A model for optimizing vaccine usage through a sequence of decisions to manage stock uncertainty
Towards Reinforcement learning
Modeling and Uncertainty Quantification (SMUQ). Organized by the Sociedade Brasileira de Matemática Aplicada e Computacional (SBMAC) and Instituto Universitario de Matemática Multidisciplinar (IMM) will be held in València (Spain) from July 8th to July 9th, 2024.
Yofre H. Garcia
Saúl Diaz-Infante Velasco
Jesús Adolfo Minjárez Sosa
sauldiazinfante@gmail.com

When a vaccine is in short supply, sometimes refraining from vaccination is the best response—at least for a while.

On December 02, 2020, the Mexican government announced a delivery plan for vaccines by Pfizer-BioNTech and other firms as part of the COVID-19 vaccination campaign.
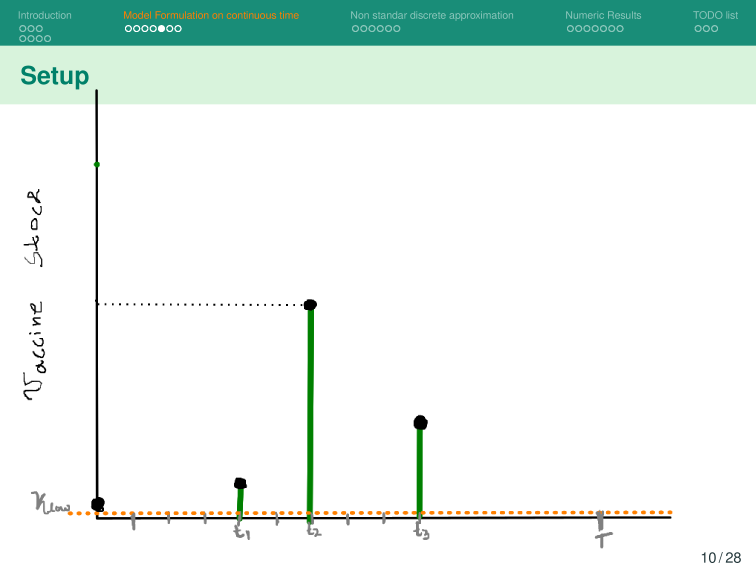
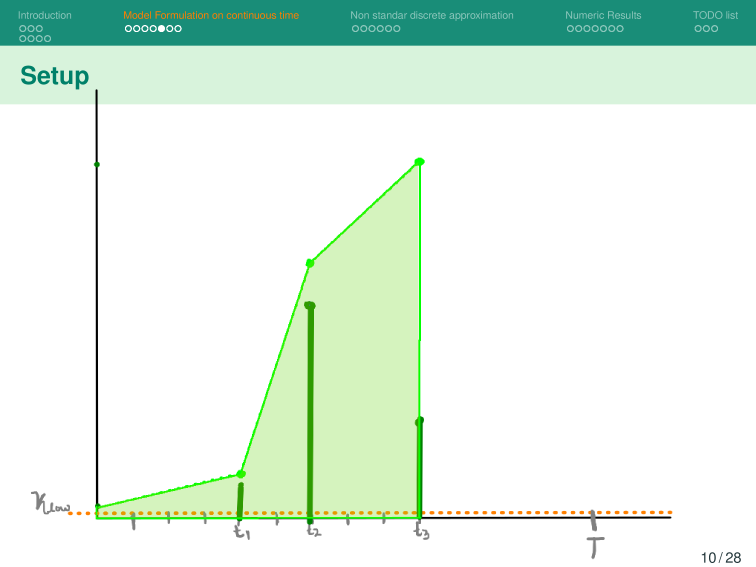
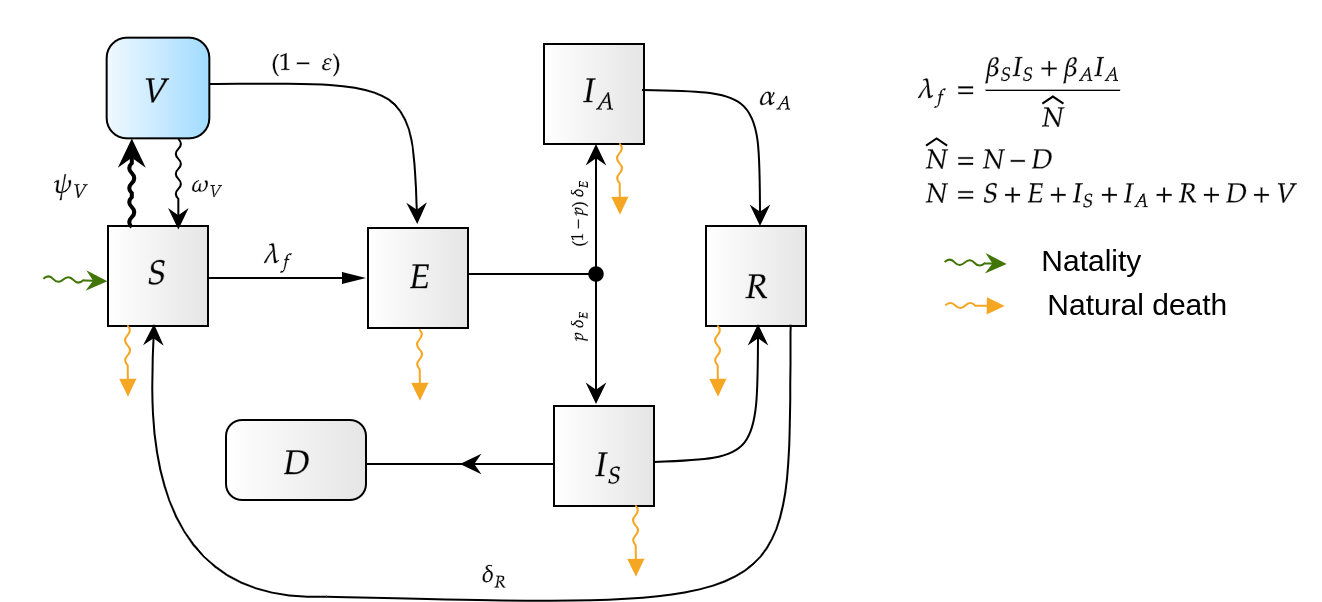
Given a shipment of vaccines calendar, describe the stock management with backup protocol and quantify random fluctuations
due to schedule or quantity.
Then, incorporate this dynamic into an ODE system that describes the disease and evaluates its response accordingly.
Text
Nonlinear control: HJB and DP
Given
\frac{dx}{dt} = f(x(t))
Goal:
Desing
to follow
s. t. optimize cost
\text{action } a_t\in \mathcal{A},
\text{state } x_t
\frac{dx_{t}}{dt} =f(x_{t} ,a_{t})
Agent
a_t\in \mathcal{A}
x_t
J(x_t, a_t, 0, T) = Q(x_T, T)
+ \int_0^T \mathcal{L}(x_{\tau}, a_{\tau}) d_{\tau}
J(x_t, a_t, 0, T) .
























\begin{aligned}
%C_{t+1}
&=
C(x_{t}, a_{t})
\\
%\Phi_{t+1}^{h}(x_t,a_t)
&=
x_t +\varphi(h,\theta)
\end{aligned}
Agent
R_{t+1}
x_{t+1}
x_0,a_0,R_1,
a_t\in \mathcal{A}(x_t)
action
state
x_{t}
reward
R_{t}
x_0, a_0, R_1,
x_1, a_1, R_2,
\cdots,
x_t, a_t, R_{t+1}
\cdots,
x_{T-1}, a_{T-1}, R_T,
x_T
G_t := R_{t+1} + \cdots + R_{T-1} + R_{T}
\begin{aligned}
G_t &:= R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3}+ \cdots
\\
&=
\sum_{k=0}
\gamma^{k} R_{t+1+k}, \qquad \gamma \in [0,1]
\end{aligned}
G_t := R_{t+1} + \cdots + R_{T-1} + R_{T}
p(s^{\prime},r | s, a)
:= \mathbb{P}[x_t=s^{\prime}, R_{t}=r | x_{t-1}=s, a_t=a]
\begin{aligned}
r(s, a)
&:= \mathbb{E}[
R_t | S_{t-1}=s, a_{t}=a
]
\\
&=
\sum_{r\in \mathcal{R}}
r
\sum_{s^{\prime}\in S}
p(s^{\prime}, r | s, a)
\end{aligned}
\begin{aligned}
G_t &:= R_{t+1} + \gamma R_{t+2} + \cdots + \gamma^{T-t-1} R_{T}
\\
&=\sum_{k=t+1}^{T}
\gamma^{k-t-1} R_k
\end{aligned}
Discounted return
Total return
\begin{aligned}
v_{\pi}(s) &:=
\mathbb{E}_{\pi}
[G_t | x_t = s]
\\
&=
\mathbb{E}_{\pi}
\left[
\sum_{k=0}^{\infty}
\gamma^{k} R_{t+k+1}
\big| x_t =s
\right]
\end{aligned}
\pi(a|s):= \mathbb{P}[a_t = a|x_t=s]
\begin{aligned}
v_{\pi}(s) &:=
\mathbb{E}_{\pi}
[G_t | x_t = s]
\\
&=
\mathbb{E}_{\pi}
\left[
\sum_{k=0}^{\infty}
\gamma^{k} R_{t+k+1}
\big| x_t =s
\right]
\\
& =
\mathbb{E}_{\pi}
\left[
R_{t+1} + \gamma G_{t+1} | x_t = s
\right]
\\
&=
\sum_{a} \pi(a |s)
\sum_{s^{\prime}, r} p(s^{\prime},r | s, a)
\left[
r
+
\gamma
\mathbb{E}_{\pi}[G_{t+1} | x_{t+1}=s^{\prime}]
\right]
\\
&=
\sum_{a} \pi(a |s)
\sum_{s^{\prime}, r} p(s^{\prime},r | s, a)
\left[
r
+
\gamma v_{\pi}(s^{\prime})
\right]
\end{aligned}
\begin{aligned}
v_{*}(s) &:=
\max_{\pi}
v_{\pi}(s)
\\
&=
\max_{a\in \mathcal{A}(s)}
\mathbb{E}_{\pi_{*}}
\left[
\sum_{k=0}^{\infty}
\gamma^{k} R_{t+k+1}
\big| x_t =s
\right]
\\
& =
\max_{a\in \mathcal{A}(s)}
\mathbb{E}_{\pi}
\left[
R_{t+1} + \gamma G_{t+1} | x_t = s
\right]
\\
&=
\max_{a\in \mathcal{A}(s)}
\sum_{a} \pi(a |s)
\sum_{s^{\prime}, r} p(s^{\prime},r | s, a)
\left[
r
+
\gamma
\mathbb{E}_{\pi}[G_{t+1} | x_{t+1}=s^{\prime}]
\right]
\\
&=
\max_{a\in \mathcal{A}(s)}
\sum_{a} \pi(a |s)
\sum_{s^{\prime}, r} p(s^{\prime},r | s, a)
\left[
r
+
\gamma v_{\pi}(s^{\prime})
\right]
\end{aligned}
x_0, a_0, R_1,
x_1, a_1, R_2,
\cdots,
x_t, a_t, R_{t+1}
\cdots,
x_{T-1}, a_{T-1}, R_T,
x_T
\begin{aligned}
\gamma &= 0
\\
G_t &:= R_{t+1} + \cancel{\gamma R_{t+2}} + \cdots + \cancel{\gamma^{T-t-1} R_{T}}
\end{aligned}
Dopamine Reward

\begin{aligned}
x_{t_{n+1}} &
= x_{t_n}
+ F(x_{t_n}, \theta, a_0) \cdot h,
\quad x_{t_0} = x(0),
\\
\text{where: }&
\\
t_n &:=
n \cdot h, \quad
n = 0, \cdots, N,
\quad t_{N} = T.
\end{aligned}
\begin{aligned}
&\min_{a_{0}^{(k)} \in \mathcal{A}_0}
c(x_{\cdot}, a_0):=
c_1(a_0^{(k)})\cdot T^{(k)} +
\sum_{n=0}^{N-1}
c_0(t_n, x_{t_n}) \cdot h
\\
\text{ s.t.} &
\\
&
x_{t_{n+1}}
= x_{t_n}
+ F(x_{t_n}, \theta, a_0) \cdot h,
\quad x_{t_0} = x(0),
\\
\text{where: }&
\\
t_n &:=
n \cdot h, \quad
n = 0, \cdots, N,
\quad t_{N} = T.
\end{aligned}
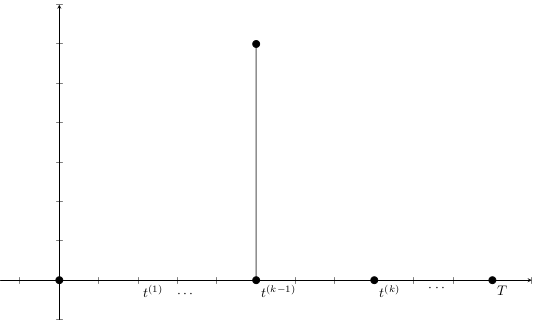
\begin{aligned}
C(x_{t^{(k+1)}}, & a_{t^{(k+1)}})
=
\\
& C_{YLL}(x_{t^{(k+1)}},a_{t^{(k+1)}})
\\
+& C_{YLD}(x_{t^{(k+1)}},a_{t^{(k+1)}})
\\
+& C_{stock}(x_{t^{(k+1)}},a_{t^{(k+1)}})
\\
+& C_{campaign}(x_{t^{(k+1)}},a_{t^{(k+1)}})
\end{aligned}
J(x,\pi) = E\left[ \sum_{k=0}^M C(x_{t^{(k)}},a_{t^{(k)}}) | x_{t^{(0)}} = x , \pi \right]
\begin{aligned}
C(x_{t^{(k+1)}}, & a_{t^{(k+1)}})
=
\\
& C_{YLL}(x_{t^{(k+1)}},a_{t^{(k+1)}})
\\
+& C_{YLD}(x_{t^{(k+1)}},a_{t^{(k+1)}})
\\
+& C_{stock}(x_{t^{(k+1)}},a_{t^{(k+1)}})
\\
+& C_{campaign}(x_{t^{(k+1)}},a_{t^{(k+1)}})
\end{aligned}
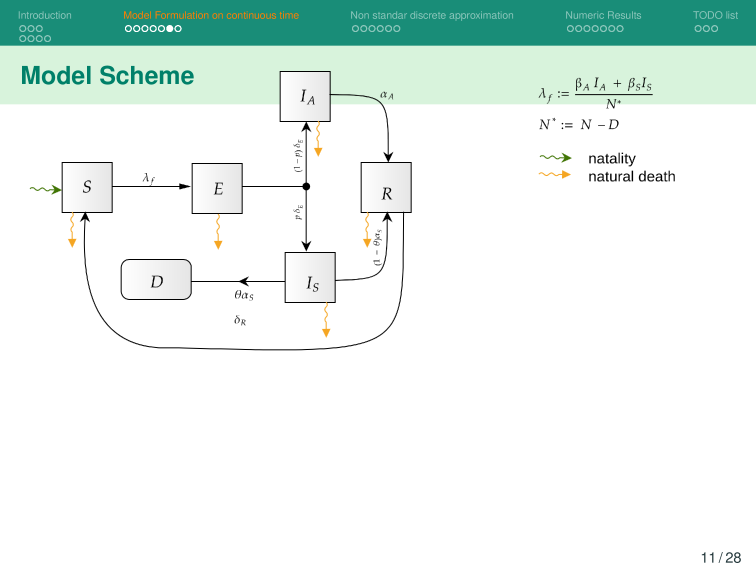
\begin{aligned}
C_{YLL}(x_{t^{(k+1)}},a_{t^{(k+1)}})
&=
\int_{t^{(k)}}^{t^{(k+1)}} YLL dt,
\\
C_{YLD}(x_{t^{(k+1)}},a_{t^{(k+1)}})
&=
\int_{t^{(k)}}^{t^{(k+1)}} YLD(x_t, a_t) dt
\\
YLL(x_t, a_t) &:=
m_1 p \delta_E (E(t) - E^{t^{(k)}} ),
\\
YLD(x_t, a_t) &:=
m_2 \theta \alpha_S(E(t) - E^{t^{(k)}}),
\\
t &\in [t^{(k)},t^{(k + 1)}]
\end{aligned}
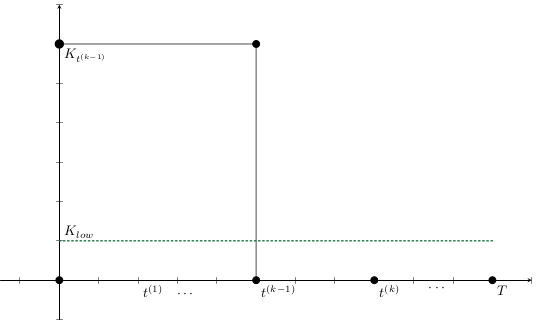
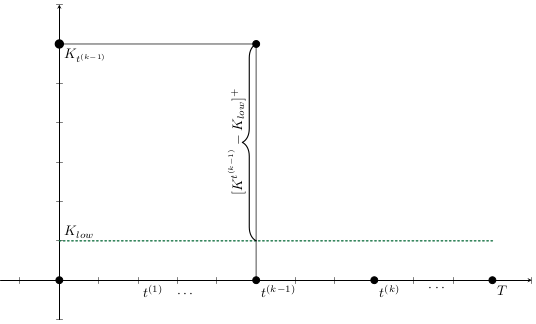
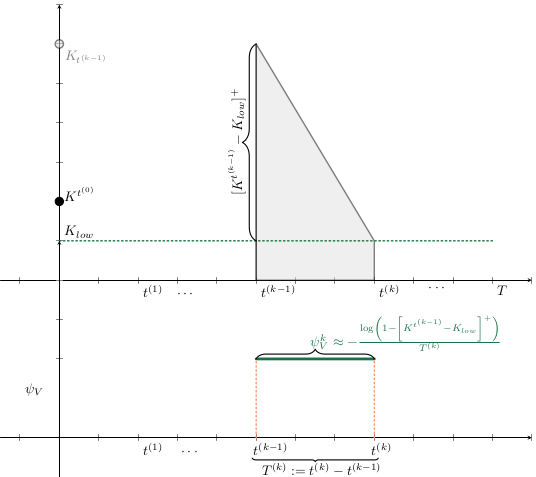
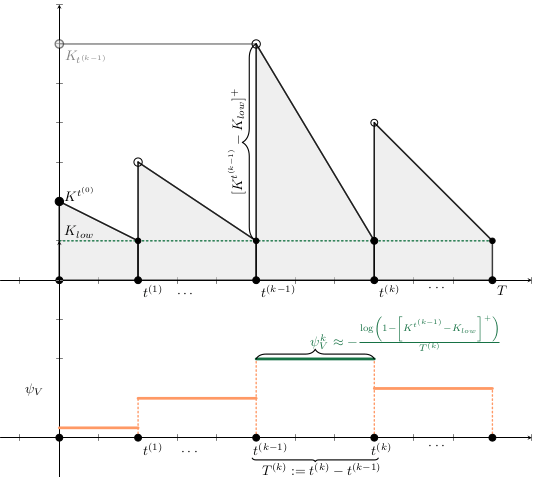
\begin{aligned}
C_{stock}(x_{t^{(k+1)}},a_{t^{(k+1)}})
& = \int_{t^{(k)}}^{t^{(k+1)}} m_3(K_{Vac}(t) - K_{Vac}^{t^{(k)}}) dt
\\
C_{campaign}(x_{t^{(k+1)}},a_{t^{(k+1)}})
&=\int_{t^{(k)}}^{t^{(k+1)}} m_4(X_{vac}(t) - X_{vac}^{t^{(k)}}) dt
\end{aligned}
\frac{dx_{t}}{dt} =f(x_{t} ,a_{t})
Agent
a_t\in \mathcal{A}
C_t
x_t
\begin{aligned}
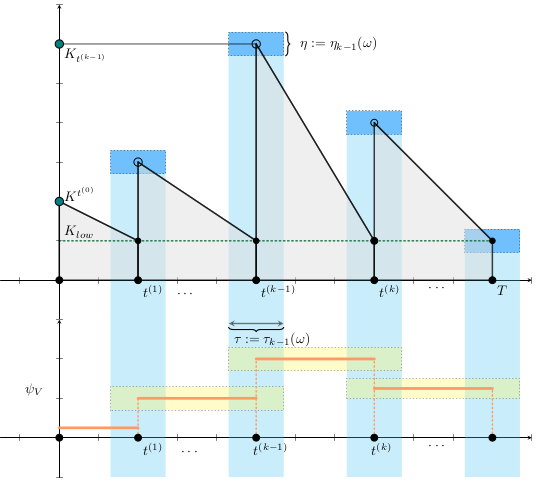
a_t^{(k)} &= p_i \cdot \Psi_V^{(k)}
\\
p_i &\in \mathcal{A}:=\{p_0, p_1, \dots, p_M\}
\\
p_i &\in [0, 1]
\end{aligned}
Deterministic Control
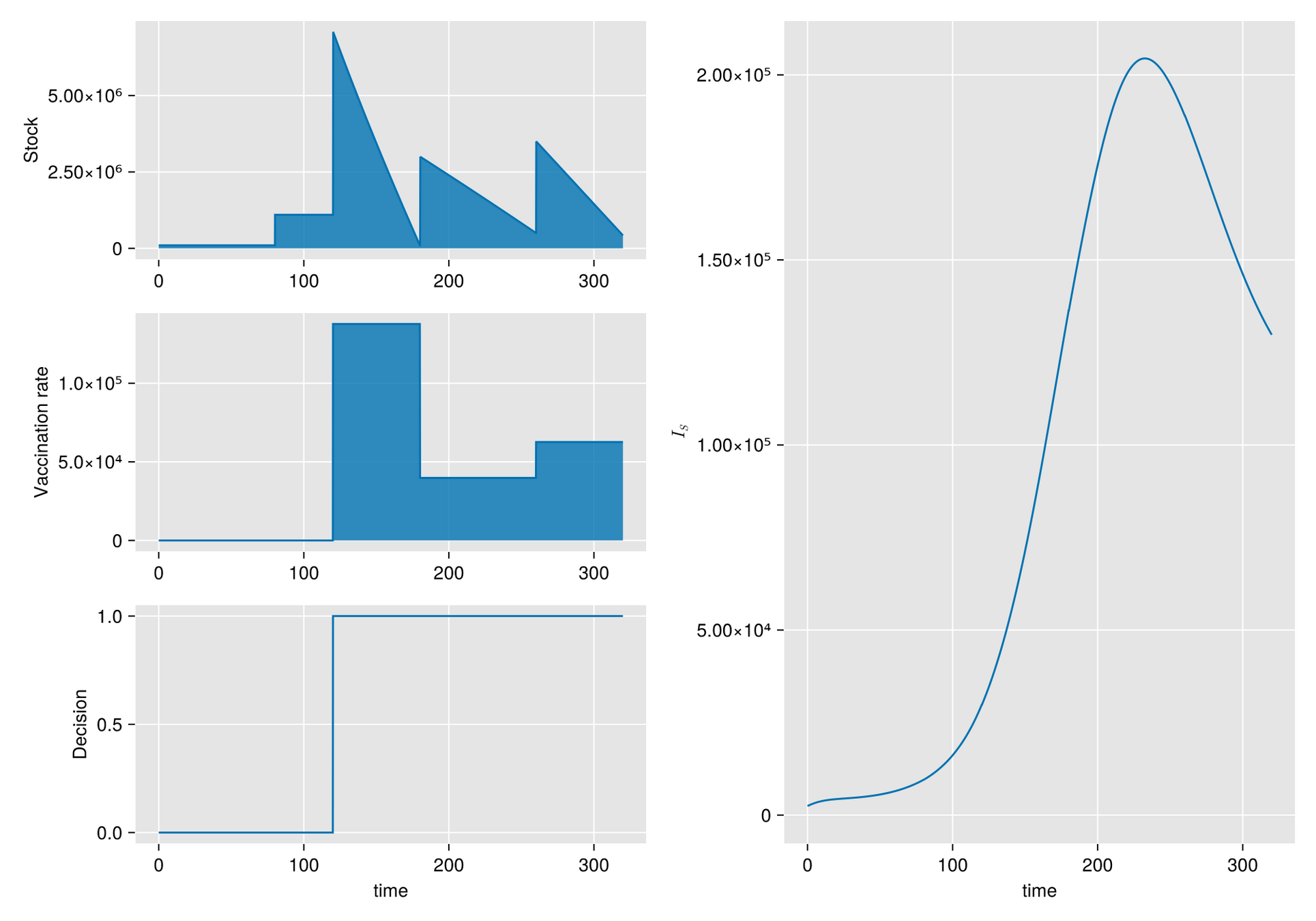
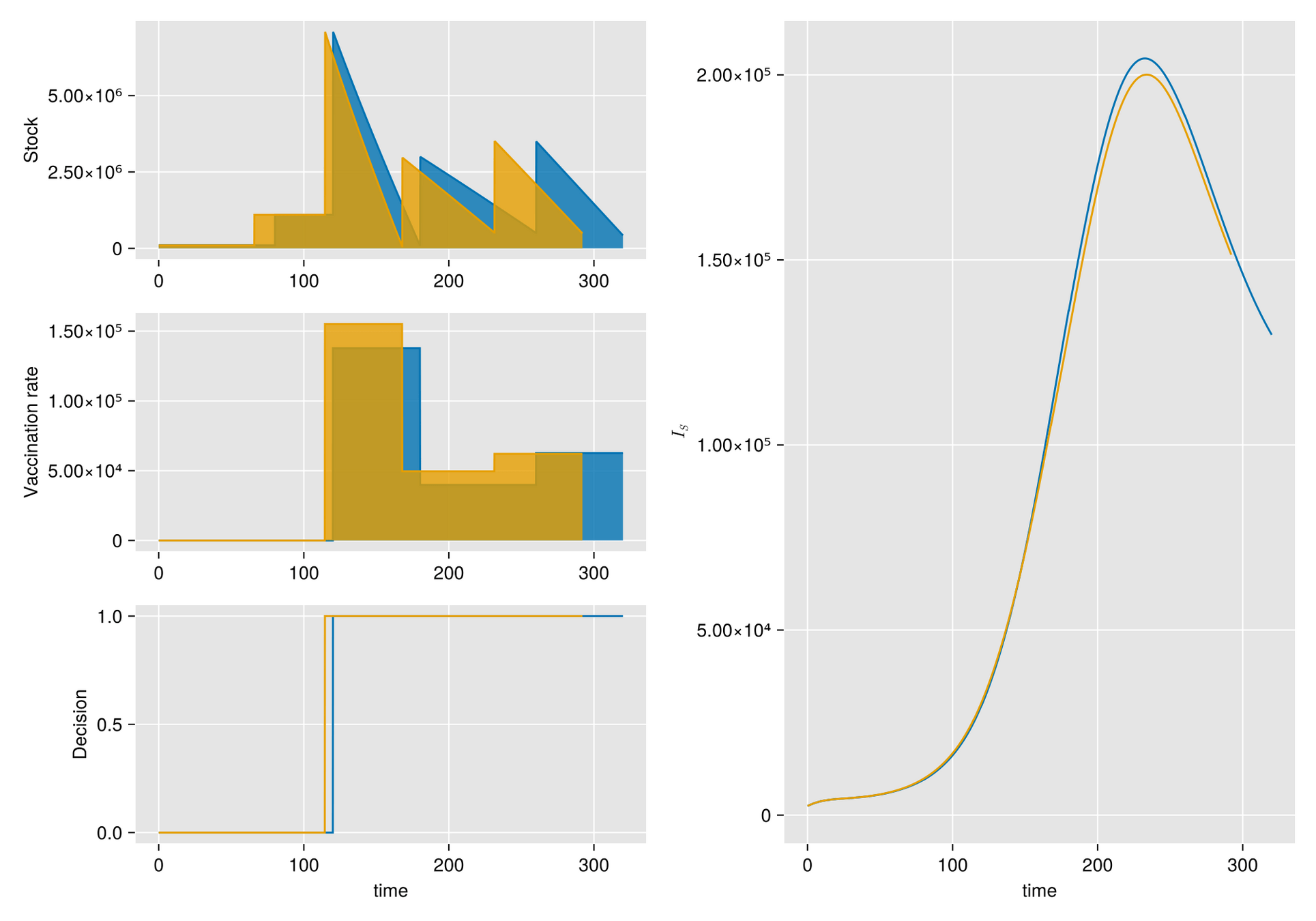
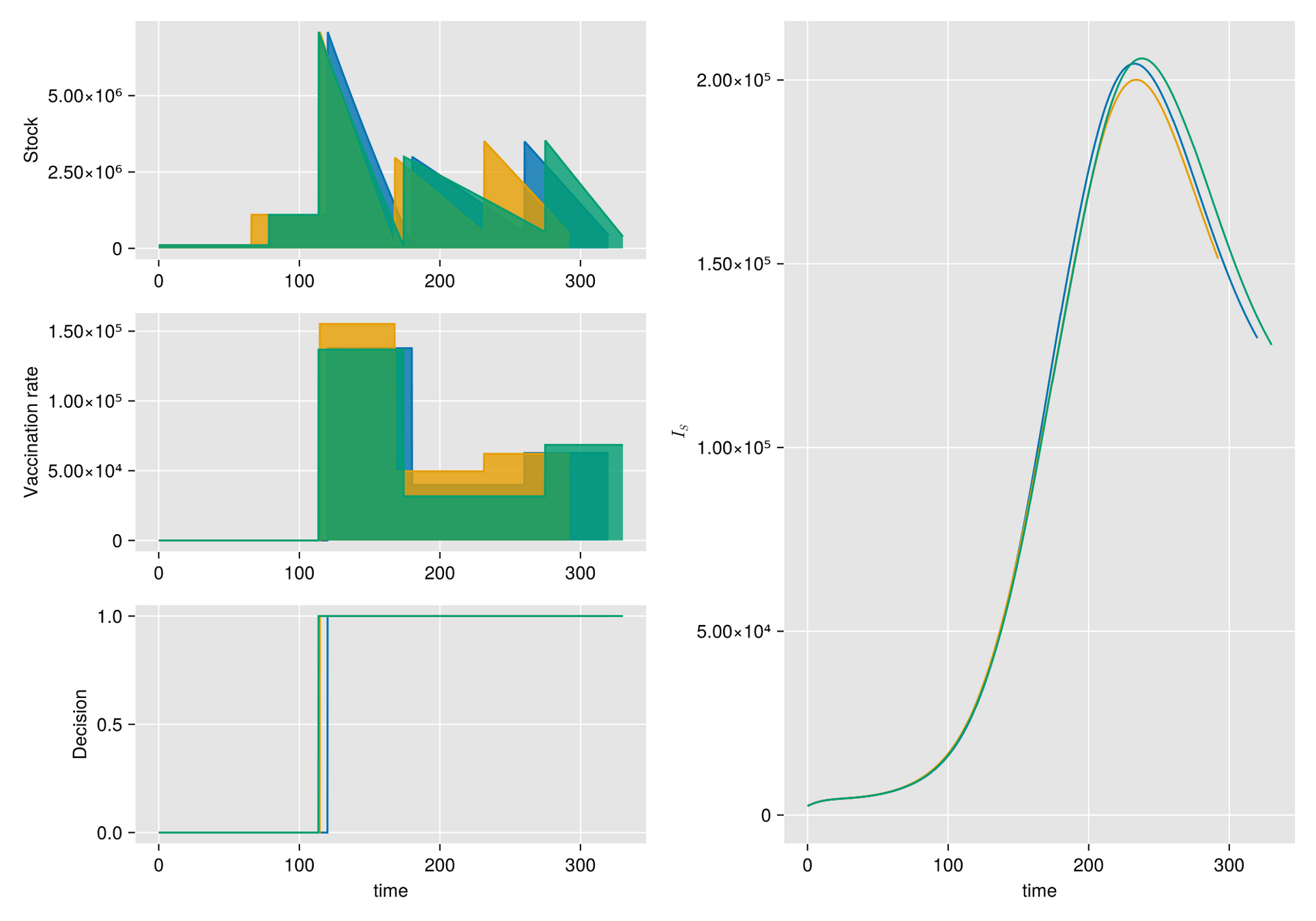
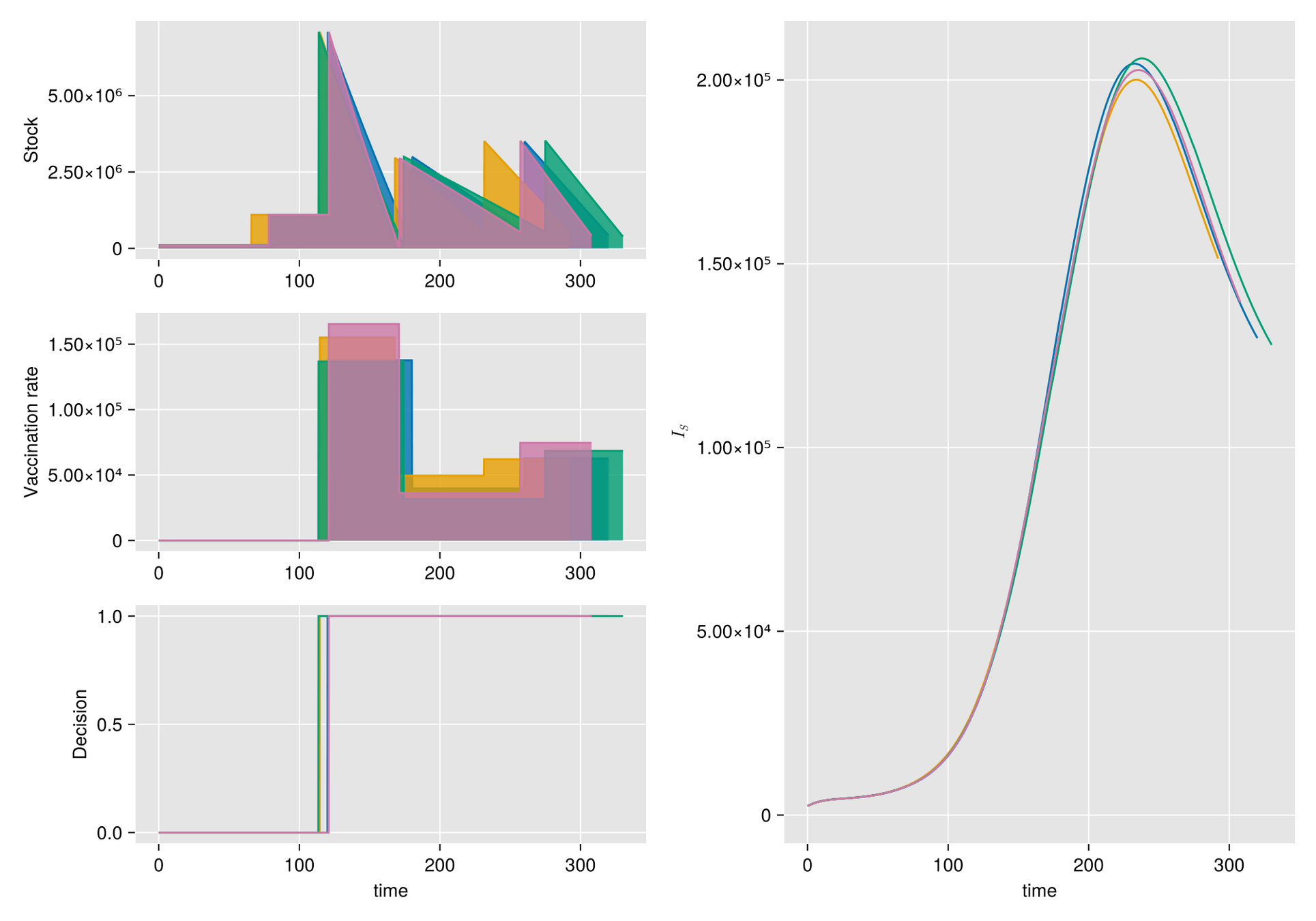
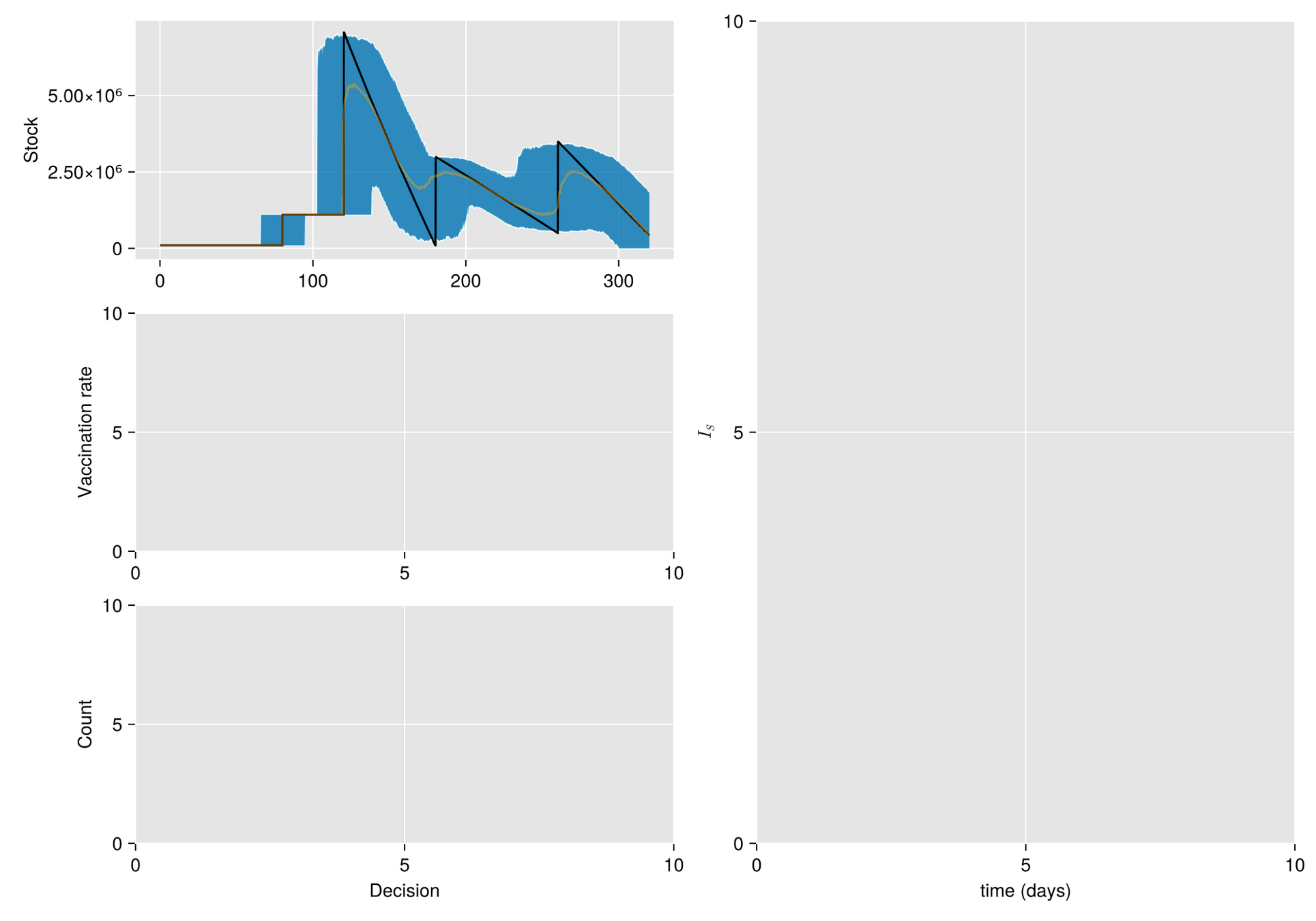
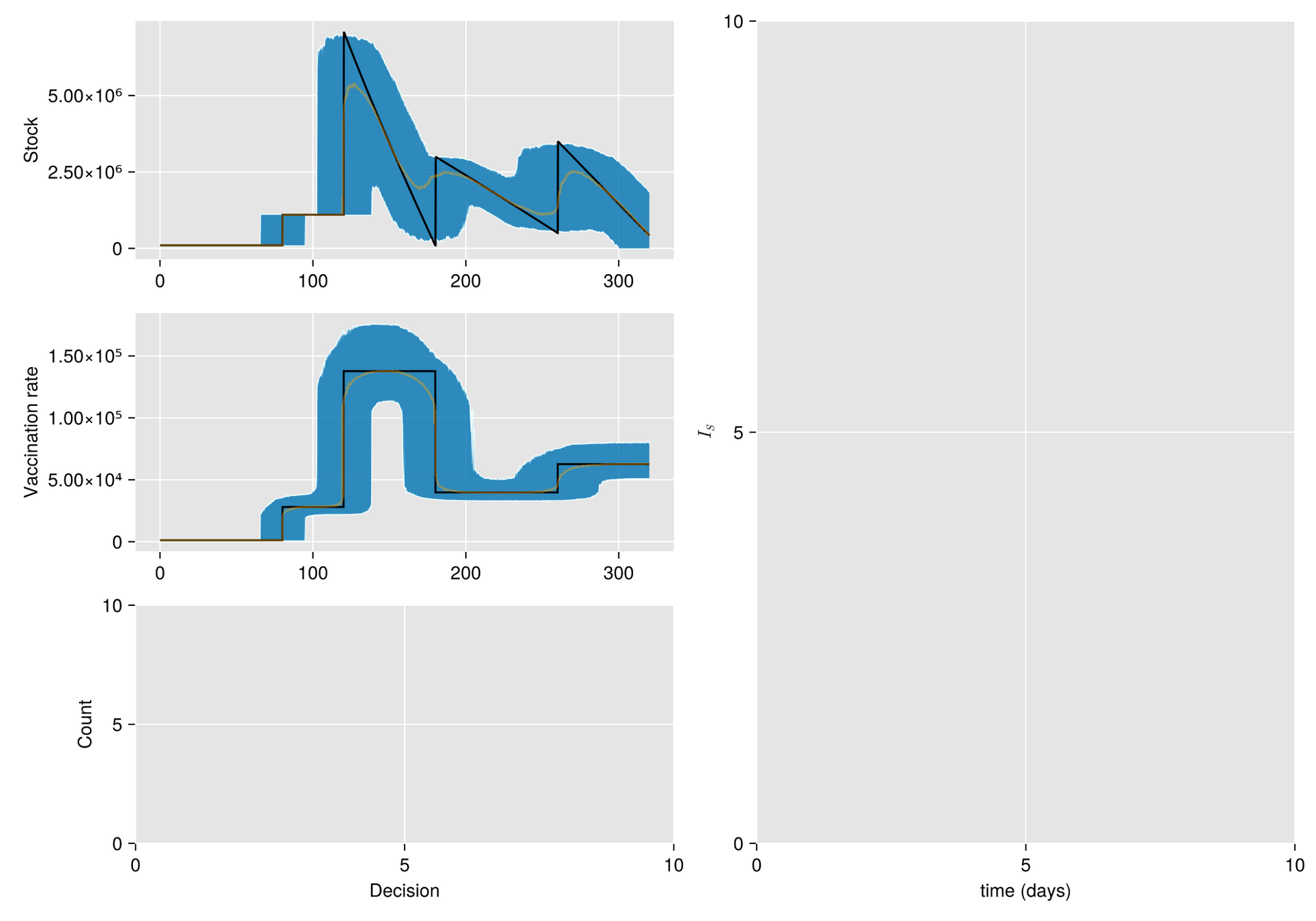
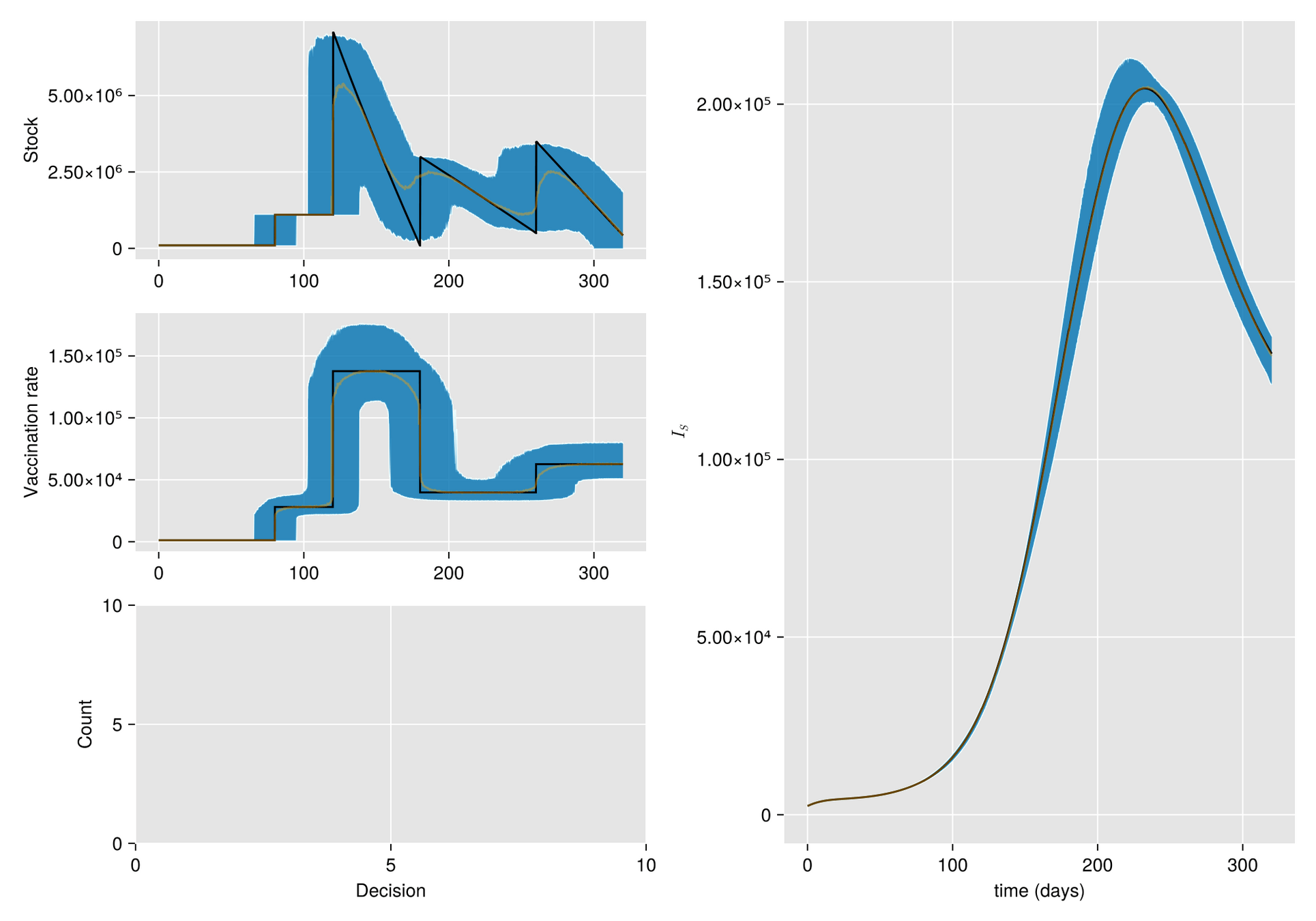
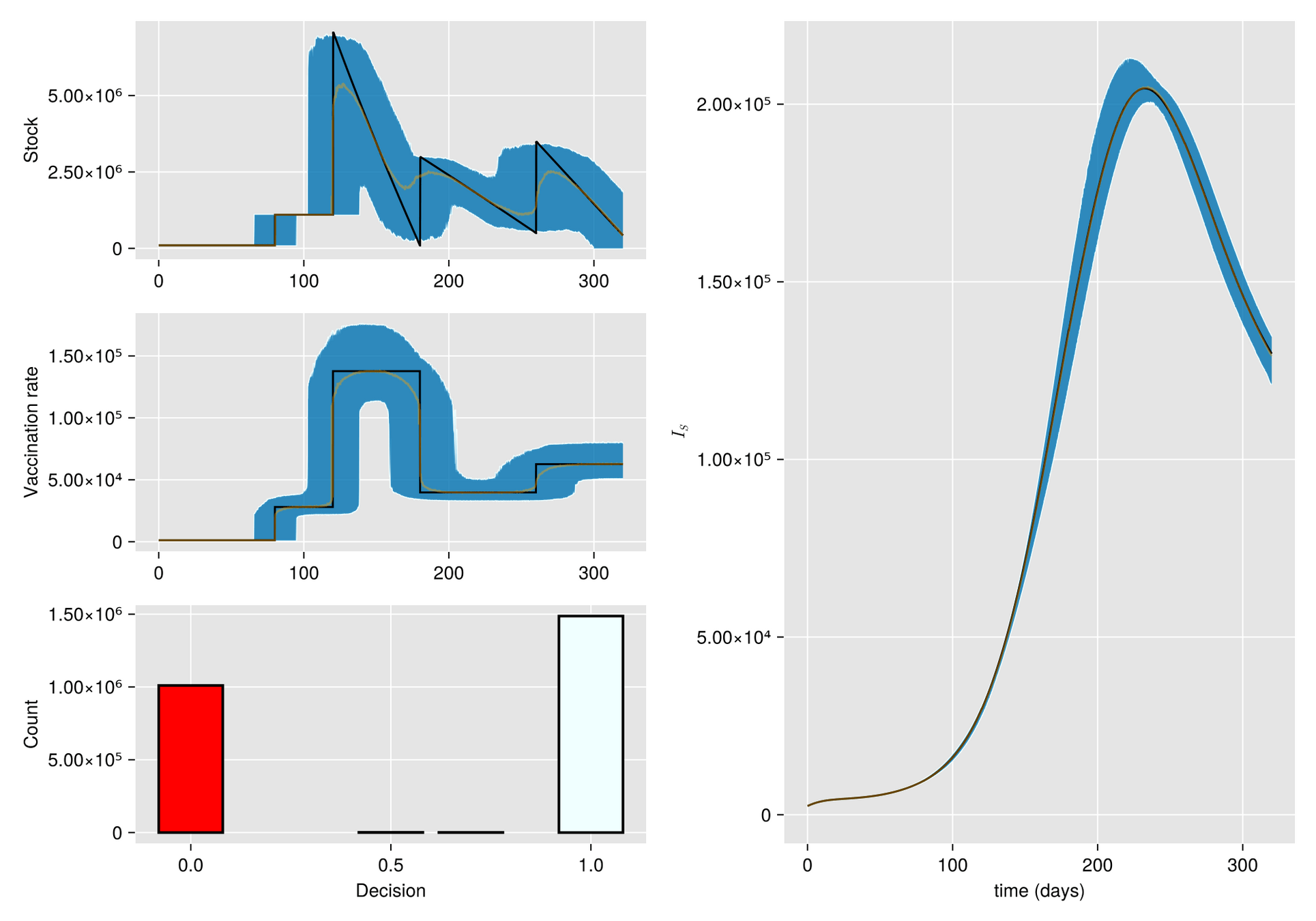

https://slides.com/sauldiazinfantevelasco/code-6bf335/fullscreen
Gracias!!

SMUQ-2024
By Saul Diaz Infante Velasco
SMUQ-2024
SMUQ-2024



