6.7900 Machine Learning (Fall 2023)
Lecture 24:
(Some) Recent ML trends/applications
Shen Shen
December 12, 2023


Notable trends lately
(in CV and NLP)
- Self-supervision
- Scaling up
- Multi-modality
- Transformer-based architecture stack
- Diffusion-based generative algorithms
Self-supervision (masking)
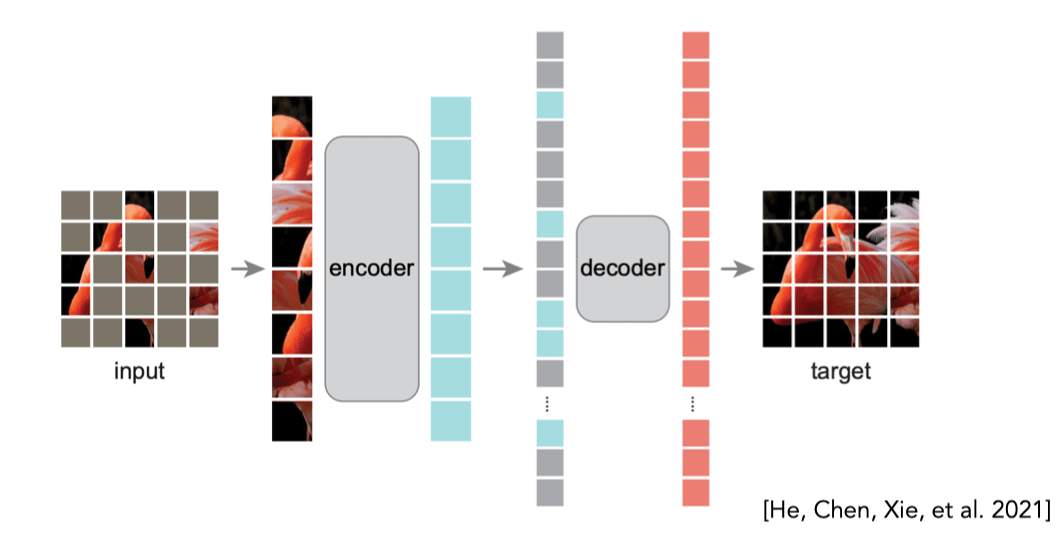
It seems
It seems
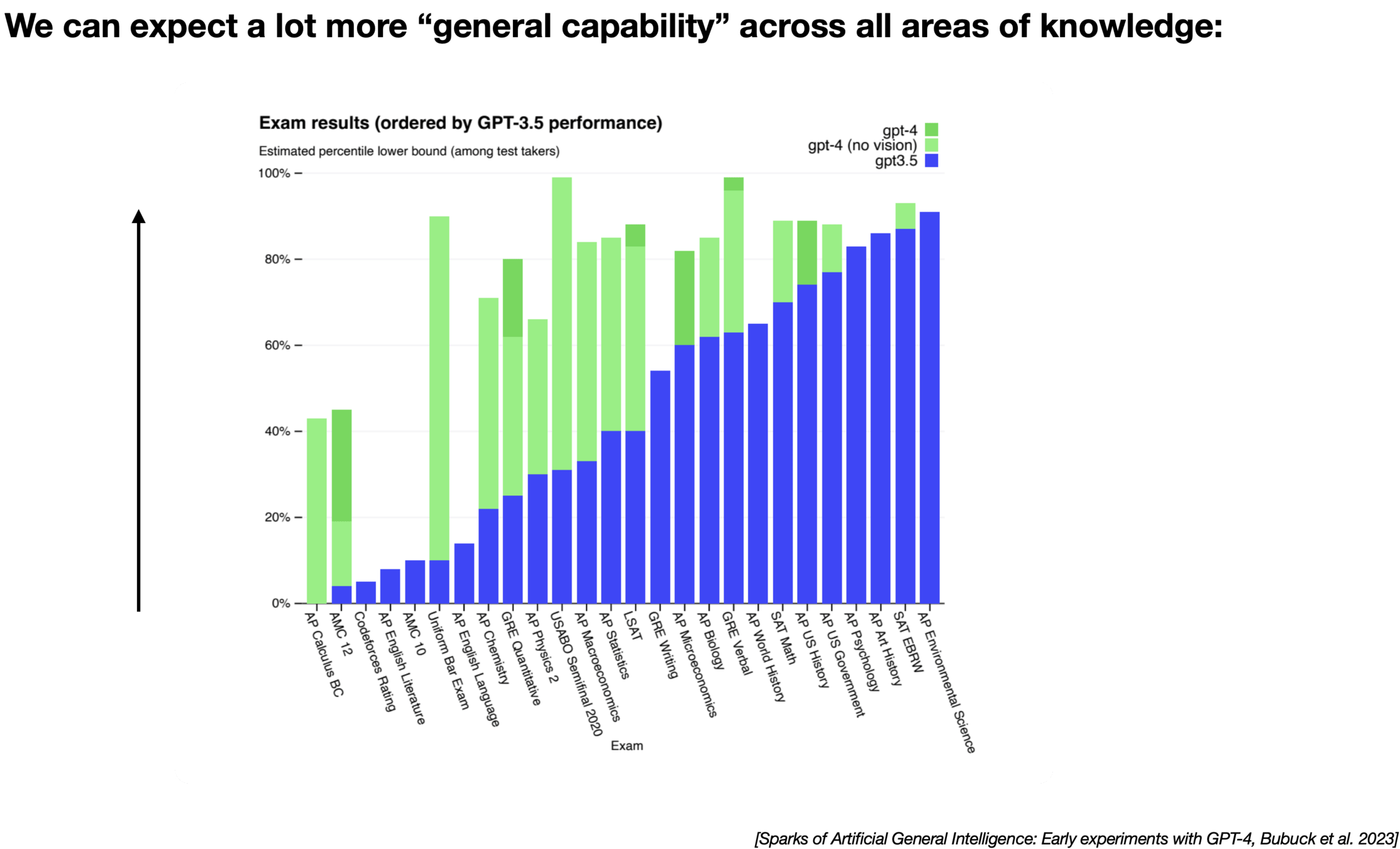
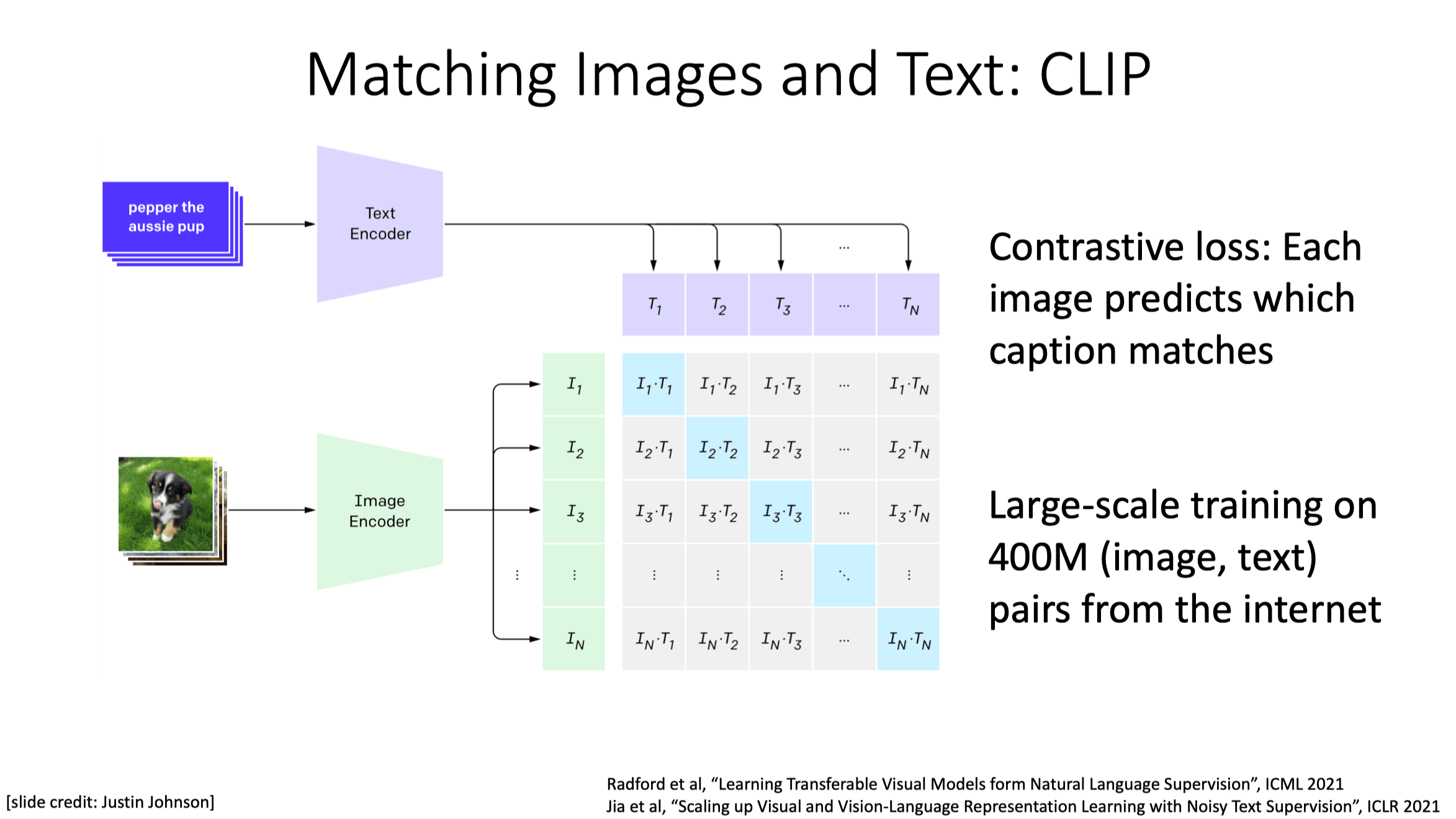
Multi-modality
Diffusion/score-based
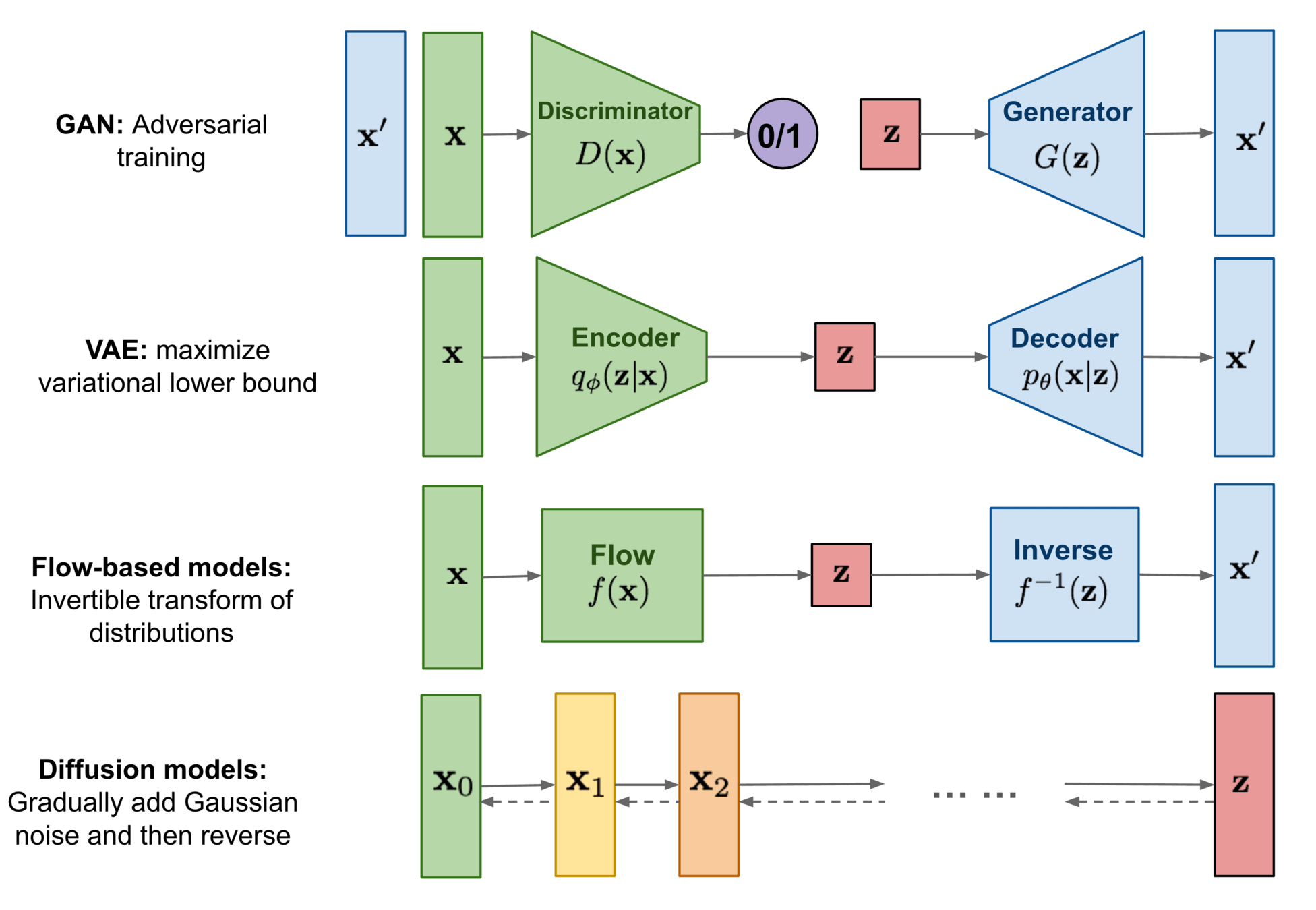
[image credit: Lilian Weng]
Dall-E 2 (UnCLIP): CLIP + GLIDE
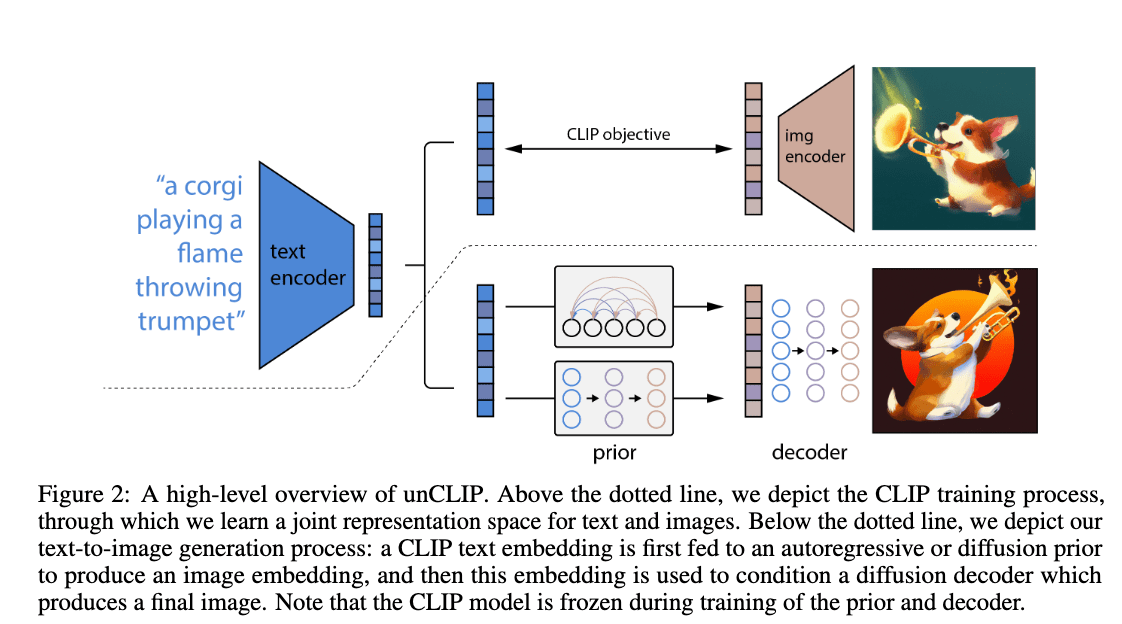
[https://arxiv.org/pdf/2204.06125.pdf]
Outline Today
Part 1: Some echoing trends in Robotics
Part 3: Some more domain-specific applications
- Engineering
- Natural sciences (e.g. life sciences, health care)
- Math, algorithms
- Social sciences (e.g. political, ethical impact)
Part 2: Some future directions in CV/NLP/Robotics
Part 1: Robotics
Lots of slides adapted from
2004 - Uses vanilla policy gradient (actor-critic)
uses first-principle (modeling, control, optimization stack)
For the next challenge:
Good control when we don't have useful models?

For the next challenge:
Good control when we don't have useful models?
- Rules out:
- (Multibody) Simulation
- Simulation-based reinforcement learning (RL)
- State estimation / model-based control
- Some top choices:
- Learn a dynamics model
- Behavior cloning (imitation learning)
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
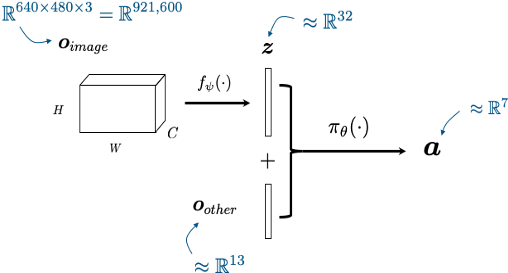
Visuomotor policies
perception network
(often pre-trained)
policy network
other robot sensors
learned state representation
actions
x history

manipulation (and general control) is hard because?
partially because the data is scarce


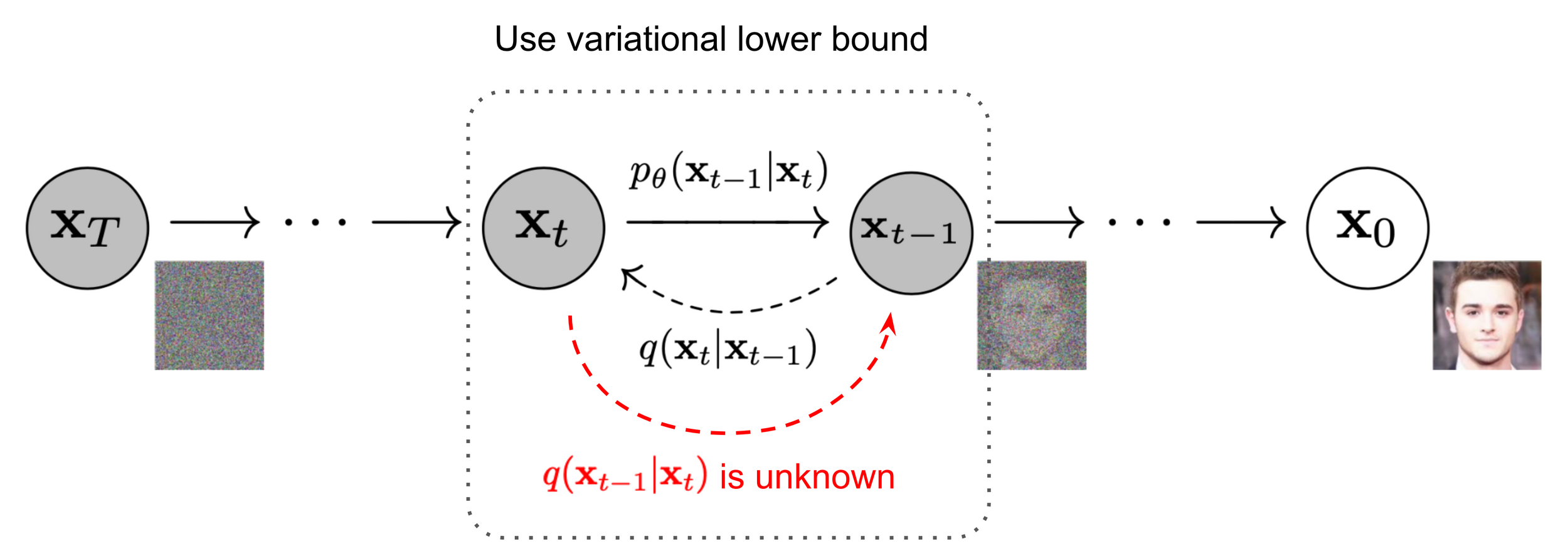
Denoising diffusion models
(for actions)
Image source: Ho et al. 2020
Denoiser can be conditioned on additional inputs, \(u\): \(p_\theta(x_{t-1} | x_t, u) \)
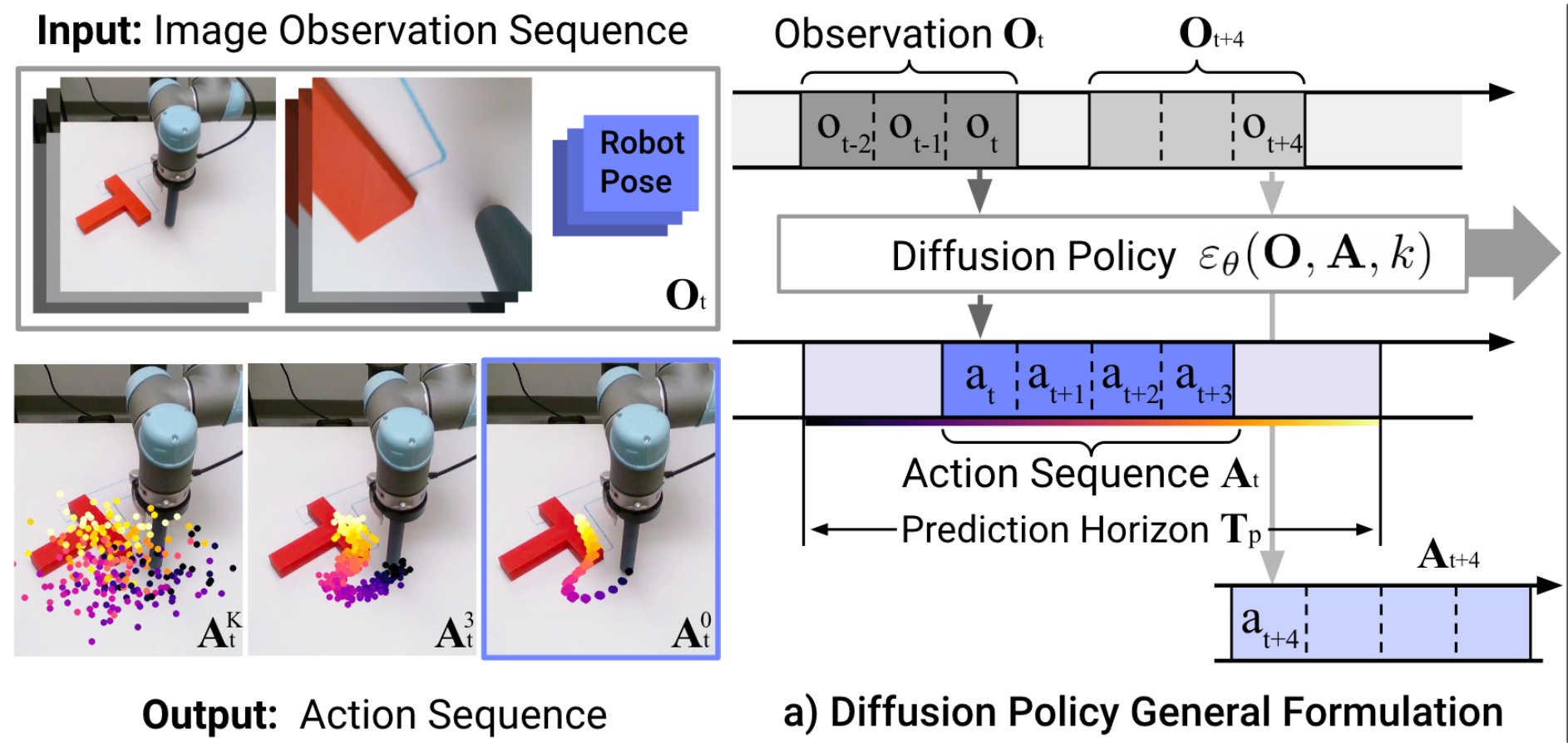
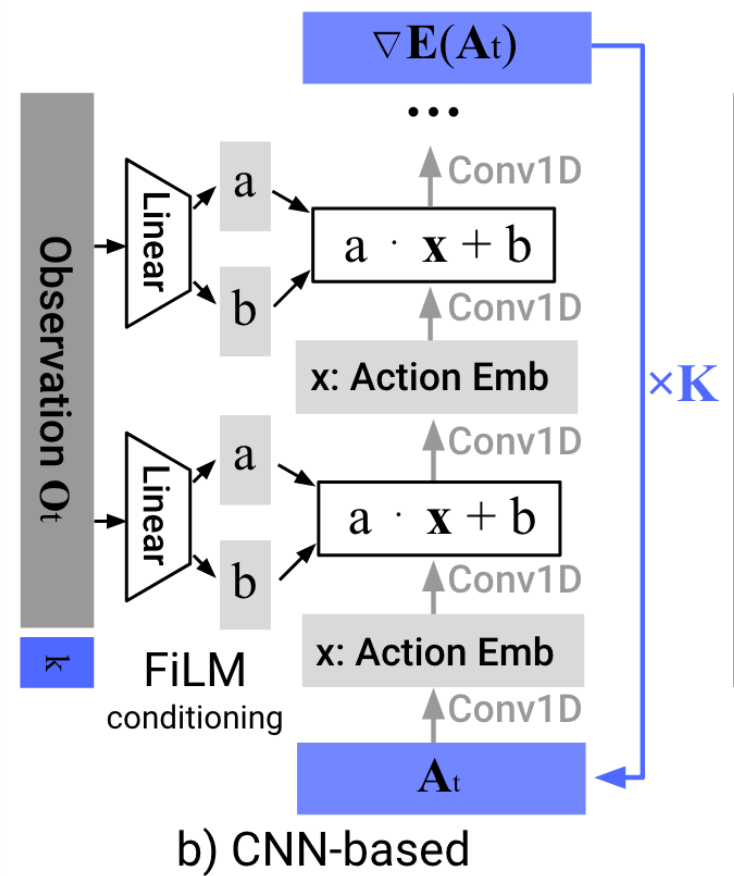
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)

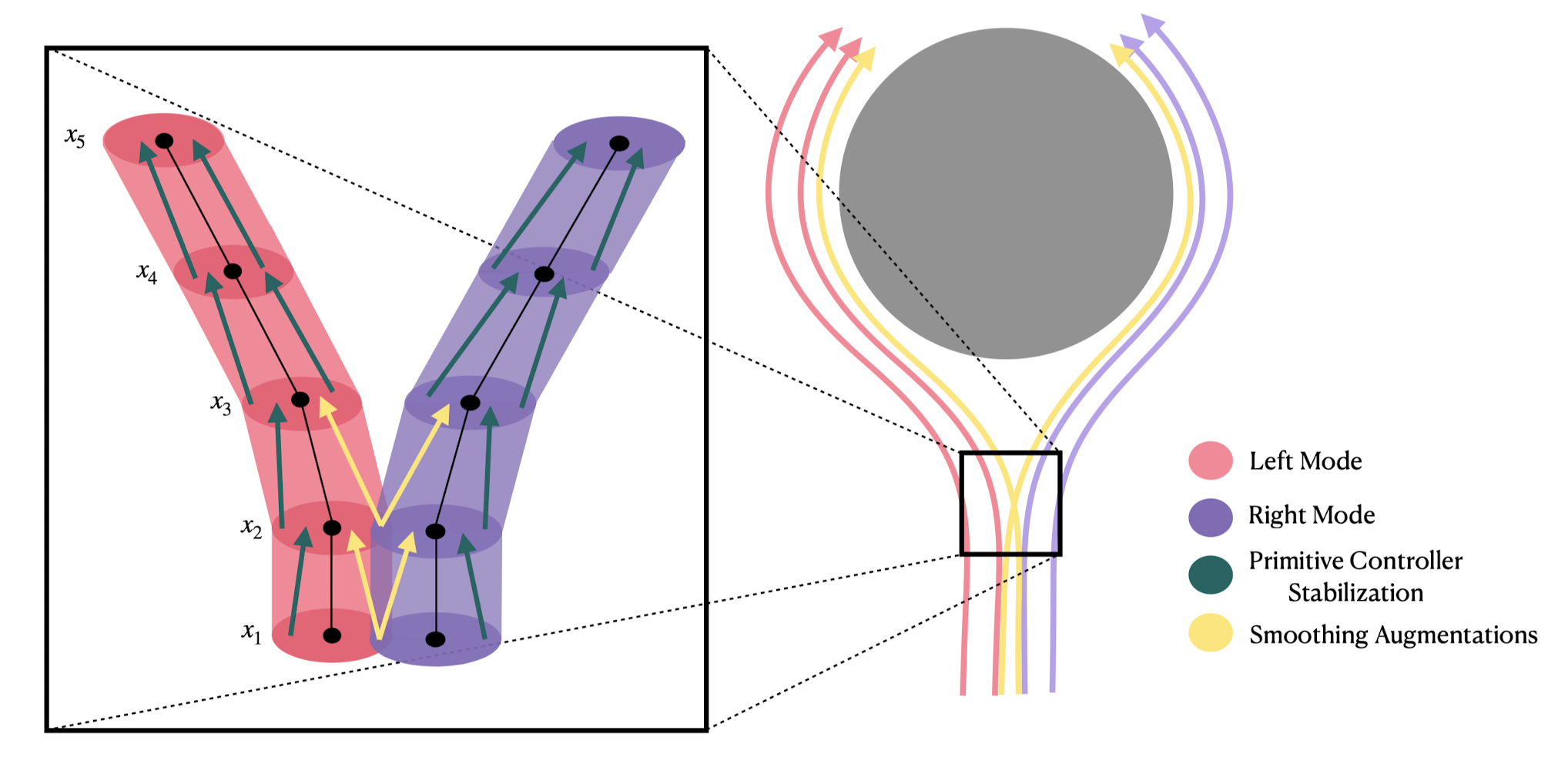
Why (Denoising) Diffusion Models?
- High capacity + great performance
- Small number of demonstrations (typically ~50)
- Multi-modal (non-expert) demonstrations
- Training stability and consistency
- no hyper-parameter tuning
- Generates high-dimension continuous outputs
- vs categorical distributions (e.g. RT-1, RT-2)
- Action-chunking transformers (ACT)
- Solid mathematical foundations (score functions)
- Reduces nicely to the simple cases (e.g. LQG / Youla)
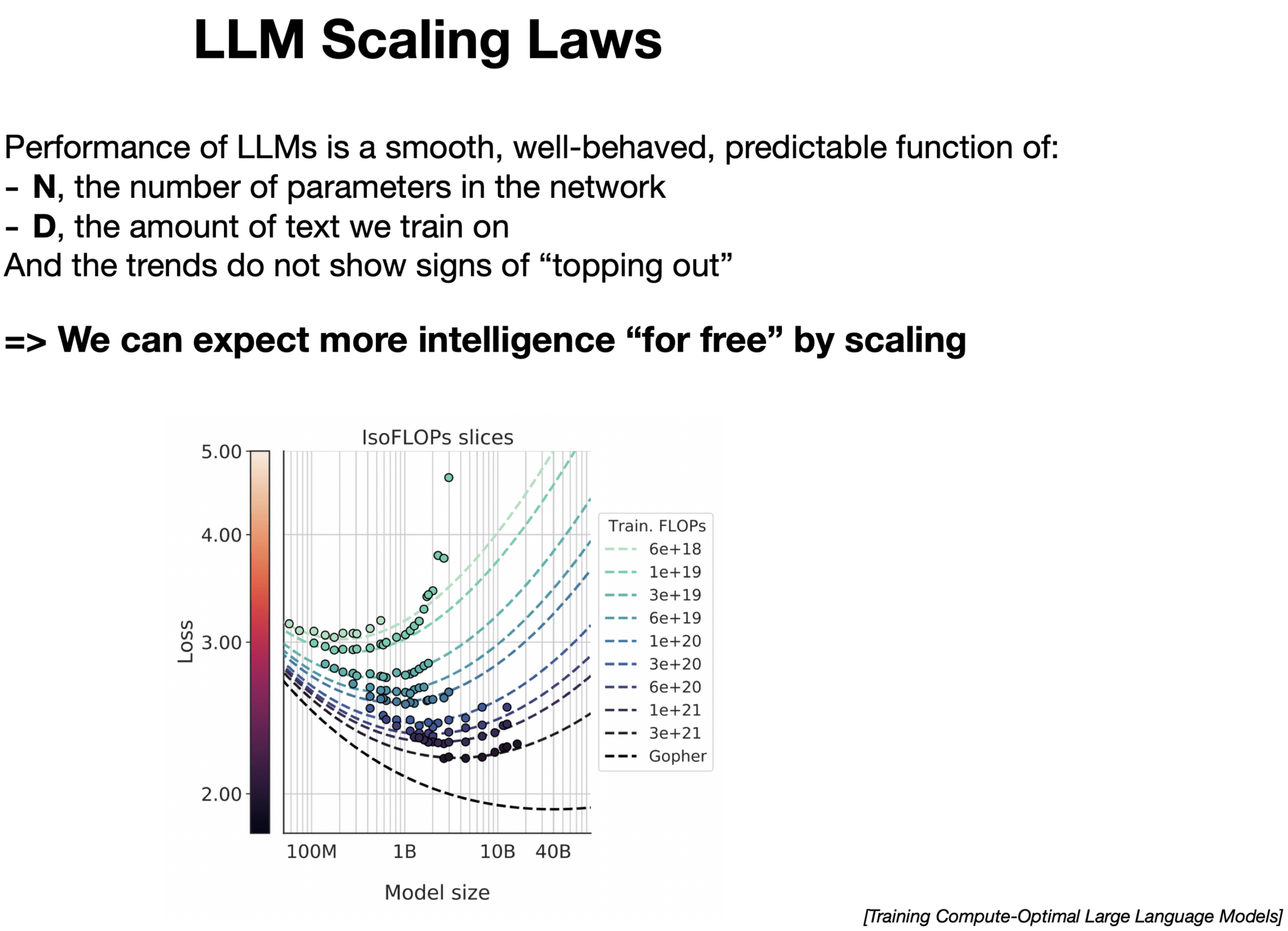
Scaling Up
- We've discussed training one skill
-
Wanted: few shot generalization to new skills
- multitask, language-conditioned policies
- connects beautifully to internet-scale data
-
Big Questions:
- How do we feed the data flywheel?
- What are the scaling laws?
Discussion
I do think there is something deep happening here...
- Manipulation should be easy (from a controls perspective)
- probably low dimensional?? (manifold hypothesis)
- memorization can go a long way
If we really understand this, can we do the same via principles from a model? Or will control go the way of computer vision and language?
Discussion
What if we did have a good model? (and well-specified objective)
- Core challenges:
- Control from pixels
- Control through contact
- Optimizing rich robustness objective
- The most effective approach today:
- RL on privileged information + teacher-student
Deep RL + Teacher-Student


Lee et al., Learning quadrupedal locomotion over challenging terrain, Science Robotics, 2020

Deep RL + Teacher-student
Magic of Modality
- Modality = image, video, 3d mesh, text etc.
- One recipe (motivated by data):
- Use discriminative model on data-rich domain to guide training in data-scarce domains
- Use generative model on data-rich domains to synthesize data for data-scarce domains
Task Planning with LLM
Connect unstructured world with structured algorithms
What humans would want:
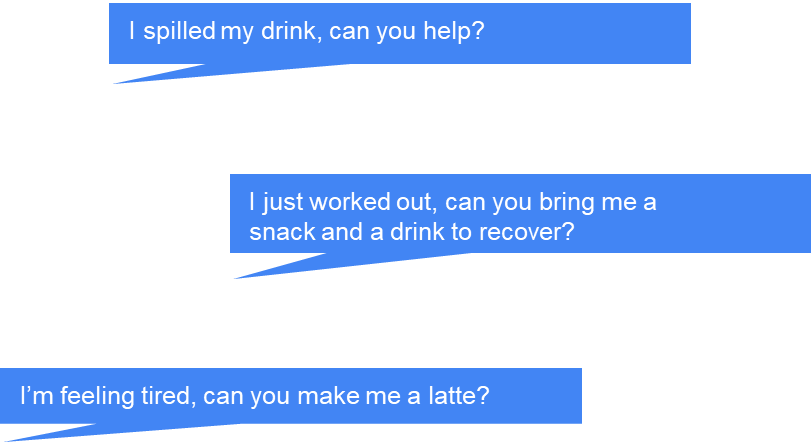
Task: clean up the spilled coke
- Set the coke can into an upright position
- Find some napkins
- Pick up napkins
- Wipe the spilled coke with napkins
- Wipe the coke can
- Throw away the used napkins
Humans: Language as tasks
Language as plans!
Can we use human priors & knowledges
It turns out humans activities on the internet produces a massive amount of knowledge in the form of text that are really useful!

Highlight
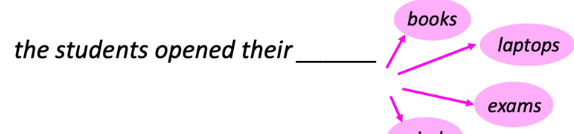
- Given a fixed list of options, can evaluate likelihood with LM
- Given all vocabularies, can sample with likelihood to generate
Ingredient 1
- Bind each executable skill to some text options
- Have a list of text options for LM to choose from
- Given instruction, choose the most likely one

Ingredient 2
- Prompt LLM to output in a more structured way
- Parse the structure output
Few-shot prompting of Large Language Models

LLMs can copy the logic and extrapolate it!
Prompt Large Language Models to do structured planning


Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, Ahn et al. , 2022
LLMs for robotics
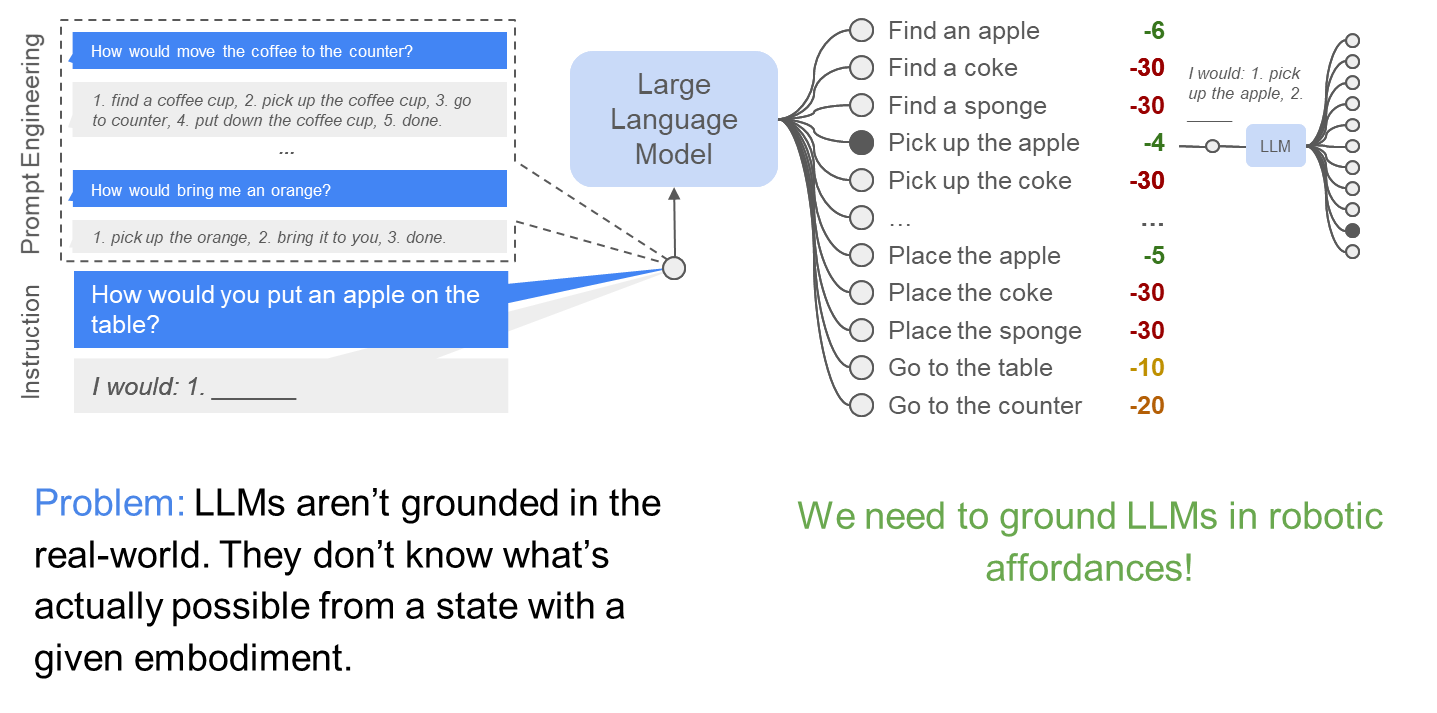
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, Ahn et al. , 2022

What task-based affordances reminds us of in MDP/RL?
Value functions!
[Value Function Spaces, Shah, Xu, Lu, Xiao, Toshev, Levine, Ichter, ICLR 2022]
Robotic affordances
Combine LLM and Affordance
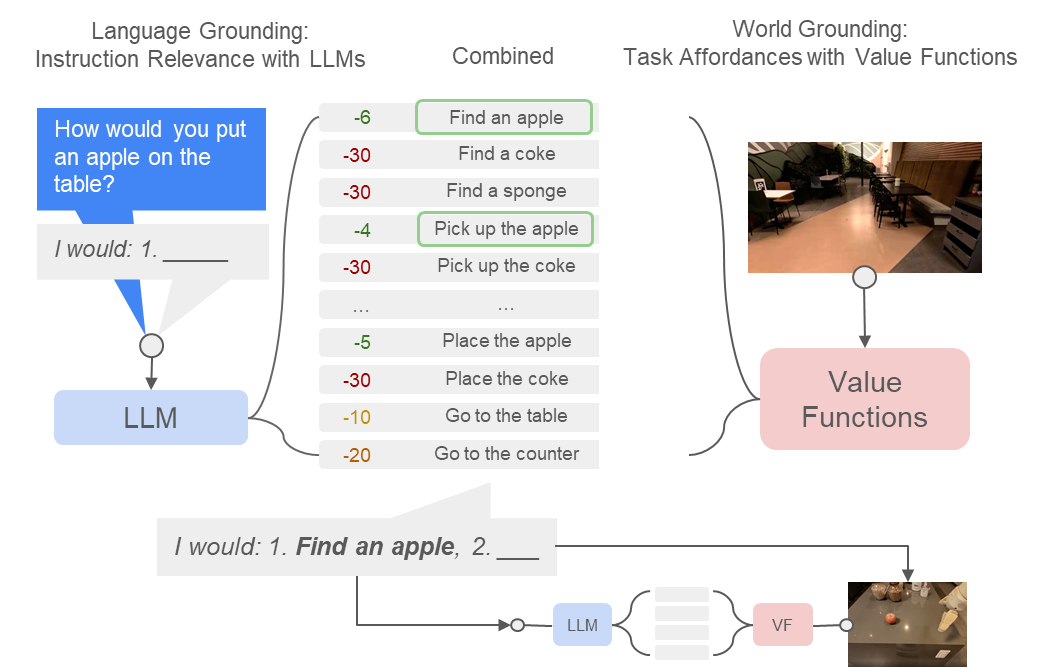
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, Ahn et al. , 2022
LLM x Affordance

Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, Ahn et al. , 2022
- Language Models as Zero-Shot Planners:
Extracting Actionable Knowledge for Embodied Agents - Inner Monologue: Embodied Reasoning through Planning with Language Models
- PaLM-E: An Embodied Multimodal Language Model
- Chain-of-thought prompting elicits reasoning in large language models
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Extended readings in
LLM + Planning
Part 2: Current/future directions
- NLP -- credits: Andrej Karpathy (nov 2023)
- CV -- credits: Kaiming He (oct 23)
- Robotics -- credits: CoRL debate (nov 23)



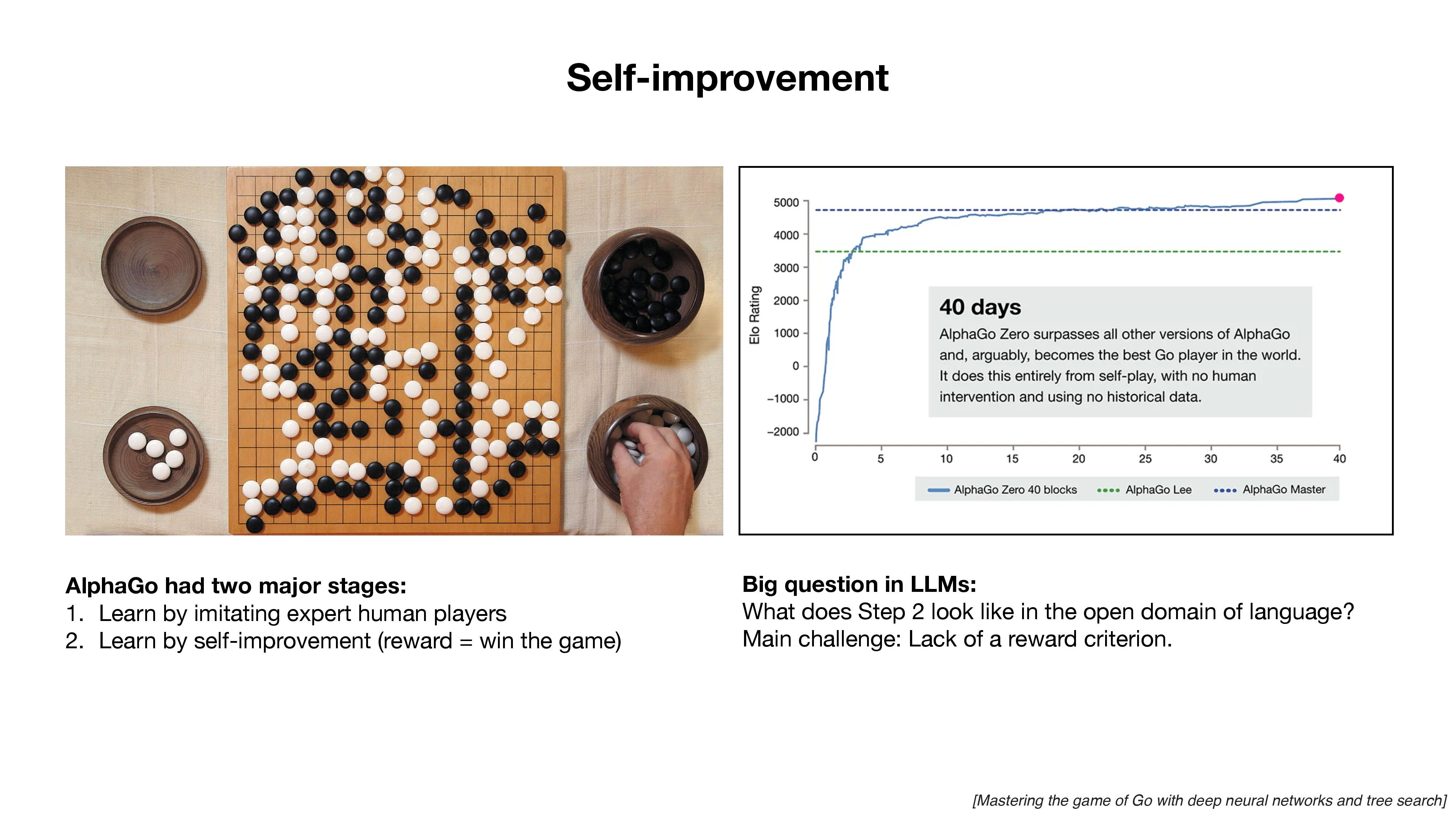
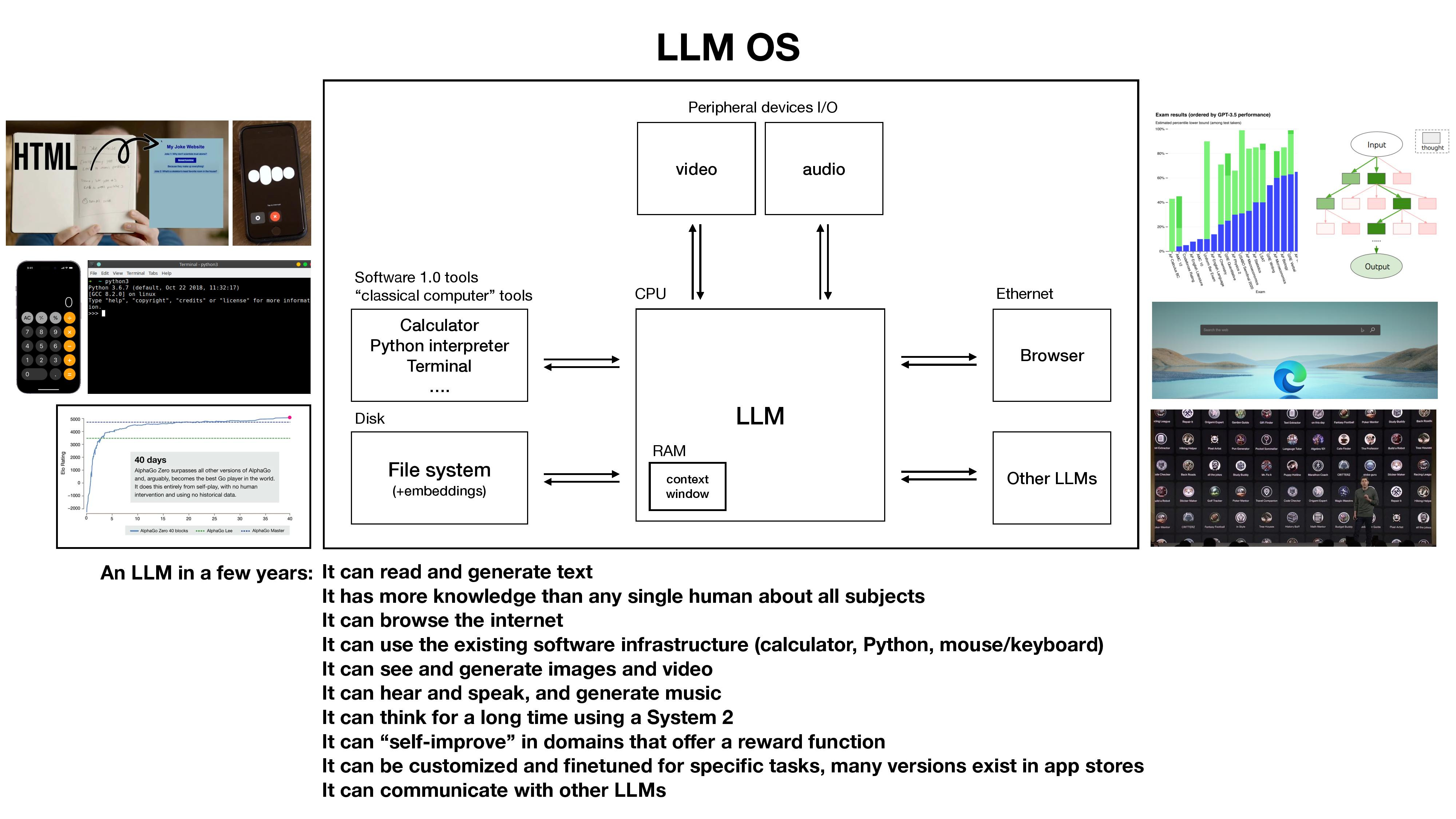








Interpretability

Why video
- Video is how human perceive the world (physics, 3D)
- Video is widely available on internet
- Internet videos contain human actions and tutorials
- Pre-train on entire youtube, first image + text -> video
- Finetune on some robot video
- Inference time, given observation image + text prompt -> video of robot doing the task -> back out actions
A lot of actions/tutorials
Magic of Modality
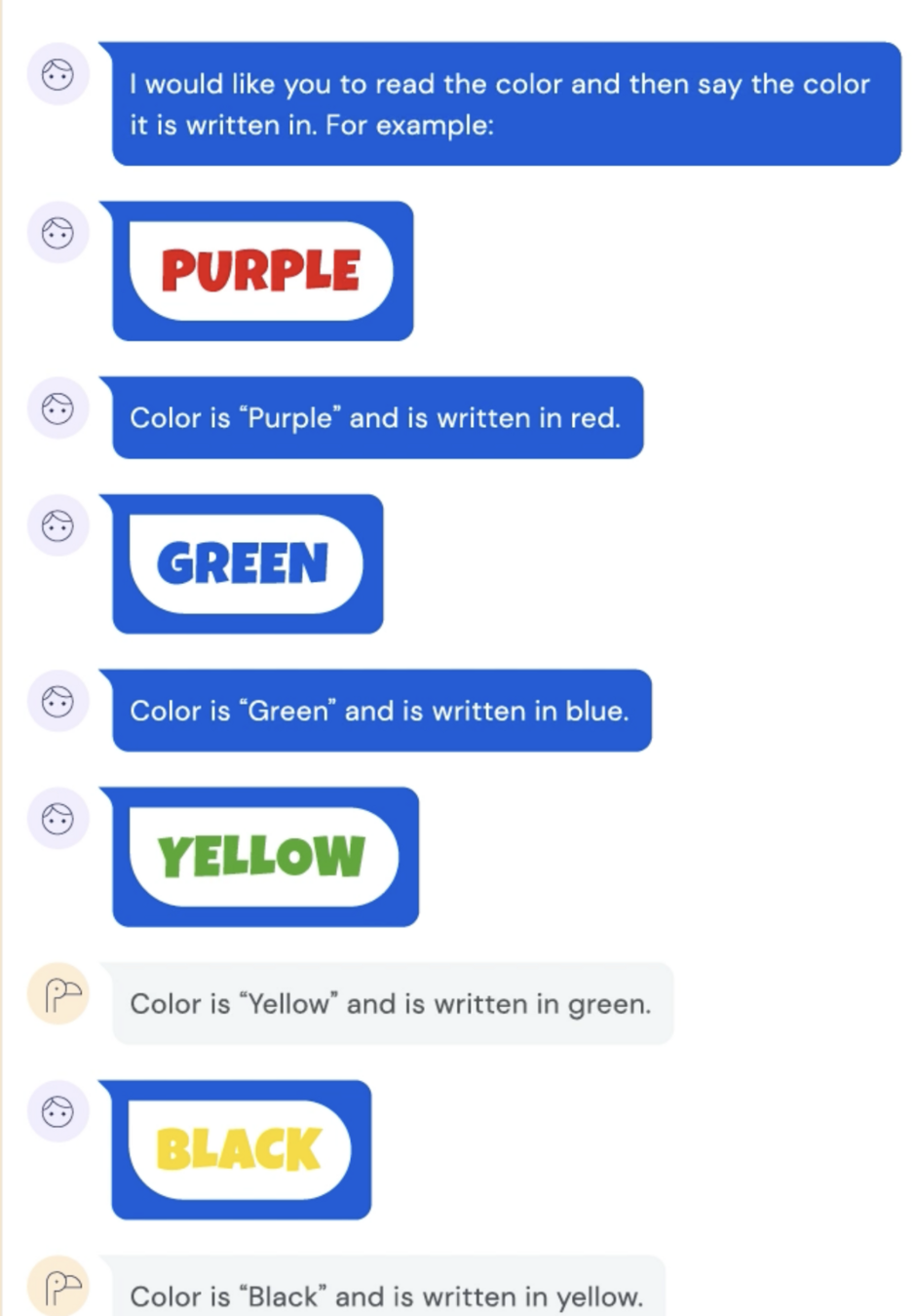
Text, Image, Video -> Text
Video -> 3D shape
Magic of Modality
Boom of 3D data
Universal dynamics model
UniSim: Learning Interactive Real-World Simulators, Du et al., 2023

Video Prediction for Robots
Learning Universal Policies via Text-Guided Video Generation, Du et al. 2023

Video Prediction for Robots
Learning Universal Policies via Text-Guided Video Generation, Du et al. 2023

Video + Language
Video Language Planning, Du et al. 2023
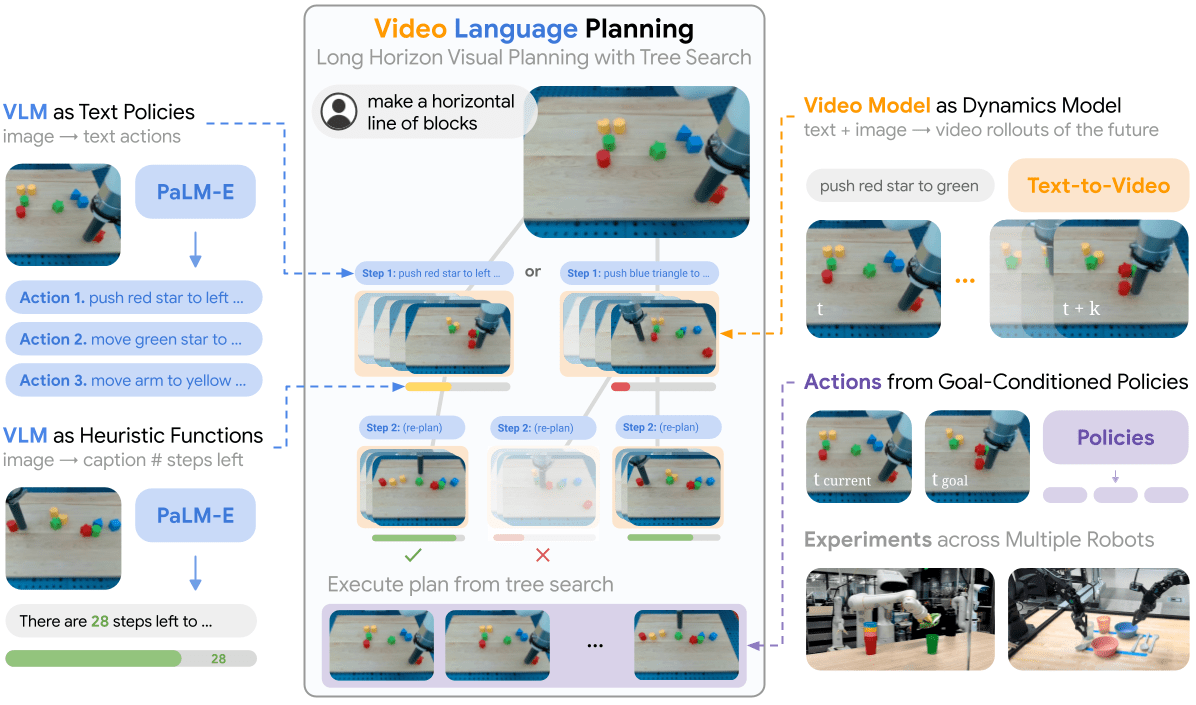
Video + Language
Video Language Planning, Du et al. 2023
Instruction: Make a Line
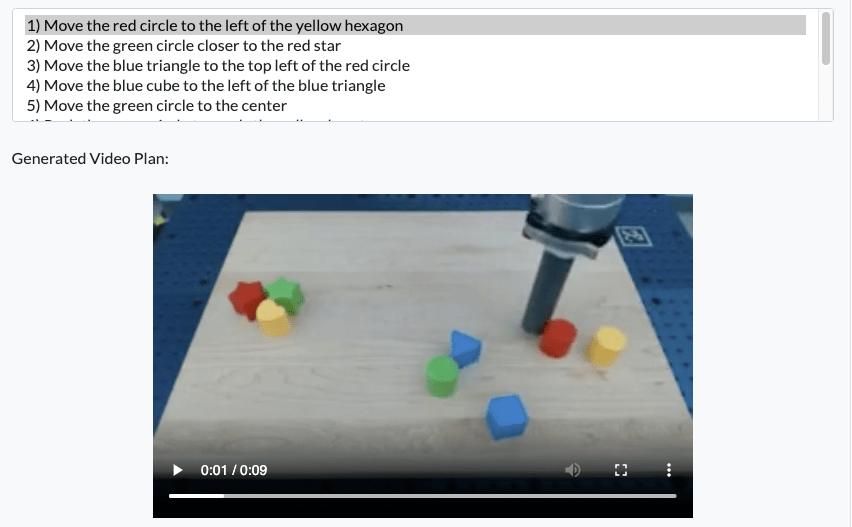
Video + RL
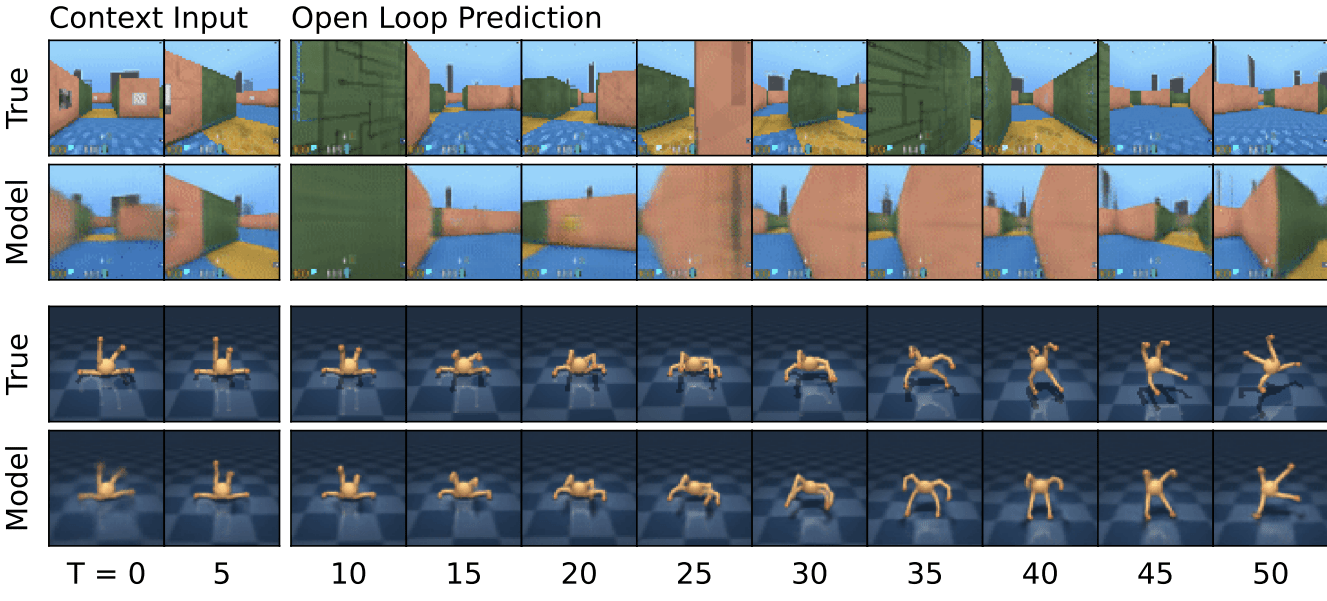
Mastering Diverse Domains through World Models, Hafner et al. 2023
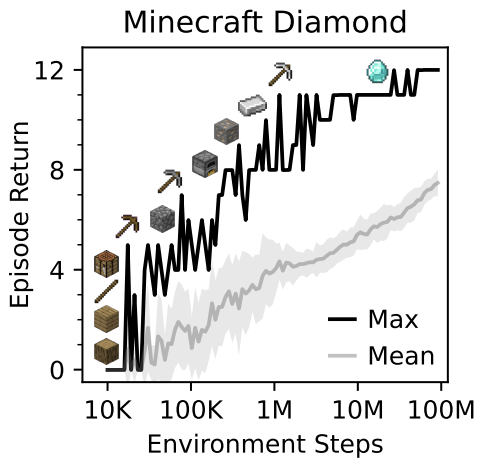
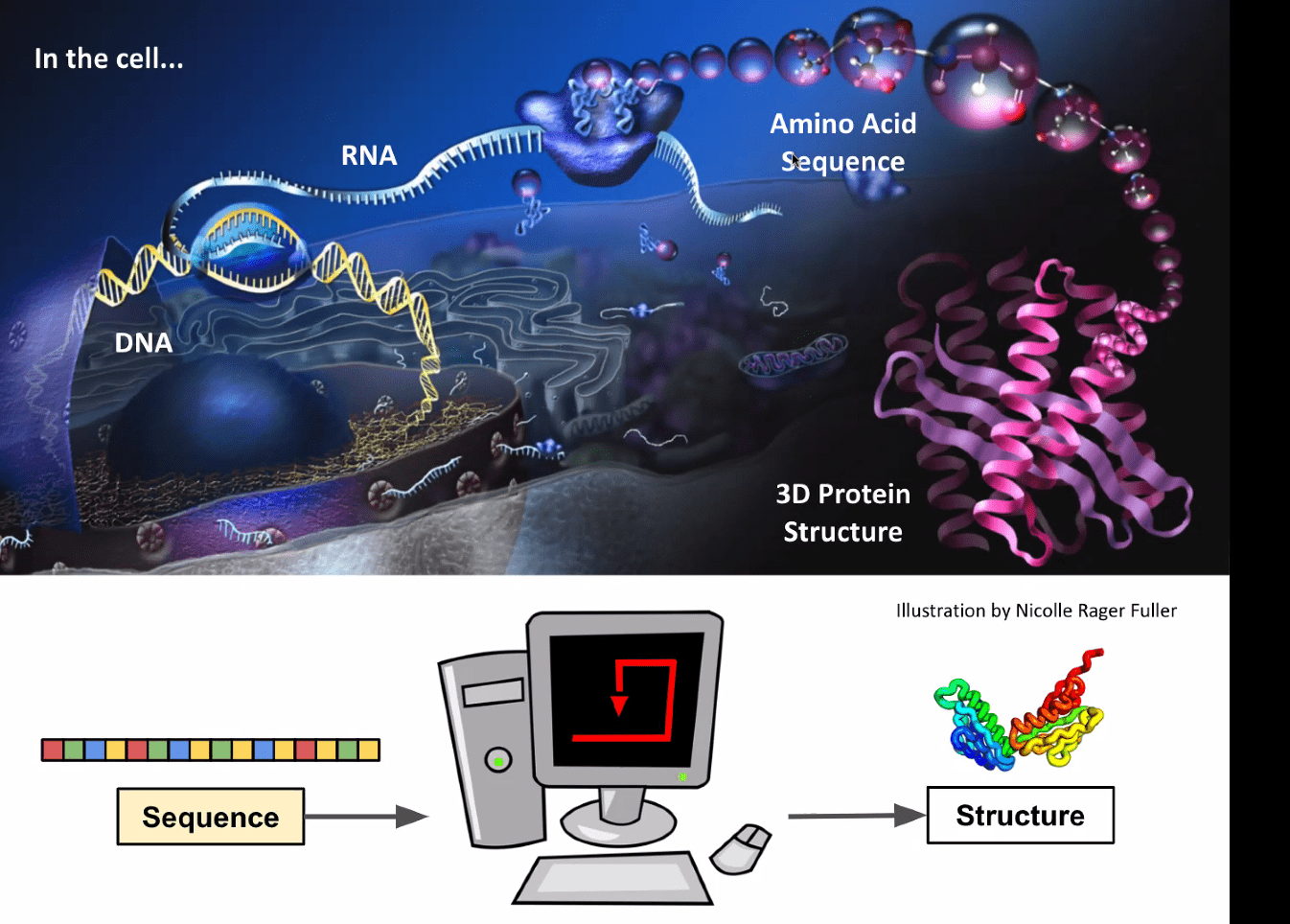
Part 3: Other domain-specific applications
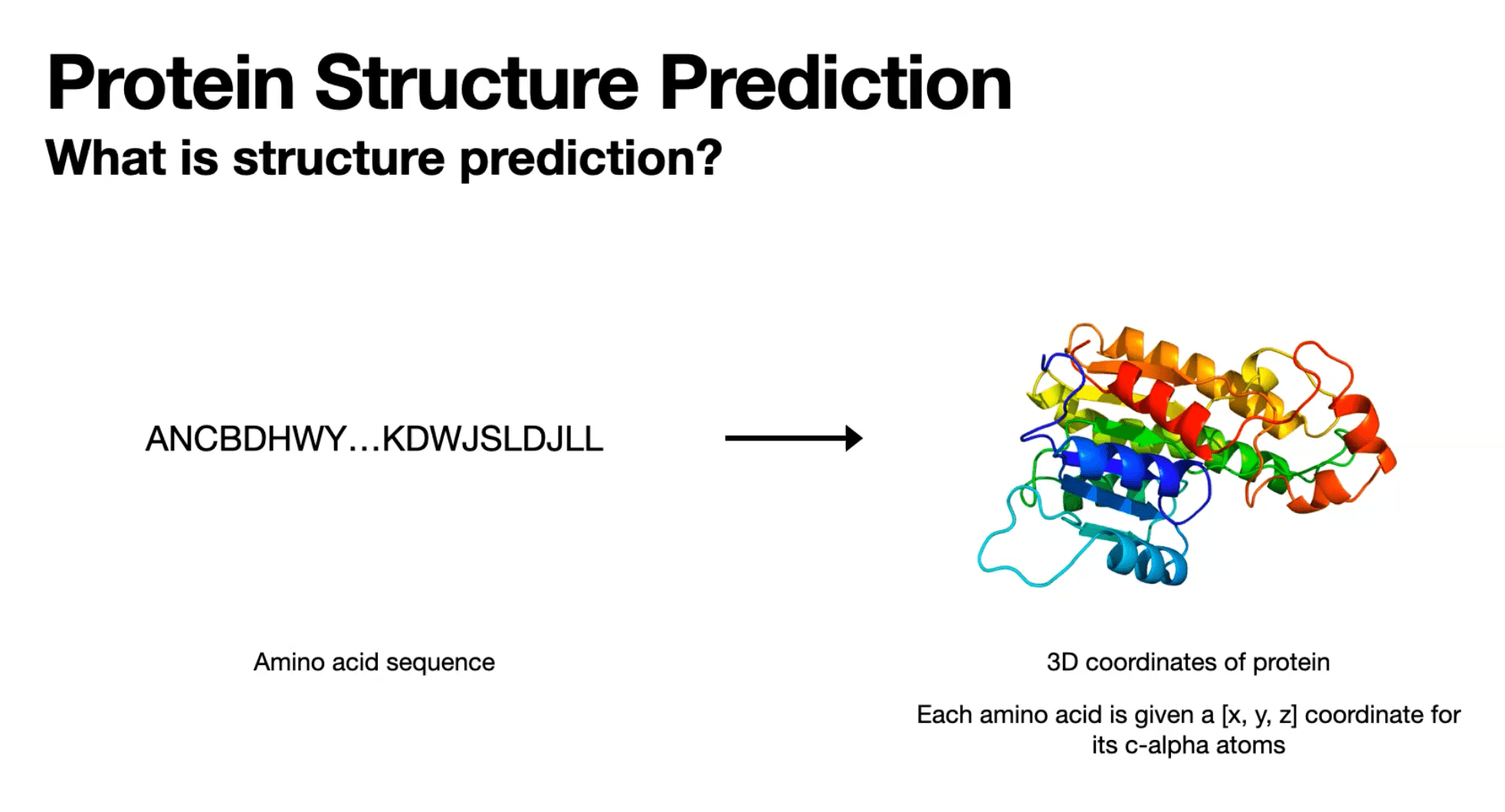


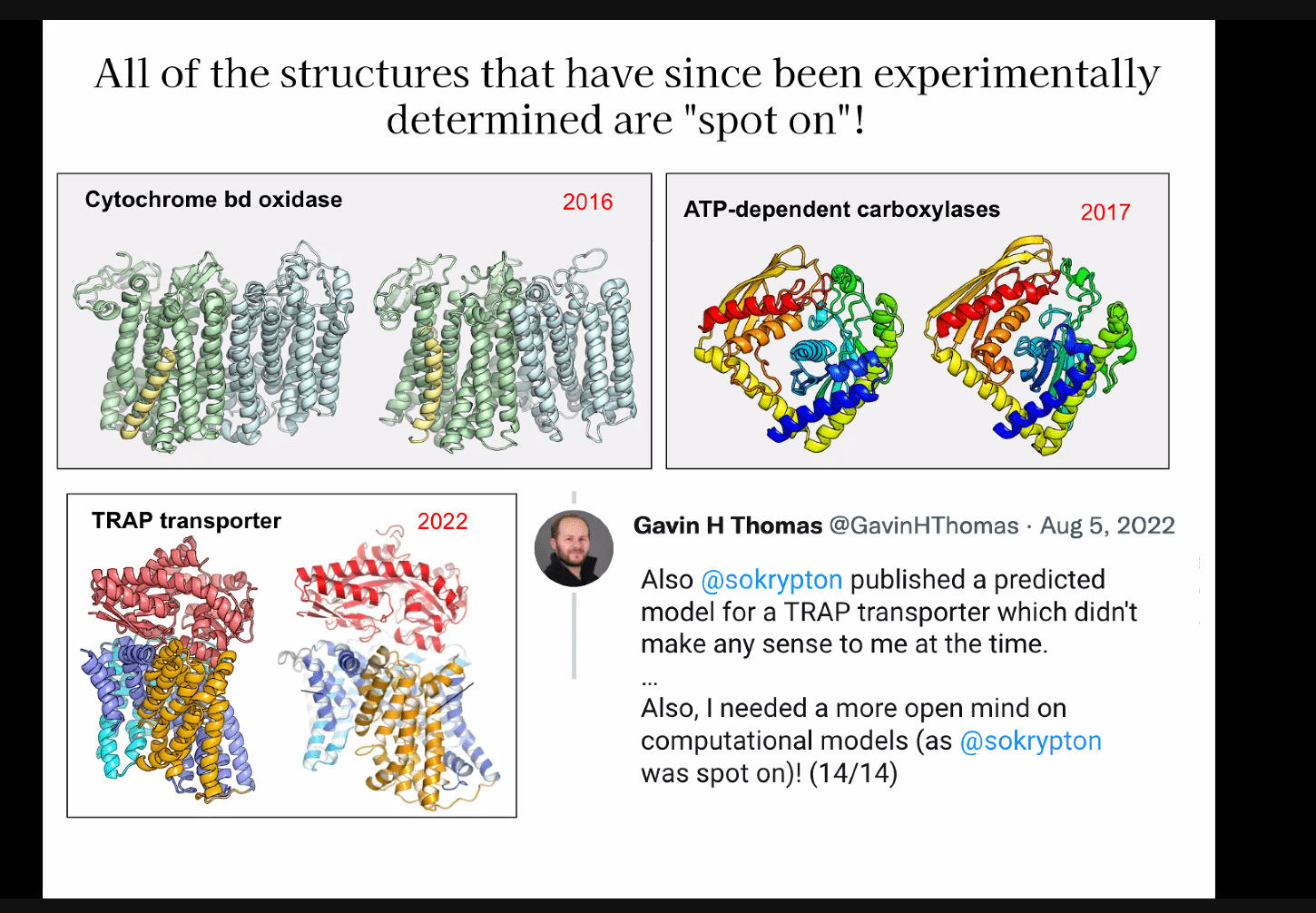
Open challenges:
two main-stream methods:
- predict amino-acid pair-wise distance. or
- predict 3d coordinates
tradeoff between representation compactness and structure.
credit: manoli/regina class

Efficient Hardware Co-design



Hardware section slides credit and link:

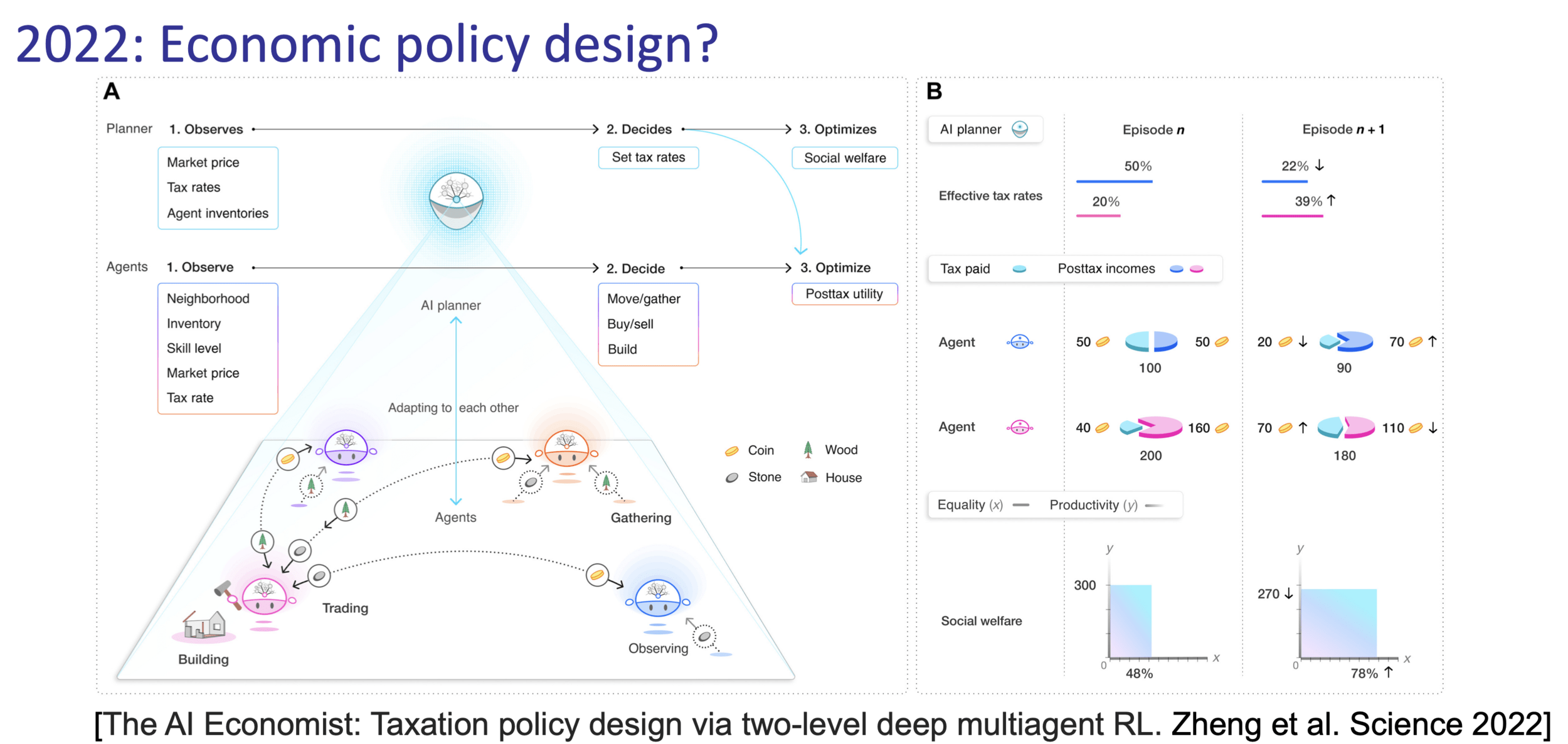
Mathematics/Algorithmetic
Computer-aided proofs have a long history
Suppose we "trivialize" theorem proofs into exam T/F question, what are some common strategies?
- If we really understand the materials, jump to invoking lemmas punchlines, etc and derive
- If less sure, make a guess about the T/F, conjecture, then prove
- If less sure still, try out a few data (if possible) and hope for counter-examples or intuition


Finding things similar to our problem.
For proofs that "look like" this in the past, induction techniques are "often" used, so an assistant may suggest "try induction"
So we need "good" characterizations of facts/statement (a lot of research there). As in what are these "theorems" about??
Nuanced/semantic characterization: what are the assumptions?
First such ML-aided system created about 15 years ago
Previously computers help:
- find counter-example
- accelerating calculations
- symbolic reasoning
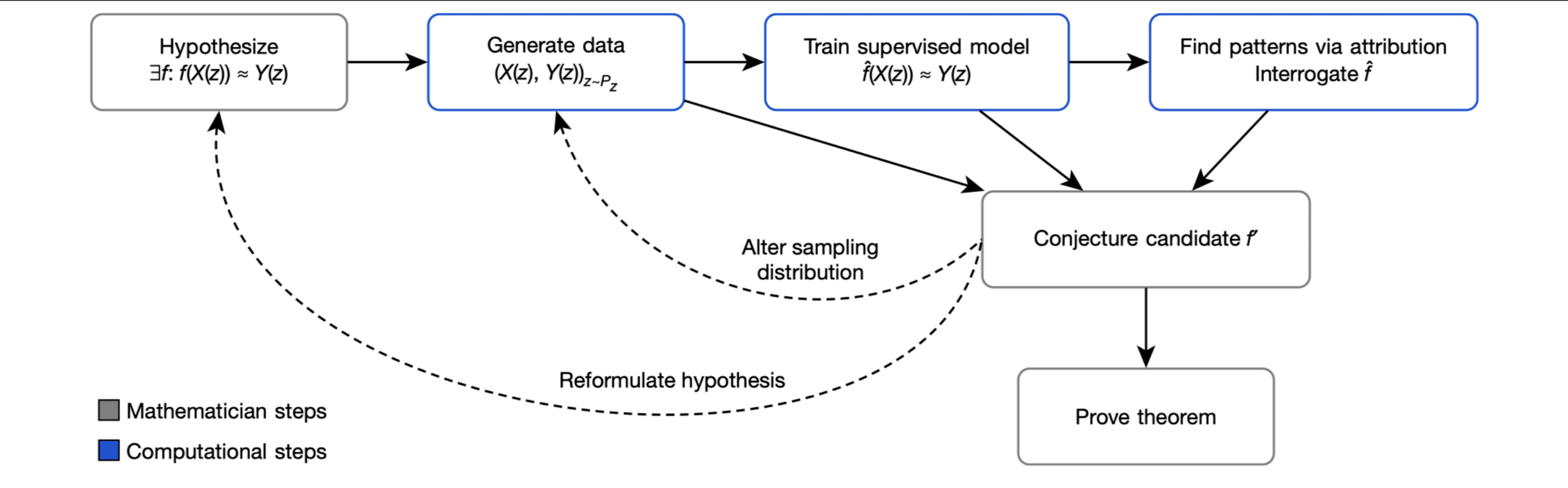
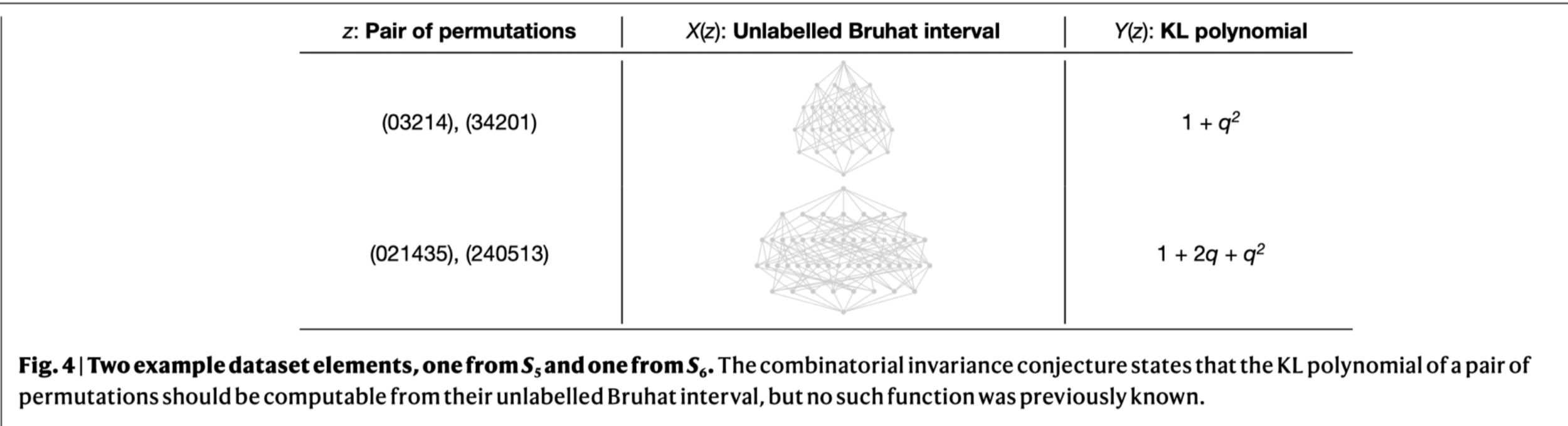


Algorithmic Discovery


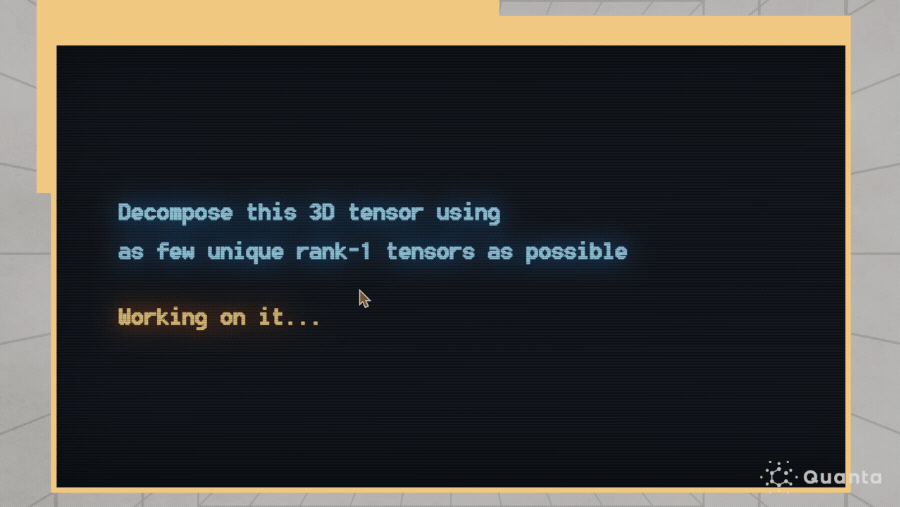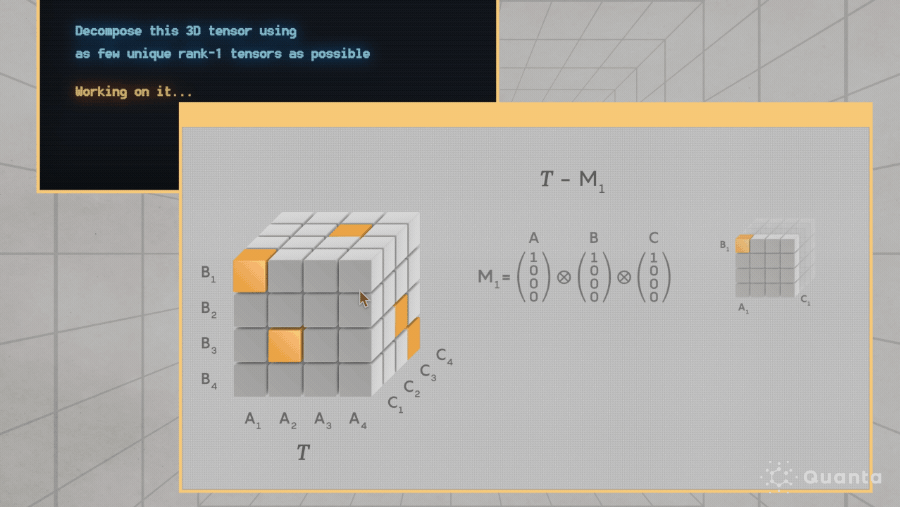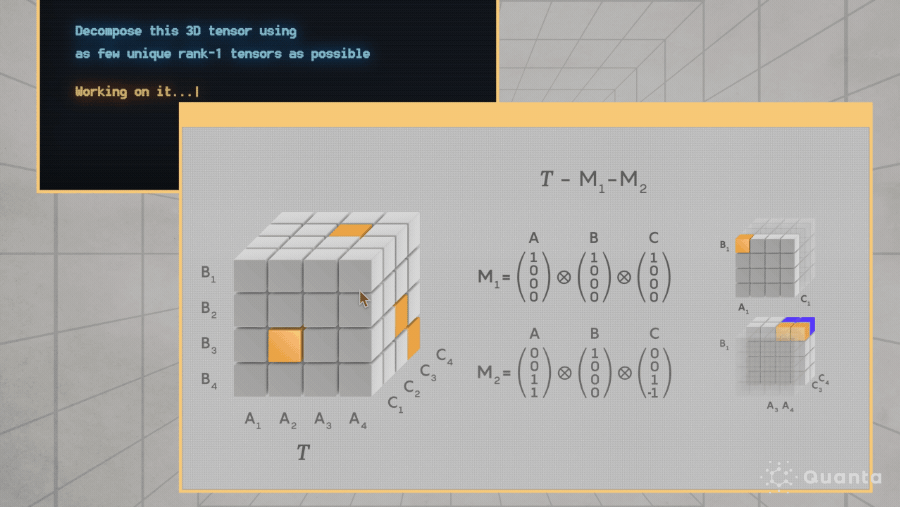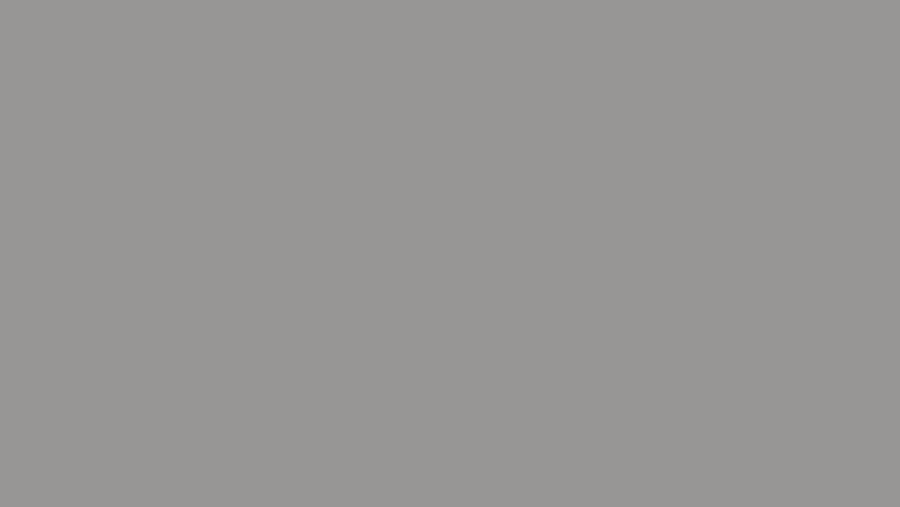

Divide-and-conquer. Try to propose inter-mediate lemmas.
Can try to do without concrete Proof Blueprint.
Take a further step: explore the rich "proof library" bits like LEAN.
Find an open-ended goal in a statistical way.
Square matrices => system suggests that it's true for arbitrary matrices =>
GPTs can read a book and reference a true statement

Societal impact




“The AI Index 2023 Annual Report,” HAI, Stanford University, April 2023.
Thanks!
We'd love to hear your thoughts on the course: this provides valuable feedback for us and other students, for future semesters!
Lecture 24 - Some recent ML trends/applications - 6.7900 Machine Learning (Fall 2023)
By Shen Shen



