Speeding Up Sum-Check Proving
ZKProof 8 \(\cdot\) Rome
10 May 2026
Quang Dao
Carnegie Mellon University
Zachary DeStefano
New York University
Suyash Bagad\(^{\star}\)
Ingonyama
Justin Thaler
a16z crypto research
Georgetown University
Yuval Domb
Ingonyama
\(^{\star}\)Currently at Aztec, work done while at Ingonyama
Sum-check is everywhere
| Arithmetisation | R1CS: Spartan [Setty '20] Plonkish: HyperPlonk [CBBZ '22] CCS: SuperSpartan [STW '23] |
| Lookup arguments | Lasso [STW '23], Twist & Shout [ST '25] |
| Folding schemes | HyperNova [KS '24], LatticeFold [DC '24] |
| zkVMs | Jolt [AST '24], SP1, Ceno [LXZSCY '24] |
All of these stacks reduce proving to one subroutine: sum-check
Note: This list is non-exhaustive!
Sum-check in Jolt
- Curve BN254, SHA-2 chain, 1000 vs 2000 iterations, run on M4 pro
- Sum-check component starts growing with higher cycle count
3.6 M cycles
sumcheck 35%pcs (dory) 63%48.5 s
100.6 s
7.2 M cycles
sumcheck 46%pcs (dory) 51%- Jolt invokes many sum-check instances; here are the two worth focusing on
Sum-check in Jolt
- For \(\ell = 23\), our optimisations give:
- Jolt invokes many sum-check instances; here are the two worth focusing on
- End-to-end \(25\%\) speedup to Jolt prover only from this paper
\sum_{x} \widetilde{\mathrm{eq}}(\boldsymbol{\tau}, x)\,\Big(\widetilde{A}_z(x)\,\widetilde{B}_z(x) \;-\; \widetilde{C}_z(x)\Big) = 0
Spartan R1CS
degree \(d = 3\), size \(\ell = \textsf{log}(T)\)
\sum_{x} \widetilde{\mathrm{eq}}(r_{\text{cyc}},\, x) \cdot \prod_{t=1}^{d} \widetilde{\mathrm{ra}}_{i,t}(r_{i,t},\, x) = \alpha_i
degree \(d \in \{5, 9, 17, 33\}\), size \(\ell = \textsf{log}(T)\)
Shout Read-Address Virtualization
5,929 ms
546 ms
11\times
2,135 ms
1,247 ms
1.7\times
Sum-check
- Prover claims, for multilinear \(p_1, \dots, p_d: \{0, 1\}^\ell \rightarrow \mathbb{F}\)
\sum_{x \in \{0, 1\}^\ell} \prod_{k=1}^{d} p_k(x) = C
- In round \(j\), prover sends a univariate of degree \(d\)
s_j(X) := \sum_{x \in \{0, 1\}^{\ell - j}} \prod_{k=1}^{d} p_k(\textcolor{FireBrick}{r_1}, \textcolor{FireBrick}{r_2}, \dots, \textcolor{FireBrick}{r_{j - 1}}, X, x)
In Jolt, most of the witness values are 64-bit or smaller
- Insight: exploit smallness of witness
Challenges are 254-bit
Small-value multiplication
\textsf{bb mult}
\times
Multiplications:
Reduction:
Total:
N^2
N^2 + N
2N^2 + N
Trick 1
\textsf{sb mult}
\times
N
N+1
2N+1
\textsf{ss mult}
\times
1
1
-
BN254 (empirical):
BN254 (runtime ns):
36
9
10.50
4.65
29
13
Ratio:
1
0.36
1
Delayed Reduction
Trick 2
S = \sum_{i=1}^{k} \textcolor{lightgreen}{c_i} \cdot \textcolor{FireBrick}{a_i} \ \textsf{mod} \ p
- Reduction is expensive, so don't reduce until you need to
- Using \(\textsf{sb}\) mults: \(k \cdot (2N+1)\)
- Using delayed reduction: \(k \cdot N + N + 1\)
- Nearly \(2\times\) improvement
- Most effective for low-degree sum-check instances: \(d \in \{2, 3\}\)
\times
=
\times
=
\times
=
\vdots
Barrett
Round Batching
Trick 3
- After each sum-check round, instance size reduces by half
p(\textcolor{FireBrick}{r_1},\, \textcolor{#9aa3ad}{x'}) \;=\; \textcolor{FireBrick}{(1 - r_1)} \cdot \textcolor{#ffe66d}{p(0,\, \textcolor{#9aa3ad}{x'})} \;+\; \textcolor{FireBrick}{r_1} \cdot \textcolor{#ffb347}{p(1,\, \textcolor{#9aa3ad}{x'})}
binding with \(\textcolor{FireBrick}{r_1}\)
small values
big values
- Idea: defer binding for first \(v\) rounds

q(\textcolor{#6c7480}{X_1, \ldots, X_v}) \;:=\; \sum_{x' \in \{0,1\}^{\ell - v}}\;\prod_{k=1}^{d}\, p_k(\textcolor{#6c7480}{X_1, \ldots, X_v},\, x').
- Build a single \(v\)-variate polynomial containing all \(v\) messages at once:
Round Batching
Trick 3
- After each round, update \(q\) as \(\forall j \in \{1, \dots, v\}\)

q(\textcolor{#6c7480}{X_1, \ldots, X_v}) \;:=\; \sum_{x' \in \{0,1\}^{\ell - v}}\;\prod_{k=1}^{d}\, p_k(\textcolor{#6c7480}{X_1, \ldots, X_v},\, x').
- Build a single \(v\)-variate polynomial containing all \(v\) messages at once:
q^{(j)}(\mathbf{X}) \;=\; \sum_{u \in U_d} \mathcal{L}_u(\textcolor{#B22222}{r_j}) \cdot q^{(j-1)}(u,\, \mathbf{X})
Round Batching
Trick 3
- If we compare the costs of first \(v\) rounds:
- Main advantage: #\(\textsf{bb}\) mults no longer depend on instance size \(2^{\ell}\)
- Concrete numbers for \(d=3, \ell = 23\) and \(v=4\)
- Naive algorithm costs \(75 \times 10^6 \ \textcolor{FireBrick}{\textsf{bb}} \ \approx 2000 \times 10^6 \ \textcolor{lightgreen}{\textsf{ss}}\)
- Our algorithm costs \(42 \times 10^6 \ \textcolor{lightgreen}{\textsf{ss}}\)

\underbrace{\hspace{2cm}}
50\times
Product of Multilinears
Trick 4
g(x) = \prod_{k=1}^{d} p_k(x) \qquad \forall x \in \mathbb{F}^v
- Suppose we want to compute \(g\) such that
- Naïve: tensor-extend each \(p_k\) to the grid, then multiply pointwise
\underbrace{(d+1)^{v}}_{\textcolor{grey}{\textsf{grid points}}} \,\cdot\, \underbrace{(d-1)}_{\textcolor{grey}{\textsf{mults per point}}} \;\in\; \mathcal{O}\!\left( \textcolor{FireBrick}{d^{\,v+1}} \right) \ \mathsf{bb}
\mathcal{O}(d^v + d \cdot \textsf{log}(d)) \ \textsf{bb}
Our algorithm:
\mathcal{O}(d^{v+1}) \ \textsf{sb}
+
- For \(d=32\) and \(v=1\) we go down from 1023 to 191 bb mults
Product of Multilinears
Trick 4
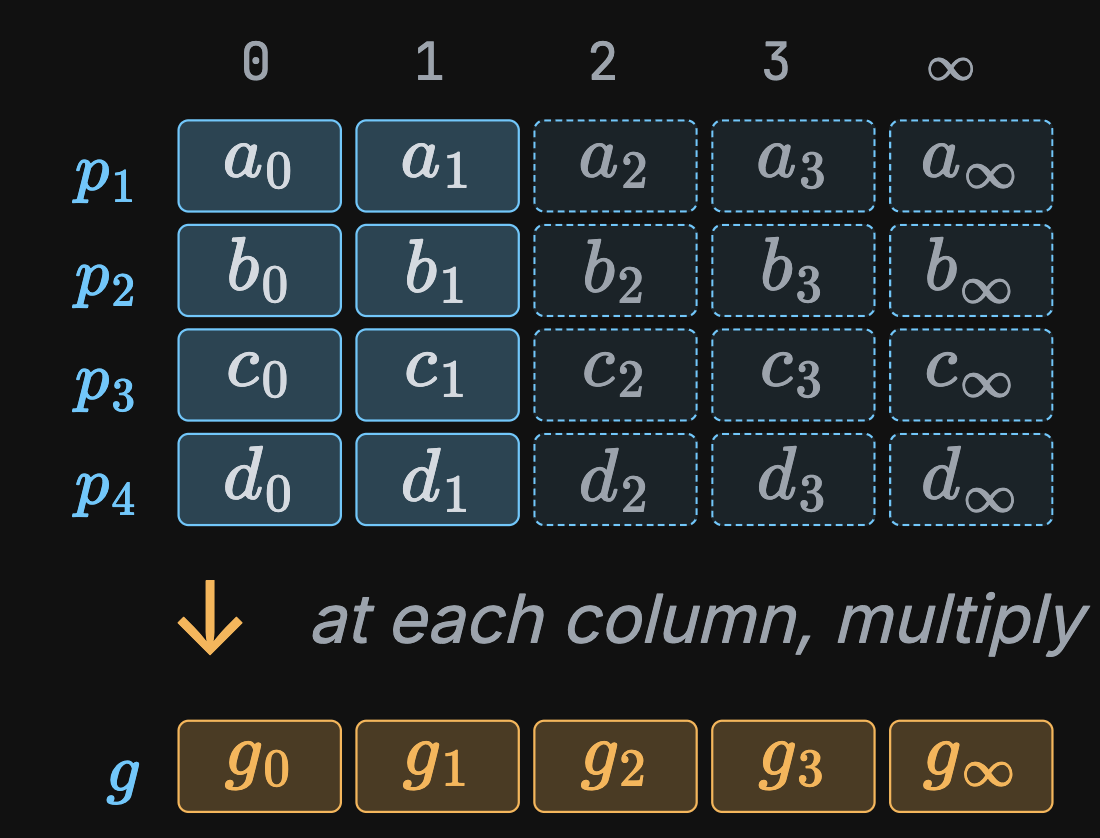
- Suppose we have \(p_1, p_2, p_3, p_4 \in \{0, 1\}\)
- Step 1: Extend to \((d+1)\) evaluations
- Step 2: Point-wise multiply
- Naïve cost: 15 \(\textsf{bb}\) mults
Product of Multilinears
Trick 4
- Suppose we have \(p_1, p_2, p_3, p_4 \in \{0, 1\}\)
- Step 1: Extend to \((d+1)\) evaluations
- Step 2: Point-wise multiply
- Naïve cost: 15 \(\textsf{bb}\) mults
Product of Multilinears
Trick 4
- Suppose we have \(p_1, p_2, p_3, p_4 \in \{0, 1\}\)
- Step 1: Extend to \((d+1)\) evaluations
- Step 2: Point-wise multiply
- Naïve cost: 15 \(\textsf{bb}\) mults
- Split the product in two parts
- Compute the products of the halves
- This costs 6 \(\textsf{bb}\) mults
- Then compute \(g_L \cdot g_R\)
- Total cost: 11 \(\textsf{bb}\) mults


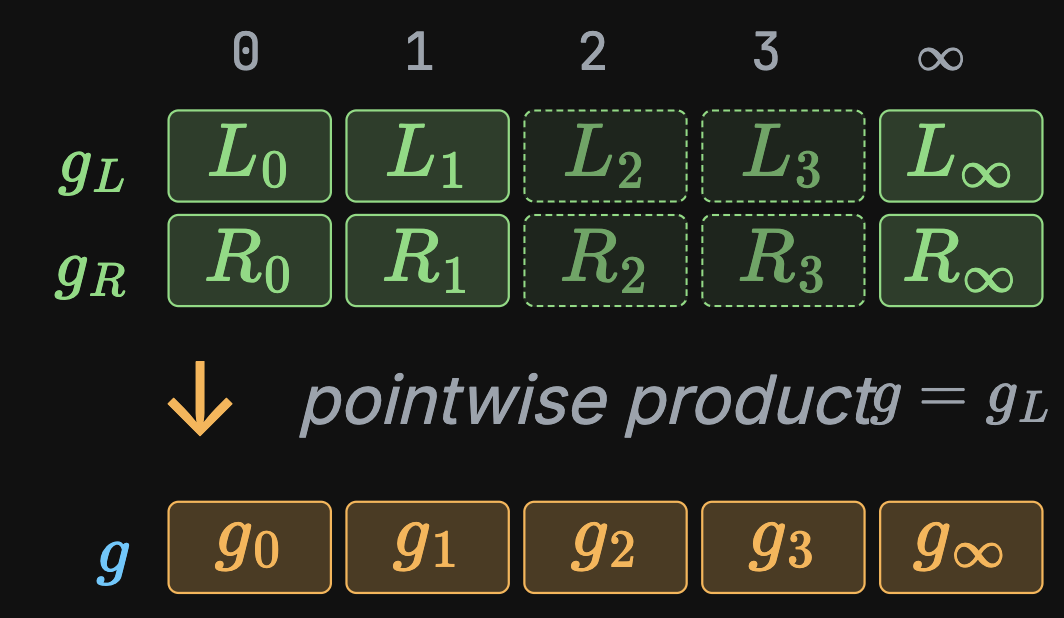
Streaming Sumcheck
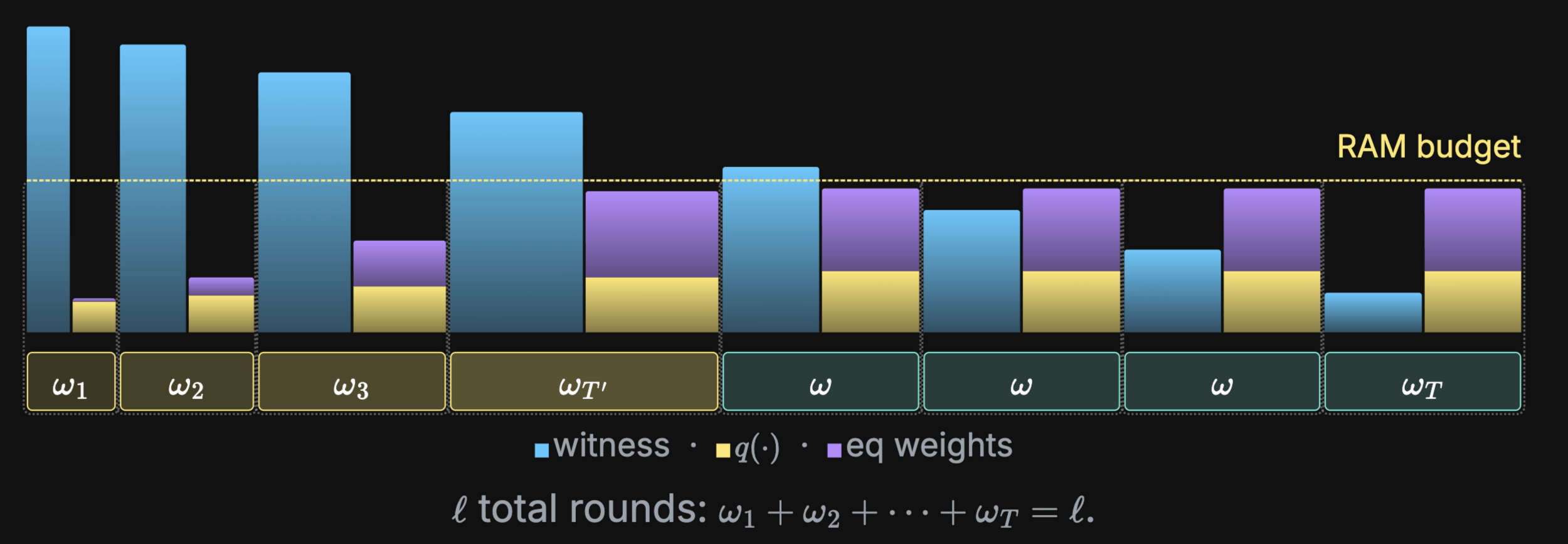
Trick 5
- Split the rounds in windows and use round batching in each of them
\mathcal{O}
\left(\textcolor{FireBrick}{d^2} \cdot
M(k + \textsf{log log M})
\right)
Baweja et al
\mathcal{O}
\left(\textcolor{lightgreen}{d \cdot \textsf{log }d} \cdot
M(k + \textsf{log log M})
\right)
Our paper
Grazie!
Reach out at: x.com/BagadSuyash
Split Eq Polynomial
Trick 6
Univariate skip
Trick 7
Few more tricks in our paper, link: eprint.iacr.org/2026/587
Speeding Up Sum-Check Proving - ZKProof 8
By Suyash Bagad




