























russtedrake PRO
Roboticist at MIT and TRI
(Part 1)
MIT 6.4210/2:
Robotic Manipulation
Fall 2022, Lecture 18
Follow live at https://slides.com/d/9H33j8E/live
(or later at https://slides.com/russtedrake/fall22-lec18)
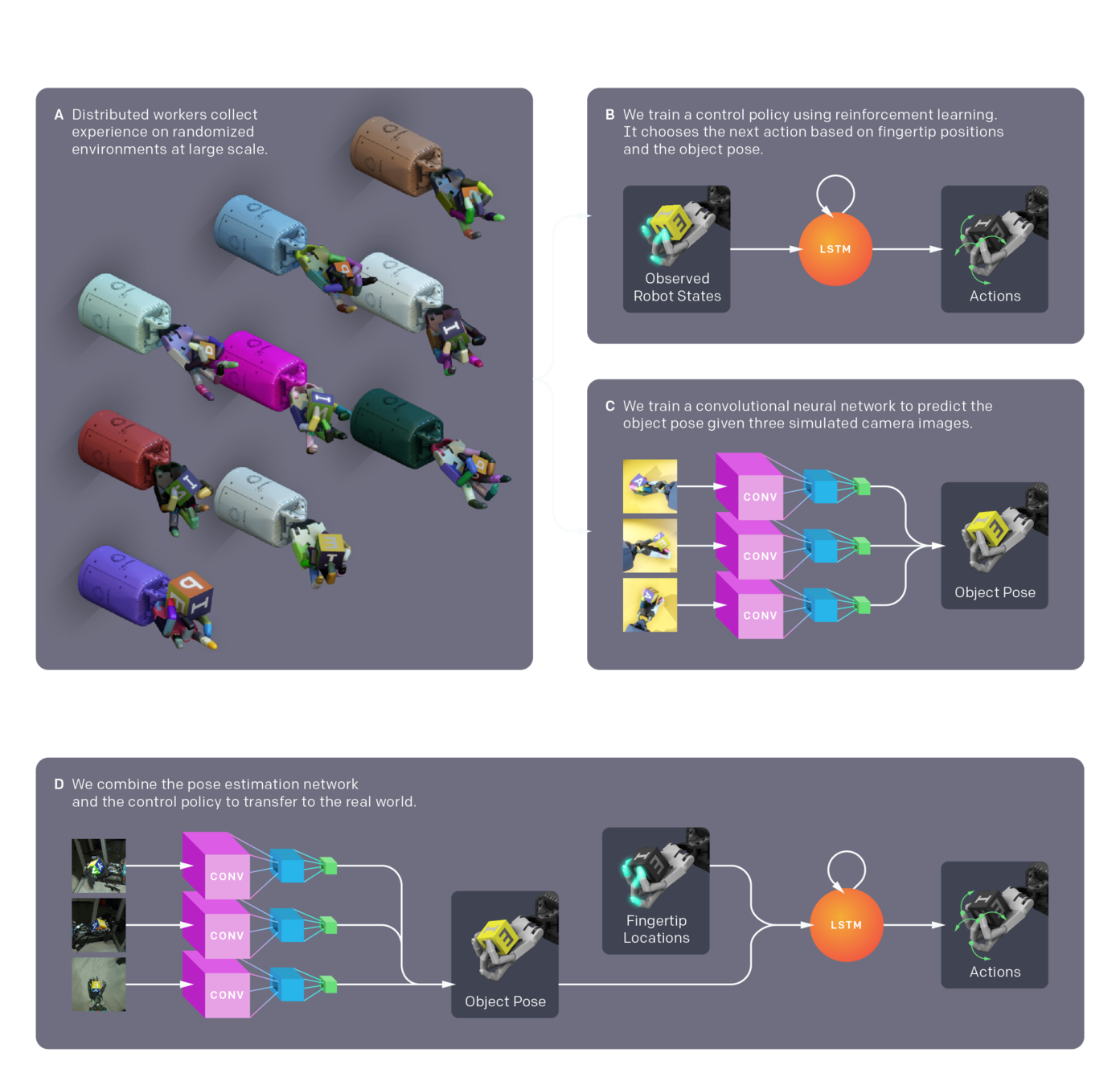
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
Andy Zeng's MIT CSL Seminar, April 4, 2022
Andy's slides.com presentation
OpenAI - Learning Dexterity
Recipe:
"And then … BC methods started to get good. Really good. So good that our best manipulation system today mostly uses BC, with a sprinkle of Q learning on top to perform high-level action selection. Today, less than 20% of our research investments is on RL, and the research runway for BC-based methods feels more robust."
import gym
from gym import error, spaces, utils
from gym.utils import seeding
class FooEnv(gym.Env):
metadata = {'render.modes': ['human']}
def __init__(self):
...
def step(self, action):
...
def reset(self):
...
def render(self, mode='human'):
...
def close(self):
...http://gym.openai.com/
import pydrake.all
builder = DiagramBuilder()
....
diagram = builder.Build()
simulator = Simulator(diagram)
simulator.AdvanceTo(...)
observation = sensor_output_port->Eval(context)
reward = reward_output_port->Eval(context)
context = diagram.CreateDefaultContext()
meshcat.Publish(context)class DrakeGymEnv(gym.Env):
"""
DrakeGymEnv provides a gym.Env interface for a Drake System (often a
Diagram) using a Simulator.
"""
def __init__(self,
simulator: Union[Simulator, Callable[[RandomGenerator],
Simulator]],
time_step: float,
action_space: gym.spaces.space,
observation_space: gym.spaces.space,
reward: Union[Callable[[System, Context], float],
OutputPortIndex, str],
action_port_id: Union[InputPort, InputPortIndex, str] = None,
observation_port_id: Union[OutputPortIndex, str] = None,
render_rgb_port_id: Union[OutputPortIndex, str] = None,
set_home: Callable[[Simulator, Context], None] = None,
hardware: bool = False):
"""
Args:
simulator: Either:
* A drake.systems.analysis.Simulator, or
* A function that produces a (randomized) Simulator.
time_step: Each call to step() will advance the simulator by
`time_step` seconds.
reward: The reward can be specified in one of two
ways: (1) by passing a callable with the signature
`value = reward(context)` or (2) by passing a scalar
vector-valued output port of `simulator`'s system.
action_port_id: The ID of an input port of `simulator`'s system
compatible with the action_space. Each Env *must* have an
action port; passing `None` defaults to using the *first*
input port (inspired by
`InputPortSelection.kUseFirstInputIfItExists`).
action_space: Defines the `gym.spaces.space` for the actions. If
the action port is vector-valued, then passing `None` defaults
to a gym.spaces.Box of the correct dimension with bounds at
negative and positive infinity. Note: Stable Baselines 3
strongly encourages normalizing the action_space to [-1, 1].
observation_port_id: An output port of `simulator`'s system
compatible with the observation_space. Each Env *must* have
an observation port (it seems that gym doesn't support empty
observation spaces / open-loop policies); passing `None`
defaults to using the *first* input port (inspired by
`OutputPortSelection.kUseFirstOutputIfItExists`).
observation_space: Defines the gym.spaces.space for the
observations. If the observation port is vector-valued, then
passing `None` defaults to a gym.spaces.Box of the correct
dimension with bounds at negative and positive infinity.
render_rgb_port: An optional output port of `simulator`'s system
that returns an `ImageRgba8U`; often the `color_image` port
of a Drake `RgbdSensor`. When not `None`, this enables the
environment `render_mode` `rgb_array`.
set_home: A function that sets the home state (plant, and/or env.)
at reset(). The reset state can be specified in one of
the two ways:
(1) setting random context using a Drake random_generator
(e.g. joint.set_random_pose_distribution()),
(2) parssing a function set_home().
hardware: If True, it prevents from setting random context at
reset() when using random_generator, but it does execute
set_home() if given.
Notes (using `env` as an instance of this class):
- You may set simulator/integrator preferences by using `env.simulator`
directly.
- The `done` condition returned by `step()` is always False by
default. Use `env.simulator.set_monitor()` to use Drake's monitor
functionality for specifying termination conditions.
- You may additionally wish to directly set `env.reward_range` and/or
`env.spec`. See the docs for gym.Env for more details.
"""from manipulation.drake_gym import DrakeGymEnvOpenAI - Learning Dexterity
"PPO has become the default reinforcement learning algorithm at OpenAI because of its ease of use and good performance."
https://openai.com/blog/openai-baselines-ppo/
model = PPO('MlpPolicy', env, verbose=1, tensorboard_log=log)
stable_baselines3/common/policies.py#L435-L440
# Default network architecture, from stable-baselines
net_arch = [dict(pi=[64, 64], vf=[64, 64])]Actions
Observations
builder.ExportOutput(inv_dynamics.get_desired_position(), "actions")Network
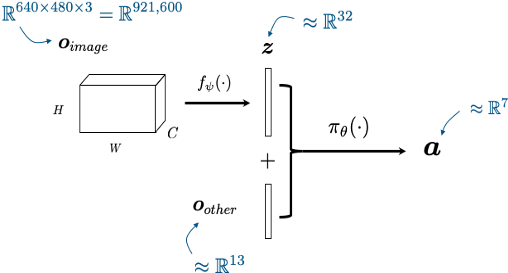
builder.ExportOutput(plant.get_state_output_port(), "observations")approximately:
angle_from_vertical = (box_state[2] % np.pi) - np.pi / 2
cost = 2 * angle_from_vertical**2 # box angle
cost += 0.1 * box_state[5]**2 # box velocity
effort = actions - finger_state[:2]
cost += 0.1 * effort.dot(effort) # effort
# finger velocity
cost += 0.1 * finger_state[2:].dot(finger_state[2:])
# Add 10 to make rewards positive (to avoid rewarding simulator
# crashes).
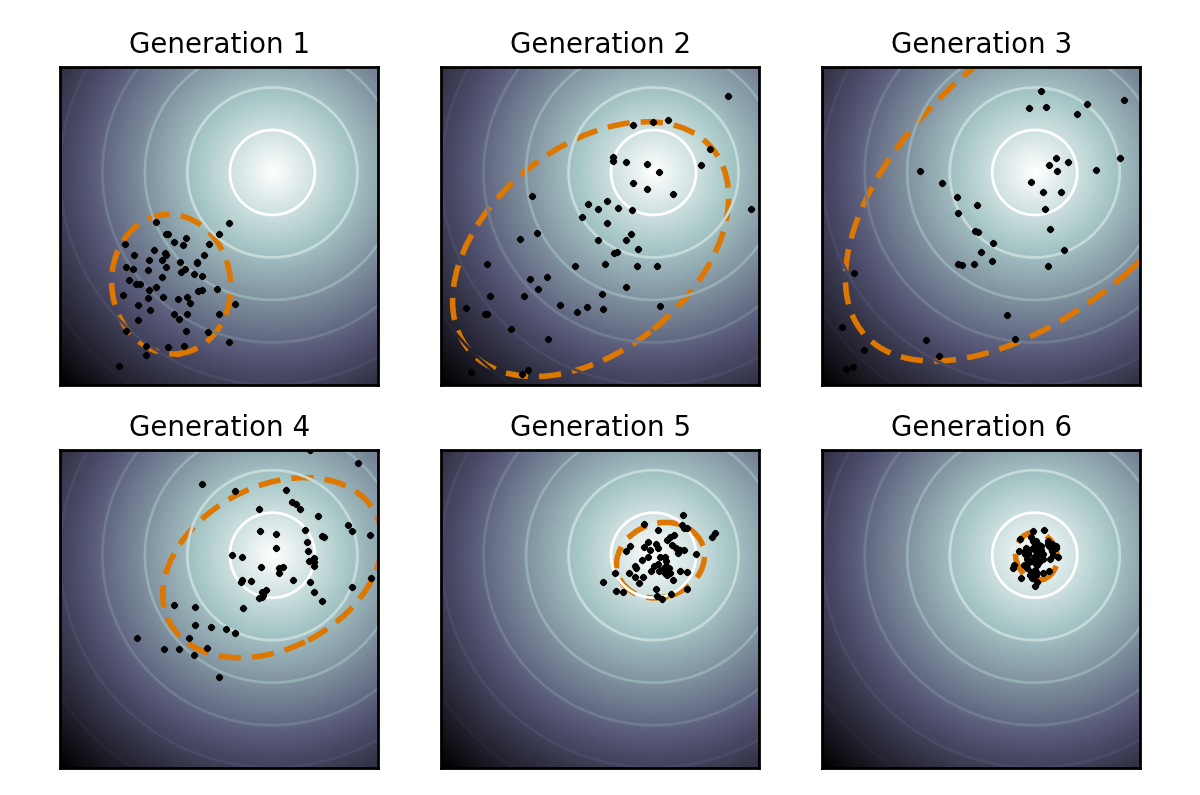
output[0] = 10 - costhttps://en.wikipedia.org/wiki/CMA-ES
(Image source: Tobin et al, 2017)
Do Differentiable Simulators Give Better Policy Gradients?
H. J. Terry Suh and Max Simchowitz and Kaiqing Zhang and Russ Tedrake
ICML 2022
Available at: https://arxiv.org/abs/2202.00817
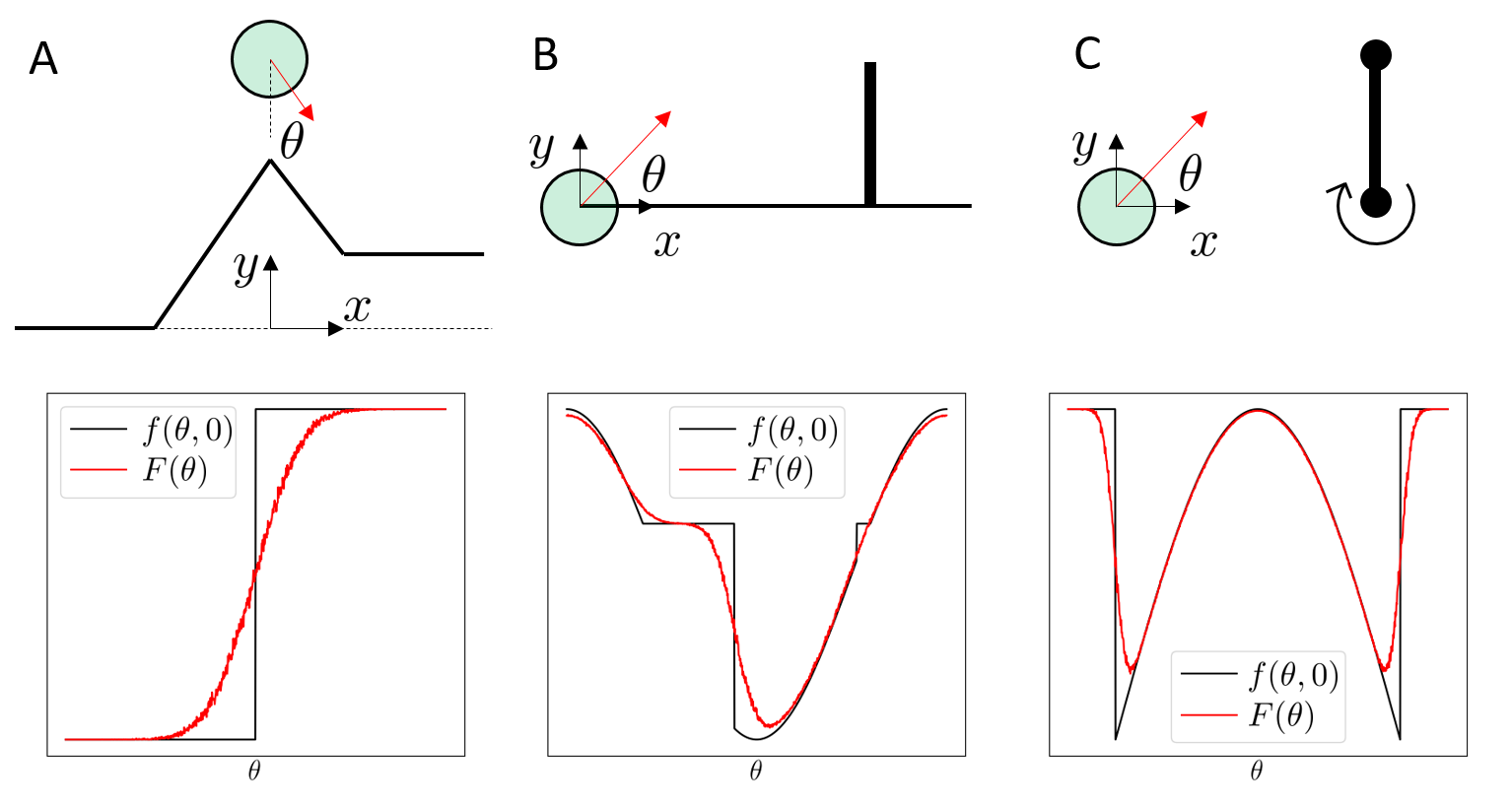
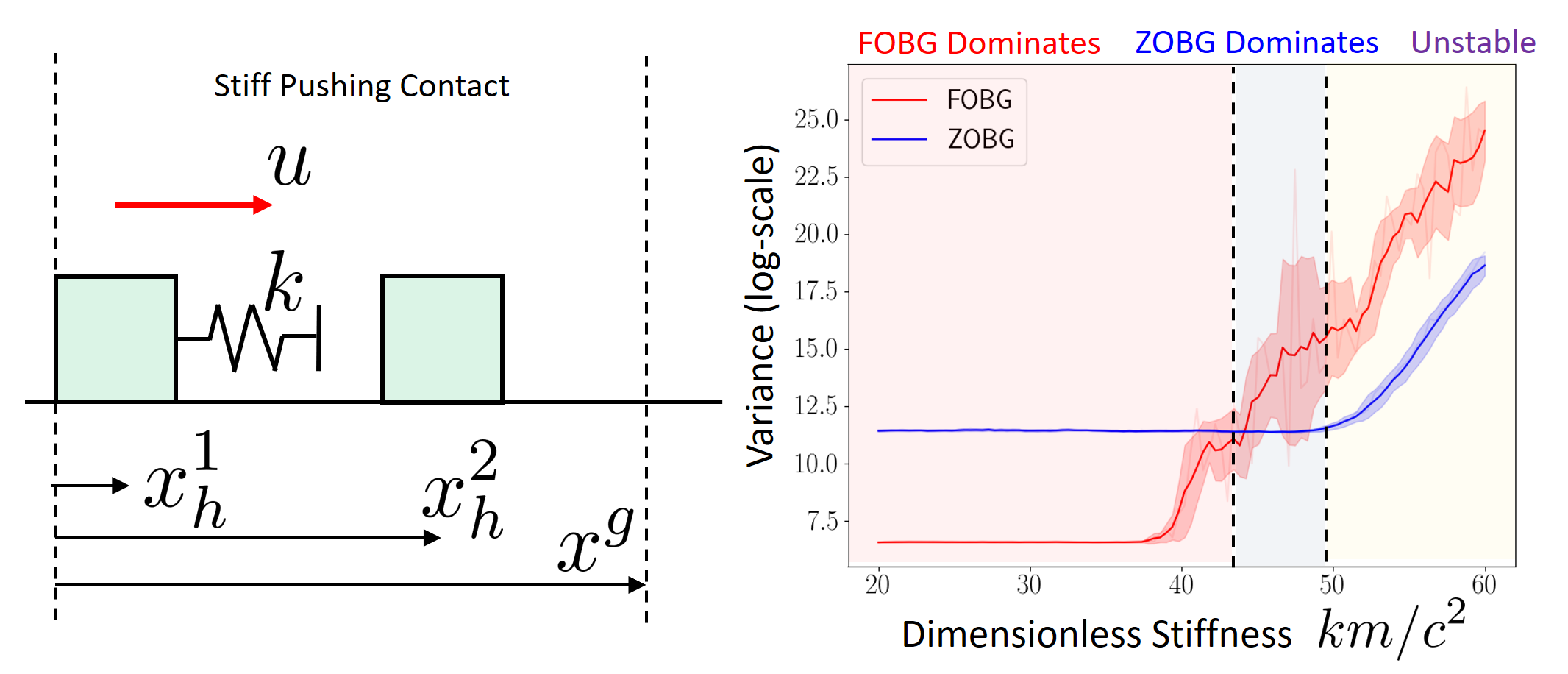
Contact dynamics can lead to discontinuous landscapes, but mostly in the corner cases.
We have "real" discontinuities at the corner cases
Soft/compliant contact can replace discontinuities with stiff approximations.
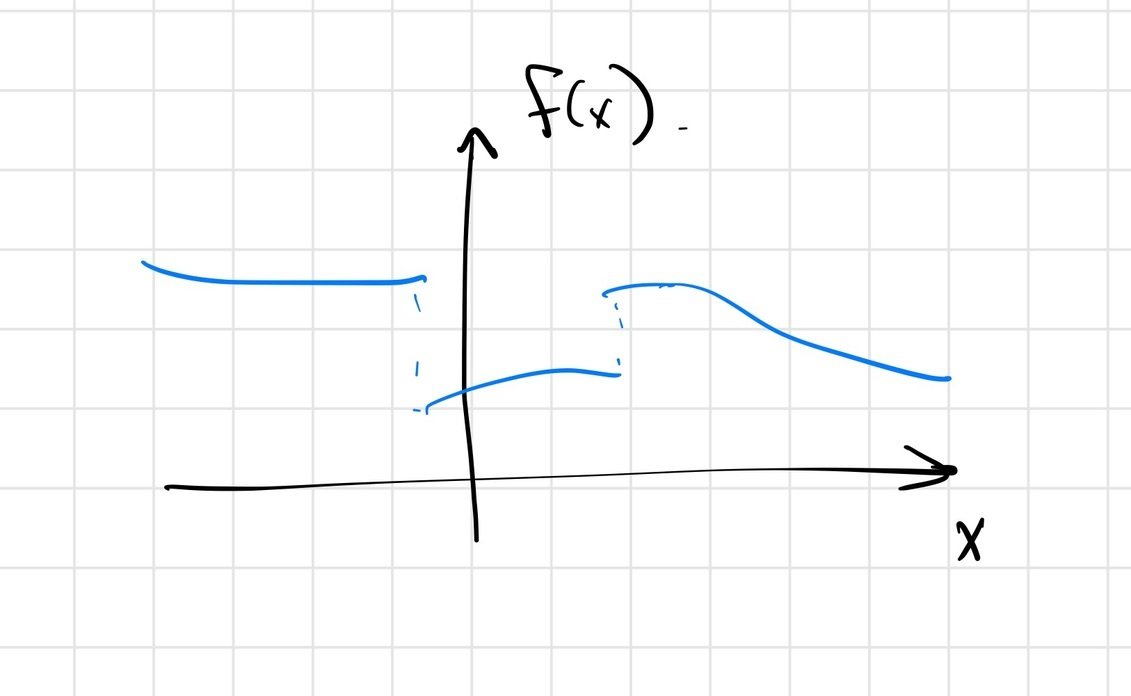
\[ \min_x f(x) \]
For gradient descent, discontinuities / non-smoothness can
vs
In reinforcement learning (RL) and "deep" model-predictive control, we add stochasticity via
then optimize a stochastic optimal control objective (e.g. maximize expected reward)
These can all smooth the optimization landscape.
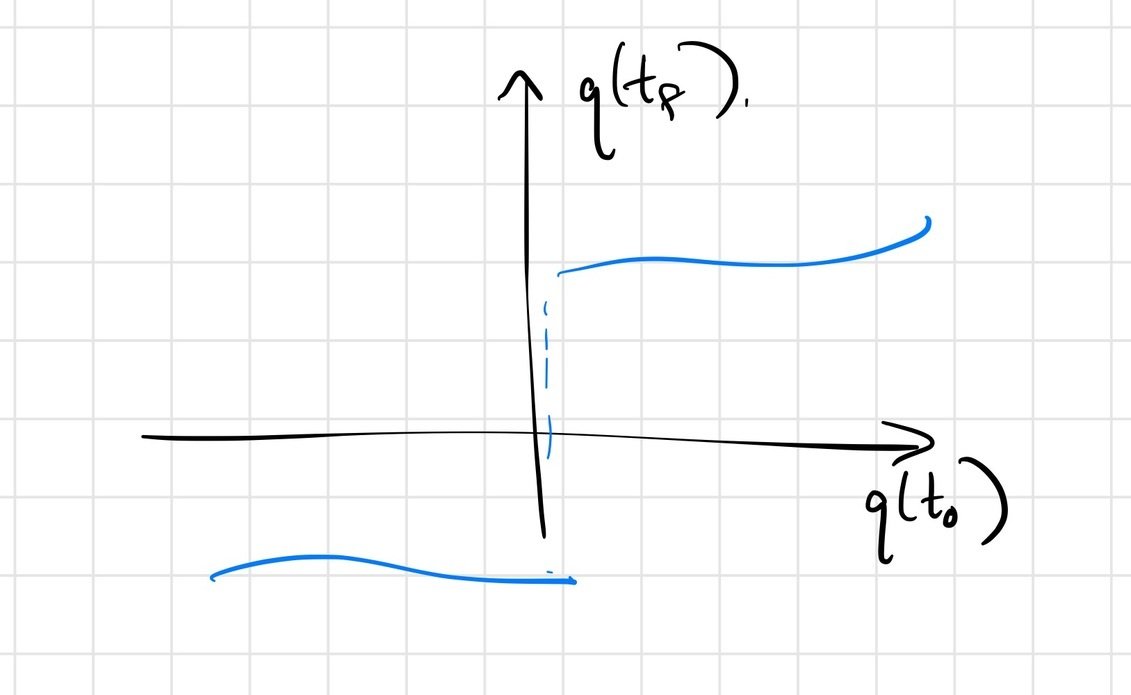
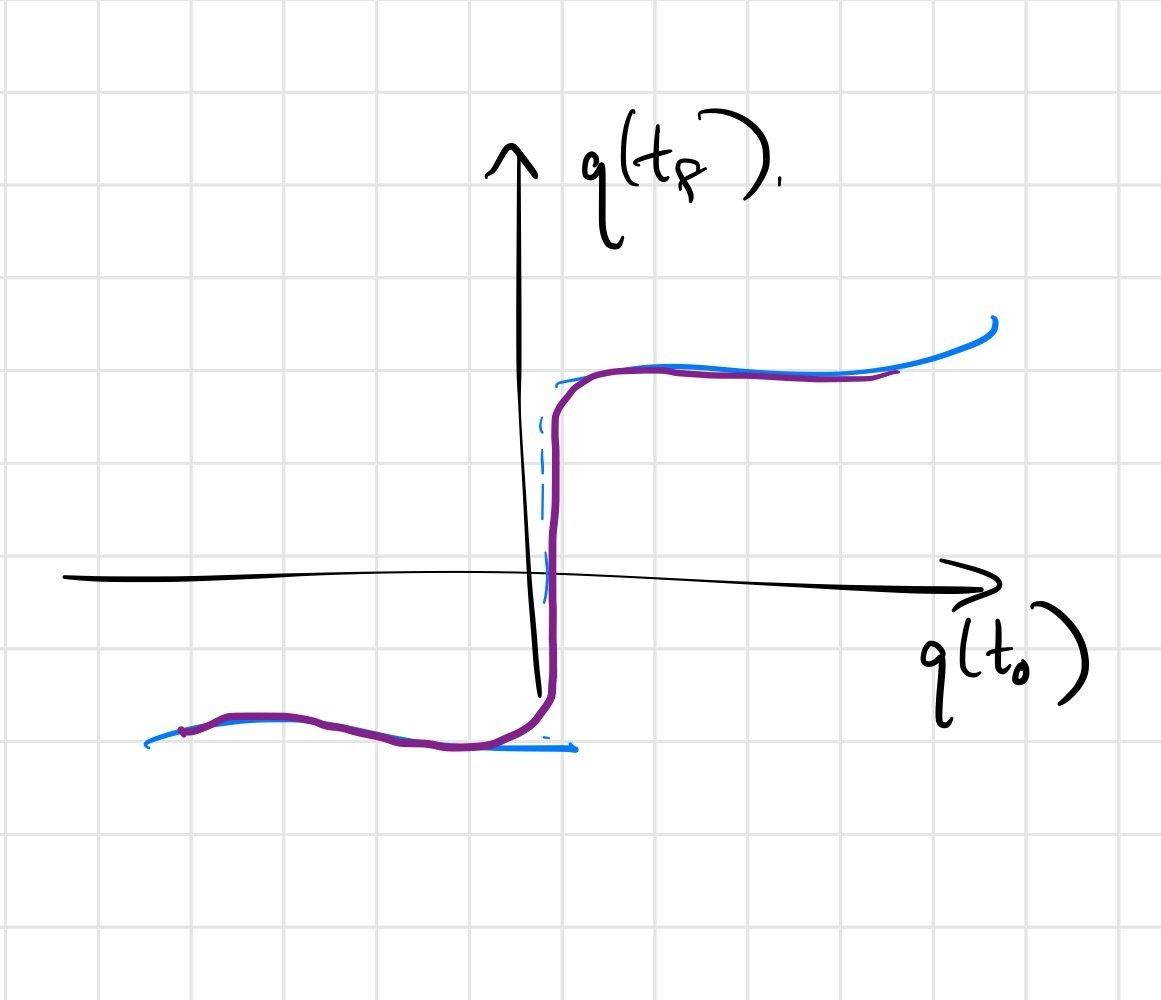
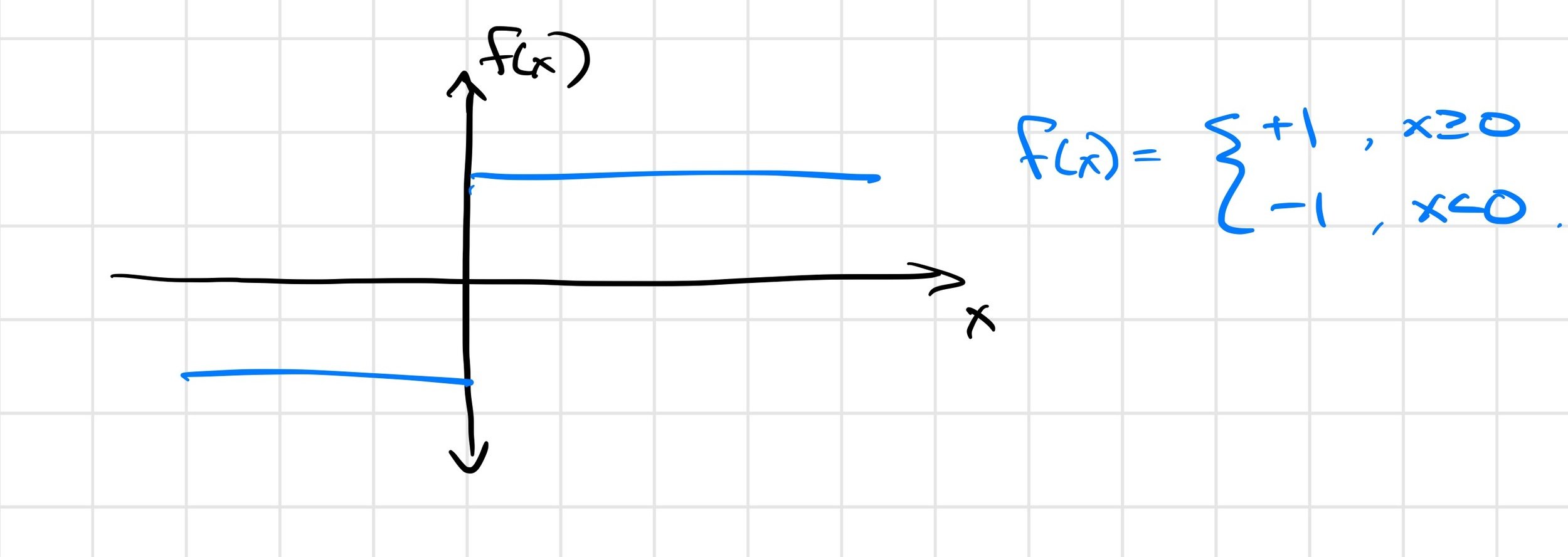
The answer is subtle; the Heaviside example might shed some light.
vs
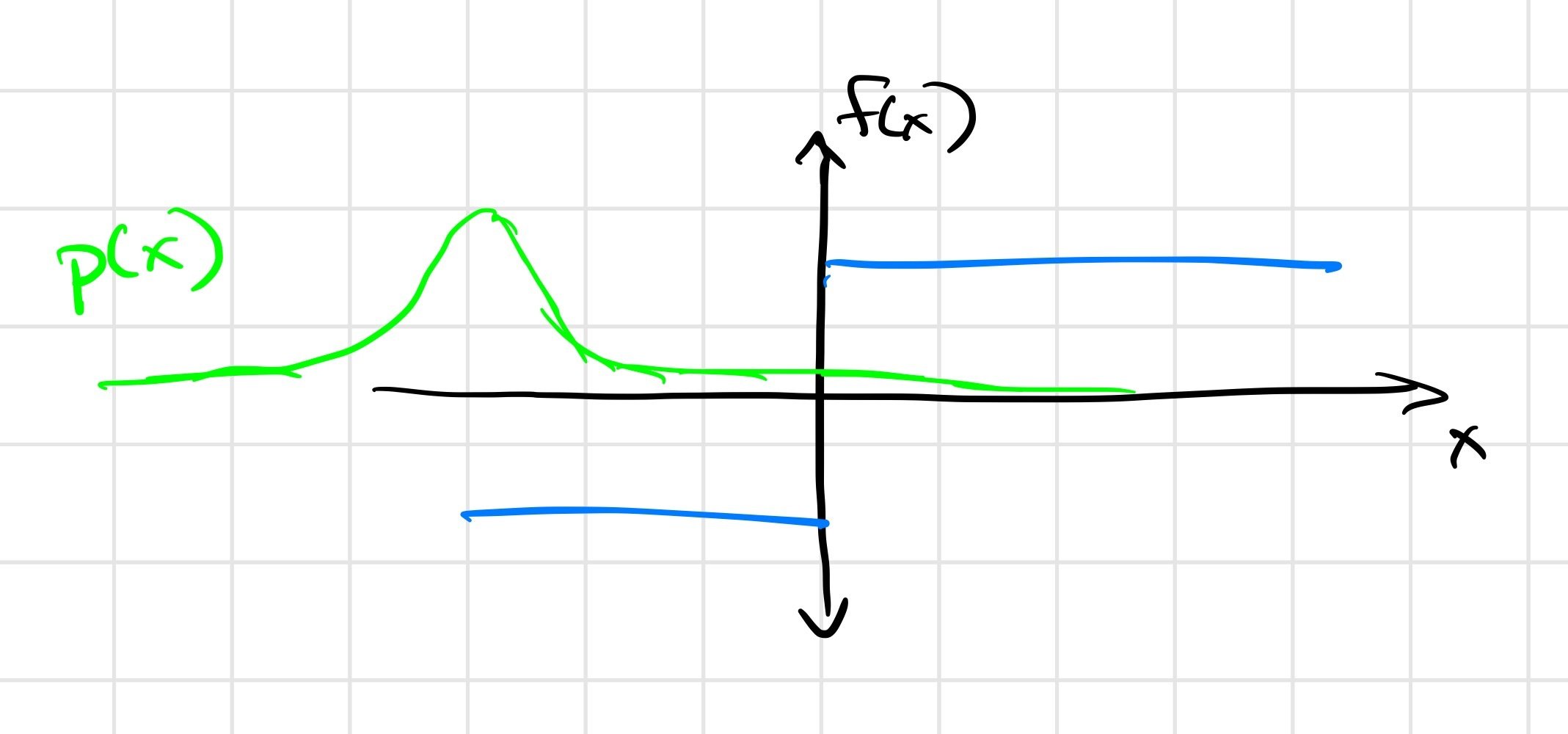
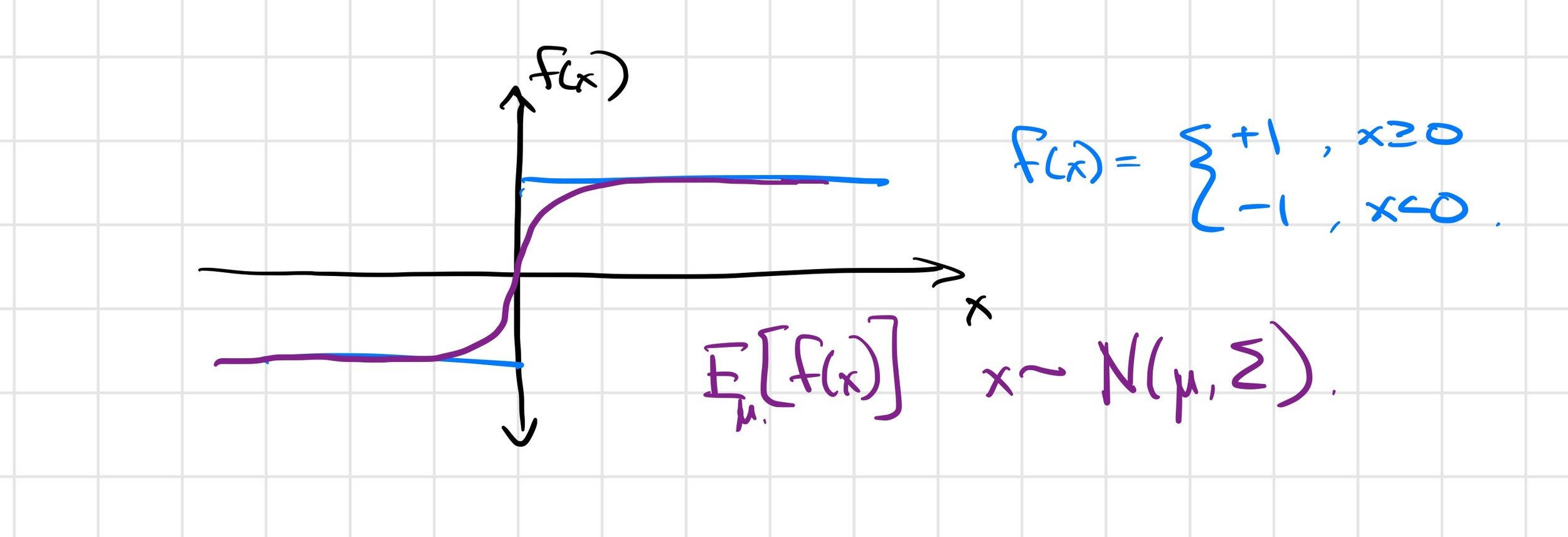
Differentiable simulators give \(\frac{\partial f}{\partial \theta}\), but we want \(\frac{\partial}{\partial \theta} E_w[f(\theta, w)]\).
J. Burke, F. E. Curtis, A. Lewis, M. Overton, and L. Simoes, Gradient Sampling Methods for Nonsmooth Optimization, 02 2020, pp. 201–225.
But the regularity conditions aren't met in contact discontinuities, leading to a biased first-order estimator.
Often, but not always.
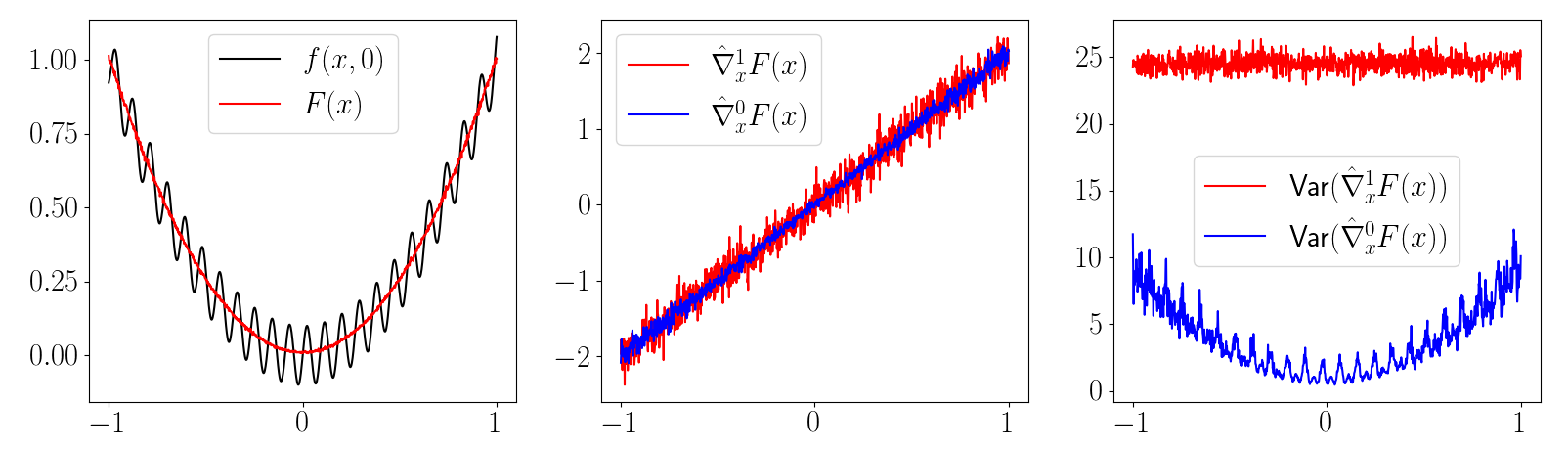
\(\frac{\partial f(x)}{\partial x} = 0\) almost everywhere!
\( \Rightarrow \frac{1}{K} \sum_{i=1}^K \frac{\partial f(\mu + w_i)}{\partial \mu} = 0 \)
First-order estimator is biased
\( \not\approx \frac{\partial}{\partial \mu} E_\mu [f(x)] \)
Zero-order estimator is (still) unbiased
e.g. with stiff contact models (large gradient \(\Rightarrow\) high variance)
Global Planning for Contact-Rich Manipulation via
Local Smoothing of Quasi-dynamic Contact Models
Tao Pang, H. J. Terry Suh, Lujie Yang, and Russ Tedrake
Available at: https://arxiv.org/abs/2206.10787
Establish equivalence between randomized smoothing and a (deterministic/differentiable) force-at-a-distance contact model.
"By studying both ES and RL gradient estimators mathematically we can see that ES is an attractive choice especially when the number of time steps in an episode is long, where actions have long-lasting effects, or if no good value function estimates are available."
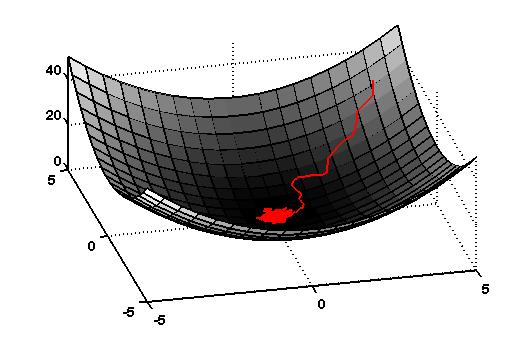
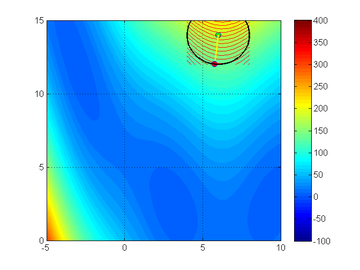
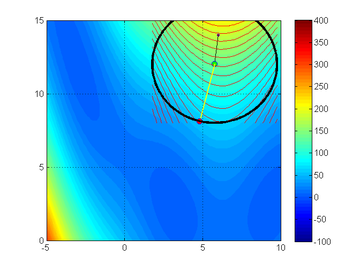
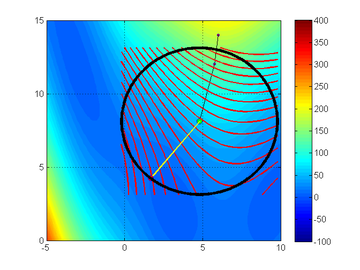
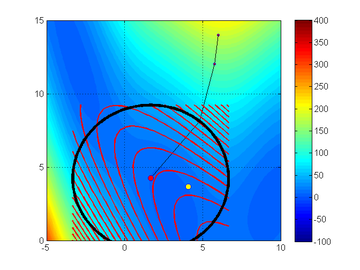
Trust-region method on a 'Branin' function. From Northwestern University Open Text Book on Process Optimization
Kolter, J. Zico, Zachary Jackowski, and Russ Tedrake. "Design, analysis, and learning control of a fully actuated micro wind turbine." 2012 American Control Conference (ACC). IEEE, 2012.
Schulman, John, et al. "Trust region policy optimization." International conference on machine learning. 2015.
def ppo_pendulum(ctxt=None, seed=1):
"""Train PPO with InvertedDoublePendulum-v2 environment.
Args:
ctxt (garage.experiment.ExperimentContext): The experiment
configuration used by Trainer to create the snapshotter.
seed (int): Used to seed the random number generator to produce
determinism.
"""
set_seed(seed)
env = GymEnv('InvertedDoublePendulum-v2')
trainer = Trainer(ctxt)
policy = GaussianMLPPolicy(env.spec,
hidden_sizes=[64, 64],
hidden_nonlinearity=torch.tanh,
output_nonlinearity=None)
value_function = GaussianMLPValueFunction(env_spec=env.spec,
hidden_sizes=(32, 32),
hidden_nonlinearity=torch.tanh,
output_nonlinearity=None)
algo = PPO(env_spec=env.spec,
policy=policy,
value_function=value_function,
discount=0.99,
center_adv=False)
trainer.setup(algo, env)
trainer.train(n_epochs=100, batch_size=10000)A System for General In-Hand Object Re-Orientation
Tao Chen, Jie Xu, Pulkit Agrawal
Conference on Robot Learning (CoRL), 2021 (Best Paper Award)
https://taochenshh.github.io/projects/in-hand-reorientation
“The sheer scope and variation across objects tested with this method, and the range of different policy architectures and approaches tested makes this paper extremely thorough in its analysis of this reorientation task.”
"We use PPO to optimize \(\pi\)."
Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).
https://spinningup.openai.com/en/latest/algorithms/ppo.html
By russtedrake
MIT Robotic Manipulation Fall 2020 http://manipulation.csail.mit.edu


