淺談隱私資訊保護方法
講者 : UR
時間 : 2020/10/25
Outline
- Introduction
- 去識別化方法
- References
Introduction
隱私資訊面臨的挑戰:
-
開放資料(Open data)
-
大數據(Big data)
-
社群網路(Social Network)
-
物聯網(IoT)
-
雲端計算(Cloud conputing)
-
Apps
...

重大隱私爭議事件實例
- 劍橋分析事件
- Netflix Prize 的資料科學競賽
去識別化方法
-
加隨機亂數雜訊法(Randomization)
-
虛擬化假名 (Pseudonymization)
-
k -匿名 (k-anonymity)
-
差分隱私 (Differential Privacy)
Randomization
-
隨機化,加隨機亂數雜訊法(Randomization)
-
直接對全部資料加少許雜訊
-
雜訊可以在計算最後被消除,或對計算結果影響很小
-
很有可能還原出原始資料值
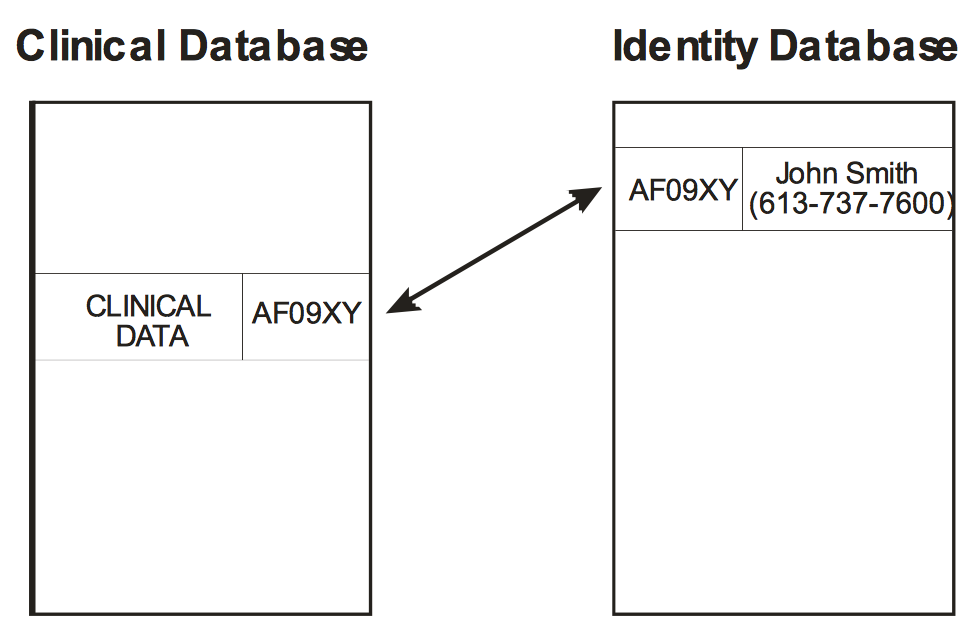
Pseudonymization -1
-
虛擬化假名,假名化
-
利用暫時性的身份用來取代真實姓名,透過刪除或隱藏個人身份指標來使得個人身份無法辨識
-
常用工具為雜湊函數(hash function)
Pseudonymization -2
-
雜湊函數(hash function)
雜湊值常用英文字母和數字隨機組成的字串表示,而且一個雜湊值只能對應一組個人資訊。
| 可接受輸入長度 | 可接受輸出長度 | |
|---|---|---|
| MD5 | 2⁶⁴−1 Bytes | 128 Bytes |
| SHA-1 | 2⁶⁴−1 Bytes | 160 Bytes |
| SHA-256 | 2⁶⁴−1 Bytes | 256 Bytes |
| SHA-512 | 2¹²⁸−1 Bytes | 512 Bytes |
Pseudonymization -3
-
單向雜湊(one-way hash),很難利用雜湊值去反向找到原始的訊息字串
-
能接受字串越長而且產生較長的雜湊值通常是較安全的
| 姓名 | ||
|---|---|---|
| 原始資料 | 楊子右 | 407040328@gapp.fju.edu.tw |
| MD5 | f2a9aad86cf1c0500b65237781f2c2c2 | a6ea72371479a4a3c2f1c7b4ec73538b |
| SHA-1 | b21ecacf35438eab06974a389b601997d99fdd5d | c50b27027770045bb71245e0f8132b4ba0310494 |
- 範例
k-anonymity -1
-
k-匿名 (k-anonymity)
-
當一個資料集中,對於一個或多個屬性值結合起來的組合 ( 如地址、年齡、性別等 ) ,若是可以找到 k 筆紀錄具有相同的組合,則此資料集就符合 k-匿名。
k-anonymity -2
-
處理方式
-
概化 (generalization) :將屬性值以區間值代替。
-
抑制 (suppression) :以其他符號代替、隱藏或刪除屬性值。
-
-
判定方式
-
將同一屬性值結合起來的組合進行分群,計算各群組之個體數量,以判定 k 值。
-
k-anonymity -3
| 姓名 | 郵遞區號 | 年齡 | 違規項目 | |
|---|---|---|---|---|
| 1 | Stan Marsh | 23123 | 30 | 酒駕 |
| 2 | Kyle Broflovski | 23131 | 32 | 酒駕 |
| 3 | Eric Cartman | 23111 | 37 | 酒駕 |
| 4 | Marshal | 11021 | 45 | 超速 |
| 5 | Raymond | 11023 | 50 | 超速 |
| 6 | Dom | 11022 | 63 | 超速 |
| 7 | K.K. Slider | 12321 | 22 | 酒駕 |
| 8 | Isabelle | 12311 | 23 | 未戴安全帽 |
| 9 | Tom Nook | 12301 | 19 | 紅燈右轉 |
| 姓名 | 郵遞區號 | 年齡 | 違規項目 | |
|---|---|---|---|---|
| 1 | * | 231** | 3* | 酒駕 |
| 2 | * | 231** | 3* | 酒駕 |
| 3 | * | 231** | 3* | 酒駕 |
| 4 | * | 110** | ≥45 | 超速 |
| 5 | * | 110** | ≥45 | 超速 |
| 6 | * | 110** | ≥45 | 超速 |
| 7 | * | 123** | <30 | 酒駕 |
| 8 | * | 123** | <30 | 未戴安全帽 |
| 9 | * | 123** | <30 | 紅燈右轉 |
-
匿名化資料表 (3-anonymity)
概化
抑制
抑制
非敏感欄位
敏感欄位
k-anonymity -4
-
對於敏感資料中,兩種可能遭受的攻擊 :
-
同質性攻擊(homogeneity attack)
透過資料敏感屬性中的些微差異來復原原來的敏感屬性。
-
背景知識攻擊(background knowledge attack)
對原先資料的背景知識有一定程度了解,進而透過敏感資訊與個人關係來還原資料。
-
Differential Privacy -1
- 差分隱私 (Differential Privacy)
- 解決交叉比對資料的攻擊
Differential Privacy -2
-
交互式 (interactive):
-
- 使用者提出一個查詢 (query),資料庫系統回應一個加入雜訊的結果。
- 目前大部分使用 differential privacy 的工具屬此。
-
非交互式 (non-interactive):
- 資料擁有者直接釋出一個擾亂後的資料集給使用者自由使用。可以應付所有未來所有可能的查詢 (query),仍能夠維持差分隱私標準。
References
THANKS
FOR LISTENING
淺談資訊保護方法
By ur89170218



