Hello World!
李旺陽
ACM-ICPC 2017 泰國第 7
TOI 2!
略玩CTF
熟悉程式語言:
C++ ⭐⭐⭐(從國中寫到現在)
PHP ⭐⭐⭐(寫玩具用)
Python3 ⭐(學好玩的?)


What is ALGORITHM?
演算法是什麼?
- 計算的方法?
- 思考的方法?
- 數學公式?
- 電腦程式?
[al-guh-rith-uh m]

What is ALGORITHM?
- 精確定義演算法是困難的,但他有一些重要特徵
- 0個以上的輸入
- 1個以上的輸出
- 有限多的步驟數可執行完畢
- 每一個步驟都是精確無歧異的
計算理論
- 採用什麼計算模型 Formal Lanauage
- 自動機的設計
- 哪些是能計算的、哪些是不能計算的Computability Theory
- 自動機的能力
- 要用多少時間、要用多少儲存Complexity Theory
- 自動機的效率
Why IOI or ACM contest ?
- 演算法競賽
- IOI, ACM-ICPC
- EDA
- 資安競賽
- CTF
不同型式的資訊競賽
- 黑客松
- Hackathon Taiwan
- 軟體開發
- 很多奇怪的比賽
Keep thinking

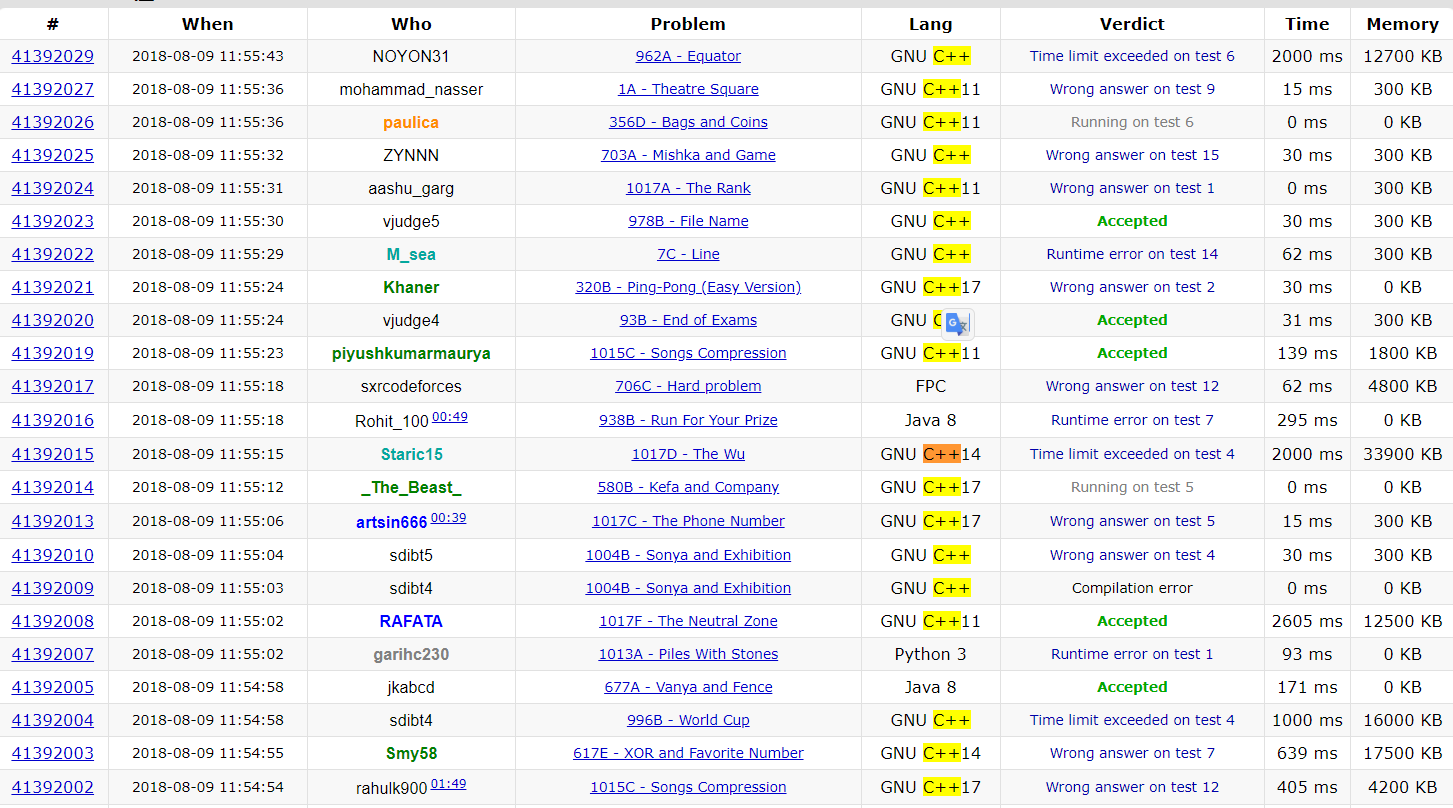
競賽程式開發
- 搞定你的編譯器
Quick Fact
- 絕大多數的選手都使用C++來寫題目
Text
Text
Text
Text
常用的程式語言
| C++ | 最常使用的解題語言 |
|---|---|
| C | 通常從大學才學程式設計的人使用 |
| Java | 解特殊題型 (大數運算) |
| Python 3 | 解特殊/簡單題型 (大數運算) |
C++簡介
- C++ 是一個極端複雜的程式語言
- 把細節學好不容易
- C++ 目前每隔3年進化一個版本
- 目前比賽常用 C++ 11 / 14
C++簡介
- C++ 提供了最不受限制的發揮空間
- C++什麼都不提供、但什麼都寫得出來
- C++什麼都不提供、但什麼都寫得出來
- C++ 版本相容是穩定優秀的
- 新版的C++提供更好的寫法,不太會限制舊的方法
How to use C++
-
編輯器?編譯器?IDE?
- 編輯器:打字的工具、能讓寫Code變輕鬆
- 編譯器:把C++轉換成程式的工具
-
IDE:附贈編譯器的編輯器
Ubuntu上的推薦配置
Gedit + 手動編譯
- NTHU ACM 比賽團隊
為什使用Gedit ?
- gedit是Ubunut下預設會被安裝的編輯器
- 不同的比賽會安裝的編輯器不一樣,但總會有gedit
- 不同的比賽會安裝的編輯器不一樣,但總會有gedit
-
gedit操作簡單(就筆記本),但可以幫程式碼套色/縮排
- 很難玩壞他
Gedit
- 在Ubuntu上地位如同筆記本的編輯器
- 但具有自動套色、縮排的功能
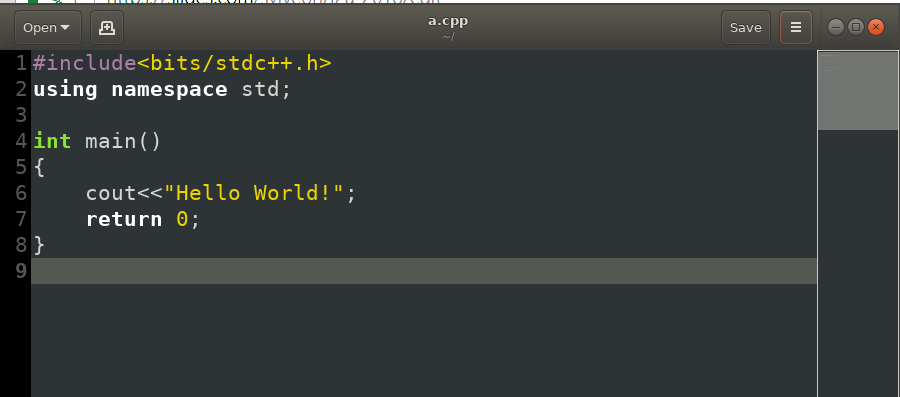
Gedit
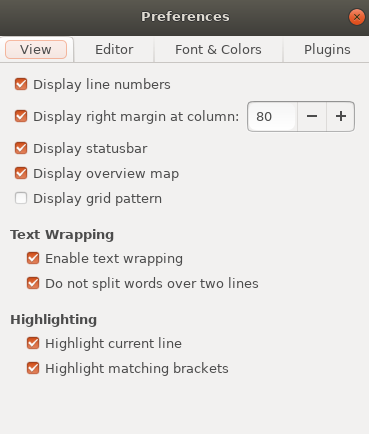
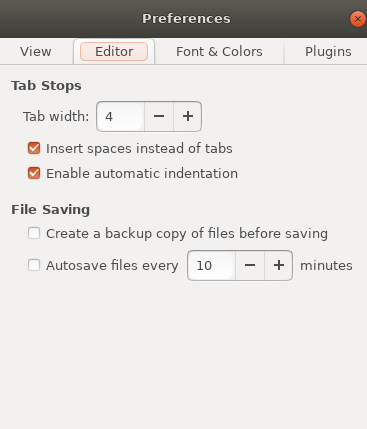
- 環境設定(Preferences)
- 把View/ Editor 可以打勾的都打勾
- 字太小可以到Font調整
手動編譯程式
- 可能需要一點點操作shell的知識
Linux的目錄
- Linux的使用者資料會放在 `\home\使用者名稱` 裡面
- 可以使用波浪號 ~ 來表示
使用者名稱@電腦名稱:目錄$
Linux的目錄
-
使用`pwd`指令可以看目前的目錄名稱
-
使用`ls`指令可以看目錄裡有什麼檔案
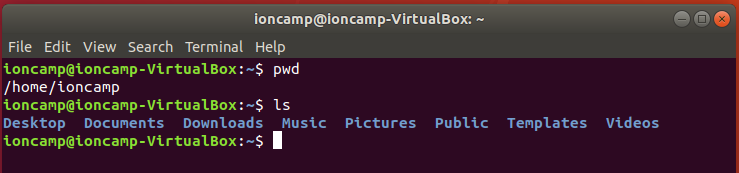
桌面的資料在 Desktop
Linux的目錄
-
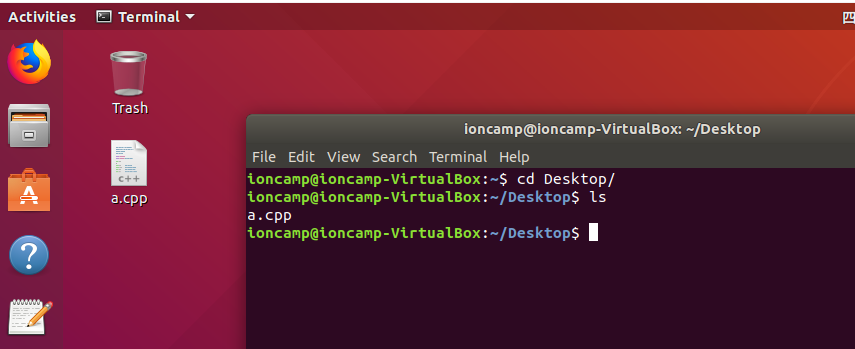
使用`cd 目錄`指令可以進入目錄
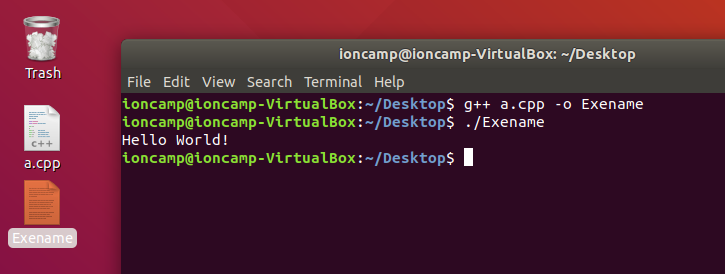
使用編譯器
- 在linux底下,常用的編譯工具為g++
- g++ 同時也為多數比賽使用的工具
其他常見的編譯器有:Clang (Mac, 部分linux使用), MSVC

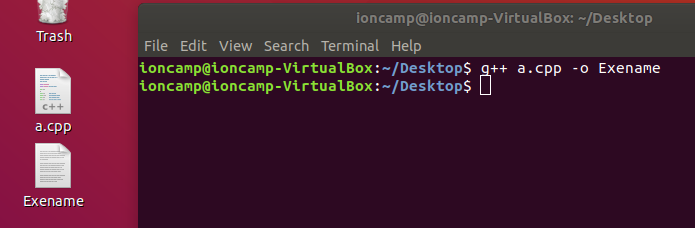
使用g++
-
指令:`g++ C++檔案 -o 程式檔`
-
如果沒有設定 `-o 程式檔` 預設會是a.out
執行程式
-
指令:`./程式檔`
-
注意要有 ./
常見問題
- ls, g++找不到檔案
- 要務必確認Shell的目錄是不是正確的
- 要務必確認Shell的目錄是不是正確的
- g++ 跑出了一大堆錯誤
- 你的程式有錯、需要根據錯誤找問題在哪裡
調教 g++
除了單純的使用之外,通常會附加一些參數來增加功能
- 更改C++的版本
- 更仔細的檢查錯誤
- 開啟優化(加速程式)
調教 g++
- 更改C++的版本
-std=c++XX
C++的版本是最需要注意的選項,設定錯誤可能會導致在不同電腦上編譯錯誤
- C++目前通常比賽使用C++11
- 舊的g++ (5)預設用C++98
- 新的g++ (6)預設用C++14
調教 g++
- 更仔細的檢查錯誤
-Wall -Wextra
讓編譯器顯示更多的錯誤
開起來經常得可以找出意想不到的BUG
調教 g++
- 一些不小心就會犯的錯誤...
int a = -1;
unsigned b = 0;
if( a < b )
cout<<"AC!";
else
cout<<"You dead!";
g++ a.cpp
./a.out
You dead!輸出
調教 g++
- 讓 Wall Wextra 來拯救悲慘的Coding人生!
int a = -1;
unsigned b = 0;
if( a < b )
cout<<"AC!";
else
cout<<"You dead!";
g++ -Wall -Wextra a.cpp
輸出

調教 g++
- 開啟優化
-OX
g++ 可以盡量的在規範內加速你的程式
一般比賽與應用上,都會使用O2優化
開啟優化後,可能會讓未定義行為造成的問題更明顯,讓程式更容易debug
從現在開始更了解比賽吧

讓比賽更順手 - Script
- 如果編譯程式都要打一堆字,會十分的麻煩,因此可以預先撰寫腳本(Script) 預先把指令打好
撰寫 Script
開啟一個文字檔案,在開頭打上`#!/bin/sh`存檔
這個檔案就是一個Script
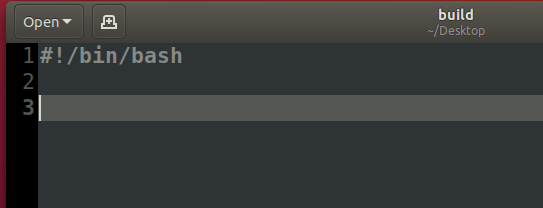
撰寫 Script
存檔之後,要設定這個檔案是可以執行的
- 用滑鼠右鍵檔案 Properties/Permissions
- 點選 Allow executing file as program
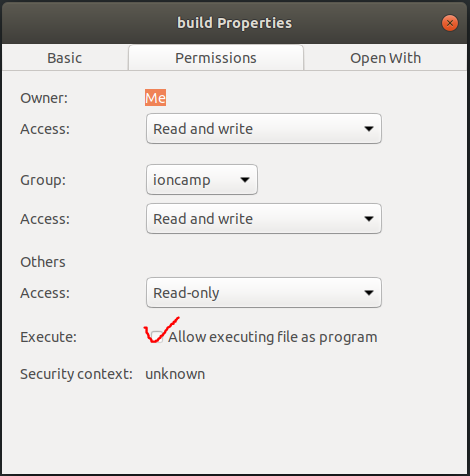
撰寫 Script
- 如果設定正確,用ls看這個檔案會跟執行檔一樣是綠色的名子
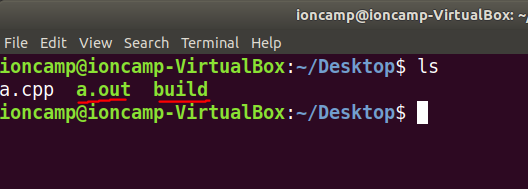
撰寫 Script
- 把剛剛的編譯參數打進去吧!
- 用 $1 來取代檔案名稱
#!/bin/sh
rm a.out # 刪除舊的程式檔案
g++ -std=c++11 -O2 -Wall -Wextra -O2 $1開始使用Script!
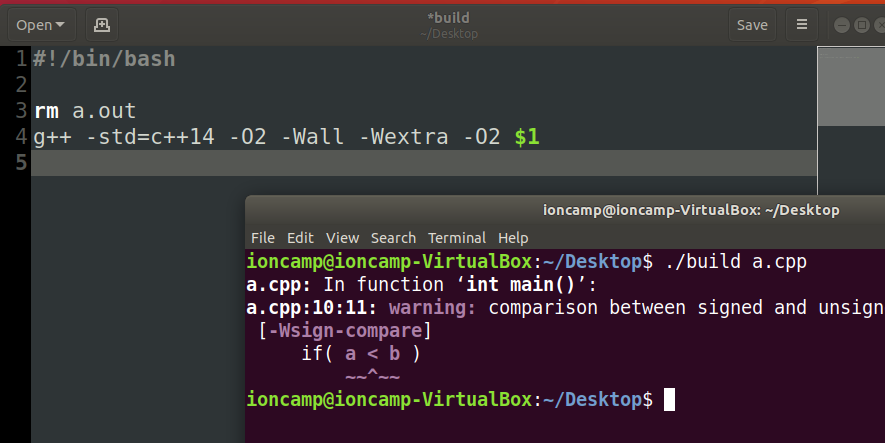
./Script名稱 CPP檔案名
環境的使用
- 在開始撰寫程式之前,好好的認識操作環境非常的重要
- 正確的調整編譯參數,可以避免不必要的錯誤
- 若有足夠的空檔,可以撰寫讓自己更輕鬆的工具
認識題目
程式題目哪裡最重要?
A. 問題描述
B. 輸入與輸出格式
D. 資料大小
C. 範例測資
矩陣是將一群元素整齊的排列成一個矩形...
第一行有三個正整數 R, C, M ...
3 2 3
0<R, C, M <10
要怎麼把題目變難?
把測資範圍多加幾個0就好了
- 某出題者的評論
APCS 2016
第一題
分數(0~100 間)
人數為 1~20 的整數
第二題
三個介於 1~10 之間的正整數
第三題
\(N < 10000\) ,\( 0 \leq L , R < 10000000 \)
\(2 \leq N \leq 100000\)
第四題
測資範圍與難度
- 有經驗的選手往往可以透過測資範圍與範例測資來預估題目的難度與題型
- 測資越大,若要在時限內執行完程式,能使用的方法越受限
- 如果不認真想方法容易TLE
- 也存在測資很小,卻很難的題目...
排序問題
- 現在有\(N\)個數字要排序,數字的範圍在\(0\sim 100\)之間
- 時間限制 1 秒
如果\(N=100\),使用泡沫排序法,程式在1秒內跑得完嗎?
如果\(N=10000\),使用泡沫排序法,程式在1秒內跑得完嗎?
如果\(N=10000\),使用快速排序法,程式在1秒內跑得完嗎?
如果\(N=10000000\),使用快速排序法,程式在1秒內跑得完嗎?
預防TLE
- 在解題時,TLE是最為棘手的狀況
- TLE表示程式無法在時限內完成(無論對錯)
- TLE幾乎只能透過使用更好的演算法解決
- TLE幾乎只能透過使用更好的演算法解決
- 因此解題目時需要一種方法來衡量程式的速度
Time Complexity
時間複雜度
好的演算法?
- 想法很簡單?
- 實作很簡單?
- 廢話比較少?
- 需要的計算量很少?
時間複雜度
- 用來描述一個演算法需要用多少計算時間來解決問題
- 找\(N\)個元素最大值
- 需要至少把每一個元素都檢查一次
- 找\(N\)個元素最大值
int mx = a[0];
for(int i=1;i<N;++i)
{
mx = max( mx , a[i] );
}Big-O 表示法
- 計算機科學中,使用符號\(O\)表示一個函數的成長關係
如果\(f(x)\in \mathcal{O}(g(x))\)
就存在\(c\)與\(x_0\)
如果\(x>x_0\)
\(c\times g(x)\geq f(x)\)
Big-O 表示法
如果\(f(x)\in \mathcal{O}(g(x))\)

Big-O 表示法
如果\(f(x)\in \mathcal{O}(g(x))\)
就存在\(c\)與\(x_0\)
\(x_0\)
\(c\times\)
Big-O 表示法
如果\(f(x)\in \mathcal{O}(g(x))\)
就存在\(c\)與\(x_0\)
如果\(x>x_0\)
\(x_0\)
\(c\times\)
\(x\)
Big-O 表示法
如果\(f(x)\in \mathcal{O}(g(x))\)
就存在\(c\)與\(x_0\)
如果\(x>x_0\)
\(c\times g(x)\geq f(x)\)
\(x_0\)
\(c\times\)
\(x\)
\(c\times g(x)\)
\(f(x)\)
Example
- 證明\(x^2-x+2 \in O(x^2)\)
Example
- 證明\(x^2-x+2 \in O(x^2)\)
如果\(x\geq1\)
\(x^2-x+2\)
\(\leq x^2+x+2\)
\(\leq x^2+x^2+2x^2=4x^2\)
Example
- 證明\(x^2-x+2 \in O(x^2)\)
如果\(x\geq1\)
\(x^2-x+2\)
\(\leq x^2+x+2\)
\(\leq x^2+x^2+2x^2=4x^2\)
設\(c=4,x_0=1\)
如果\(x_0\leq x\)
\(x^2-x+2\leq cx^2\)
因此
\(x^2-x+2 \in O(x^2)\)
Fact
- 對於多項式\(f(x)=a_0+a_1x+a_2x^2+\cdots +a_nx^n\)
\(f(x)\in \mathcal{O}(x^n)\)
- 多項式的複雜度就是\(x\)次數最大的項
- 當\(x\)很大的時候,其他的數字比例小的可以忽略
演算法與Big-Oh
- 計算演算法對於任意資料,要花費幾個基本運算算完
- 基本運算ex:
- 基本型態的加減乘除(3+5)
- 存取一個基本型態的資料
- 寫入一個基本型態的資料
- 基本運算ex:
- 計較細節的操作過於瑣碎,因此使用bigO來表達
Example
- 計算下演算法的BigO複雜度
// Find max value index in array
int index = -1;
for(int i=0;i<N;++i)
{
bool flag = true;
for(int j=0;j<N;++j)
{
if( a[j] > a[i] )
flag = false;
}
if( flag )
index = i;
}如果一個演算法複雜度是\(O(x^2)\),表示該方法最糟不會比所有\(O(x^2)\)的方法糟糕
Example
- 計算下演算法的BigO複雜度
// Find max value index in array
int index = 0;
for(int i=1;i<N;++i)
{
if( a[i] > a[index] )
index = i;
}Order of the Function
- 由BigOh我們可以發現函數的成長幅度有階級關係
- 如果\(f(x)\)是\(O(x)\),那它也是\(O(x^2)\)
- 如果一個函數的階級越大,數值成長速度越快
\(O(x^5)\)
\(O(x^3)\)
\(O(x)\)
Order of the function

Quick fact
- 複雜度由小到大排列
- \(O(1)\) 用公式解解一元二次方程式
- \(O(\alpha (n) )\) Disjoint Set
- \(O(logn)\) 二分搜尋法
- \(O(\sqrt{n})\)
- \(O(n)\) 找最大值
- \(O(n\log n)\) C++的排序
- \(O(n^2)\) 泡沫排序法
\(O(\log n!)=O(n\log n)\)
Quick fact
- 複雜度由小到大排列
- \(O(nlogn)\) C++的排序
- \(O(n^2)\) 泡沫排序法
- \(O(n^3)\) 普通矩陣乘法
- \(O(e^{\left(c + o(1)\right)(\ln n)^{\alpha}(\ln \ln n)^{1-\alpha}})\) 我覺得這很酷
- \(O(2^n)\) 旅行推銷員問題DP
- \(O(n!)\) 枚舉排列組合
競賽的經驗法則
- 假設對於一個題目想到了複雜度是\(O(N^2)\)的方法
- 這個方法會不會TLE呢?
把題目測資上限\((N=20000)\)代入
如果大於\(10^8\),基本上就會TLE
Input & Ouput
C/C++基本輸入輸出方法
scanf/printf
cin/cout
不論喜歡用何種方法,至少要熟悉一套
C++ Stream
cin
getline
鍵盤輸入
檔案輸入
串流輸入
C++中只要知道串流怎麼操作
就能處理任意能接上串流的資料
標準輸入STDIN
標準輸出STDOUT
cout
鍵盤輸出
檔案輸出
串流輸出
cin
- 從標準輸入讀取資料到變數中
int a;
double b;
cin>>a>>b;輸入重導向
- 一般的作業系統都支援修改程式標準輸入的方法
- 除了鍵盤之外,另一個常使用的方法為檔案輸入
./a.exe < input.txt輸入的處理觀念
- 輸入輸出是程式單位操作最慢的地方
- 盡可能地不依賴複雜的處理函數
- 把資料先讀取進變數中再處理
Cout
- 把資料輸出到標準輸出中
int a = 1234;
cout >> a >> endl;輸出的重導向
- 與輸入一樣,作業系統通常支援把輸出傳送至檔案中
./a.out > answer.txt
./a.out < test.in > res.out # 可以一起用C 語言的輸入輸出
int a;
scanf("%d", &a);
printf("%d", a);C語言無法自動判斷型態,要透過%d等標記來協助
C語言的小數輸入與輸出
| float | double | long double | |
|---|---|---|---|
| scanf | f | lf | Lf |
| printf | f | f | Lf |
| printf(C++11) | f | lf, f | Lf |
scanf/printf語言的標記在不同標準上會有差異
輸入EOF
- 如果題目要求以EOF結尾,要怎麼在鍵盤上輸入?
Ctrl+Z
如何判斷EOF - C++
- C++ 當遇到輸入錯誤時,cin 會回傳 false
int a;
while( cin>>a )
{
//輸入成功就重複執行
}如何判斷EOF - C
- C 當遇到輸入錯誤時,scanf 會回傳 EOF
int a;
while( scanf("%d", &a) != EOF )
{
//輸入成功就重複執行
}字串
C語言的字串為使用 \0 結尾的字元陣列
char str[100] = "C Style String";C++語言的字串為string物件
string str = "C++ string";字串的使用
- C++可以同時使用C-Style String以及自己的string
- C語言只能使用 C-Style String
C++的字串可以自動控制長度,可以減少陣列長度不夠的問題
C語言的字串若善加使用,效率比C++還要好
整行讀取
- 如果資料太過於複雜,為了避免過多的IO操作,會把資料一次的讀取到字串後,再用其他方法處理
| C | C++ | |
|---|---|---|
| C字串 | fgets | cin.getline |
| C++字串 | getline |
cin.getline
- 不斷讀取直到遇到換行符號
char buf[100];
cin.getline(buf, 100);這程式可以讀幾個字元?
陣列開大一點,不會有問題;陣列開小一點,絕對會出事
More Example
- 這個程式會輸出什麼?
int a;
char buf[10];
cin >> a;
cin.getline(buf, 10);
cout << a << "," << buf << "<";123
abc輸入
輸出
123,<消失的abc
- cin 讀取資料時,會把不必要的資料(換行)留在串流中
int a;
cin >> a;| 1 | 2 | 3 | \n | a | b | c |
|---|
cin 開始讀取整數給a
消失的abc
- cin 讀取資料時,會把不必要的資料(換行)留在串流中
int a;
cin >> a;| 2 | 3 | \n | a | b | c |
|---|
cin 開始讀取整數給a
| 1 |
|---|
消失的abc
- cin 讀取資料時,會把不必要的資料(換行)留在串流中
int a;
cin >> a;| 3 | \n | a | b | c |
|---|
cin 開始讀取整數給a
| 2 |
|---|
消失的abc
- cin 讀取資料時,會把不必要的資料(換行)留在串流中
int a;
cin >> a;| \n | a | b | c |
|---|
cin 開始讀取整數給a
| 3 |
|---|
消失的abc
- cin 讀取資料時,會把不必要的資料(換行)留在串流中
int a;
cin >> a;| \n | a | b | c |
|---|
cin 發現不是數字,停止讀取
| \n |
|---|
消失的abc
- cin 讀取資料時,會把不必要的資料(換行)留在串流中
getline(buf, 10);| \n | a | b | c |
|---|
cin.getline開始讀取
消失的abc
- cin 讀取資料時,會把不必要的資料(換行)留在串流中
getline(buf, 10);| a | b | c |
|---|
cin.getline讀取到換行,直接結束
| \n |
|---|
消失的abc
- 如果要混合使用一般讀取與整行讀取,要把多餘的換行吃掉
int a;
char buf[10];
cin >> a;
cin.get(); // 讀一個字元
cin.getline(buf, 10);
cout << a << "," << buf << "<";123
abc輸入
輸出
123,abc<小練習
- 這會輸出什麼?
int a;
char buf[10];
cin >> a;
cin.getline(buf, 10);
cout << a << "," << buf << "<";123 abc輸入
輸出
123, abc<getline
- C++ 字串用的讀取方法
string str;
getline(cin, str);
cout << str ;參數的設計有點詭異
fgets
- C 字串用的讀取方法
- 會把換行也讀到字串中!
char buf[10];
fgets(buf, 10, stdin);
cout << buf << "X";abcd1234\n
輸入
輸出
abcd1234
X
fgets
- 透過一點方法拿掉換行...
char buf[10];
fgets(buf, 10, stdin);
// 如果沒有換行符號會RE!
*strchr(buf, '\n') = 0;
cout << buf << "X";abcd1234\n
輸入
輸出
abcd1234X
strchr : 找到字串中某個字元的位置
Stringstream
字串串流
A+B+C...問題
在一行裡面有很多個數字,你能把數字都加起來嗎?
123 456 789
1 2 3 4 5 6 7 8 9 10
111368
55
11範例輸入
範例輸出
讀取一筆測資
- 如果要能讀取一筆測資,就要能判斷是不是讀到換行符號
- 目前教過了哪些輸入方法可以判斷換行?
不要在輸入函數上做太多動作
整行讀取
- 既然資料都在同一行中,不如就直接整行讀近來!
string buf;
while( getline(cin, buf) )
{
}分解字串
- 我們需要的數字都被空白符號隔開了
- 要如何簡單的處理?
"123 456 789"字串串流
- 在sstream中
- 可以把字串同時當cin, cout來使用!
- 是分割字串、型態轉換的強大工具!
#include<sstream>
std::stringstream ss;字串串流
- 把東西塞入字串串流中,用法等於cout
#include<sstream>
std::stringstream ss;
ss << "1234" << ' ' << 5678;
//ss現在為 "1234 5678"字串串流
- 把東西從字串串流拿出,用法等於cin
ss << "1234" << ' ' << 5678;
//ss現在為 "1234 5678"
int a;
ss >> a; // a = 1234, ss現在為 " 5678"
ss >> a; // a = 5678, ss現在為 ""字串串流
- 使用字串串流可以很輕鬆的分解以空白隔開的資料
- 字串串流的使用等同cin, cout,不用多記用法
A+B+C..
- 利用字串串流,就可以靈活的處裡繁複的輸入
- 若要重複使用要初始化!
string buf;
stringstream ss;
while( getline(cin, buf) )
{
ss.clear(); // 記得初始化
ss.str(buf); // 直接設定串流裡面的資料
int tmp, ans = 0;
while( ss >> tmp ) ans+=tmp;
cout << ans;
}C++的IO優化
C++的惡名
- 在打比賽時,聽聞過很多C++的cin/cout很慢,會TLE
- 該理由也是部分選手用scanf/printf的原因
真相是什麼?
萬惡的淵藪
std::flush
清除輸出串流內的資料
C++的輸出機制
- C++的輸出是非同步的
- 使用cout指令時,不一定會立刻輸出資料
- 會累積到一定的數量在一起輸出
如果操作的對象是檔案,那這個策略是必要的
因為硬碟動一次的代價很大,不一次做多一點事會很浪費時間
std::flush
- 正確的使用flush,可以讓資料即時產生
- 錯誤的使用flush,會讓前面的優化失效
大部分的OJ都會把標準輸出變成檔案輸出,讓問題更加明顯
可是哪裡用了flush ?
隱藏的陷阱
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a;
while( cin >> a )
{
cout << a << endl;
}
}
哪裡用到了flush ?
endl
-
根據C++的標準,用一次cout<<endl等於
cout << '\n' << flush;
從今天開始,不要亂用endl,用 '\n'代替它
cout
- 因為歷史因素,如果要同時讓C的輸出與C++的輸出一起運作,需要做很多奇怪的同步處裡(可能會flush)
如果不用這個同步功能,可以把它關掉
ios::sync_with_stdio(false);
// 關掉後就不可以cout / printf 混用cin
- 每次cin前,會把綁定的cout做一次flush
因為OJ不會即時的看答案對不對,因此不需要這個功能
因此可以取消這功能
cin.tie(0);
// 關掉後 cout的資料就不一定會立刻顯示C++的IO優化
- 確實的處裡這些問題,C++的輸入輸出是比C還要快的。
- 使用C++解題的同學務必知道這些優化方法
#include<bits/stdc++.h>
using namespace std;
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
int a;
while( cin >> a )
{
cout << a << '\n';
}
}
C++ 基本知識
標頭黨
- C++可以使用C的函數庫,為了相容性,雖然可以使用舊的名子,但C++應該要使用C++的標頭檔
| stdio.h | cstdio |
| string.h | cstring |
| stdlib.h | cstdlib |
| ctype.h | cctype |
XXX.h \(\Rightarrow\) cXXX
未定義行為
Undefined Behavior
- C / C++ 最困難之處,寫出來會動的程式碼不代表是正確的
- 未定義行為通常是邏輯錯誤,不可執行預測結果
- 寫程式時要避免未定義行為的發生
常見未定義行為 - 除0
- 除以0是常見的錯誤,其結果不能預測
- 程式若發生通常會直接當機
cout << 1 / 0 << endl;常見未定義行為 - 溢位
- Debug最困難的,不是會當掉的程式,而是有bug但正常運作的程式
int x = 2147483647; //int 最大值
if( x+1 > x )
cout << "Ya!" << endl;
else
cout << "溢位" << endl;
int 加超過範圍會變成負數,正確嗎?
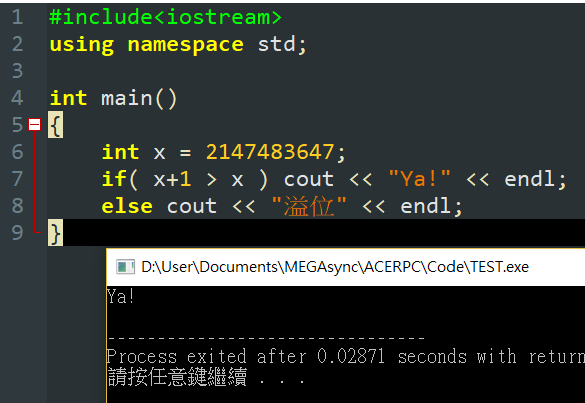
未定義行為
- 未定義行為的結果C++標準不保證是什麼
- 編譯器遇到未定義行為可以任意的處置
- 再編譯器開啟優化時,任意的處置造成的效果會放大
未定義行為
if( x+1 > x )
當x不是最大值時,判斷式成立 ( true )
當x是最大值時,雖然二補數下+1會變負數,但是C++規定int計算超出範圍是未定義行為,數值未定。因此編譯器為了優化,可以認為此時 x+1 會大於 x ( true )
經過編譯器的調教後...
if( x+1 > x )
cout << "Ya!";
else
cout << "溢位";if( true )
cout << "Ya!";
else
cout << "溢位";cout << "Ya!";
珍惜人生,遠離未定義行為
浮點小數
- 不要用float
- 不要用float
- 不要用float
- 因為很重要所以說三次
電腦的小數
- 在現代電腦中,小數與整數的儲存方法不太一樣
- 整數:二補數 \(87_{10}=1010111_2\)
- 小數:科學記號 \(3.14\approx 1.57\times 2^1\)
01000000010010001111010111000011
=3.1400001049041748046875
使用小數,就有誤差
- 在電腦中存小數,會設法以最接近的數字來表示
- 有可能比原來大,也可能比原來小
若能避免使用小數,就應該避免
否則要小心處理誤差的問題
小數等於
- 小數部能夠直接判斷等於,因為計算的誤差可能讓結果變成超接近的數字,但不是期望的數字
double x;
cin >> x;
if( x==5 ); 容易出問題
if( std::abs( x - 5 ) < 1E-6 ); 要容許一點誤差你覺得這是幾次⽅?
- 如果A,B,C都是正整數,如果\(A^B=C\),給你A,C,可以求出B嗎?
C=243, A=3, B=?
優秀的解答?
- 使用高中公式,可以得到\(B=\log C/\log A\)
- 很剛好的C++可以算\(\log\)
double A, C;
cin >> C >> A;
int B = log(A) / log(C);
cout << B;243 3輸入
輸出
4世界就是這麼剛好
log(243)/log(3) = 4.99999999999999911182158029987
計算結果比原來數字小了一點
轉成int,小數部分全部變不見
打包資料
打包資料
- 有的時候會想要把有關聯的資料(ex 座標)合併在一起,同步操作,在C++有許多種方法可以使用
| 資料數量 | |
|---|---|
| struct/class | 任意多 |
| std::pair | 2 |
| std::tuple | 任意多 |
struct
- 在C++中,struct與class功能一樣,除了預設物件屬性不同,一般而言比賽都用struct。
//定義
struct Point{
int x;
int y;
string name;
};
//宣告
Point data, array[666];
//使用變數
data.x = data.y = array[2].x = 7122;
data.name = "StarStar";建構子
- 在變數被宣告時,呼叫用來初始化的函數
struct Info{
string name;
Info(){ //建構子
name = "7122";
}
};
Info data; //會呼叫建構子
cout<< data.name ;
Output:
7122有參數的建構子
- 在變數被宣告時,呼叫用來初始化的函數
struct Point{
int x;
int y;
Point(int a,int b){ //建構子
x=a; y=b;
}
};
Point data(94,87); //會呼叫建構子
cout<< data.x << ' ' <<data.y ;
Output:
94 87有參數的建構子
- 存在自定義建構子時,不會生成預設(無參數)建構子
struct Point{
int x;
int y;
Point(int a,int b){ //建構子
x=a; y=b;
}
};
Point data; //ERROR!
Output:
Compile Error!
Can not find Point()有參數的建構子
- 存在自定義建構子時,不會生成預設(無參數)建構子
struct Point{
int x;
int y;
Point(int a,int b){ //建構子
x=a; y=b;
}
Point(){ //建構子 called
x=1; y=2;
}
};
Point data;
cout<<x<<' '<<y;
Output:
1 2std::pair
- 把兩個型態綁一起
using pis = pair<int,string>; //C++11
pii data;
data.first = 123;
data.second = "ABC";
data = {123,"ABC"};
data = make_pair(123,"ABC");std::pair
- std::pair支援比較運算,皆以字典序比較
using pii = pair<int,int>;
pii a[3] = { {2,1},{1,2},{3,0} };
sort( a,a+3 );
for( auto v:a )
cout<<v.first<<' '<<v.second<<endl;Output:
1 2
2 1
3 0std::pair
- 兩個不夠用,可以自己套自己 = =
using piii = pair<int,pair<int,int>> ; //C++11
using piii2= pair<int,pair<int,int> > ;
piii a;
a.first = a.second.first = a.second.second = 87std::tuple (c++11)
- 把任意多的資料綁一起
#include<utility> //also in algorithm
using tiii= tuple<int,int,int>;
tiii a;
a = {1,2,3}; // C++14 and g++ >= 6
a = make_tuple(1,2,3); // Always OK
std::tuple (c++11)
- tuple拆解資料
using tiii= tuple<int,int,int>; //C++11
tiii a = {1,2,3};
auto [i,j,k] = a; //C++17
int i,j,k;
tie(i,j,k) = a; //Always OK
i = get<0>(a);
j = get<1>(a);
k = get<2>(a); //Always OK
Basic Data Structure
with STL
What is STL
- C++ Standard Template Library
- 由標準實作的演算法與資料結構
- 目前規格書約有1600頁
- 多用多查資料
- cppreference(白)
- cplusplus(藍)
C++ 標準
- 目前的最新C++標準是C++17
- 大多數比賽使用C++11/14
- 從2017年開始ACM-ICPC使用C++14為競賽標準
- 大陸OJ通常連C++11都沒有
vector
- 中文翻譯為「向量」,不過沒人用
- 強化版的陣列,大小可以自動變大
- 在尾部的元素操作效率佳
#include<vector>
vector<int> arr;
arr.resize(N); //設定大小為N
arr[0] = arr[N-1] = 1; //與一般陣列一樣錯!錯!錯!
- 請不要這樣開陣列
- C++該語法不合法,且容易造成Stack overflow
int a;
cin>>a;
int arr[a]; // Error!讓vector拯救你的陣列
int a;
cin>>a;
vector<int> arr(a);vector 新增元素
- 使用emplace_back或是push_back在最後方新增元素
- 複雜度為平攤\(O(1)\)
- emplace_back常數比較小,建議使用
vector<int> v;
v.push_back(1); //不建議使用
v.emplace_back(2);
for(int i:v) cout<<i<<' ';Output:
1 2push_back
push_back( 我是資料 )
我是資料 (2)
複製
| 我是資料 |
|---|
複製
push_back要複製資料2次
emplace_back
emplace_back( 我是資料 )
直通終點
| 我是資料 |
|---|
複製
emplace_back要複製資料2次
vector 新增元素 - 2
vector<tuple<int,int,int>> v;
v.push_back(make_tuple(4,5,6));
//只有emplace_back可以這樣縮減歐~
v.emplace_back(7,8,9);
for(auto [i,j,k]:v) //C++17
cout<<i<<' '<<j<<' '<<k<<endl;Output:
1 2 3
4 5 6
7 8 9
emplace_back的括號可以當作是呼叫建構子
提問時間
Any Questions?
Intro to algorithm 2019
By sylveon
Intro to algorithm 2019
Intro to algorithm




