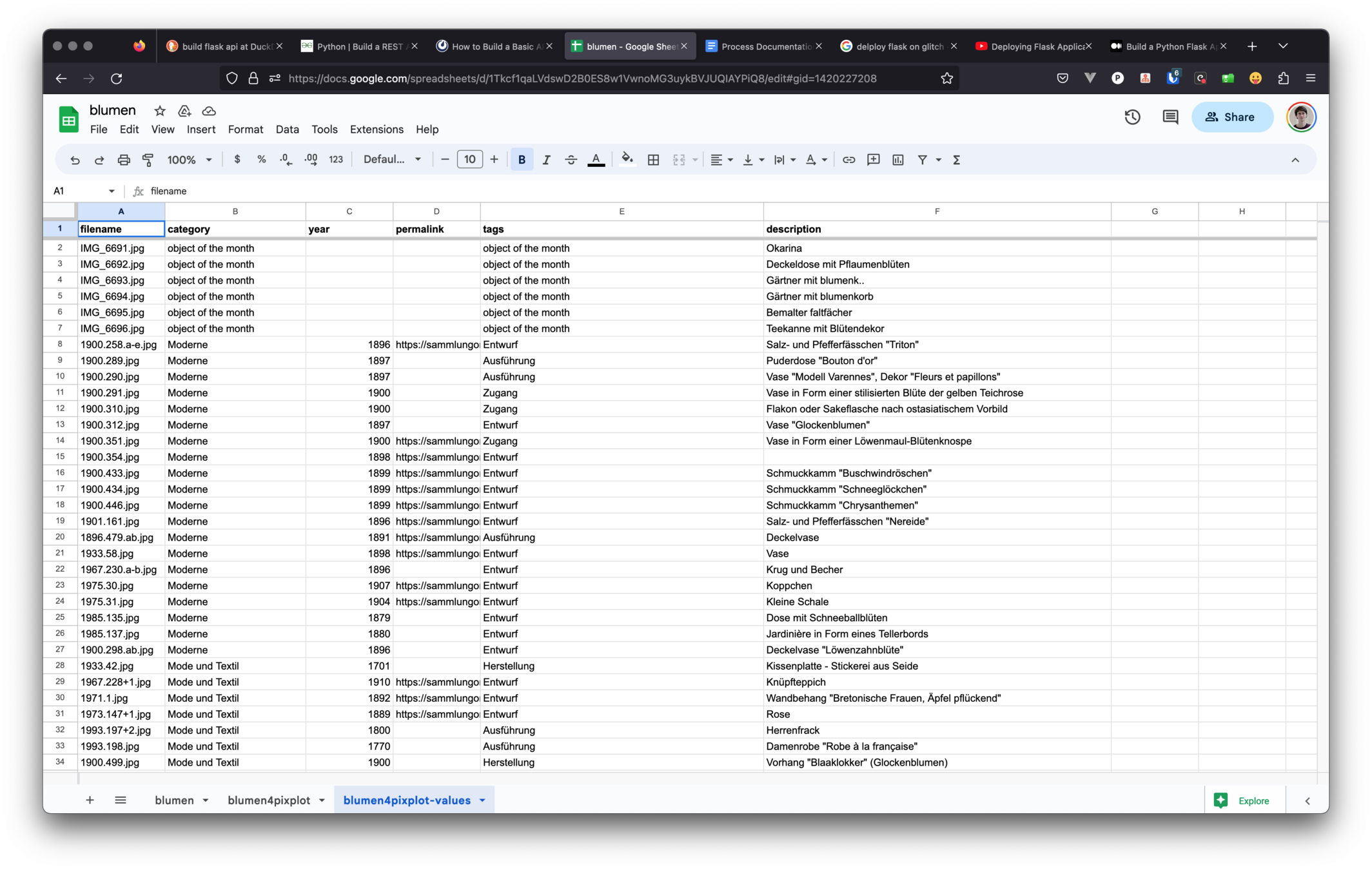
3210 records
filered for iconography containing "blumen"
blumen.csv
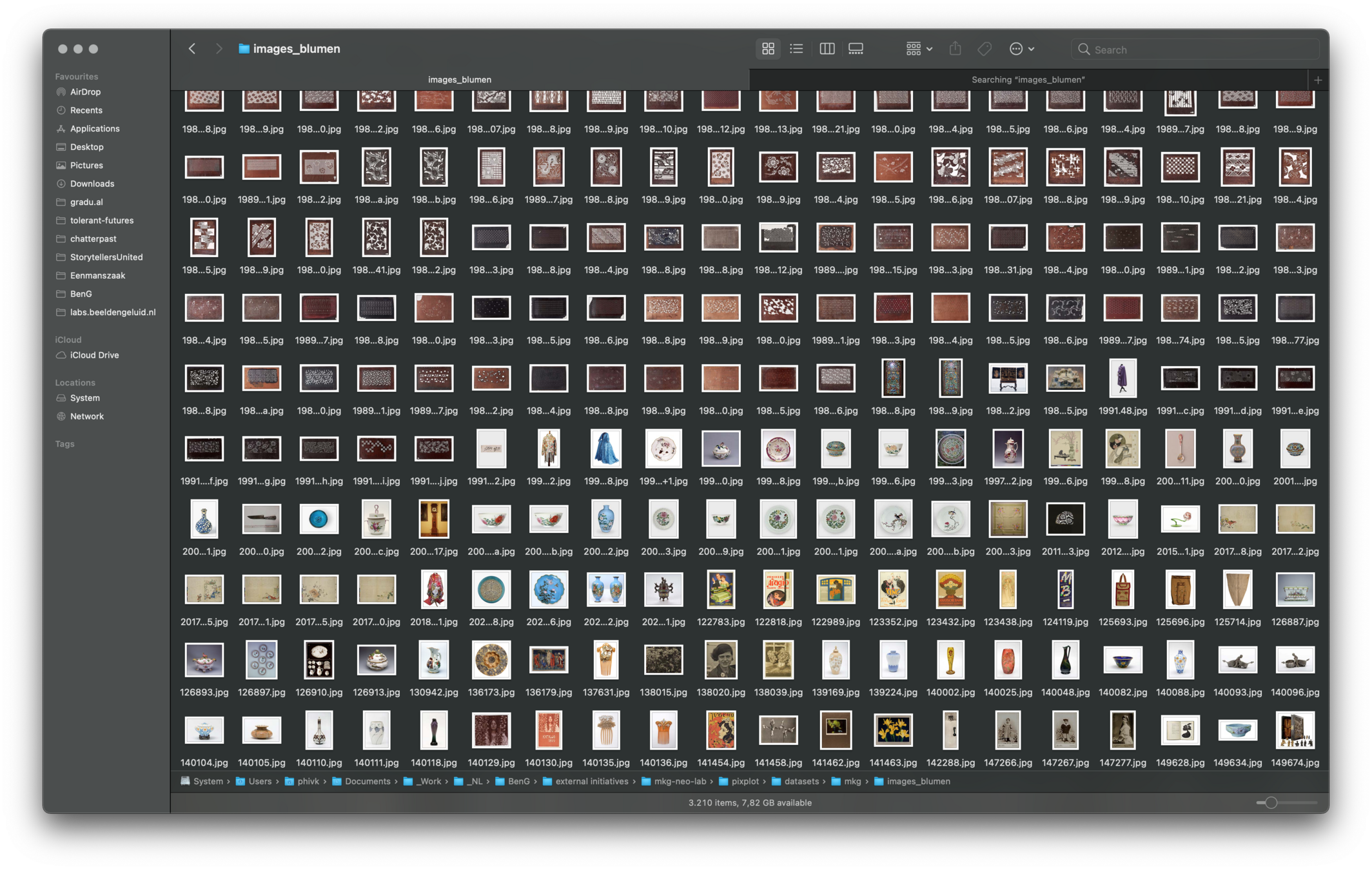
images_blumen/
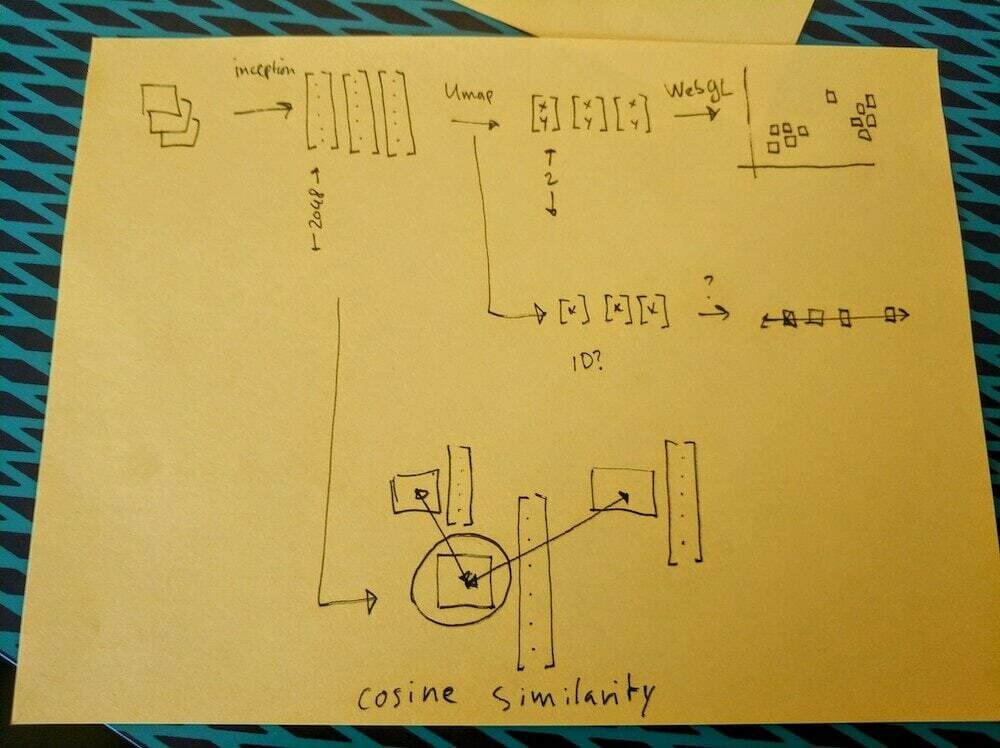
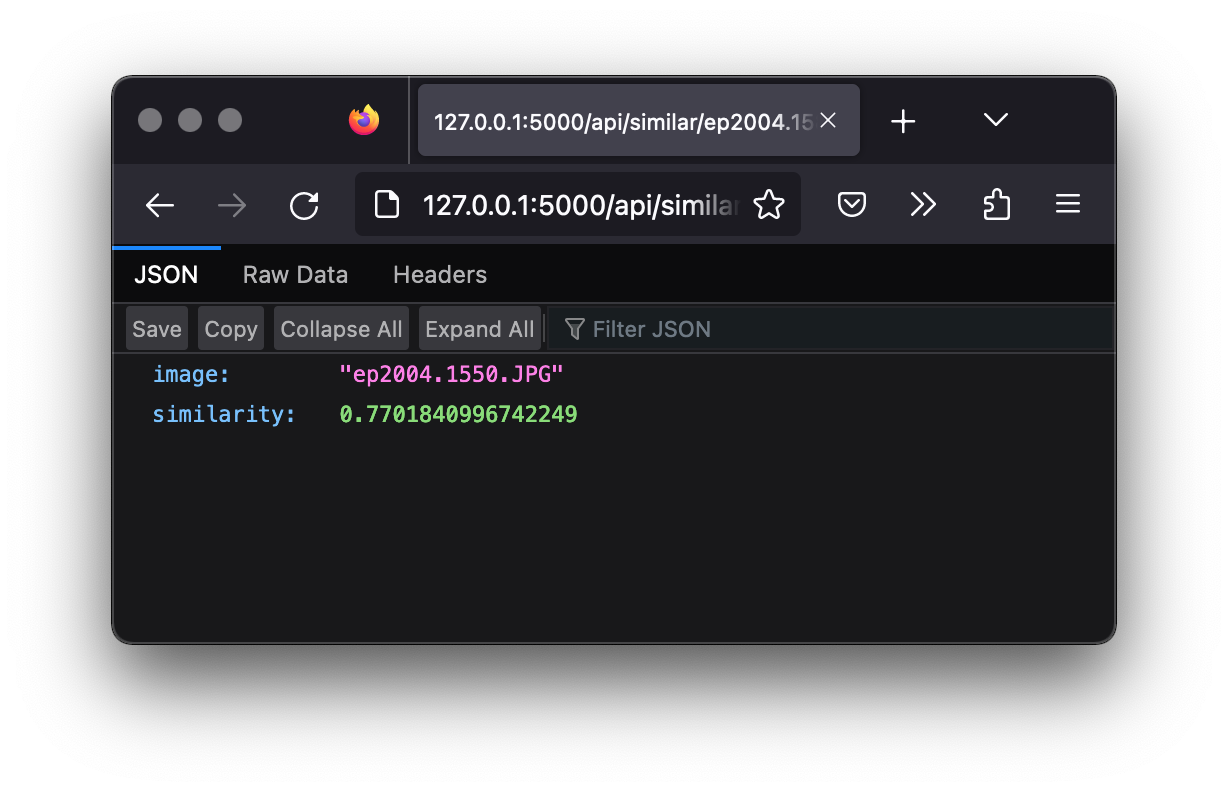
proof of concept (flask)
Application Programming Interface (API)
def cosine_similarity(vecA, vecB):
return np.dot(vecA,vecB)/(norm(vecA)*norm(vecB))(private) repo on GitHub
Choose Your Own Object
functional prototype for visitors
start with a curated object,
walk through the collection
along 2 axes (visual & metadata)
tested in gallery, positive responses
exploration benefits from an queryable API 🤖
image embeddings can support intuitive ways
of search, exploration and recommendation 👍
metadata and content (e.g. image) features can be combined into meaningful UX 🤗
working with image embeddings is easier than I thought 😌
Data Sprinting is an interesting format
for insight gathering and rapid prototyping
By Philo van Kemenade
I participated in the Neo Lab Data Exploration Sprint hosted by the Museum fur Kunst & Gewerbe in Hamburg. In an intense weeklong sprint, we analysed their (partially openly licensed) collection data and explored different ways of scrutinising, visualising, and accessing records in their collections. Specifically, I looked at visual similarities for exploration, search and recommendation. https://www.mkg-hamburg.de/en/neo-lab#toc-open-call-data-exploration-sprint




