Russ Meeting
2023/05/15
Contributions
1. We ask: Is it possible to bypass the difficult problem of statistical uncertainty quantification and directly use distance-to-data?
2. Amortization of this computation using diffusion score-matching (we make this computation batch-trainable)
3. Propose a class of algorithms that reinterpret and incorporate existing algorithms into a more coherent framework for MBRL (by framing them as KL-regularized planning between occupation measure and perturbed data distribution)
Review of Method
\begin{aligned}
\min_{x_t,u_t} \quad & \sum_t c(x_t,u_t) - \beta \sum_t \log p (x_t, u_t) \\
\text{s.t.} \quad & x_{t+1} = f(x_t, u_t) \quad \forall t
\end{aligned}
Single Shooting
\begin{aligned}
\min_{x_t,u_t} \quad & \sum_t c(x_t,u_t) - \beta \sum_t \log p_\theta (x_t, u_t) \\
\text{s.t.} \quad & x_{t+1} = f_\alpha(x_t, u_t) \quad \forall t \\
\alpha^* = & \text{argmin}_\alpha \mathbb{E}_{x,u,x'} \|f_\alpha(x,u) - x'\|^2
\end{aligned}
Collocation
\begin{aligned}
\min_{x_t,u_t} \quad & \sum_t c(x_t,u_t) - \beta \sum_t \log p_\theta (x_t, u_t, x_{t+1}) \\
\end{aligned}
Review of Method
Previously....
Uncertainty Metric
Type of Gradient
Choice of Transcription
Ensembles
Data Distance
GPs
Dropouts
First
Zeroth
Shooting
Transcription
Why Ensembles vs. Data Distance?
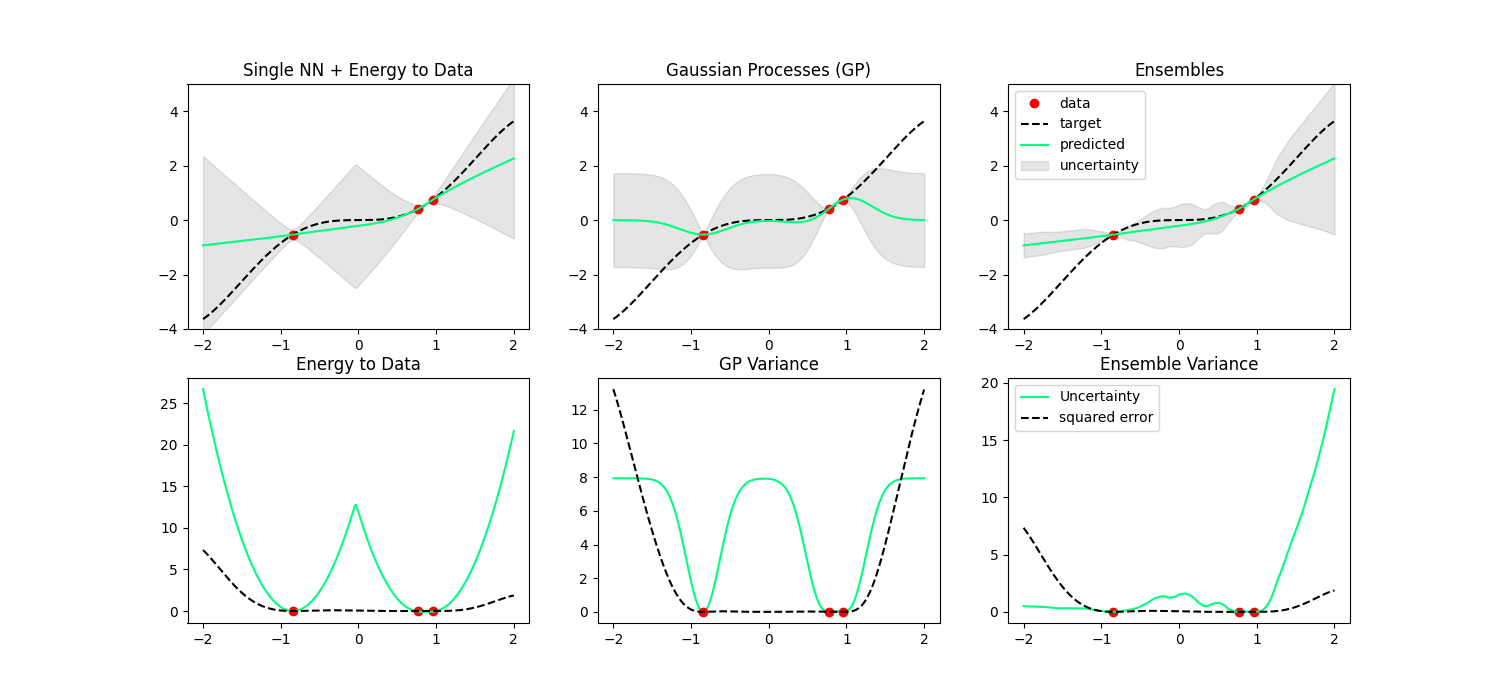
1. Data distance is stable to data as an uncertainty metric
2. Data distance never underestimates uncertainty if scaled appropriately.
* Side question: Data distance? Data energy?
What's really wrong with ensembles?
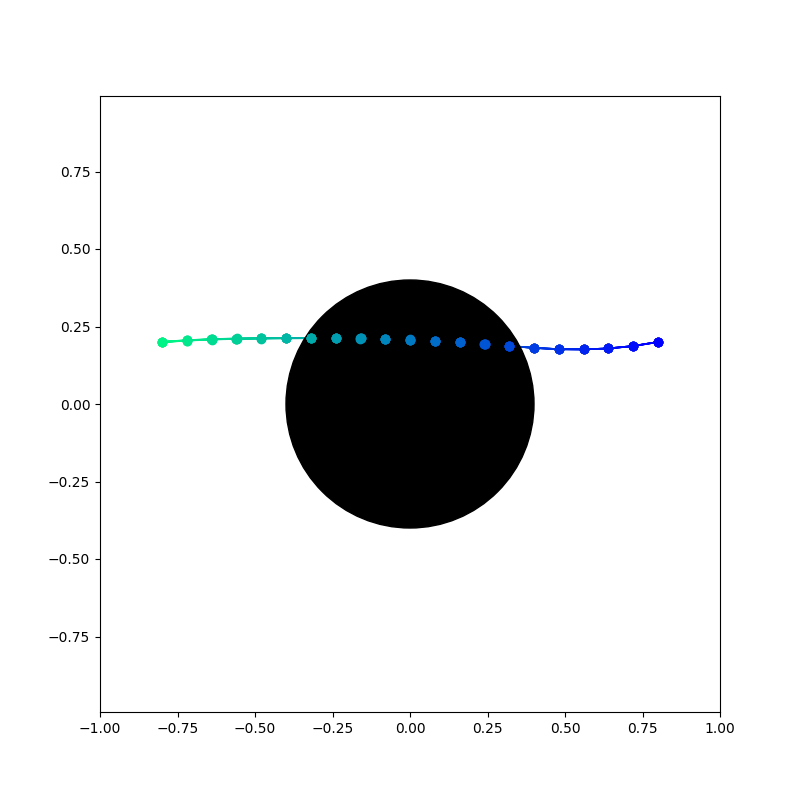
MPPI with Ensemble Variance Penalty
Gradient-based with Ensemble Variance Penalty
No Data Region
No Data Region
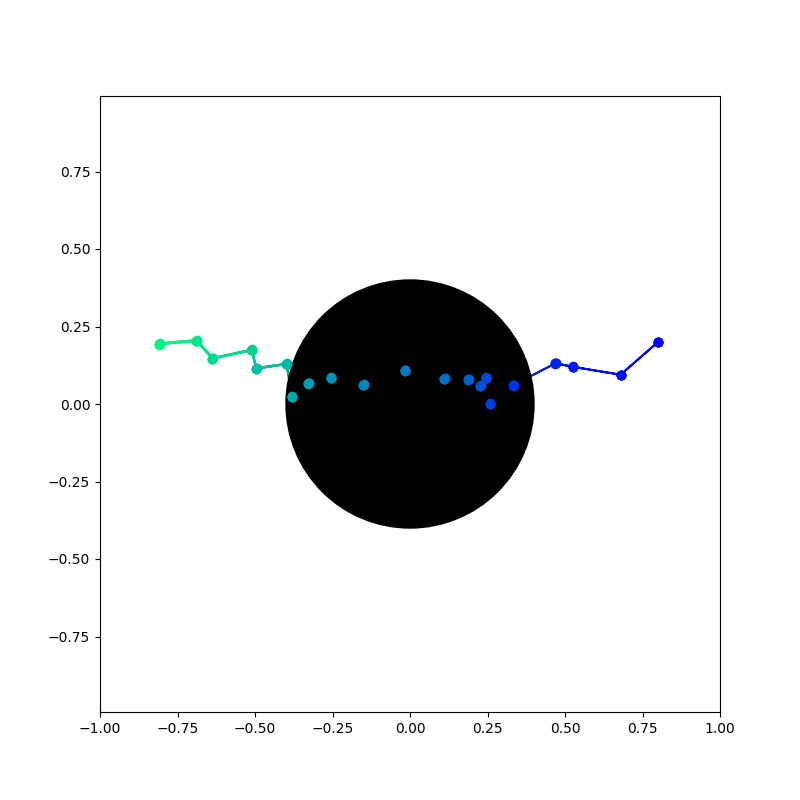
What's really wrong with ensembles?
- Ensembles do okayish in situations for detecting out-of-support kind of situations
Observed
Observed
- But there are interpolative regimes that are still "out-of-distribution", but is within the support of data.
- If function values in this region changes drastically, this kills ensembles
- Especially when the underlying model class has inductive bias towards certain wrong solutions.
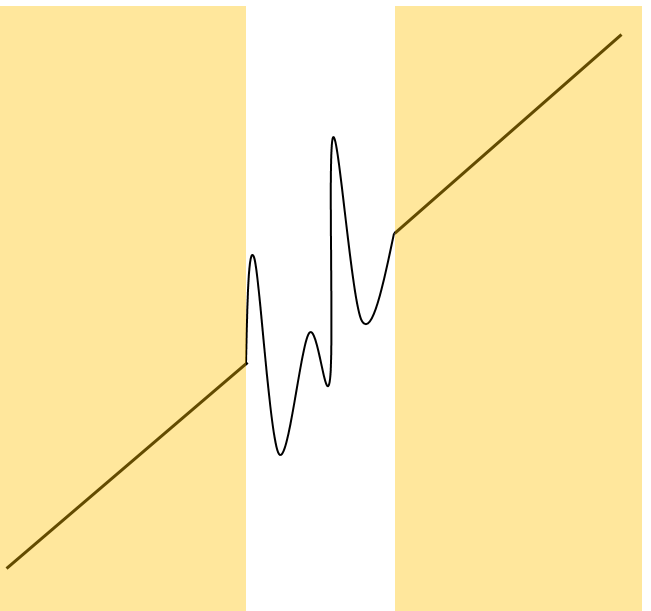
Why Data Distance?
- Data distance completely bypasses this pathology by working in the domain of data. So it doesn't care about inductive bias.
- But this is a double-edged sword, as it will unfairly penalize regions without data IF we have the right inductive bias (e.g. if function is periodic and we chose sinusodial basis)
Preliminary Results: Corridor Example
Without data distance penalty
With data distance penalty
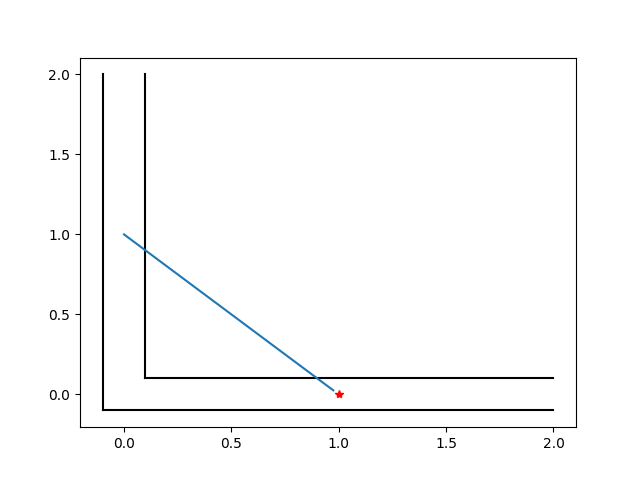
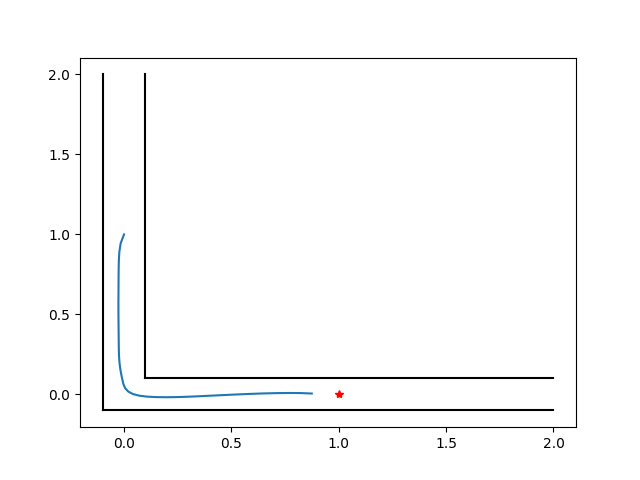
Preliminary Results: Pendulum Swingup
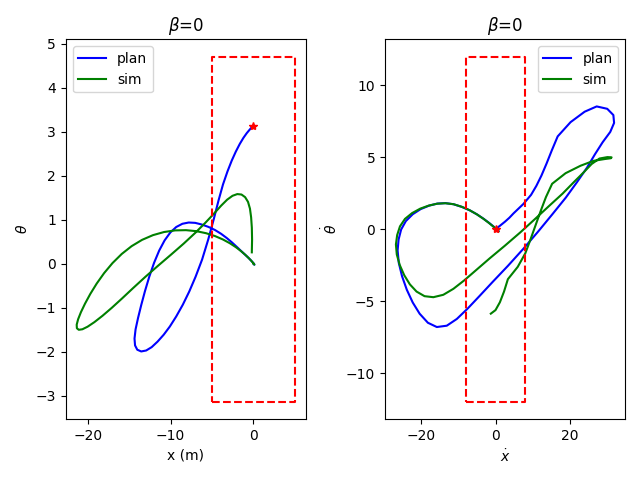
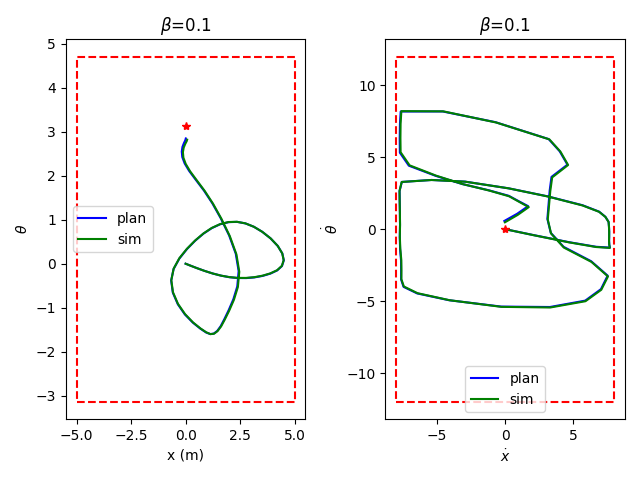
Without data distance penalty
With data distance penalty
Data region
Data region
Data region
Data region
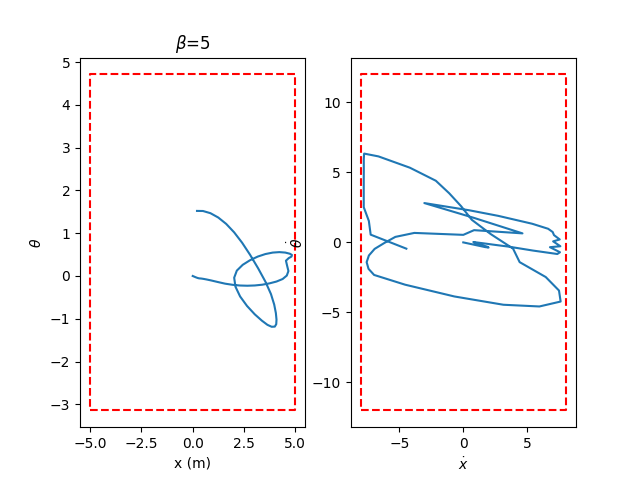
Too large of a regularization hurts task performance
Preliminary Results: Pendulum Swingup
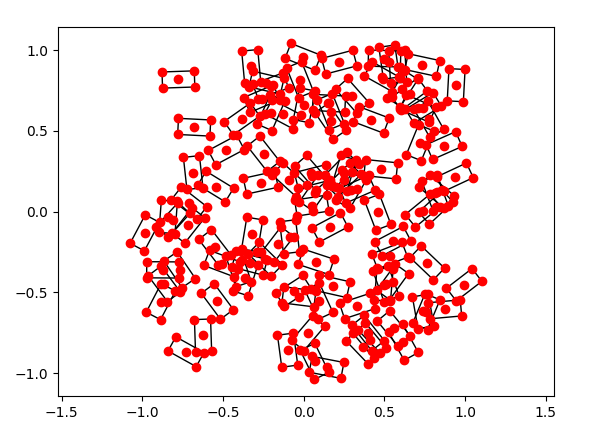
From keypoints: able to preserve implicit constraints
Pendulum with keypoints lie on a circular manifold.
We're able to impose data-based constraints very successfully.
Keypoints to the Future example
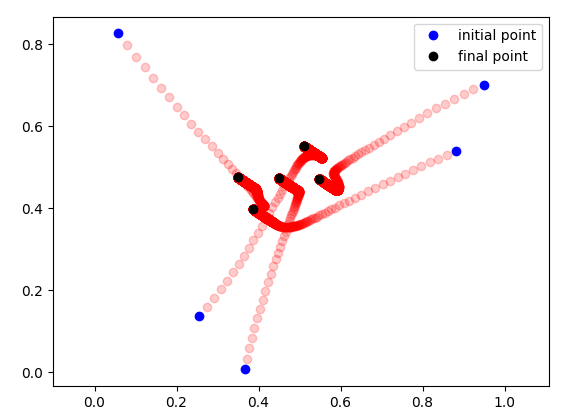
Example of Data stability: We're able to stabilize back to the data manifold
Training Distribution
Optimization against Data Distance Uncertainty
Pixel-space Single Integrator
Recall carrots case where things disappeared and appeared out of nowhere.
This might have a chance of resolving some of those issues with learned dynamics.
D4RL Mujoco Benchmarks
With regularization
Without regularization
D4RL Mujoco Benchmarks
Strangely, collocation does not work as well for Mujoco benchmarks,
so we went with the single-shooting variant


(We think it's because it's not able to obey dynamic constraints very well)
D4RL Mujoco Benchmarks
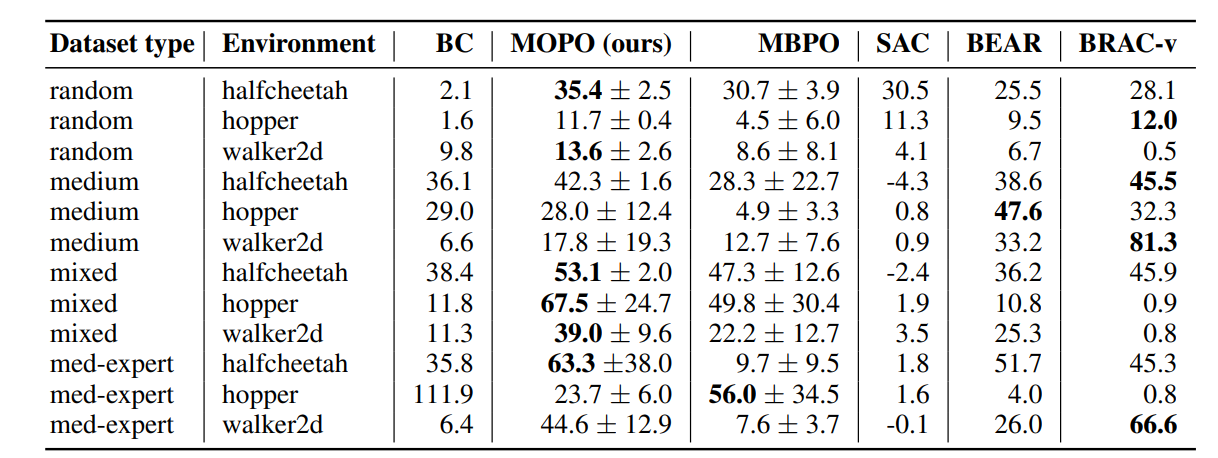
31.3
12.3
15.6
46.6
60.6
36.2
61.6
109.2
103.0
Ours
Lessons from D4RL
"A Divergence Minimizing Perspective on Imitation Learning" - CoRL 2019
Lessons from D4RL
We can use this method to IMPROVE existing demonstrations in a situation where we have access to rewards.
- Escapes pathological examples for behavior cloning by doing KL on occupation measure, NOT action distribution
- Improve over demonstration data by incorporating the ability to optimize rewards.
Questions & Future Directions for CoRL
Single shooting vs. Collocation - doesn't seem necessary to argue, since we're really trying to unify things into a bigger framework?
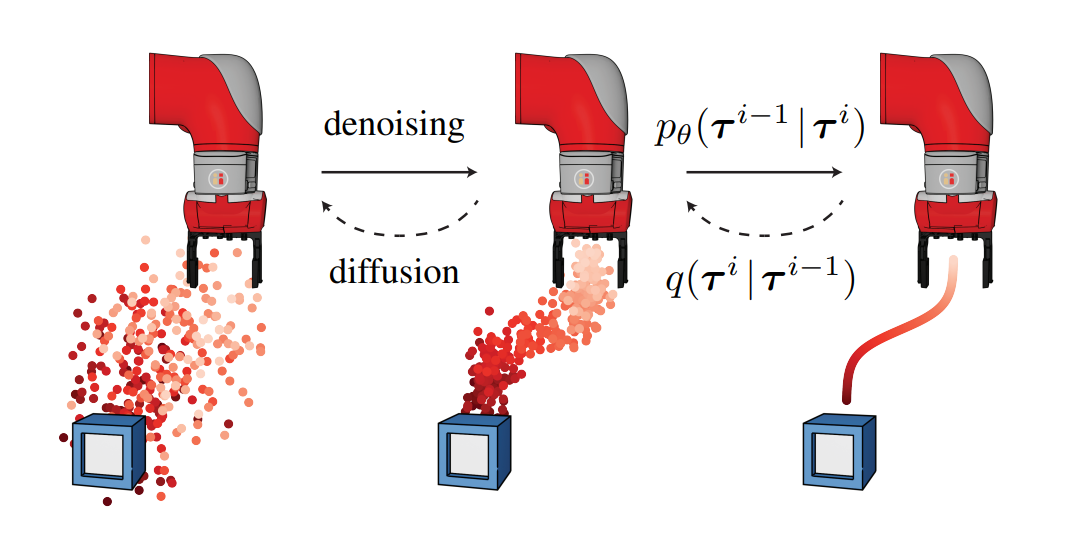
For example, diffuser is solving collocation
(with a very confusing notation & motivation)
\begin{aligned}
\min_{x_t,u_t} \quad & \sum_t c(x_t,u_t) - \beta \sum_t \log p_\theta (x_t, u_t, x_{t+1}) \\
\end{aligned}
But there is no explicit interpretation that this is direct collocation with data distance penalization
Would it be okay to swap single shooting & collocation where it seems convenient, and say we're not selling an exact algorithm, but an entire framework?
(That way we can say we're not competing with diffusion planning, but say that their success already shows the effectiveness of our proposed framework)
Questions & Future Directions for CoRL
What would be an interesting hardware experiment?
1. Replicating Keypoints to the Future with Mocap Markers
2. Carrots for Pixel-based Planning
DataDistance
By Terry Suh



