

Lecture 11: Markov Decision Processes
Shen Shen
November 15, 2024
Intro to Machine Learning

Outline
-
Markov Decision Processes
-
Definition, terminologies, and policy
-
Policy Evaluation
-
\(V\)-values: State Value Functions
-
Bellman recursions and Bellman equations
-
-
Policy Optimization
-
Optimal policies \(\pi^*\)
-
\(Q\)-values: State-action Optimal Value Functions
-
Value iteration
-
-
Toddler demo, Russ Tedrake thesis, 2004
(Uses vanilla policy gradient (actor-critic))
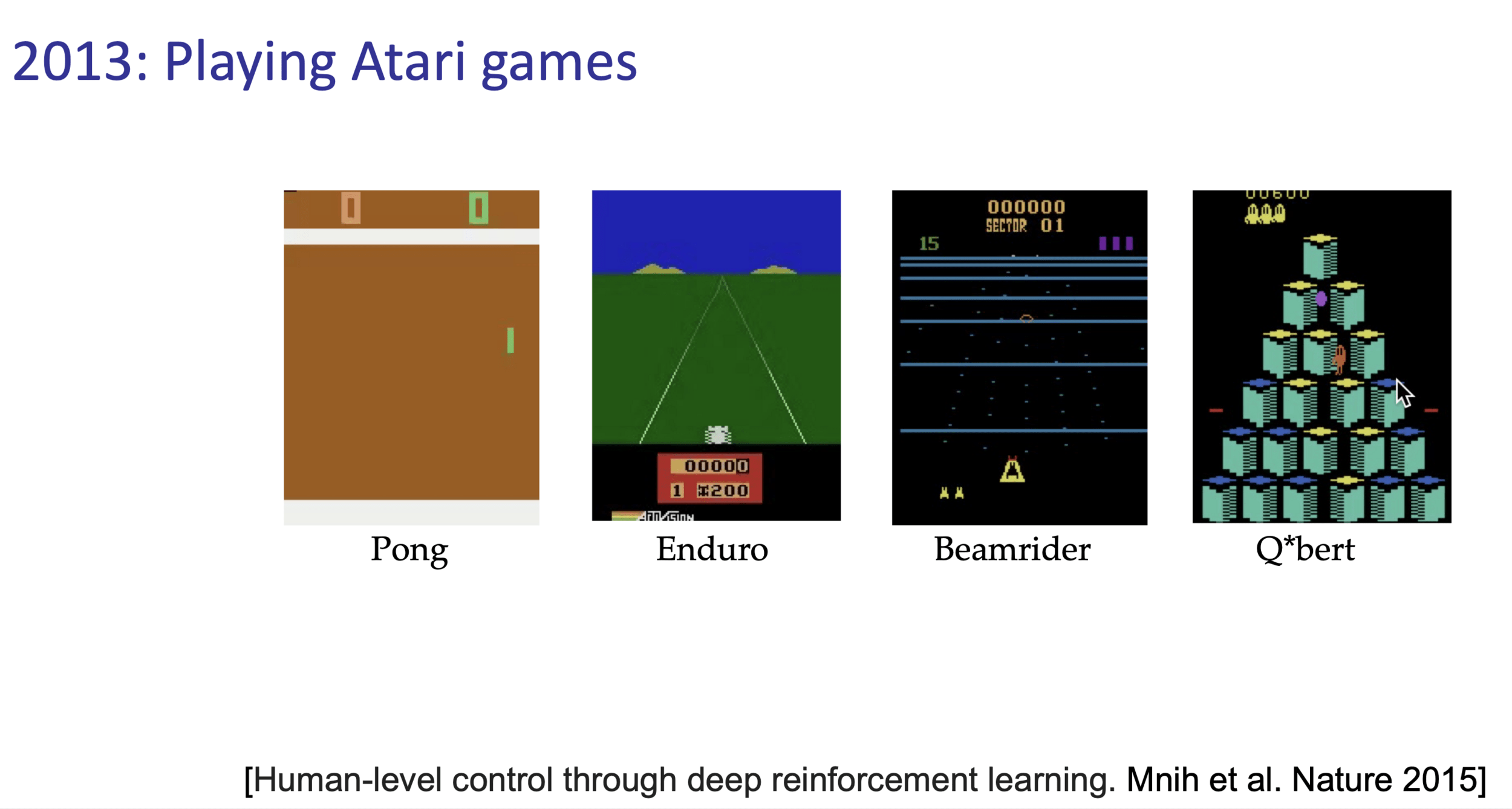





Reinforcement Learning with Human Feedback
Outline
-
Markov Decision Processes
-
Definition, terminologies, and policy
-
Policy Evaluation
-
\(V\)-values: State Value Functions
-
Bellman recursions and Bellman equations
-
-
Policy Optimization
-
Optimal policies \(\pi^*\)
-
\(Q\)-values: State-action Optimal Value Functions
-
Value iteration
-
-
Markov Decision Processes
-
Research area initiated in the 50s by Bellman, known under various names (in various communities):
-
Stochastic optimal control (Control theory)
-
Stochastic shortest path (Operations Research)
-
Sequential decision making under uncertainty (Economics)
-
Reinforcement learning (Artificial Intelligence, Machine Learning)
-
-
A rich variety of accessible and elegant theory, math, algorithms, and applications. But also, considerable variation in notations.
-
We will use the most RL-flavored notations.
- (state, action) results in a transition into a next state:
-
Normally, we get to the “intended” state;
-
E.g., in state (7), action “↑” gets to state (4)
-
-
If an action would take Mario out of the grid world, stay put;
-
E.g., in state (9), “→” gets back to state (9)
-
-
In state (6), action “↑” leads to two possibilities:
-
20% chance to (2)
-
80% chance to (3).
-
-
80\%
20\%
Running example: Mario in a grid-world

- 9 possible states
- 4 possible actions: {Up ↑, Down ↓, Left ←, Right →}
1
2
9
8
7
5
4
3
6
1
1
1
1
-10
-10
-10
-10
reward of (3, \(\downarrow\))
reward of \((3,\uparrow\))
reward of \((6, \downarrow\))
reward of \((6,\rightarrow\))
- (state, action) pairs give out rewards:
- in state 3, any action gives reward 1
- in state 6, any action gives reward -10
- any other (state, action) pair gives reward 0
-
discount factor: a scalar of 0.9 that reduces the "worth" of rewards, depending on the timing we receive them.
- e.g., for (3, \(\leftarrow\)) pair, we receive a reward of 1 at the start of the game; at the 2nd time step, we receive a discounted reward of 0.9; at the 3rd time step, it is further discounted to \((0.9)^2\), and so on.

Mario in a grid-world, cont'd
- \(\mathcal{S}\) : state space, contains all possible states \(s\).
- \(\mathcal{A}\) : action space, contains all possible actions \(a\).
- \(\mathrm{T}\left(s, a, s^{\prime}\right)\) : the probability of transition from state \(s\) to \(s^{\prime}\) when action \(a\) is taken.
Markov Decision Processes - Definition and terminologies
80\%
20\%
1
2
9
8
7
5
4
3
6
\(\mathrm{T}\left(7, \uparrow, 4\right) = 1\)
\(\mathrm{T}\left(9, \rightarrow, 9\right) = 1\)
\(\mathrm{T}\left(6, \uparrow, 3\right) = 0.8\)
\(\mathrm{T}\left(6, \uparrow, 2\right) = 0.2\)
- \(\mathcal{S}\) : state space, contains all possible states \(s\).
- \(\mathcal{A}\) : action space, contains all possible actions \(a\).
- \(\mathrm{T}\left(s, a, s^{\prime}\right)\) : the probability of transition from state \(s\) to \(s^{\prime}\) when action \(a\) is taken.
- \(\mathrm{R}(s, a)\) : reward, takes in a (state, action) pair and returns a reward.
- \(\gamma \in [0,1]\): discount factor, a scalar.
- \(\pi{(s)}\) : policy, takes in a state and returns an action.
The goal of an MDP is to find a "good" policy.
Sidenote: In 6.390,
- \(\mathrm{R}(s, a)\) is deterministic and bounded.
- \(\pi(s)\) is deterministic.
- \(\mathcal{S}\) and \(\mathcal{A}\) are small discrete sets, unless otherwise specified.
Markov Decision Processes - Definition and terminologies
State \(s\)
Action \(a\)
Reward \(r\)


\dots
Policy \(\pi(s)\)
Transition \(\mathrm{T}\left(s, a, s^{\prime}\right)\)
Reward \(\mathrm{R}(s, a)\)
time
a trajectory (aka, an experience, or a rollout), of horizon \(h\)
\(\quad \tau=\left(s_0, a_0, r_0, s_1, a_1, r_1, \ldots s_{h-1}, a_{h-1}, r_{h-1}\right)\)
r_0 = \\ \mathrm{R}(s_0, a_0)
\underbrace{\hspace{4cm}}
s_0
a_0 = \pi(s_0)
s_1
a_0
r_0
a_1
s_2
r_1
s_3
a_3
r_3
a_2
r_2
s_4
a_4
r_4
s_5
a_5
r_5
initial state
s_{h-1}
a_{h-1}
r_{h-1}
s_6
a_6
r_6
s_{7}
all depends on \(\pi\)
Outline
-
Markov Decision Processes
-
Definition, terminologies, and policy
-
Policy Evaluation
-
\(V\)-values: State Value Functions
-
Bellman recursions and Bellman equations
-
-
Policy Optimization
-
Optimal policies \(\pi^*\)
-
\(Q\)-values: State-action Optimal Value Functions
-
Value iteration
-
-
Starting in a given \(s_0\), how "good" is it to follow a policy for \(h\) time steps?
State \(s\)
Action \(a\)
Reward \(r\)
\dots
Policy \(\pi(s)\)
Transition \(\mathrm{T}\left(s, a, s^{\prime}\right)\)
Reward \(\mathrm{R}(s, a)\)
s_0
s_1
a_0
r_0
a_1
s_2
r_1
s_3
a_3
r_3
a_2
r_2
s_4
a_4
r_4
s_5
a_5
r_5
s_{h-1}
a_{h-1}
r_{h-1}
s_6
a_6
r_6
s_{7}
But, consider the Mario game, with
\mathrm{R}(s_0, a_0)
\gamma \mathrm{R}(s_1, a_1)
\gamma^3\mathrm{R}(s_3, a_3)
\gamma^2 \mathrm{R}(s_2, a_2)
\dots
+
+
+
+
\gamma^{h-1}\mathrm{R}(s_{h-1}, a_{h-1})
+
One idea:
??
\dots
reward of \((6,\uparrow\))
1
2
9
8
7
5
4
3
6
80\%
20\%
1
1
1
1
-10
-10
-10
-10
-10
6
\uparrow
State \(s\)
Action \(a\)
Reward \(r\)
\dots
Policy \(\pi(s)\)
Transition \(\mathrm{T}\left(s, a, s^{\prime}\right)\)
Reward \(\mathrm{R}(s, a)\)
s_0
s_1
a_0
r_0
a_1
s_2
r_1
s_3
a_3
r_3
a_2
r_2
s_4
a_4
r_4
s_5
a_5
r_5
s_{h-1}
a_{h-1}
r_{h-1}
s_6
a_6
r_6
s_{7}
\mathrm{R}(s_0, a_0)
\gamma \mathrm{R}(s_1, a_1)
\gamma^3\mathrm{R}(s_3, a_3)
\gamma^2 \mathrm{R}(s_2, a_2)
\dots
+
+
+
+
\gamma^{h-1}\mathrm{R}(s_{h-1}, a_{h-1})
+
\mathbb{E}[
]
in 390, this expectation is only w.r.t. the transition probabilities \(\mathrm{T}\left(s, a, s^{\prime}\right)\)
\( h\) terms inside
\underbrace{\hspace{7.6cm}}
Starting in a given \(s_0\), how "good" is it to follow a policy for \(h\) time steps?
For a given policy \(\pi(s),\) the (state) value functions
\(V^h_\pi(s):=\mathbb{E}\left[\sum_{t=0}^{h-1} \gamma^t \mathrm{R}\left(s_t, \pi\left(s_t\right)\right) \mid s_0=s, \pi\right], \forall s, h\)
- value functions \(V^h_\pi(s)\): the expected sum of discounted rewards, starting in state \(s\) and follow policy \(\pi\) for \(h\) steps.
- horizon-0 values defined as 0.
- value is long-term, reward is short-term (one-time).
\mathrm{R}(s_0, a_0)
\gamma \mathrm{R}(s_1, a_1)
\gamma^3\mathrm{R}(s_3, a_3)
\gamma^2 \mathrm{R}(s_2, a_2)
\dots
+
+
+
+
\gamma^{h-1}\mathrm{R}(s_{h-1}, a_{h-1})
+
\mathbb{E}[
]
evaluating the "always \(\uparrow\)" policy
\(V^h_\pi(s):=\mathbb{E}\left[\sum_{t=0}^{h-1} \gamma^t \mathrm{R}\left(s_t, \pi\left(s_t\right)\right) \mid s_0=s, \pi\right], \forall s, h\)
expanded form
\mathrm{R}(s_0, a_0)
\gamma \mathrm{R}(s_1, a_1)
\gamma^2 \mathrm{R}(s_2, a_2)
\dots
+
+
+
\mathbb{E}[
]
\( h\) terms inside
\underbrace{\hspace{4cm}}
- Horizon \(h\) = 0: no step left.
0
0
0
0
0
0
0
0
0
V_{\pi}^0(s)
1
2
9
8
7
5
4
3
6
80\%
20\%
- \(\pi(s) = ``\uparrow",\ \forall s\)
- all rewards are zero, except
- \(\mathrm{R}(3, \uparrow) = 1\)
- \(\mathrm{R}(6, \uparrow) = -10\)
- \(\gamma = 0.9\)
- Horizon \(h\) = 1: receive the rewards at face value
0
0
0
0
0
0
0
1
-10
V_{\pi}^1(s) = \mathrm{R}(s, \uparrow)
1
2
9
8
7
5
4
3
6
80\%
20\%
evaluating the "always \(\uparrow\)" policy
- \(\pi(s) = ``\uparrow",\ \forall s\)
- all rewards are zero, except
- \(\mathrm{R}(3, \uparrow) = 1\)
- \(\mathrm{R}(6, \uparrow) = -10\)
- \(\gamma = 0.9\)
- Horizon \(h\) = 2
\mathbb{E}[
]
\mathrm{R}(s_0, a_0)
.9 \mathrm{R}(s_1, a_1)
+

\( 2\) terms inside
V_{\pi}^2(s) =
0
0
\mathrm{R}(1, \uparrow) + \gamma \mathrm{R}(1, \uparrow)
0
\mathrm{R}(2, \uparrow) + \gamma \mathrm{R}(2, \uparrow)
1.9
\mathrm{R}(3, \uparrow) + \gamma \mathrm{R}(3, \uparrow)
0
\mathrm{R}(4, \uparrow) + \gamma \mathrm{R}(1, \uparrow)
= 1 + 0.9 *(1) = 1.9
\mathrm{R}(5, \uparrow) + \gamma \mathrm{R}(2, \uparrow)
1
2
9
8
7
5
4
3
6
80\%
20\%
evaluating the "always \(\uparrow\)" policy
- \(\pi(s) = ``\uparrow",\ \forall s\)
- all rewards are zero, except
- \(\mathrm{R}(3, \uparrow) = 1\)
- \(\mathrm{R}(6, \uparrow) = -10\)
- \(\gamma = 0.9\)
- Horizon \(h\) = 2
\mathbb{E}[
]
\mathrm{R}(s_0, a_0)
.9 \mathrm{R}(s_1, a_1)
+
\( 2\) terms inside
V_{\pi}^2(s) =
-9
0
0
0
-9.28
\mathrm{R}(6, \uparrow) + \gamma [.2 \mathrm{R}(2, \uparrow) + .8 \mathrm{R}(3, \uparrow)]
0
0
1.9
0
\mathrm{R}(8, \uparrow) + \gamma \mathrm{R}(5, \uparrow)
\mathrm{R}(7, \uparrow) + \gamma \mathrm{R}(4, \uparrow)
\mathrm{R}(9, \uparrow) + \gamma \mathrm{R}(6, \uparrow)
action \(\uparrow\)
\mathrm{R}(6, \uparrow)
20\%
80\%
6
2
3
action \(\uparrow\)
action \(\uparrow\)
\mathrm{R}(2, \uparrow)
\gamma
\mathrm{R}(3, \uparrow)
\gamma
= -10 + 0.9*(0.2*0+0.8*1)
= -9.28
?
= 0 + 0.9*(-10)
1
2
9
8
7
5
4
3
6
80\%
20\%
Recall:
\(\pi(s) = ``\uparrow",\ \forall s\)
\(\mathrm{R}(3, \uparrow) = 1\)
\(\mathrm{R}(6, \uparrow) = -10\)
\(\gamma = 0.9\)
2
3
action \(\uparrow\)
action \(\uparrow\)
\gamma^2
\mathrm{R}(2, \uparrow)
\mathrm{R}(3, \uparrow)
\gamma^2
6
action \(\uparrow\)
\mathrm{R}(6, \uparrow)
\mathrm{R}(6, \uparrow)
20\%
20\%
2
action \(\uparrow\)
3
80\%
80\%
action \(\uparrow\)
\gamma
\mathrm{R}(3, \uparrow)
\gamma
\mathrm{R}(2, \uparrow)
+
\mathrm{R}(2, \uparrow)
\gamma
\gamma
\mathrm{R}(2, \uparrow)
20\%
[
+
]
\mathrm{R}(6, \uparrow)
=
\mathrm{R}(3, \uparrow)
\gamma
\mathrm{R}(3, \uparrow)
80\%
[
+
+
]
\gamma
V_\pi^3(6)=
\mathrm{R}(6, \uparrow)
\mathrm{R}(2, \uparrow)
\gamma
\gamma^2
\mathrm{R}(2, \uparrow)
20\%
[
+
+
]
\mathrm{R}(3, \uparrow)
\gamma
80\%
[
+
+
]
\mathrm{R}(3, \uparrow)
\gamma^2
\mathrm{R}(6, \uparrow)
=
\gamma
20\%
+
V_\pi^2(2)
\gamma
80\%
+
V_\pi^2(3)
?
V_{\pi}^3(s)
- Horizon \(h\) = 3
evaluating the "always \(\uparrow\)" policy
Bellman Recursion
V_\pi^h(s)= \mathrm{R}(s, \pi(s))+ \gamma \sum_{s^{\prime}} \mathrm{T}\left(s, \pi(s), s^{\prime}\right) V_\pi^{h-1}\left(s^{\prime}\right)
weighted by the probability of getting to that next state \(s^{\prime}\)
\((h-1)\) horizon values at a next state \(s^{\prime}\)
the immediate reward for taking the policy-prescribed action \(\pi(s)\) in state \(s\).
discounted by \(\gamma\)
horizon-\(h\) value in state \(s\): the expected sum of discounted rewards, starting in state \(s\) and following policy \(\pi\) for \(h\) steps.
V_\pi^h(s)= \mathrm{R}(s, \pi(s))+ \gamma \sum_{s^{\prime}} \mathrm{T}\left(s, \pi(s), s^{\prime}\right) V_\pi^{h-1}\left(s^{\prime}\right)
approaches infinity
V_\pi^{\infty}(s)= \mathrm{R}(s, \pi(s))+ \gamma \sum_{s^{\prime}} \mathrm{T}\left(s, \pi(s), s^{\prime}\right) V_\pi^{\infty}\left(s^{\prime}\right)
\(|\mathcal{S}|\) many linear equations, one equation for each state
Bellman Recursion
typically \(\gamma <1\) in MDP definition
becomes Bellman Equations
\(V^h_\pi(s):=\mathbb{E}\left[\sum_{t=0}^{h-1} \gamma^t \mathrm{R}\left(s_t, \pi\left(s_t\right)\right) \mid s_0=s, \pi\right], \forall s, h\)
If the horizon \(h\) goes to infinity
finite-horizon Bellman recursions
infinite-horizon Bellman equations
V_\pi^{\infty}(s)= \mathrm{R}(s, \pi(s))+ \gamma \sum_{s^{\prime}} \mathrm{T}\left(s, \pi(s), s^{\prime}\right) V_\pi^{\infty}\left(s^{\prime}\right), \forall s
V^{h}_\pi(s)= \mathrm{R}(s, \pi(s))+ \gamma \sum_{s^{\prime}} \mathrm{T}\left(s, \pi(s), s^{\prime}\right) V^{h-1}_\pi\left(s^{\prime}\right), \forall s
Recall: For a given policy \(\pi(s),\) the (state) value functions
\(V^h_\pi(s):=\mathbb{E}\left[\sum_{t=0}^{h-1} \gamma^t \mathrm{R}\left(s_t, \pi\left(s_t\right)\right) \mid s_0=s, \pi\right], \forall s, h\)
\pi(s)
V_{\pi}^{h}(s)
MDP
Policy evaluation
Quick summary
Outline
-
Markov Decision Processes
-
Definition, terminologies, and policy
-
Policy Evaluation
-
\(V\)-values: State Value Functions
-
Bellman recursions and Bellman equations
-
-
Policy Optimization
-
Optimal policies \(\pi^*\)
-
\(Q\)-values: State-action Optimal Value Functions
-
Value iteration
-
-
- For a fixed MDP, the optimal values \(\mathrm{V}^h_{\pi^*}({s})\) must be unique.
- Optimal policy \(\pi^*\) might not be unique (think, e.g. symmetric world)
- In finite horizon, optimal policy depends on how many time steps left.
- In infinite horizon, time steps no longer matters. In other words, there exists a stationary optimal policy.
Optimal policy \(\pi^*\)
Definition of \(\pi^*\): for a given MDP and a fixed horizon \(h\) (possibly infinite), \(\mathrm{V}^h_{\pi^*}({s}) \geqslant \mathrm{V}^h_\pi({s})\) for all \(s \in \mathcal{S}\) and for all possible policy \(\pi\).
- One possible idea: enumerate over all possible policies, do policy evaluation, get the max values \(\mathrm{V}^h_{\pi^*}({s})\) which then gives us the optimal policy.
- Very very tedious ... also gives no insights.
- A better idea: take advantage of the recursive structure.
How to search for an optimal policy \(\pi^*\)?
Definition of \(\pi^*\): for a given MDP and a fixed horizon \(h\) (possibly infinite), \(\mathrm{V}^h_{\pi^*}({s}) \geqslant \mathrm{V}^h_\pi({s})\) for all \(s \in \mathcal{S}\) and for all possible policy \(\pi\).
V^{h}_\pi(s)= \mathrm{R}(s, \pi(s))+ \gamma \sum_{s^{\prime}} \mathrm{T}\left(s, \pi(s), s^{\prime}\right) V^{h-1}_\pi\left(s^{\prime}\right), \forall s
Optimal state-action value functions \(Q^h(s, a)\)
Q^h (s, a)=\mathrm{R}(s, a)+\gamma \sum_{s^{\prime}} \mathrm{T}\left(s, a, s^{\prime} \right) \max _{a^{\prime}} Q^{h-1}\left(s^{\prime}, a^{\prime}\right), \forall s, a, h
\(Q^h(s, a)\): the expected sum of discounted rewards for
- starting in state \(s\),
- take action \(a\), for one step
- act optimally there afterwards for the remaining \((h-1)\) steps
\(V\) values vs. \(Q\) values
- \(V\) is defined over state space; \(Q\) is defined over (state, action) space.
- Any policy can be evaluated to get \(V\) values; whereas \(Q,\) per definition, has the sense of "tail optimality" baked in.
- \(\mathrm{V}^h_{\pi^*}({s})\) can be derived from \(Q^h(s,a)\), and vise versa.
- \(Q\) is easier to read "optimal actions" from.
Optimal state-action value functions \(Q^h(s, a)\)
\(Q^h(s, a)\): the expected sum of discounted rewards for
- starting in state \(s\),
- take action \(a\), for one step
- act optimally there afterwards for the remaining \((h-1)\) steps
recursively finding \(Q^h(s, a)\)
\(Q^h(s, a)\): the expected sum of discounted rewards for
- starting in state \(s\),
- take action \(a\), for one step
- act optimally there afterwards for the remaining \((h-1)\) steps
1
2
9
8
7
5
4
3
6
80\%
20\%
Recall:
\(\gamma = 0.9\)
1
1
1
1
-10
-10
-10
-10
States and one special transition:
\(\mathrm{R}(s,a)\)
Q^0(s, a)
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
-10
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
Q^1(s, a)
-10
1
-10
-10
Q^1(s, a) = \mathrm{R}(s,a)
0
0
0
1
0
-10
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
-10
1
-10
-10
0
0
Q^2(s, a)
Let's consider \(Q^2(3, \rightarrow)\)
- receive \(\mathrm{R}(3,\rightarrow)\)
\( = 1 + .9 \max _{a^{\prime}} Q^{1}\left(3, a^{\prime}\right)\)
- next state \(s'\) = 3, act optimally for the remaining one timestep
- receive \(\max _{a^{\prime}} Q^{1}\left(3, a^{\prime}\right)\)
\( = 1.9\)
0
0
0
0
1.9
1
2
9
8
7
5
4
3
6
80\%
20\%
Recall:
\(\gamma = 0.9\)
States and one special transition:
\(Q^h(s, a)\): the expected sum of discounted rewards for
- starting in state \(s\),
- take action \(a\), for one step
- act optimally there afterwards for the remaining \((h-1)\) steps
\(Q^2(3, \rightarrow) = \mathrm{R}(3,\rightarrow) + \gamma \max _{a^{\prime}} Q^{1}\left(3, a^{\prime}\right)\)
Q^1(s, a) = \mathrm{R}(s,a)
0
0
0
1
0
-10
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
-10
1
-10
-10
0
0
Q^2(s, a)
Let's consider \(Q^2(3, \uparrow)\)
- receive \(\mathrm{R}(3,\uparrow)\)
\( = 1 + .9 \max _{a^{\prime}} Q^{1}\left(3, a^{\prime}\right)\)
- next state \(s'\) = 3, act optimally for the remaining one timestep
- receive \(\max _{a^{\prime}} Q^{1}\left(3, a^{\prime}\right)\)
\( = 1.9\)
0
0
0
0
1.9
1.9
1
2
9
8
7
5
4
3
6
80\%
20\%
Recall:
\(\gamma = 0.9\)
States and one special transition:
\(Q^h(s, a)\): the expected sum of discounted rewards for
- starting in state \(s\),
- take action \(a\), for one step
- act optimally there afterwards for the remaining \((h-1)\) steps
\(Q^2(3, \uparrow) = \mathrm{R}(3,\uparrow) + \gamma \max _{a^{\prime}} Q^{1}\left(3, a^{\prime}\right)\)
Q^1(s, a) = \mathrm{R}(s,a)
0
0
0
1
0
-10
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
-10
1
-10
-10
0
0
Q^2(s, a)
Let's consider \(Q^2(3, \leftarrow)\)
- receive \(\mathrm{R}(3,\leftarrow)\)
\( = 1 + .9 \max _{a^{\prime}} Q^{1}\left(2, a^{\prime}\right)\)
- next state \(s'\) = 2, act optimally for the remaining one timestep
- receive \(\max _{a^{\prime}} Q^{1}\left(2, a^{\prime}\right)\)
\( = 1\)
0
0
0
0
1.9
1.9
1
1
2
9
8
7
5
4
3
6
80\%
20\%
Recall:
\(\gamma = 0.9\)
States and one special transition:
\(Q^h(s, a)\): the expected sum of discounted rewards for
- starting in state \(s\),
- take action \(a\), for one step
- act optimally there afterwards for the remaining \((h-1)\) steps
\(Q^2(3, \leftarrow) = \mathrm{R}(3,\leftarrow) + \gamma \max _{a^{\prime}} Q^{1}\left(2, a^{\prime}\right)\)
Q^1(s, a) = \mathrm{R}(s,a)
0
0
0
1
0
-10
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
-10
1
-10
-10
0
0
Q^2(s, a)
Let's consider \(Q^2(3, \downarrow)\)
- receive \(\mathrm{R}(3,\downarrow)\)
\( = 1 + .9 \max _{a^{\prime}} Q^{1}\left(6, a^{\prime}\right)\)
- next state \(s'\) = 6, act optimally for the remaining one timestep
- receive \(\max _{a^{\prime}} Q^{1}\left(6, a^{\prime}\right)\)
\( = -8\)
0
0
0
0
1.9
1.9
1
-8
1
2
9
8
7
5
4
3
6
80\%
20\%
Recall:
\(\gamma = 0.9\)
States and one special transition:
\(Q^h(s, a)\): the expected sum of discounted rewards for
- starting in state \(s\),
- take action \(a\), for one step
- act optimally there afterwards for the remaining \((h-1)\) steps
\(Q^2(3, \leftarrow) = \mathrm{R}(3,\leftarrow) + \gamma \max _{a^{\prime}} Q^{1}\left(2, a^{\prime}\right)\)
1
2
9
8
7
5
4
3
6
80\%
20\%
Recall:
\(\gamma = 0.9\)
Q^1(s, a) = \mathrm{R}(s,a)
States and one special transition:
0
0
0
1
0
-10
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
-10
1
-10
-10
0
0
Q^2(s, a)
- act optimally for one more timestep, at the next state \(s^{\prime}\)
0
0
0
0
1.9
1.9
1
-8
- 20% chance, \(s'\) = 2, act optimally, receive \(\max _{a^{\prime}} Q^{1}\left(2, a^{\prime}\right)\)
- 80% chance, \(s'\) = 3, act optimally, receive \(\max _{a^{\prime}} Q^{1}\left(3, a^{\prime}\right)\)
-9.28
\(= -10 + .9 [.2*0+ .8*1] = -9.28\)
- receive \(\mathrm{R}(6,\uparrow)\)
\(Q^h(s, a)\): the expected sum of discounted rewards for
- starting in state \(s\),
- take action \(a\), for one step
- act optimally there afterwards for the remaining \((h-1)\) steps
\(Q^2(6, \uparrow) =\mathrm{R}(6,\uparrow) + \gamma[.2 \max _{a^{\prime}} Q^{1}\left(2, a^{\prime}\right)+ .8\max _{a^{\prime}} Q^{1}\left(3, a^{\prime}\right)] \)
Let's consider
Q^1(s, a)
0
0
0
1
0
-10
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
-10
1
-10
-10
0
0
Q^2(s, a)
0
0
0
0
1.9
1.9
1
-8
-9.28
\(Q^2(6, \uparrow) =\mathrm{R}(6,\uparrow) + \gamma[.2 \max _{a^{\prime}} Q^{1}\left(2, a^{\prime}\right)+ .8\max _{a^{\prime}} Q^{1}\left(3, a^{\prime}\right)] \)
Q^h (s, a)=\mathrm{R}(s, a)+\gamma \sum_{s^{\prime}} \mathrm{T}\left(s, a, s^{\prime} \right) \max _{a^{\prime}} Q^{h-1}\left(s^{\prime}, a^{\prime}\right), \forall s,a
=\mathrm{R}(s, a)
in general
1
2
9
8
7
5
4
3
6
80\%
20\%
Recall:
\(\gamma = 0.9\)
States and one special transition:
\(Q^h(s, a)\): the expected sum of discounted rewards for
- starting in state \(s\),
- take action \(a\), for one step
- act optimally there afterwards for the remaining \((h-1)\) steps
Q^1(s, a)
0
0
0
1
0
-10
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
-10
1
-10
-10
0
0
Q^2(s, a)
0
0
0
0
1.9
1.9
1
-8
-9.28
\pi_h^*(s)=\arg \max _a Q^h(s, a), \forall s, h
what's the optimal action in state 3, with horizon 2, given by \(\pi_2^*(3)=?\)
in general
either up or right
1
2
9
8
7
5
4
3
6
80\%
20\%
Recall:
\(\gamma = 0.9\)
States and one special transition:
\(Q^h(s, a)\): the expected sum of discounted rewards for
- starting in state \(s\),
- take action \(a\), for one step
- act optimally there afterwards for the remaining \((h-1)\) steps
Given the recursion
Q^{\infty}(s, a)=\mathrm{R}(s, a)+\gamma \sum_{s^{\prime}} \mathrm{T}\left(s, a, s^{\prime} \right) \max _{a^{\prime}} Q^{\infty}\left(s^{\prime}, a^{\prime}\right)
- for \(s \in \mathcal{S}, a \in \mathcal{A}\) :
- \(\mathrm{Q}_{\text {old }}(\mathrm{s}, \mathrm{a})=0\)
- while True:
- for \(s \in \mathcal{S}, a \in \mathcal{A}\) :
- \(\mathrm{Q}_{\text {new }}(s, a) \leftarrow \mathrm{R}(s, a)+\gamma \sum_{s^{\prime}} \mathrm{T}\left(s, a, s^{\prime}\right) \max _{a^{\prime}} \mathrm{Q}_{\text {old }}\left(s^{\prime}, a^{\prime}\right)\)
- if \(\max _{s, a}\left|Q_{\text {old }}(s, a)-Q_{\text {new }}(s, a)\right|<\epsilon:\)
- return \(\mathrm{Q}_{\text {new }}\)
- \(\mathrm{Q}_{\text {old }} \leftarrow \mathrm{Q}_{\text {new }}\)
Q^h (s, a)=\mathrm{R}(s, a)+\gamma \sum_{s^{\prime}} \mathrm{T}\left(s, a, s^{\prime} \right) \max _{a^{\prime}} Q^{h-1}\left(s^{\prime}, a^{\prime}\right)
we can have an infinite horizon equation
Infinite-horizon Value Iteration
if run this block \(h\) times and break, then the returns are exactly \(Q^h\)
\{
\(Q^{\infty}(s, a)\)
Summary
- Markov decision processes (MDP) is nice mathematical framework for making sequential decisions. It's the foundation to reinforcement learning.
- An MDP is defined by a five-tuple, and the goal is to find an optimal policy that leads to high expected cumulative discounted rewards.
- To evaluate how good a given policy \(\pi, \) we can calculate \(V_{\pi}(s)\) via
- the summation over rewards definition
- Bellman recursion for finite horizon, equation for infinite horizon
- To find an optimal policy, we can recursively find \(Q(s,a)\) via the value iteration algorithm, and then act greedily w.r.t. the \(Q\) values.
Thanks!
We'd love to hear your thoughts.
6.390 IntroML (Fall24) - Lecture 11 Markov Decision Processes
By Shen Shen




