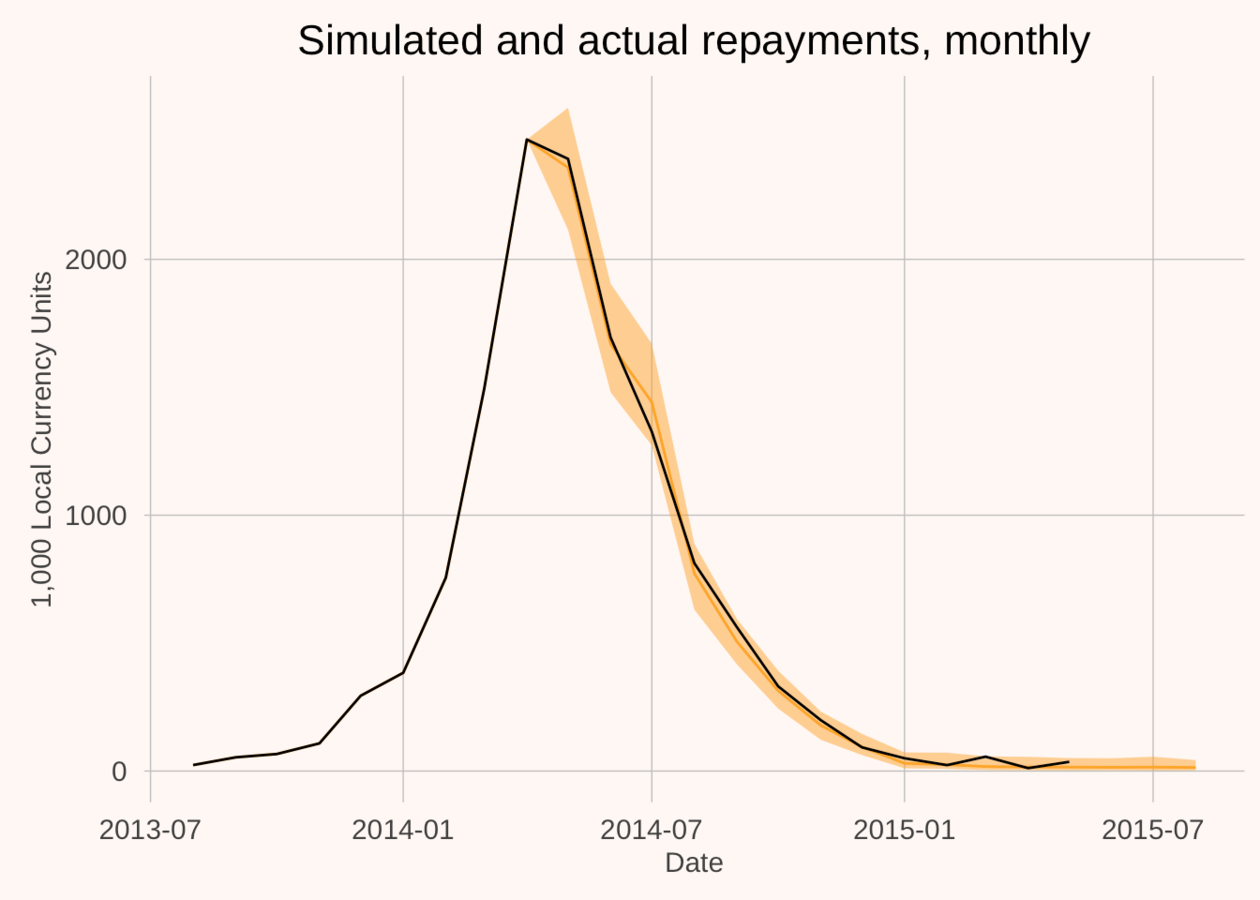
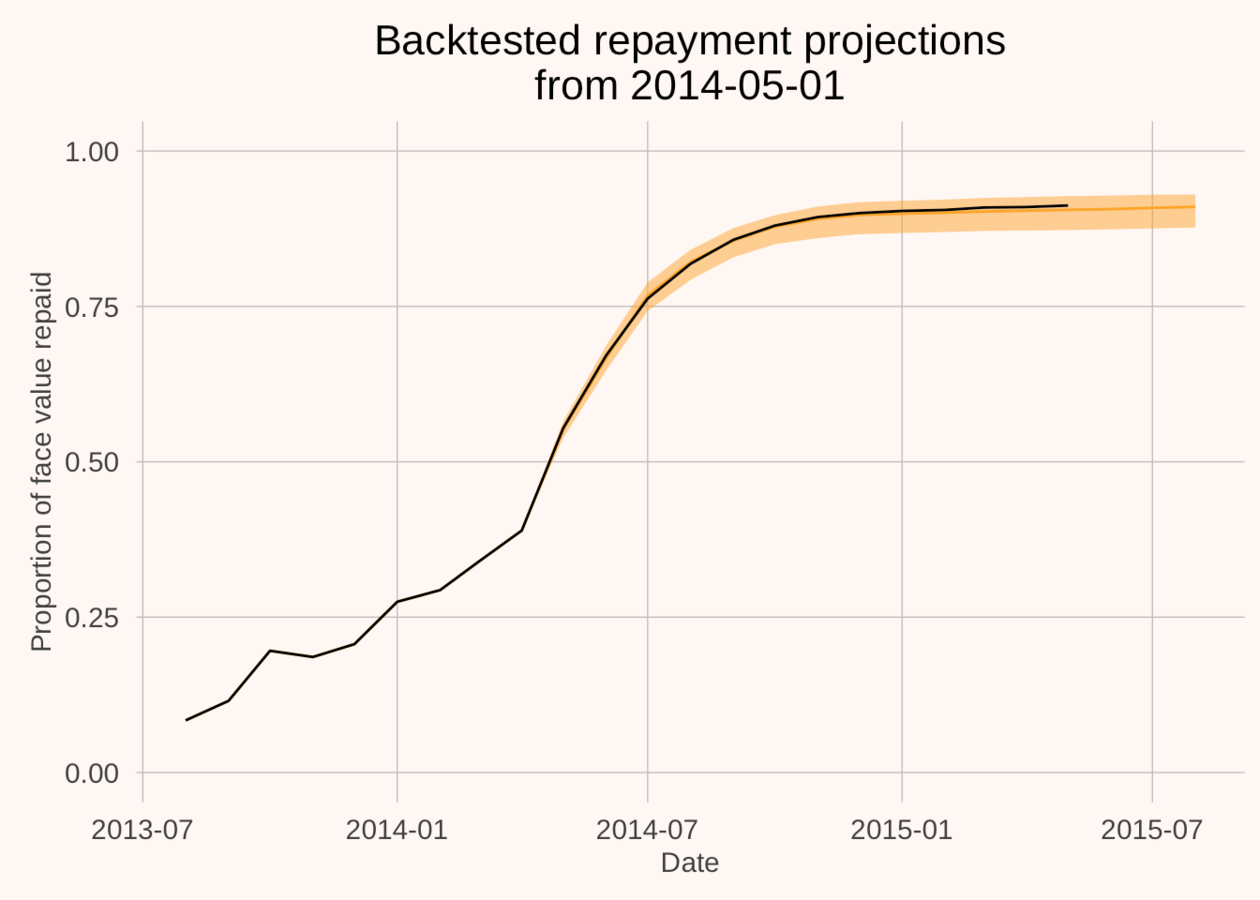
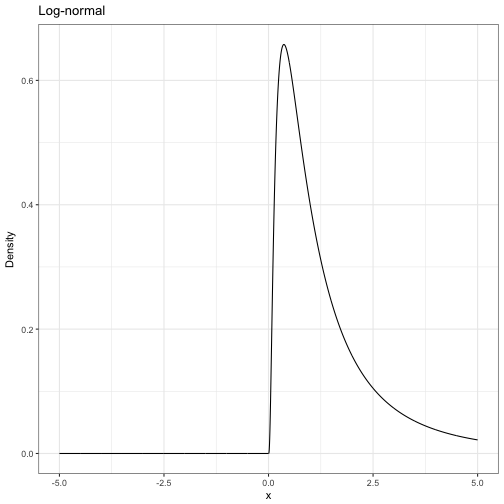
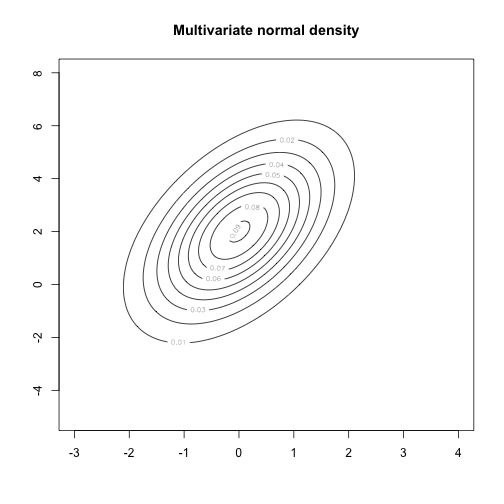
This factors into conditional densities
\[
p(\mbox{Heights}, \mbox{average}_{m}, \mbox{average}_{f},\sigma, \mbox{distribution of sexes})
\]
\[
= p(\mbox{Heights}|\, \mbox{average}_{m}, \mbox{average}_{f},\sigma, \mbox{distribution of sexes})\times
\]
\[
p(\mbox{average}_{m}|\, \mbox{average}_{f}, \sigma,\mbox{distribution of sexes})\times
\]
\[
p(\mbox{average}_{f}|\, \sigma,\mbox{distribution of sexes})\times
\]
\[
p(\sigma|\,\mbox{distribution of sexes})\times
\]
\[
p(\mbox{distribution of sexes})
\]
And if these are independent
\[
= p(\mbox{Hghts}|\mbox{params})\times p(\mbox{av}_{m})\times p(\mbox{av}_{f})\times p(\sigma)\times p(\mbox{sex distr.})
\]