Transferred/Compact Convolutional Filters
Outline
- Review of Convolution Network
- Transferred/Compact Filters
-
Compact Filters
- Bottleneck Skill
- Group Convolution
- Depthwise Separable Convolution and 1x1 Convolution
- Dilated Convolution
- Transferred Filters
- Group Equivariant
- Ghost Module
-
Compact Filters
- Classical Models
- SqueezeNet
- MobileNet
- ShuffleNet
- ShiftNet
Review of Convolution Network
Convolution Network Save Parameters
Dense Network
Conv Network
Weights : N x N
Operations : N x N
Weights : 3
Operations : N x 3
Complexity of Convolution Network
Feature Map
MxNxC
A Filter
KxKxC (+1:bias)
Filter 1
A New Channel
(M/s)x(N/s)x1
shift s pixel
Complexity of Convolution Network
Feature Map
MxNxC
A Filter
KxKxC (+1:bias)
Filter 1
Filter 2, 3, ..., D-1
Filter D
New Feature Map
(M/s)x(N/s)xD
Parameters:
A Filter KxKxC
A Conv Layer KxKxCxD
Complexity :
A new pixel KxKxC
A new channel KxKxCx(M/s)x(N/s)
A new feature map KxKxCx(M/s)x(N/s)xD
shift s pixel
Transferred/Compact Filters
Using cheaper mehtods to get information.
Saving parameter numbers or computation cost.

https://www.facebook.com/Lowcostcosplay/
Compact Filters
- Bottleneck Skill
- Group Convolution
- Depthwise Separable Convolution
- Dilated Convolution
Generate feature maps with cheaper method.
Bottleneck Skill
(NxN) : Original
(NxM+MxN = 2xNxM) : Bottleneck
2N/M : Ratio (Less than 1 if M < 0.5N)
Group Convolution
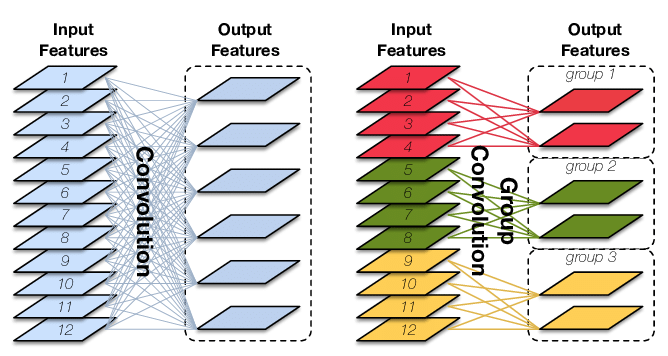
(Input Channels, Output Channles, Kerenl Size)
(C, N, (K x K))
Parameters:
K x K x C x N : Traditional Convolution
K x K x (C/M) x (N/M) x M : M-Groups Group Convolution (=KxKxCxN/M)
1/M : Ratio
https://www.cnblogs.com/shine-lee/p/10243114.html
Issue
Different group will not commucate
Depthwise Seperable Convolution and 1x1 Convolution
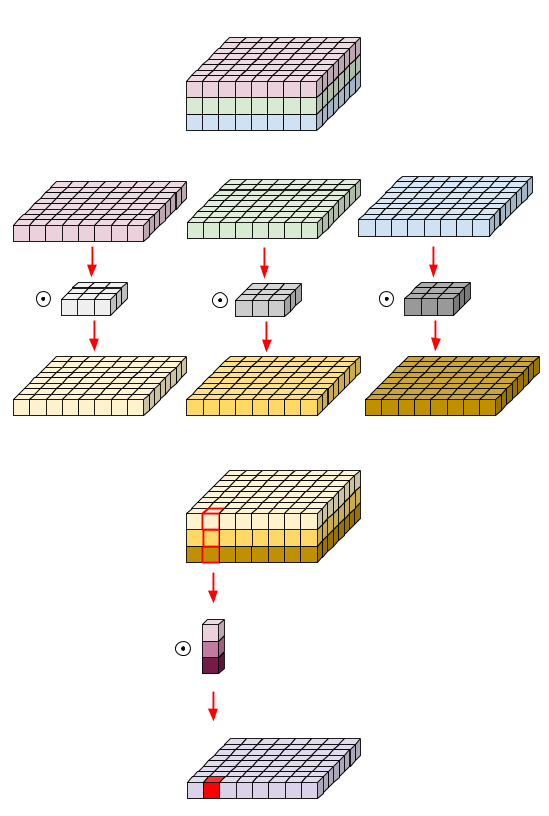
https://medium.com/@zurister/depth-wise-convolution-and-depth-wise-separable-convolution-37346565d4ec
(Input Channels, Output Channles, Kerenl Size):
(C, C, (K x K))
Parameters:
Traditional Convolution
K x K x C x N
============================
Depthwise Seperable Convolution
(C-Groups Group Convolution)
K x K x (C/C) x (C/C) x C
1 x 1 Convolution
1 x 1 x C x N
============================
Ratio (D.S.C. cost ratio+ 1x1 C. cost ratio)
1/N + 1/(K x K)
Dilated Convolution
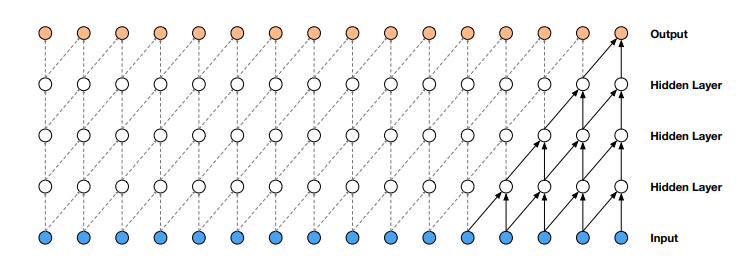
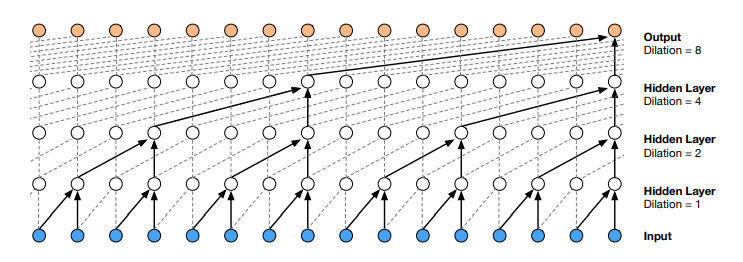
Use dilate method to skip some nodes. If we do this, we can get greater respective fields compare to traditinal convolution.
And each nodes' contribute times are equal.
Oord, Aaron van den, et al. "Wavenet: A generative model for raw audio." arXiv preprint arXiv:1609.03499 (2016).
Convolution
Dilated
Convolution
Transferred Filters
Transfer the existed feature map/filters to get new feature map/filters.
- Group Equivariant
- Ghost Module
Group Equivariant
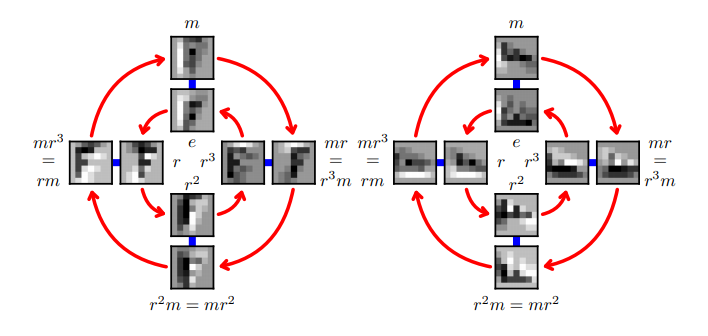
Apply rotate, flip on filters to get more feature map.
No Filp
Filp
90°
180°
270°
8 times more feature maps without adding parameters
0°
Ghost Module(2019 Nov)
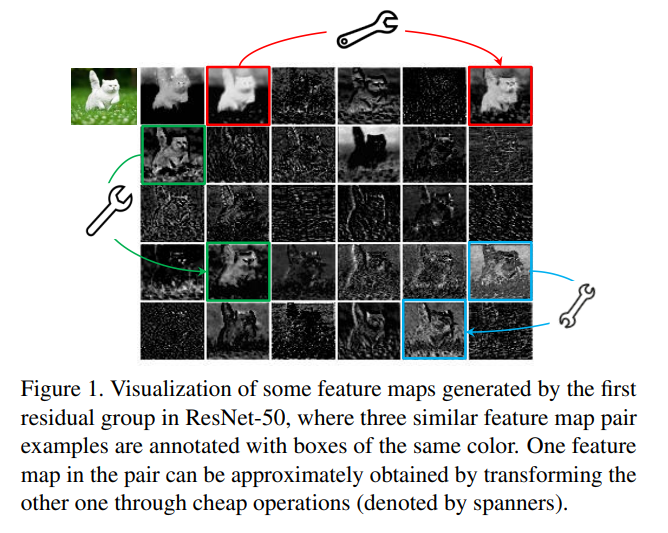
Ghost Module(2019 Nov)
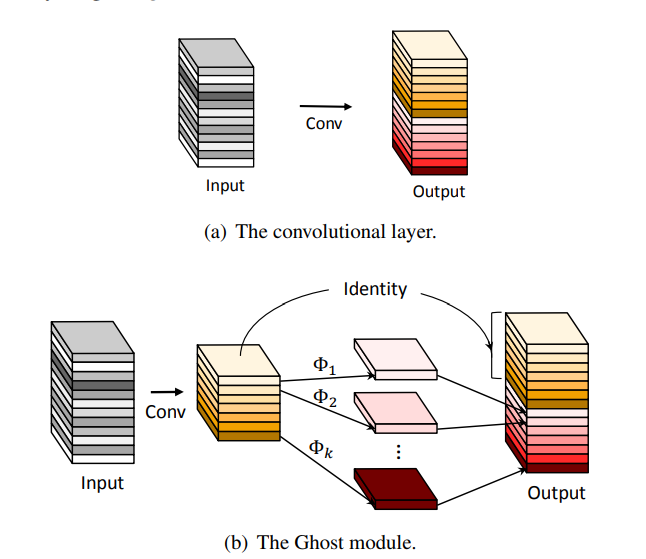
Use a very cheap transform to generate a new feature map base on old features.
Paramters to get a new feature map
Traditional Conv : K x K x C+1
Depth Sep Conv : K x K +1
Ghost Module : 1+1
Classical Models
- SqueezeNet
- MobileNet
- ShuffleNet
- ShiftNet
SqueezeNet(2016)
S_1x1
E_1x1
E_3x3
E_1x1
Concat
Fire Module
Take an example
input channels : 128
output channels : 128
S_1x1 : 16 ((1x1x128+1)x16)
E_1x1 : 64 ((1x1x16+1)x64)
E_3x3 : 64 ((3x3x16+1)x64)
12432 (Block's params)
Traditional Conv
147584 (((3x3x128+1)x128))
Ratio : 0.084
MobileNet(2017)

Take an example
input channels : 128
output channels : 128
3x3 DWConv : (3x3+1)x128
1x1 Conv : (1x1x128+1)x128
Block's Params
1280+16512=17792
Traditional Conv
147584 (((3x3x128+1)x128))
Ratio : 0.12
ShuffleNet(2017)
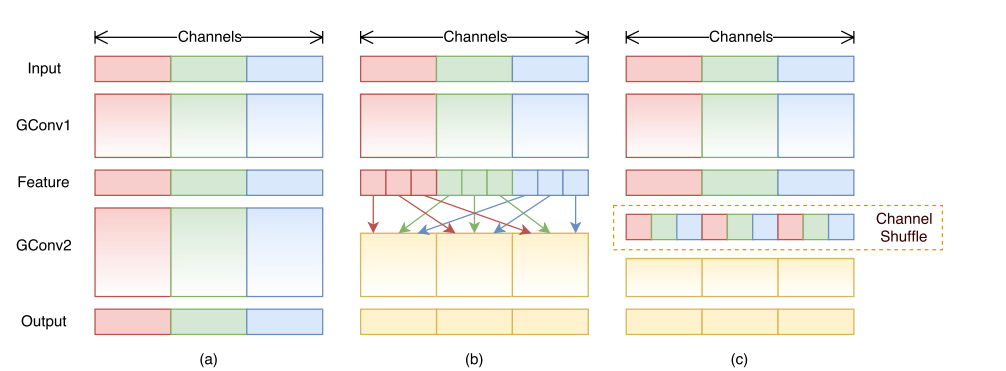
Issue(GConv)
Different group will not commucate
ShuffleNet
Shuffle feature maps to make a feature map can influence other groups' feature map in the future.
ShuffleNet(2017)
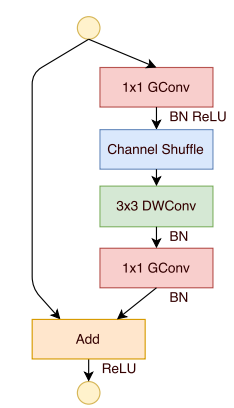
Take an example
input channels : 240
output channels : 240
Bottleneck channels : 240/4=80
Groups : 2
1x1 GConv : (240+1)x80/2
3x3 DWConv : (3x3+1)x80
1x1 GConv : (80+1)x240/2
Block's Params
9640+800+9720=20160
Traditional Conv
518640 ((9x240+1)x240)
Ratio : 0.04
ShiftNet(2017)
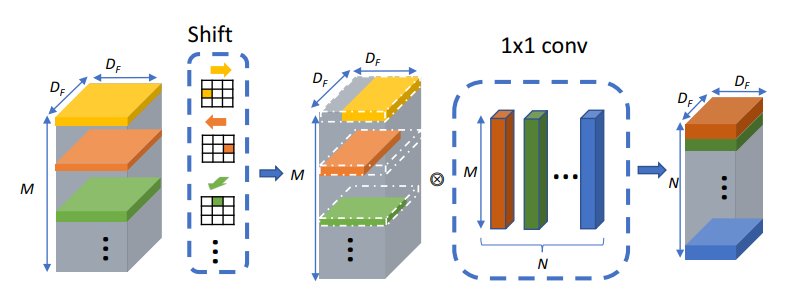
Different from use K x K kernel to increse respective fields, this work shift feature maps to different direction to make differnt location's features can communicate to each other.
# see code (squeezenet, mobilenet, shufflenet, ghostnet)
git clone https://gitlab.aiacademy.tw/yidar/CompactModelDesign.gitSurvey Paper
Cheng, Yu, et al. "A survey of model compression and acceleration for deep neural networks." arXiv preprint arXiv:1710.09282 (2017).
Transferred/Compact Convolution Filters
By sin_dar_soup



