Pre-start


Announcements
- Office hours today 4ish-6ish BRC Cafe
- HW4 released --- you should be able to do all of it after today's lecture
- Perhaps Thursday if we don't finish GMMs today
- Final project type up just give me the week to finish writing it up and sharing data/paper links
Neural Signal Processing & Machine Learning
ELEC/BIOE 548 | ELEC 483
Fall 2022
Episode 19: Clustering Finale and Clusterless 👀


1
Introduction. Class & brains
2
Fundamental neurobiology. How do neurons fire? How/what do we record?
3
Modeling spike trains. First bit of analysis work and understanding firing properties of neurons.
5
Classification. Making machines learn. Which direction is a monkey trying to reach? Bayesian decoding.
4
Point processes. Continued modeling work of neurons.
6
Clustering/Mixture models. Making machines learn some more. Spike sorting.
Bi-weekly Schedule
7
Continuous decoding. Kalman filters. Machines continue to learn.
8
Spectral analysis? LFP interpretation in spectral domain. But also kinda in clustering.
Brain Signals!
-
How can we measure neural activity?
-
What info do neurons encode in trains of action potentials (“spike trains”)?
-
How can we model “statically” encoded information?
-
Estimation/”decoding”
-
Signal conditioning – “spike sorting” (PCA, Expectation-Maximization)
-
How can we model/decode “dynamic” information? (filtering, Kalman, HMM)
-
Beyond spike trains (LFP, EEG, imaging)
Recap: LFP Clustering

Recap: LFP Clustering
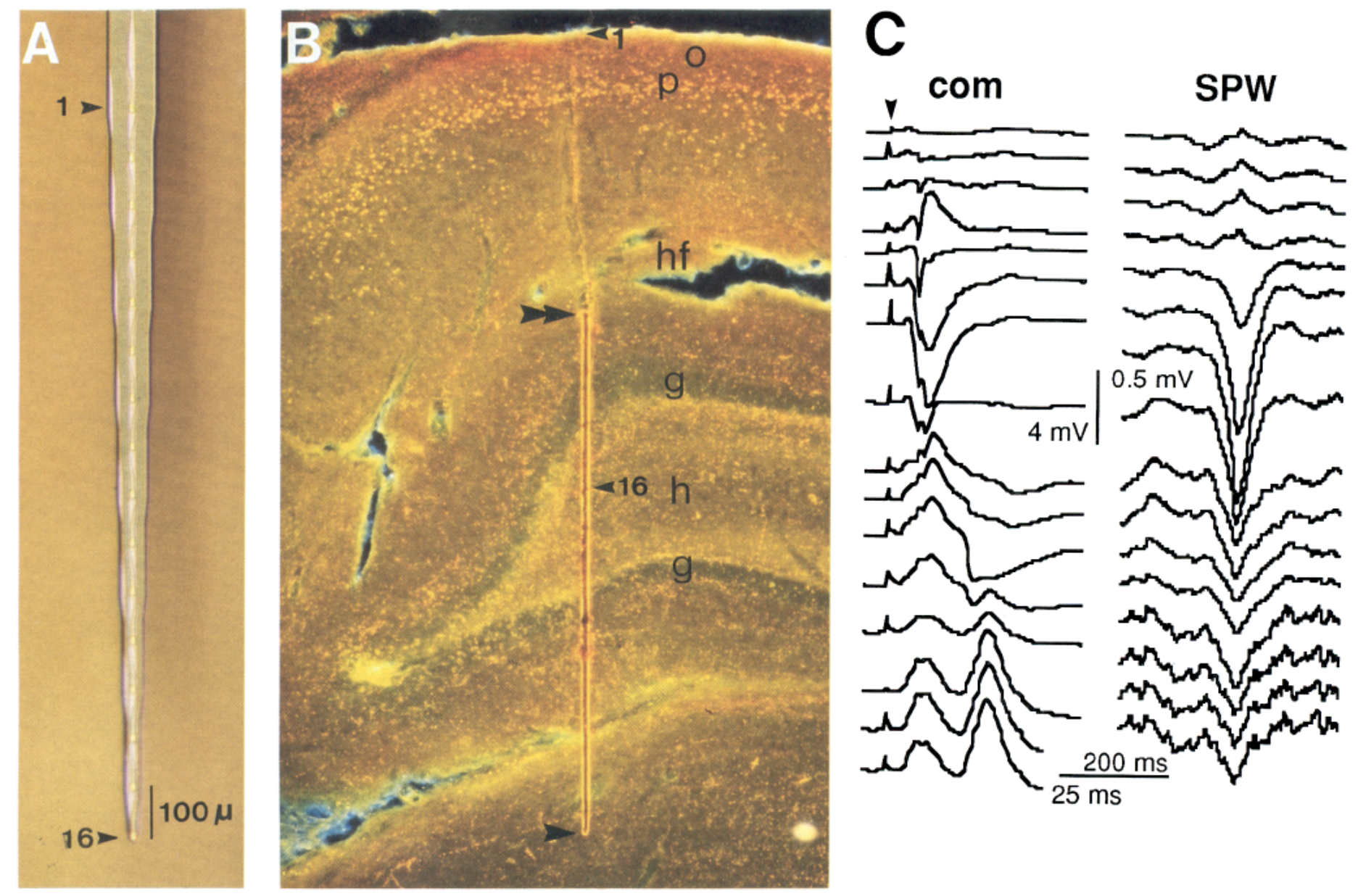
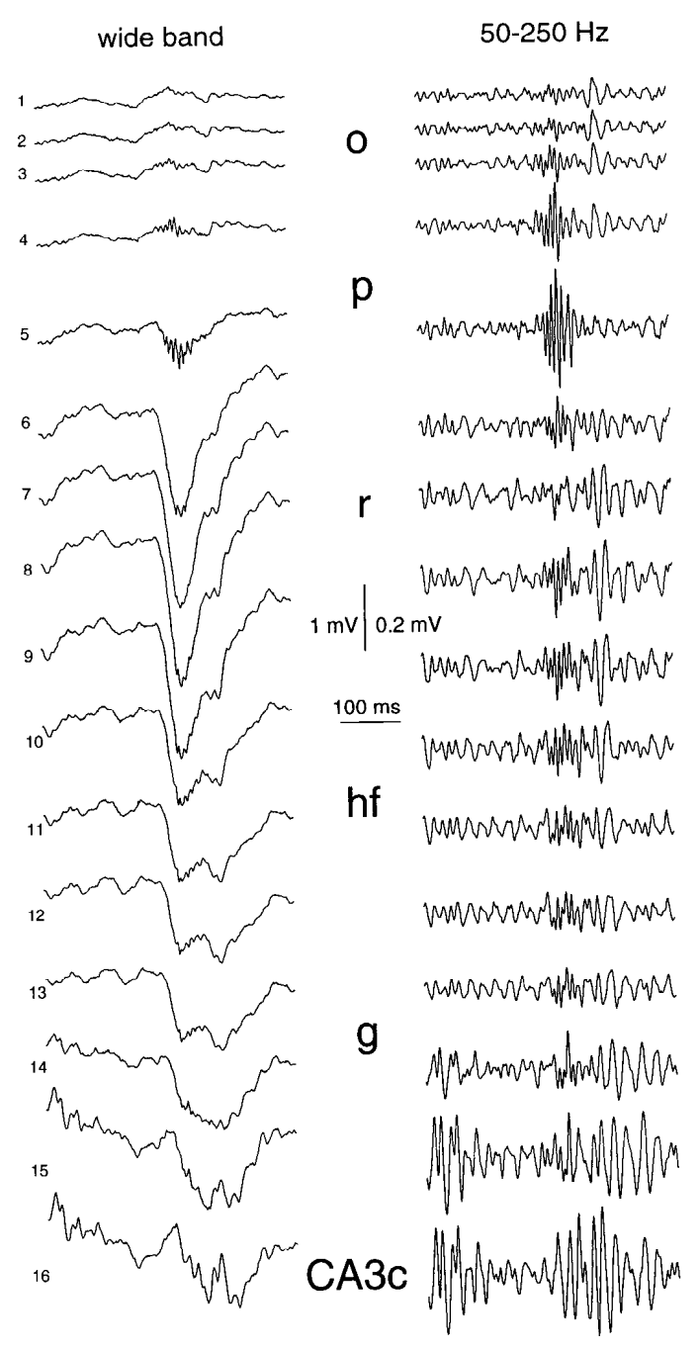
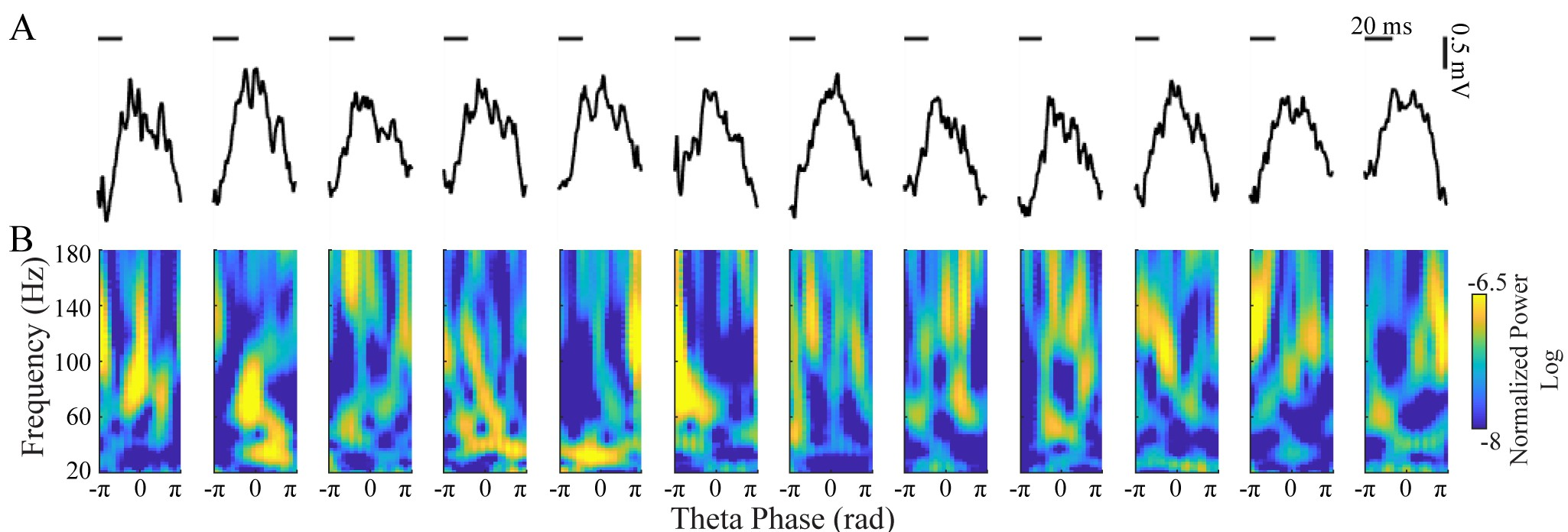
Recap: LFP Clustering
Please note that this problem is further detailed within the homework.

Recap: LFP Clustering
Clustering Math!
Recap K-Means
J = \sum_{n=1}^{N}\sum_{k=1}^{K}r_{n,k}||\mathbf{x}_n-\mathbf{\mu}_k||^2
r_{n,k}=
% \left\{
% \begin{array}
% 1, & \text{if }
% 0, & \text{otherwise}
\left\{
\begin{array}{ c l }
1 & \textrm{if } {\mathbf{x}_n} \textrm{belongs } \textrm{to } \textrm{the } \textit{k}^{th} \textrm{ cluster}\\
0 & \textrm{otherwise}
\end{array}
\right.
Clustering Math!
Expectation-Maximization


Iteration Number
After E-step 1
After M-step 1
Cost function decreases during K-Means
Clustering Application
Recap: Spike sorting

Raw data
30 kHz

Clustering Application
Recap: Spike sorting
Clustering Math!
K- Means Algorithm
J = \sum_{n=1}^{N}\sum_{k=1}^{K}r_{n,k}||\mathbf{x}_n-\mathbf{\mu}_k||^2
r_{n,k}=
% \left\{
% \begin{array}
% 1, & \text{if }
% 0, & \text{otherwise}
\left\{
\begin{array}{ c l }
1 & \textrm{if } {\mathbf{x}_n} \textrm{belongs } \textrm{to } \textrm{the } \textit{k}^{th} \textrm{ cluster}\\
0 & \textrm{otherwise}
\end{array}
\right.
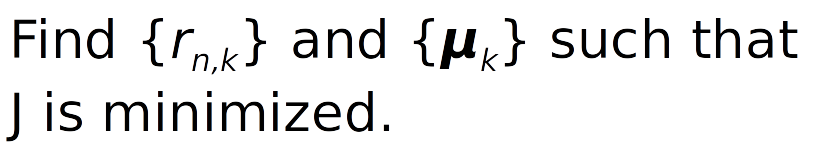
Iteration
- Choose {rn,k} such that J is minimized. Each n contributes independently to cost, so for each n, assign:
Formalization
- For each cluster, optimize parameters {μk}:
r_{n,k}=
% \left\{
% \begin{array}
% 1, & \text{if }
% 0, & \text{otherwise}
\left\{
\begin{array}{ c l }
1 & \textrm{if } k = \argmin_j||\mathbf{x}_n - \mathbf{\mu}_j||^2\\
0 & \textrm{otherwise}
\end{array}
\right.
Clustering Math!
K- Means Algorithm

- Define k
- Initialize centroids
- Calculate distance of each point from centriods
- Assign data points to corresponding centroids with minimal distance
- Update centroid location with some update rule
- Calculate mean of position of assigned data points
- Repeat steps 3--5
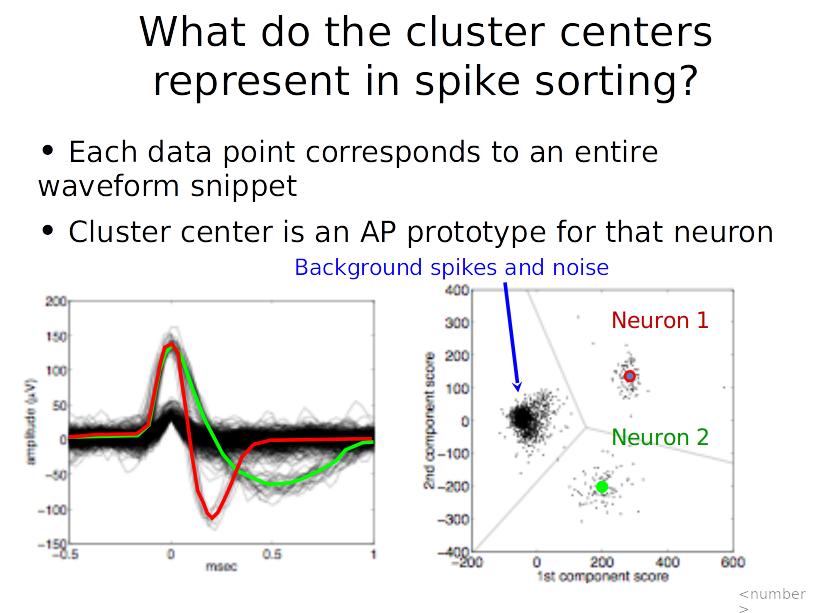
Drawbacks
- Hard assignments to clusters. What happens when a data point lies roughly midway between cluster centers?
- No easy way to determine the number of clusters K. We usually just go with the best we can that minimizes the number of data points that are "confusing"
So What Can We Do?
- Gaussian mixture models (GMMs)
- Soft assignments to clusters in a way that reflects a level of uncertainty of cluster assignment.
- An optimal K can be found from the data. This is made possible by the fact that the GMM is a probabilistic model.
Can We Do Anything Else?
💡 What if we take information from all the spikes? 💡
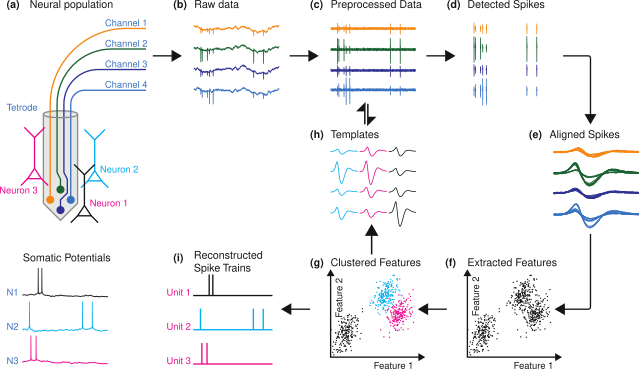
- Dependent on accuracy of spike sorting
- Discarding information from non-clustered spikes
- Spike sorting is not conducive to realtime analysis
Bayesian Decoding Limitations


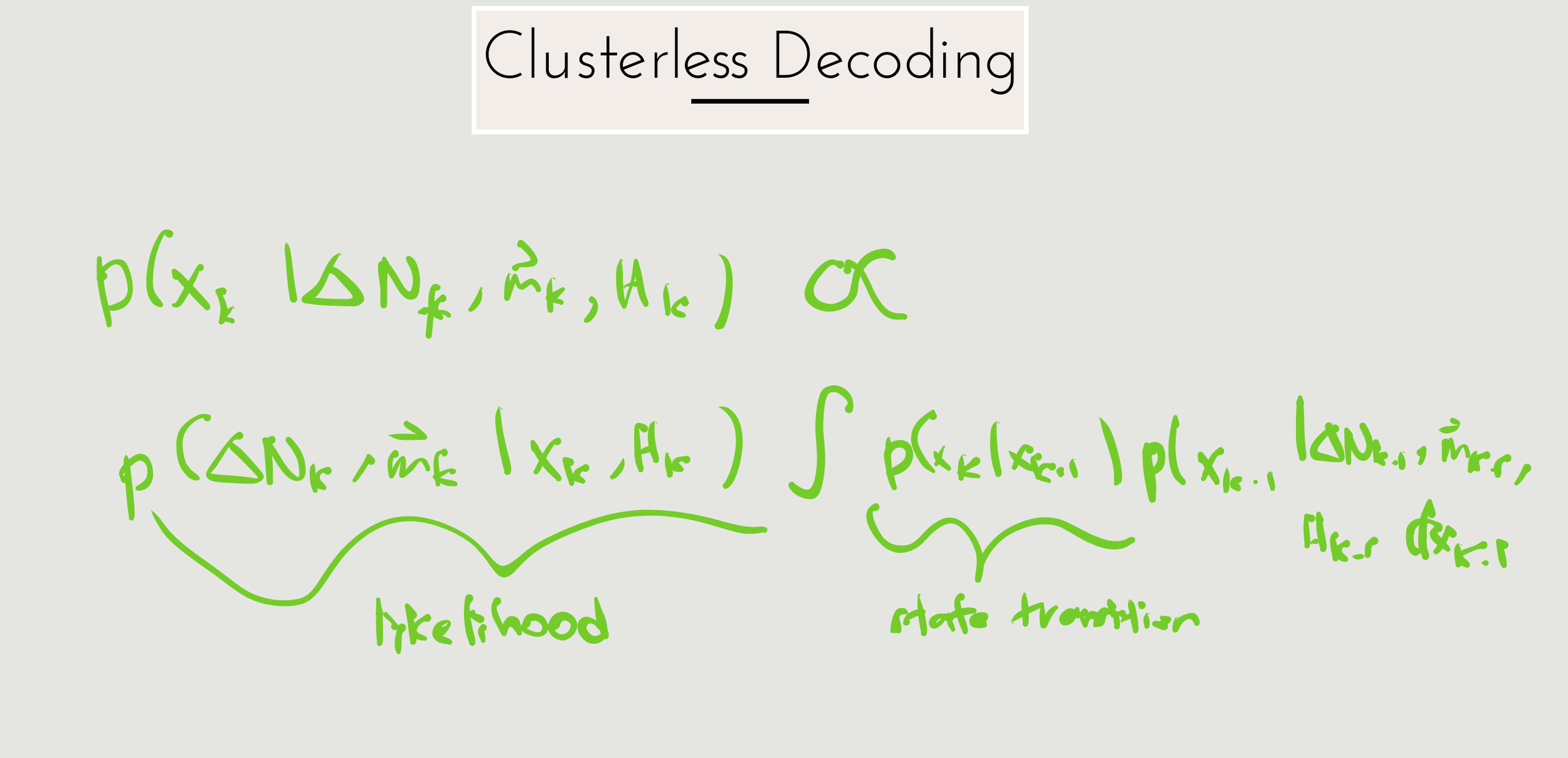
Clusterless Decoding
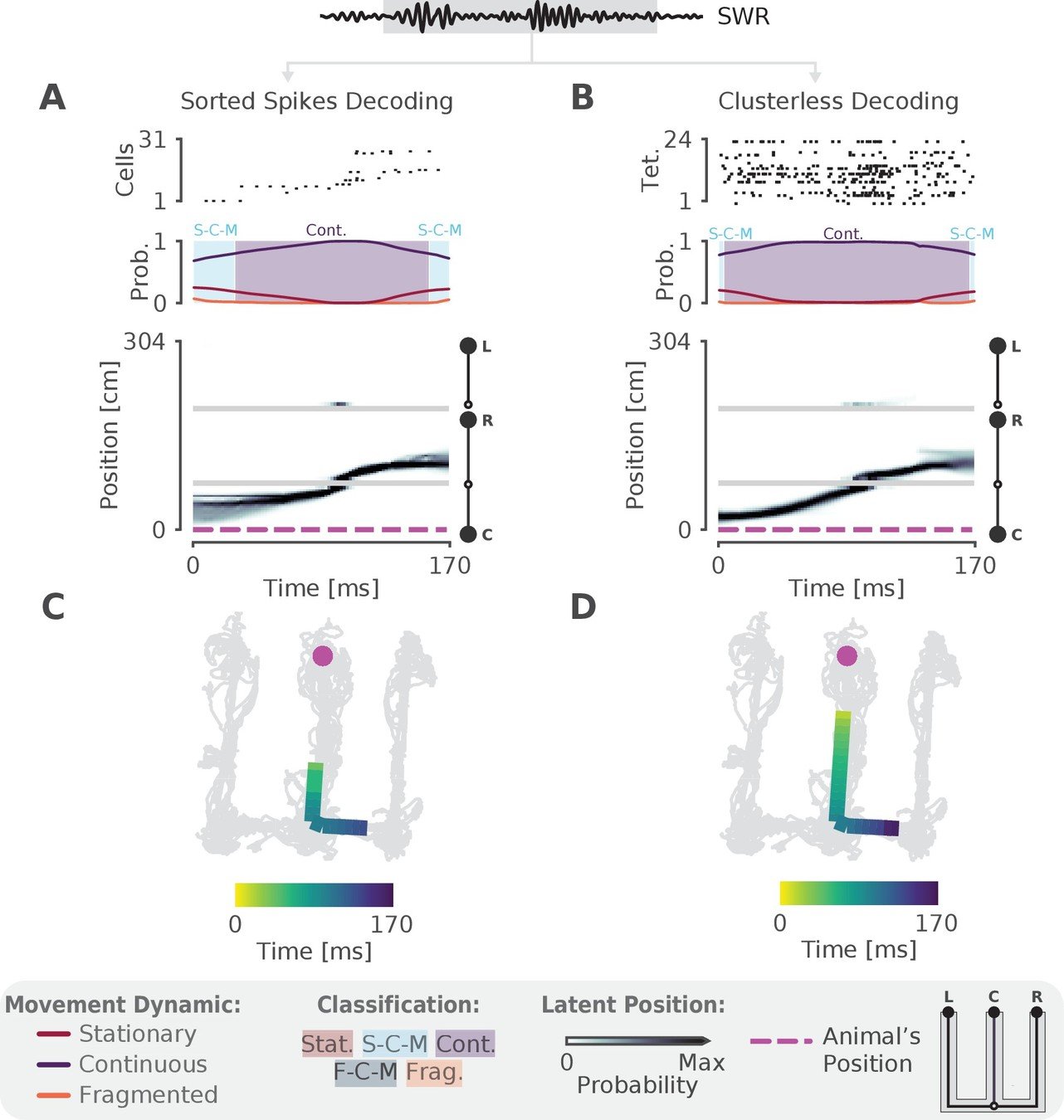
Denovellis, eLife, 2021

ELEC548 Lec19
By Shayok Dutta




