










































 ️
️


















Roberto Calandra PRO
Full Professor at TU Dresden. Head of the LASR Lab. Working in AI, Robotics and Touch Sensing.
Roberto Calandra
Caltech - CS 159 - 25 May 2021
Facebook AI Research
How to scale to more complex, unstructured domains?
Robotics
Finance
Biological Sciences
Logistics /
Decision Making
Disaster Relief
Industrial Automation
Exploration
Medicine & Eldercare
From YouTube: https://www.youtube.com/watch?v=g0TaYhjpOfo
Multi-modal Sensing
Optimized Hardware Design
Quick adaptation to new tasks
Touch Sensing
Morphological adaptation
In this talk
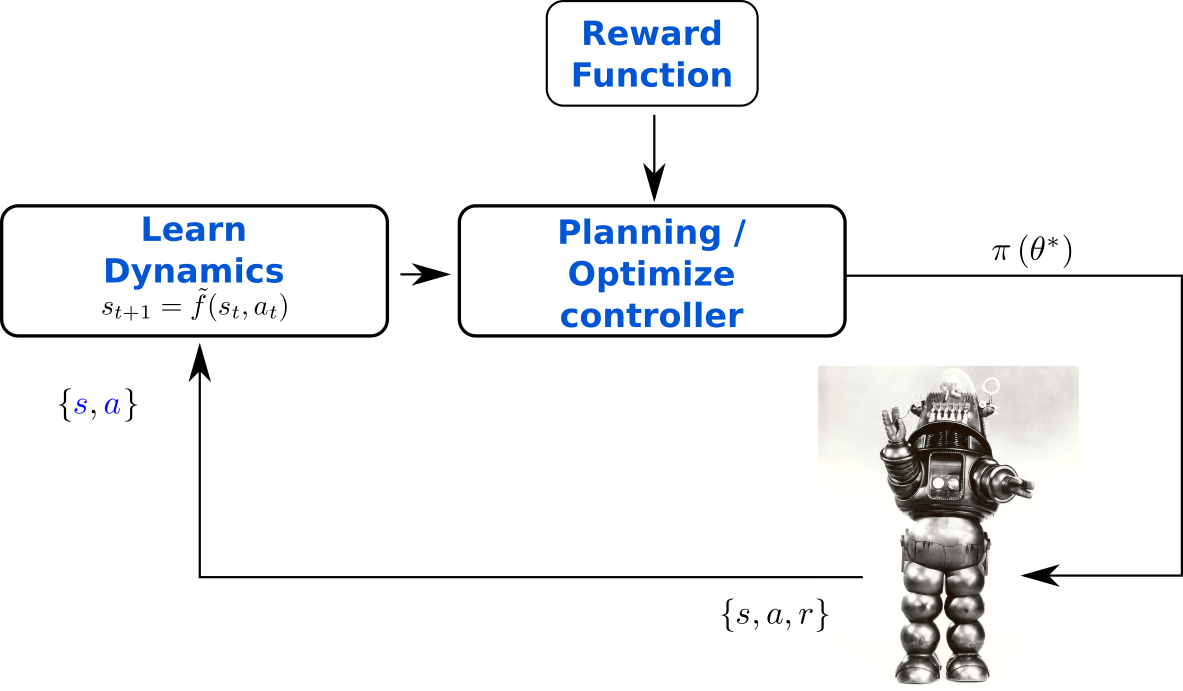
Model-based
Reinforcement Learning
Hardware
Software
Humans seem to make extensive use of predictive models for planning and control *
(e.g., to predict the effects of our actions)
Can artificial agents learn and use predictive models of the world?
Hyphothesis: better predictive capabilities will lead to more efficient adaptation
* [Kawato, M. Internal models for motor control and trajectory planning Current Opinion in Neurobiology , 1999, 9, 718 - 727],
[Gläscher, J.; Daw, N.; Dayan, P. & O'Doherty, J. P. States versus rewards: dissociable neural prediction error signals underlying model-based and model-free reinforcement
learning Neuron, Elsevier, 2010, 66, 585-595]
+
predictive models enable explainability
(by peeking into the beliefs of our models and understand their decisions)
Local convergence guaranteed*
Simple to implement
Computationally light
Does not generalize
Data-inefficient
No convergence guarantees
Challenging to learn model
Computationally intensive
Data-efficient
Generalize to new tasks
Evidence from neuroscience that humans use both approaches! [Daw et al. 2010]
Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765
1000x
Faster than
Model-free RL
Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765
Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
Bansal, S.; Calandra, R.; Levine, S. & Tomlin, C. J.
MBMF: Model-Based Priors for Model-Free Reinforcement Learning
Withdrawn from Conference on Robot Learning (CORL), 2017
There exist models that are wrong, but nearly optimal when used for control
(NO)
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
- George E.P. Box
- Roberto Calandra
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Learning for DynamIcs & Control (L4DC), 2020
Objective mismatch arises when one objective is optimized in the hope that a second, often uncorrelated, metric will also be optimized.
Negative Log-Likelihood
Task Reward
Deterministic model
Probabilistic model
Historical assumption ported from System Identification
Assumption: Optimizing the likelihood will optimize the reward
Experimental results show that the likelihood of the trained models are not strongly correlated with task performance
How can we give more importance to data that are important for the specific task at hand?
Our attempt: re-weight data w.r.t. distance from optimal trajectory
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
(NO)
(NO)
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Learning for Dynamics and Control (L4DC), 2020, 761-770
Multiplicative Error -- Doomed to accumulate
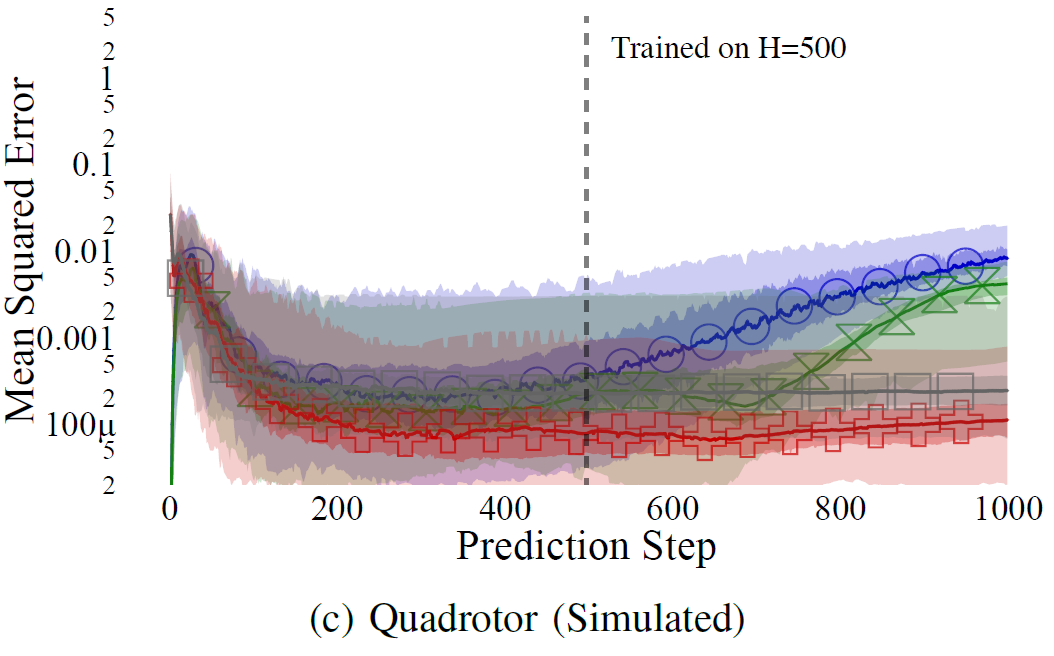
Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
Under review, 2020, [available online: https://arxiv.org/abs/2012.09156]
Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
Under review, 2020, [available online: https://arxiv.org/abs/2012.09156]
(from O(t) to O(1) for any given t)
Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
Under review, 2020, [available online: https://arxiv.org/abs/2012.09156]
(YES)
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
(NO)
(NO)
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Learning for Dynamics and Control (L4DC), 2020, 761-770
Zhang, B.; Rajan, R.; Pineda, L.; Lambert, N.; Biedenkapp, A.; Chua, K.; Hutter, F. & Calandra, R.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
International Conference on Artificial Intelligence and Statistics (AISTATS), 2021
Zhang, B.; Rajan, R.; Pineda, L.; Lambert, N.; Biedenkapp, A.; Chua, K.; Hutter, F. & Calandra, R.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
International Conference on Artificial Intelligence and Statistics (AISTATS), 2021
Zhang, B.; Rajan, R.; Pineda, L.; Lambert, N.; Biedenkapp, A.; Chua, K.; Hutter, F. & Calandra, R.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
International Conference on Artificial Intelligence and Statistics (AISTATS), 2021
Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
Under review, 2020, [available online: https://arxiv.org/abs/2012.09156]
(YES)
Zhang, B.; Rajan, R.; Pineda, L.; Lambert, N.; Biedenkapp, A.; Chua, K.; Hutter, F. & Calandra, R.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
International Conference on Artificial Intelligence and Statistics (AISTATS), 2021
(YES)
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
(NO)
(NO)
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Learning for Dynamics and Control (L4DC), 2020, 761-770
Lambert, N.O.; Drew, D.S.; Yaconelli, J; Calandra, R.; Levine, S.; & Pister, K.S.J.
Low Level Control of a Quadrotor with Deep Model-Based Reinforcement Learning
IEEE Robotics and Automation Letters (RA-L), 2019, 4, 4224-4230
Belkhale, S.; Li, R.; Kahn, G.; McAllister, R.; Calandra, R. & Levine, S.
Model-Based Meta-Reinforcement Learning for Flight with Suspended Payloads
IEEE Robotics and Automation Letters (RA-L), 2021, 6, 1471-1478
Lambeta, M.; Chou, P.-W.; Tian, S.; Yang, B.; Maloon, B.; Most, V. R.; Stroud, D.; Santos, R.; Byagowi, A.; Kammerer, G.; Jayaraman, D. & Calandra, R.
DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation
IEEE Robotics and Automation Letters (RA-L), 2020, 5, 3838-3845
Lambeta, M.; Chou, P.-W.; Tian, S.; Yang, B.; Maloon, B.; Most, V. R.; Stroud, D.; Santos, R.; Byagowi, A.; Kammerer, G.; Jayaraman, D. & Calandra, R.
DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation
IEEE Robotics and Automation Letters (RA-L), 2020, 5, 3838-3845
Lambeta, M.; Chou, P.-W.; Tian, S.; Yang, B.; Maloon, B.; Most, V. R.; Stroud, D.; Santos, R.; Byagowi, A.; Kammerer, G.; Jayaraman, D. & Calandra, R.
DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation
IEEE Robotics and Automation Letters (RA-L), 2020, 5, 3838-3845
Pineda, L.; Amos, B.; Zhang, A.; Lambert, N. O. & Calandra, R.
MBRL-Lib: A Modular Library for Model-based Reinforcement Learning
Arxiv, 2021 https://arxiv.org/abs/2104.10159
Model-based RL is a compelling framework for efficiently learn motor skills
Discussed several theoretical and empirical limitations of current approaches
MBRL-Lib is a new open-source library dedicated to MBRL:
https://github.com/facebookresearch/mbrl-lib
If you are interested in MBRL, I would be delighted to collaborate.
PS: This course is amazing! Wish I had this course 10 years ago...
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
Objective Mismatch in Model-based Reinforcement Learning
Under review, Soon on Arxiv, 2019
By Roberto Calandra



