


















russtedrake PRO
Roboticist at MIT and TRI
Robust Control to Foundation Models
Russ Tedrake
November 6, 2023
"Dexterous Manipulation" Team
(founded in 2016)
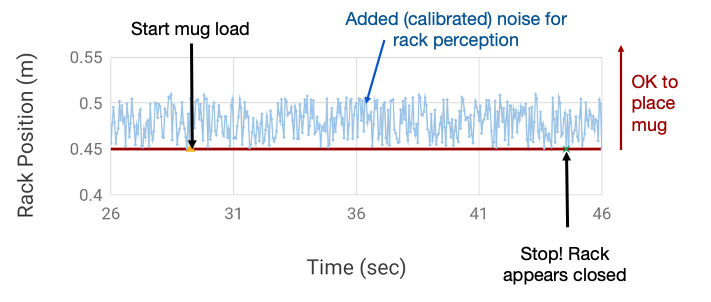
For the next challenge:
For the next challenge:
We've been exploring, and found something good in...
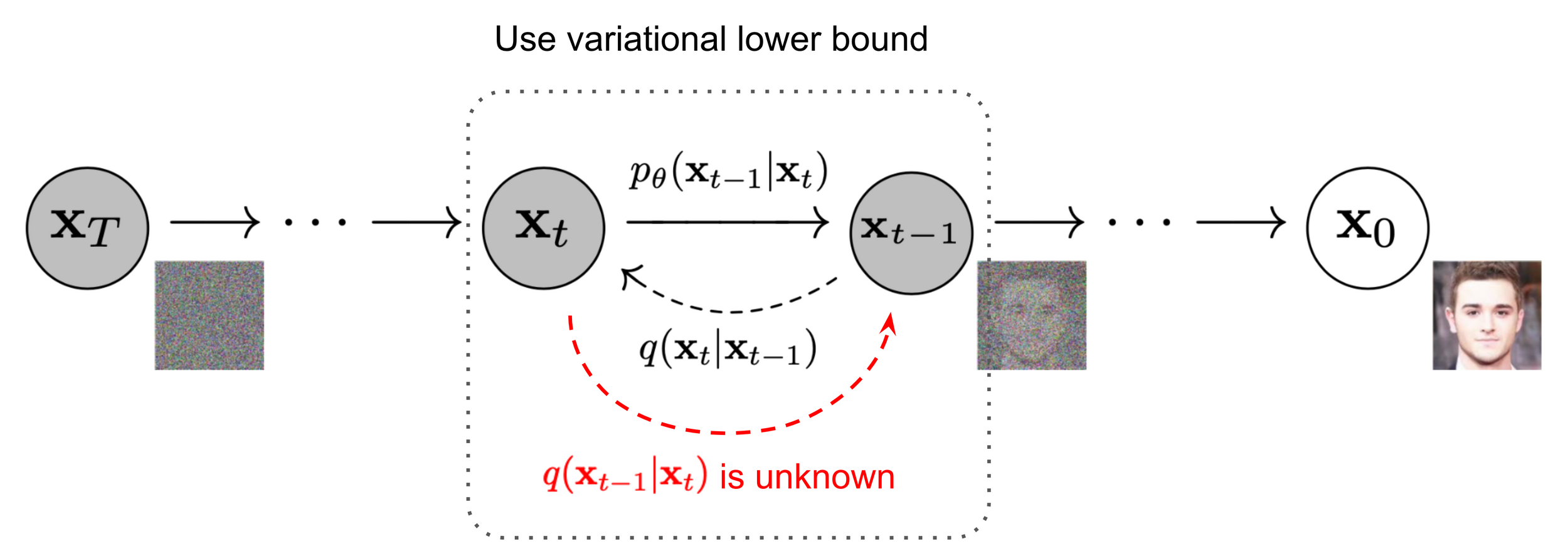
Image source: Ho et al. 2020
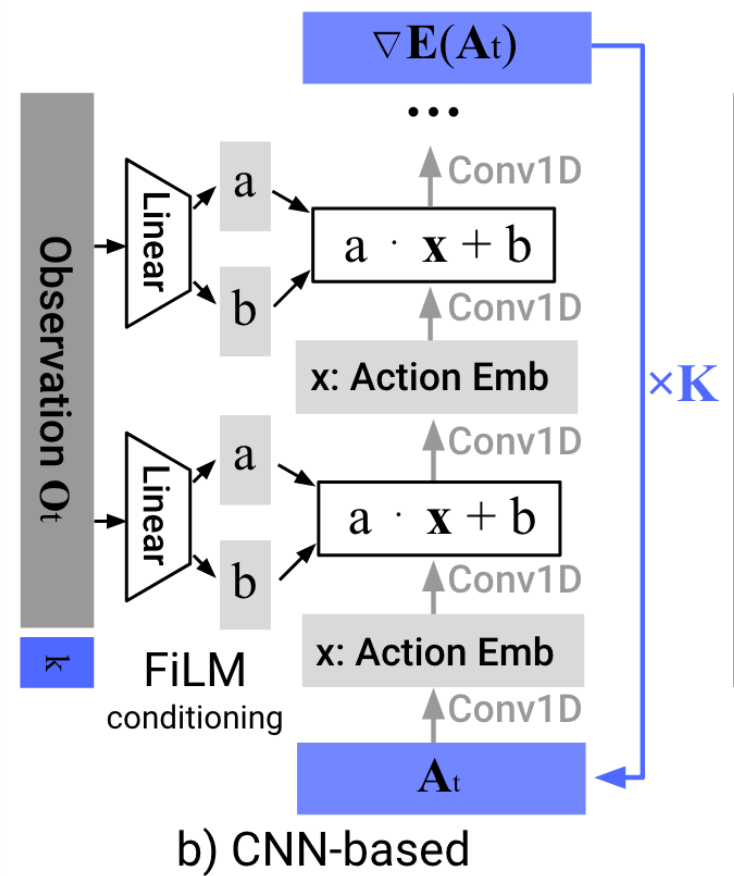
Denoiser can be conditioned on additional inputs, \(u\): \(p_\theta(x_{t-1} | x_t, u) \)
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)
Denoising approximates the projection onto the data manifold;
approximating the gradient of the distance to the manifold
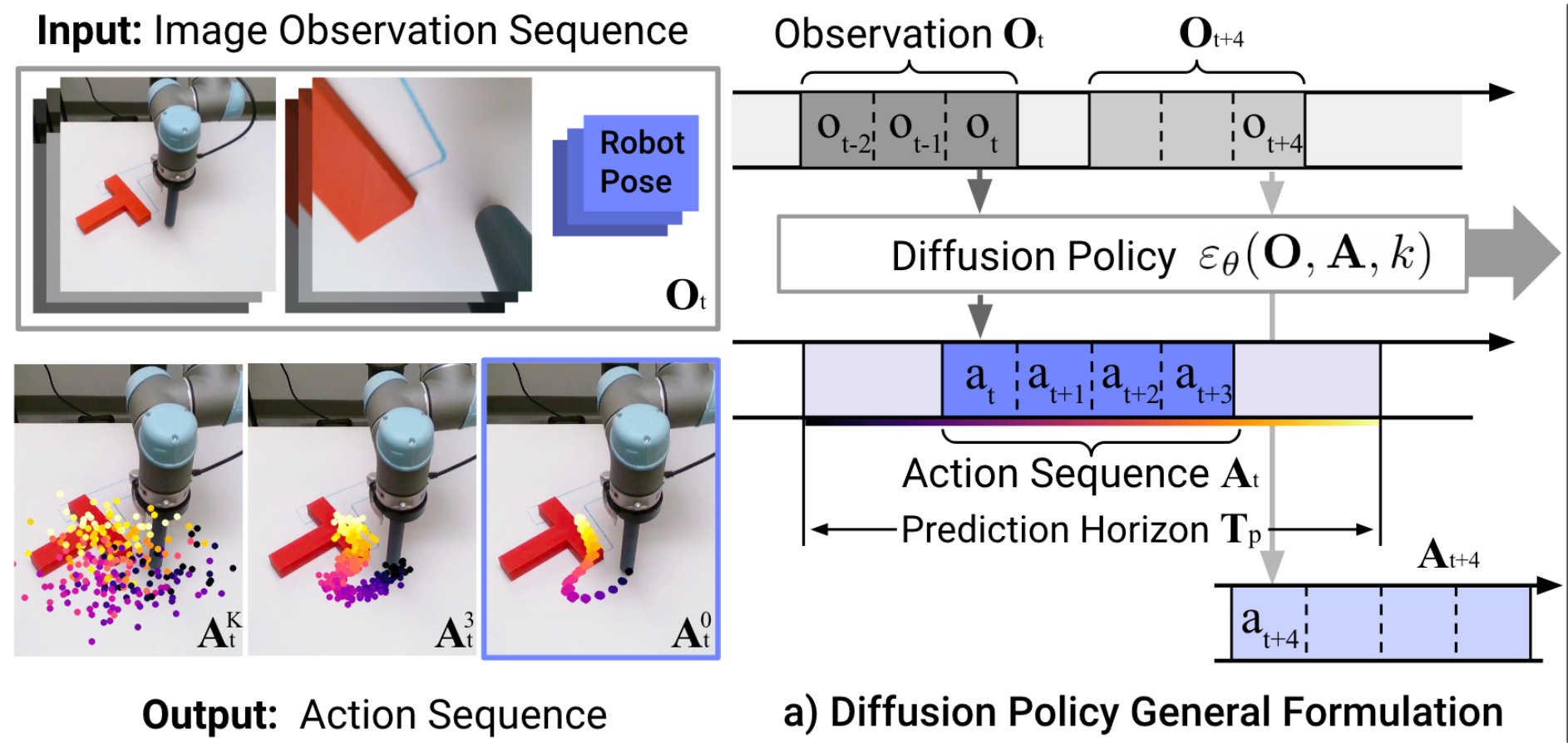
input
output
Control Policy
(as a dynamical system)
"Diffusion Policy" is an auto-regressive (ARX) model with forecasting
\(H\) is the length of the history,
\(P\) is the length of the prediction
Conditional denoiser produces the forecast, conditional on the history
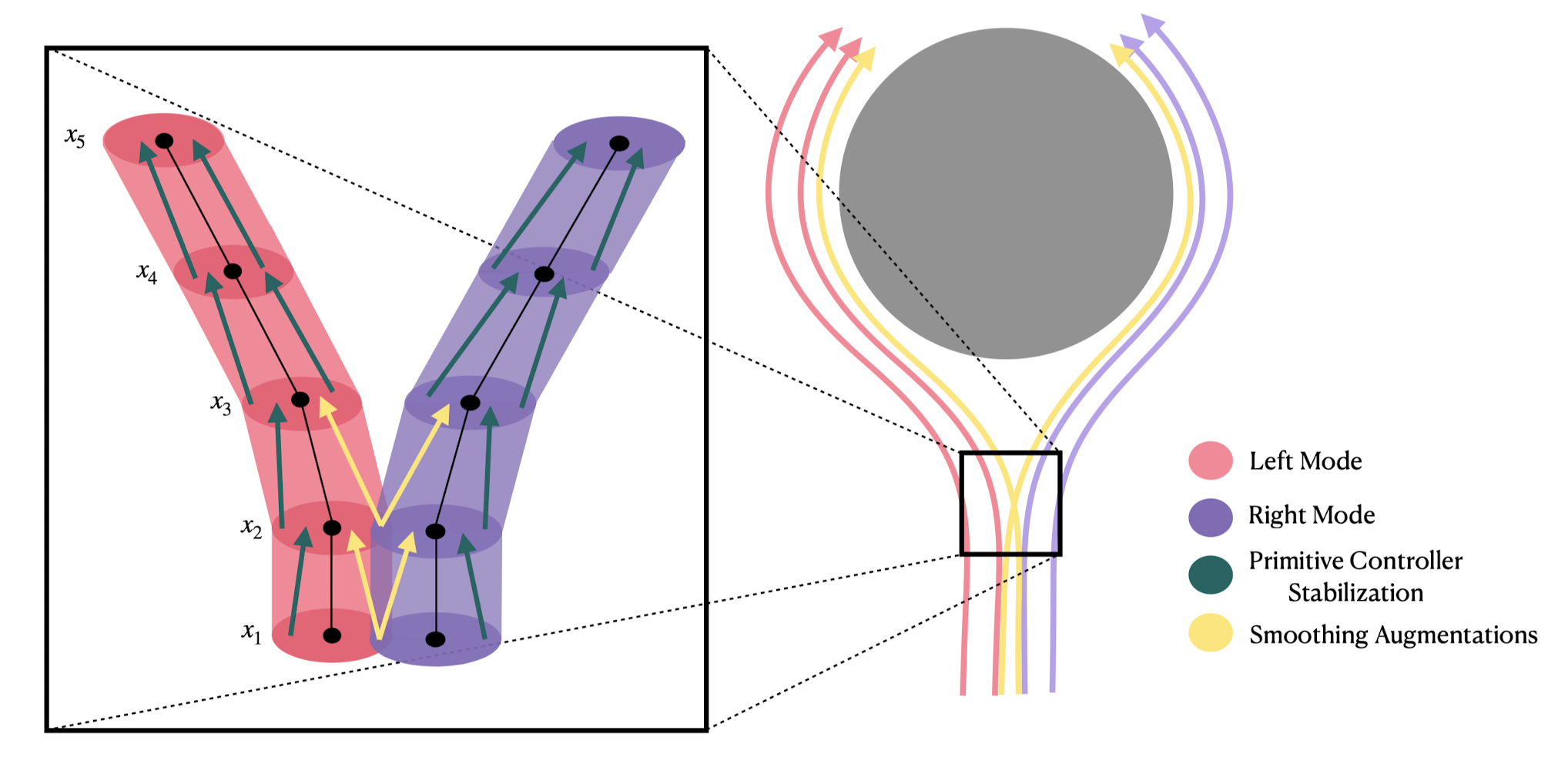
e.g. to deal with "multi-modal demonstrations"
with TRI's Soft Bubble Gripper
Open source:
I do think there is something deep happening here...
Q: How should we think about deployability?
Aside: I still very much believe in and work on model-based control!
Let's remember some lessons from control...
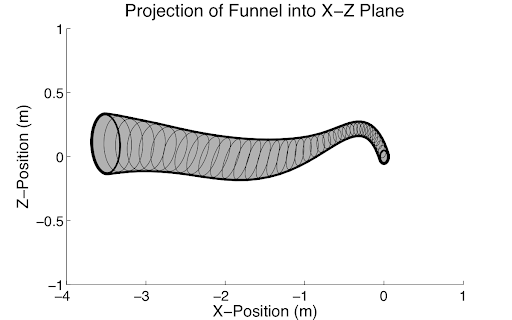
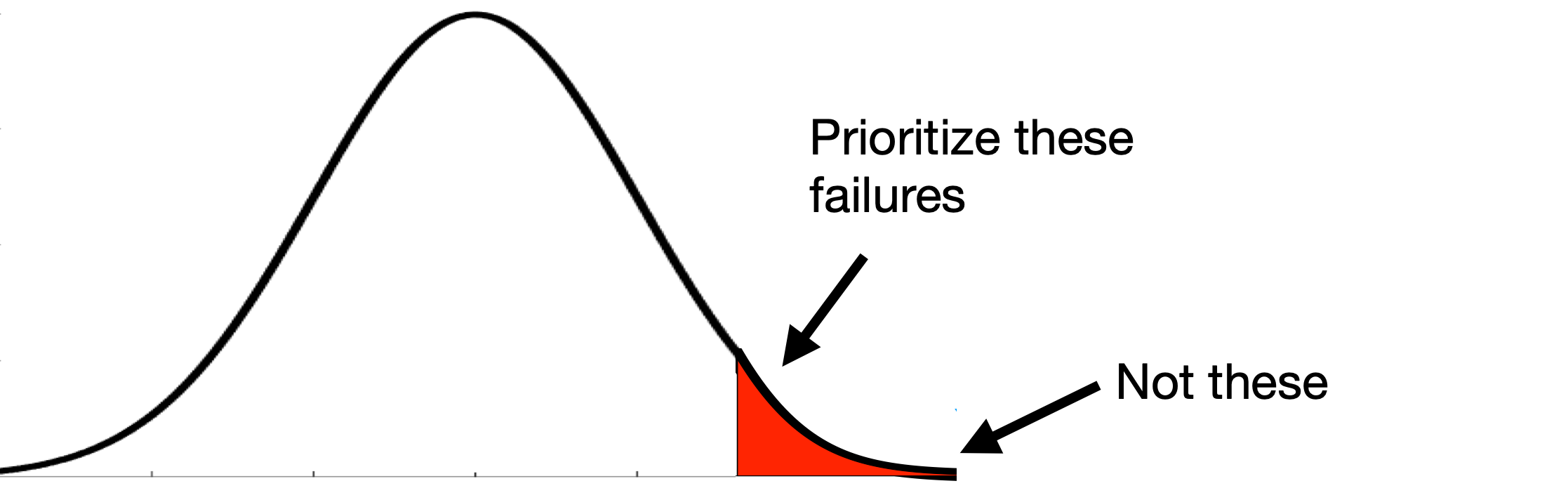
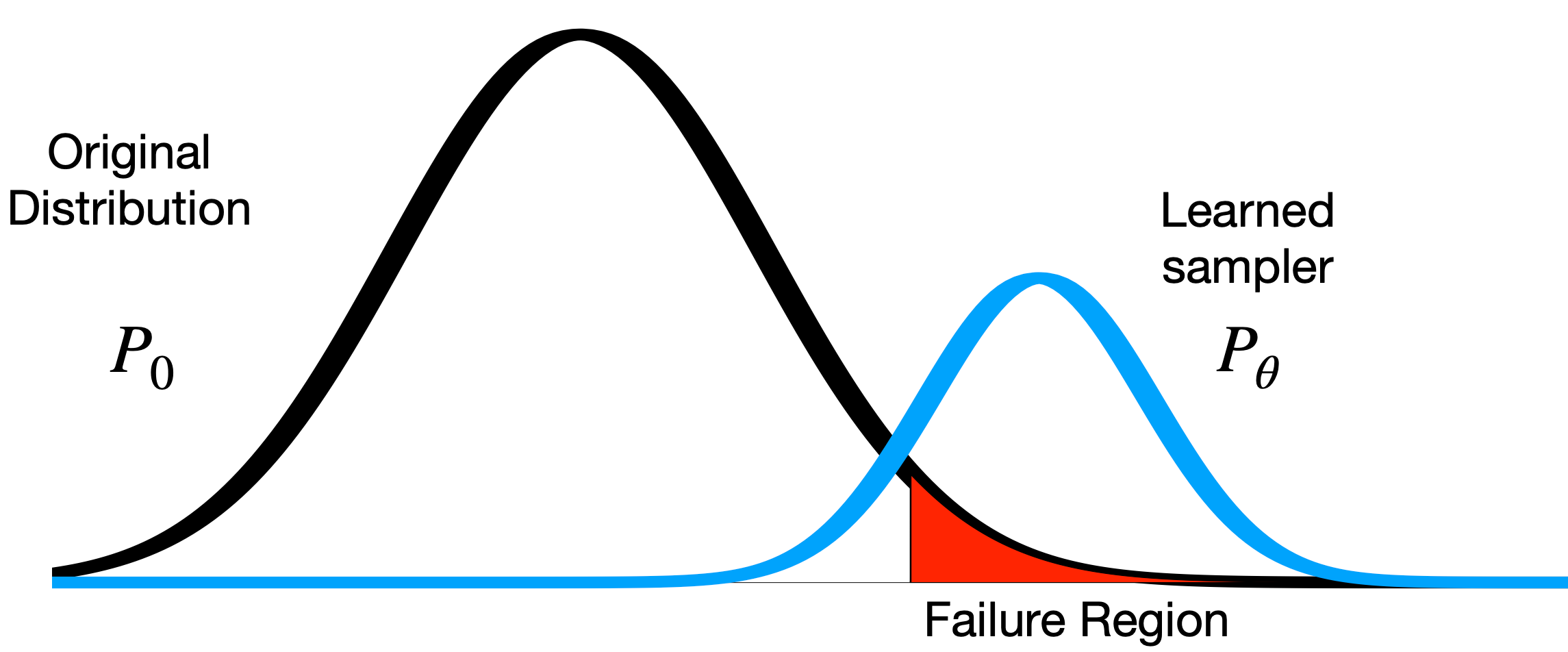
Found surprisingly rare and diverse failures of the full comma.ai openpilot in the Carla simulator.
http://manipulation.mit.edu
http://underactuated.mit.edu
By russtedrake
Princeton Robotics Seminar



