

Vedant Puri
PhD student at Carnegie Mellon University
Mechanical Engineering, Carnegie Mellon University
Advisors: Prof. Burak Kara, Prof. Jessica Zhang
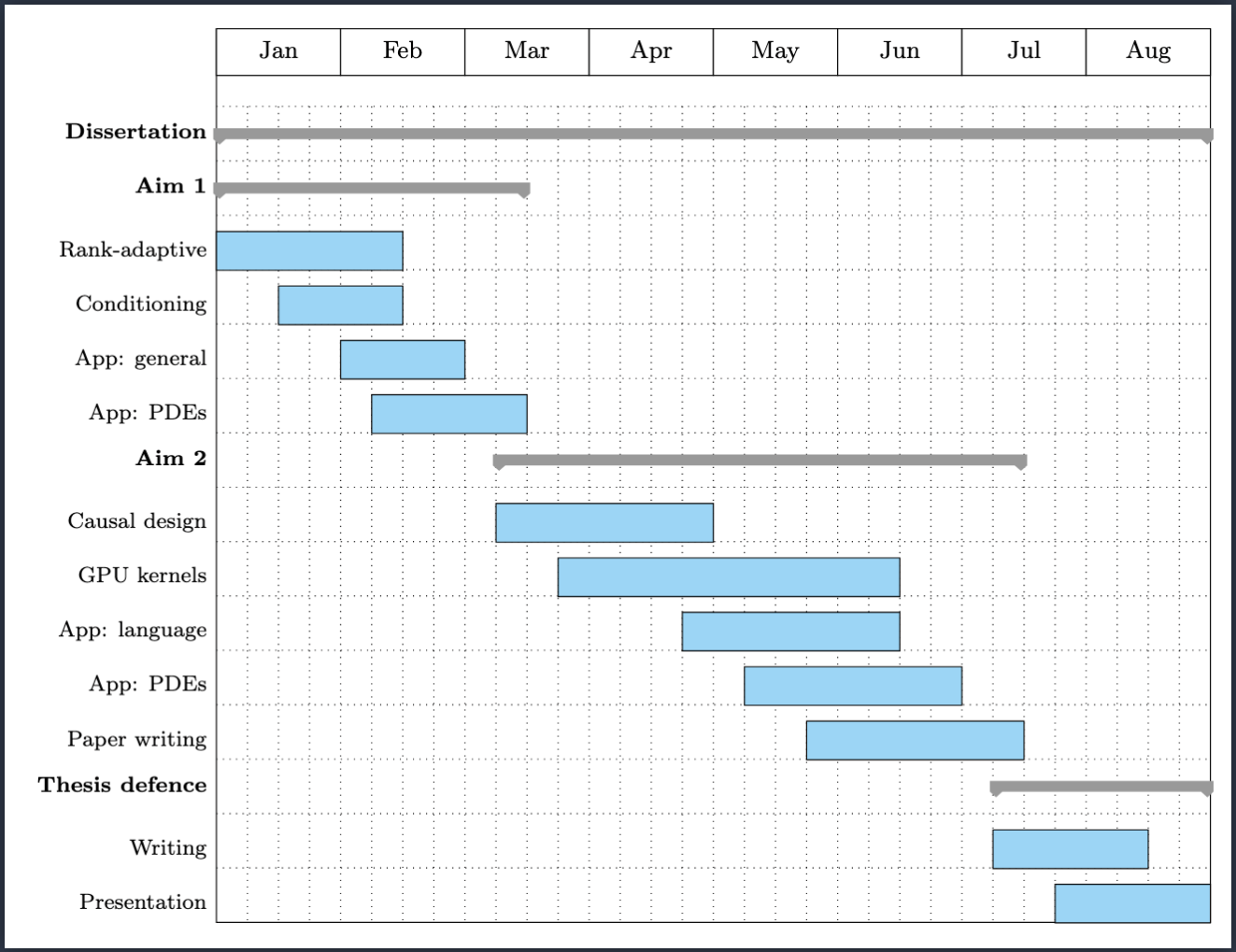
PROPOSED WORK
NEXT PAPER - ICML (Int'l conference of Machine Learning)
PROGRESS
NEXT STEPS
Aim 2: Causal self attention with FLARE
AIM 1(a): rank-adaptive
AIM 1(b): conditioning mechanism
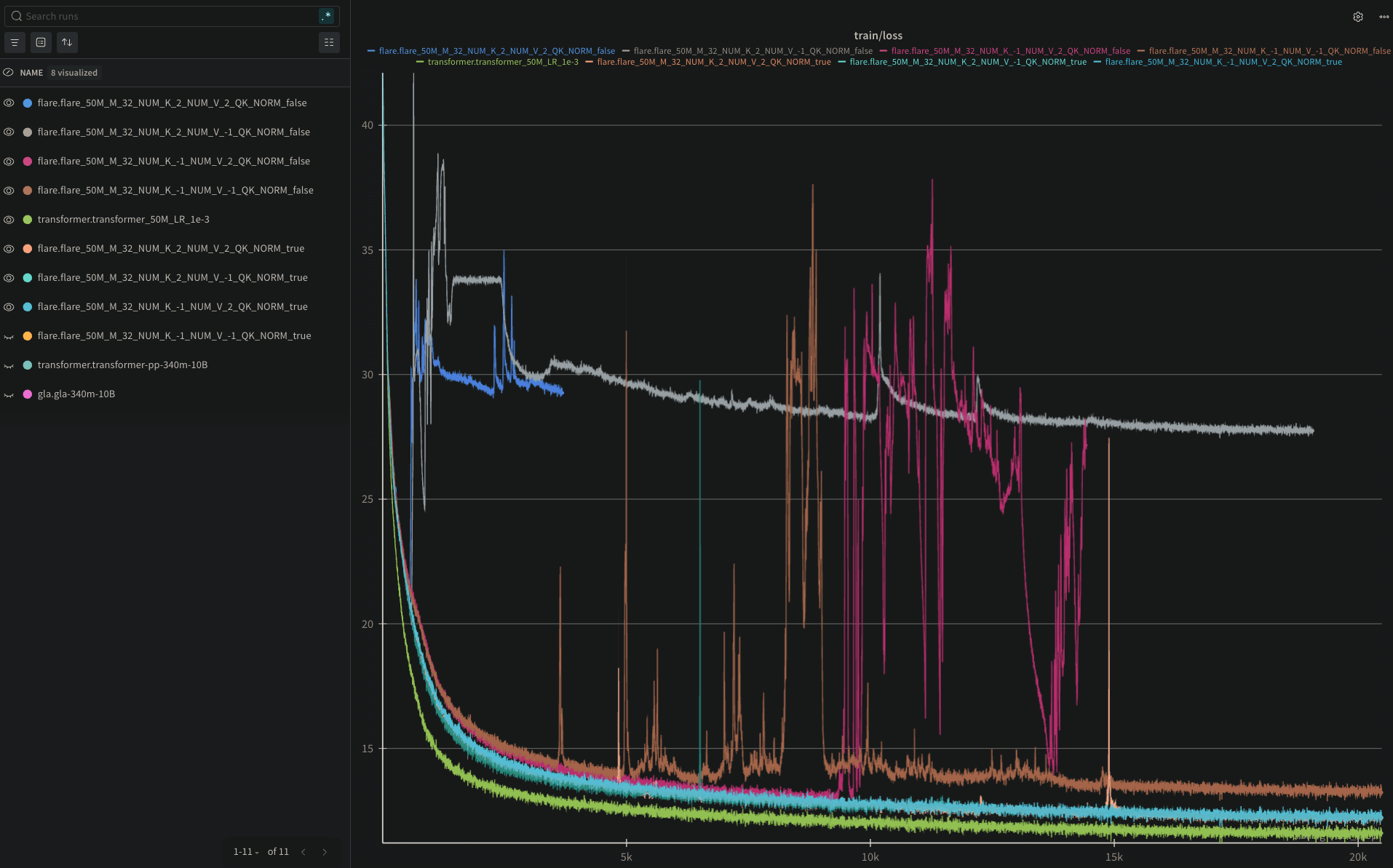
Progress
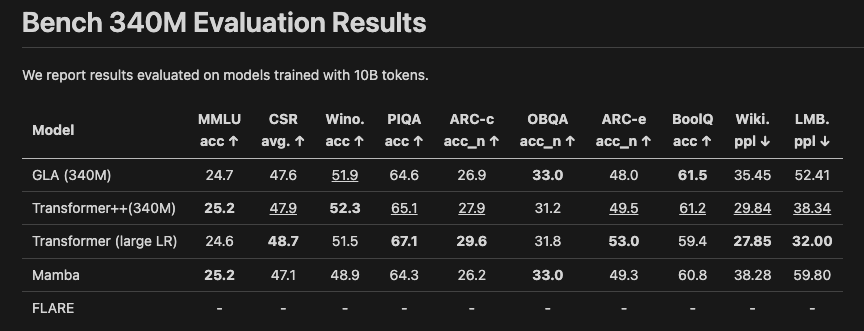
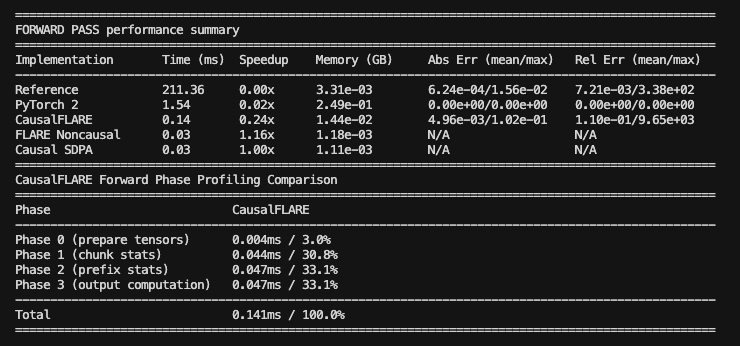
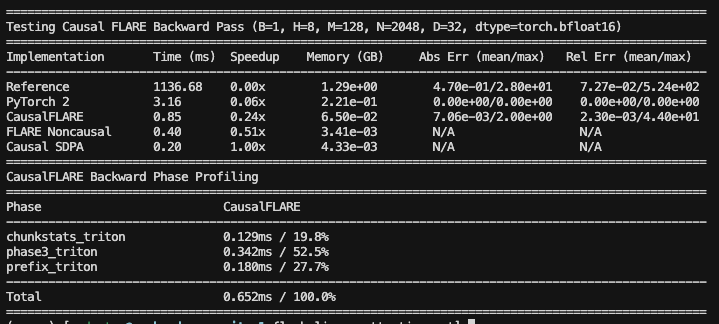
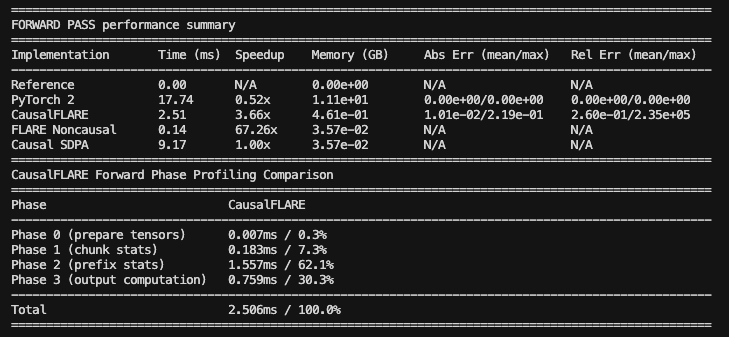
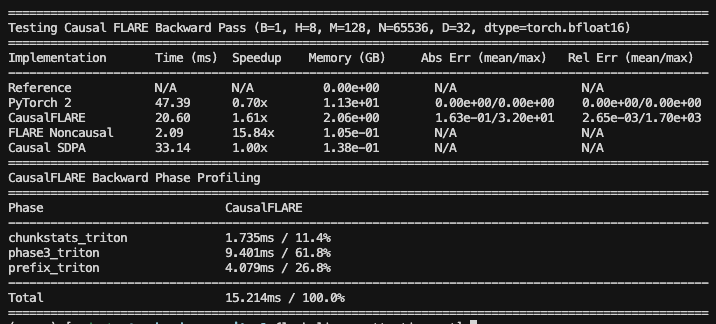
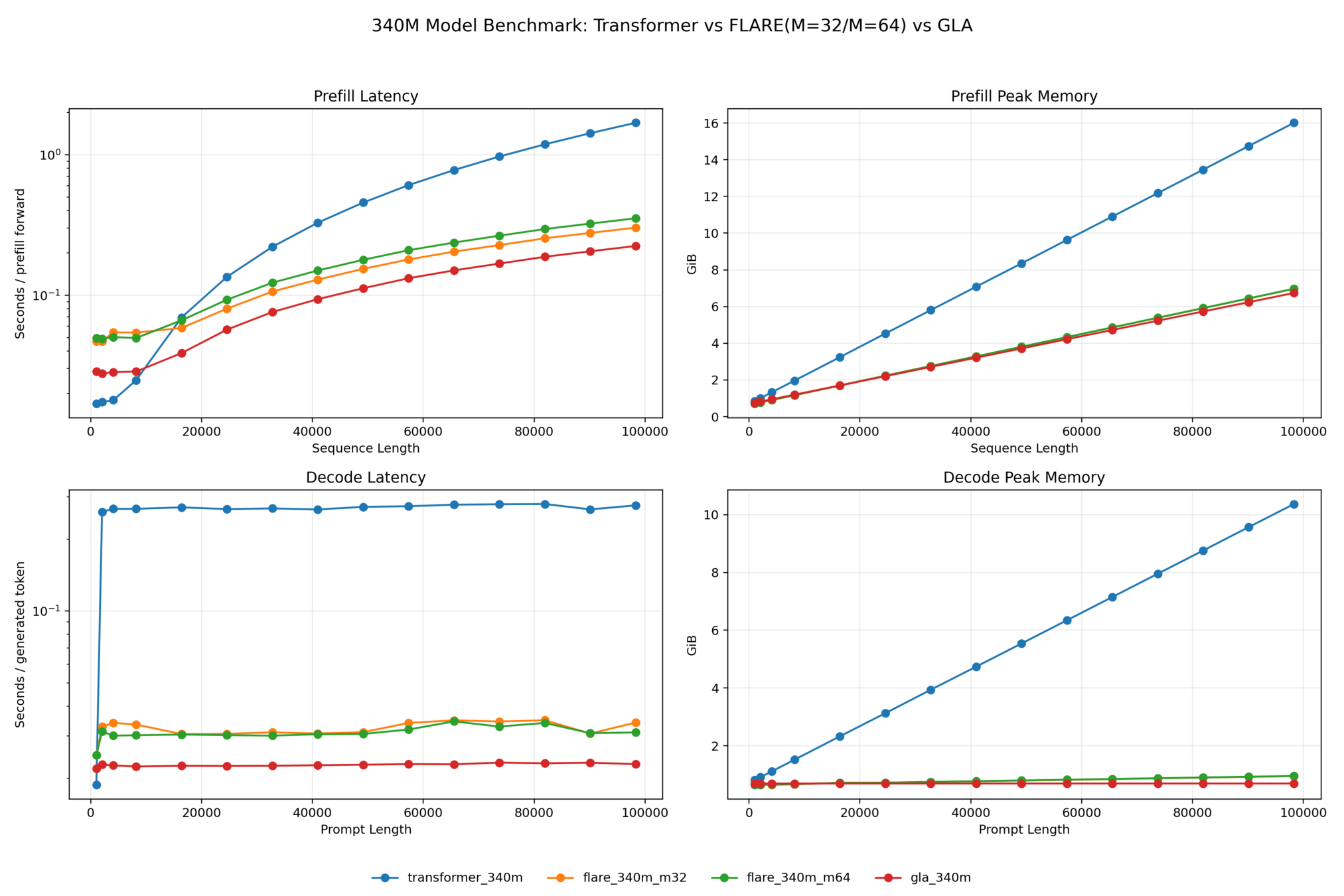
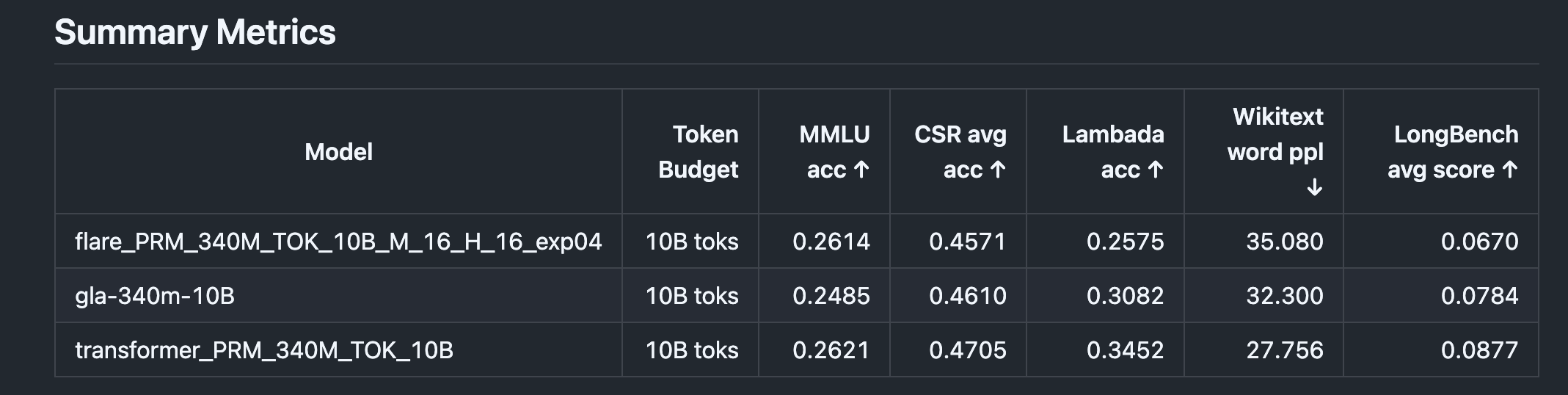
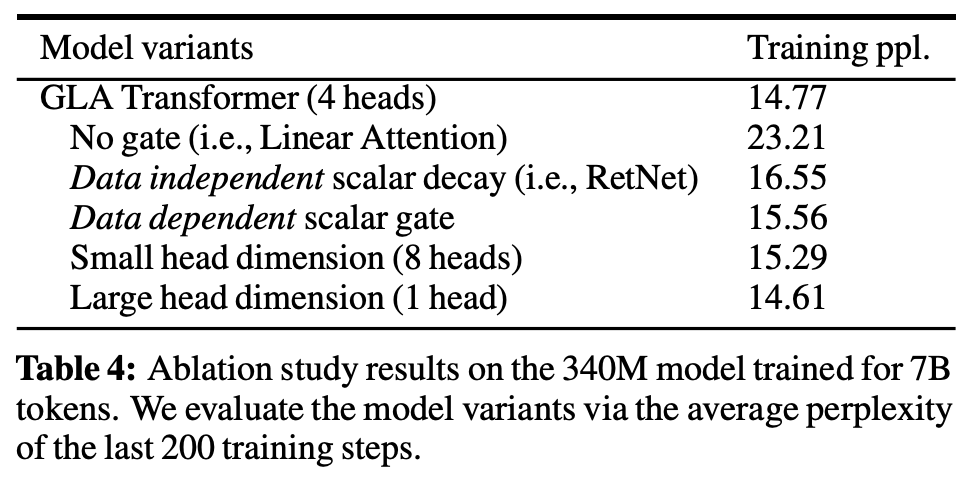
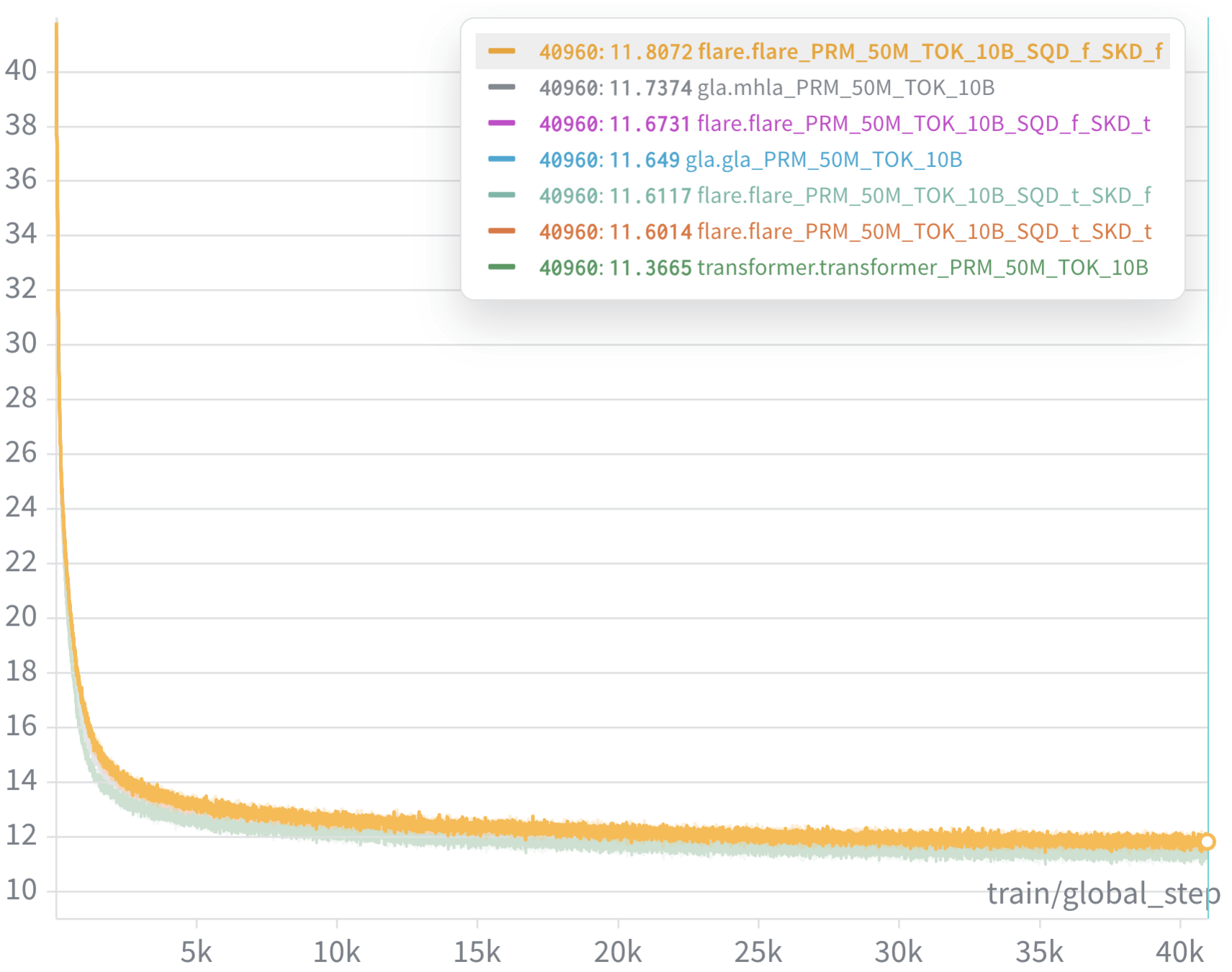
Benchmarking (model size: 340M params, context length: 2k tokens)
Advantages
Progress
Progress
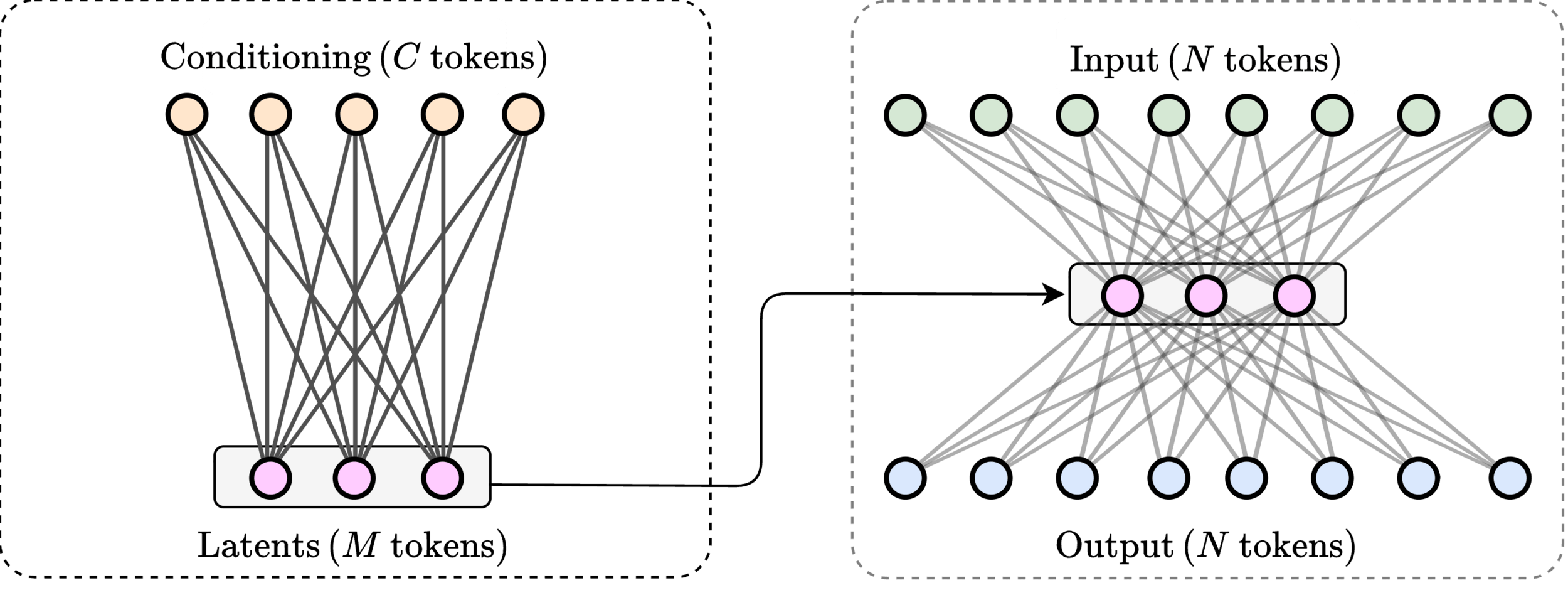
Memory-Efficient Causal Attention via Latent Routing (FLARE Decoder)
Target Conference: NeurIPS 2026 (May 15)
1. Contrib: Latent routing formulation of causal attention
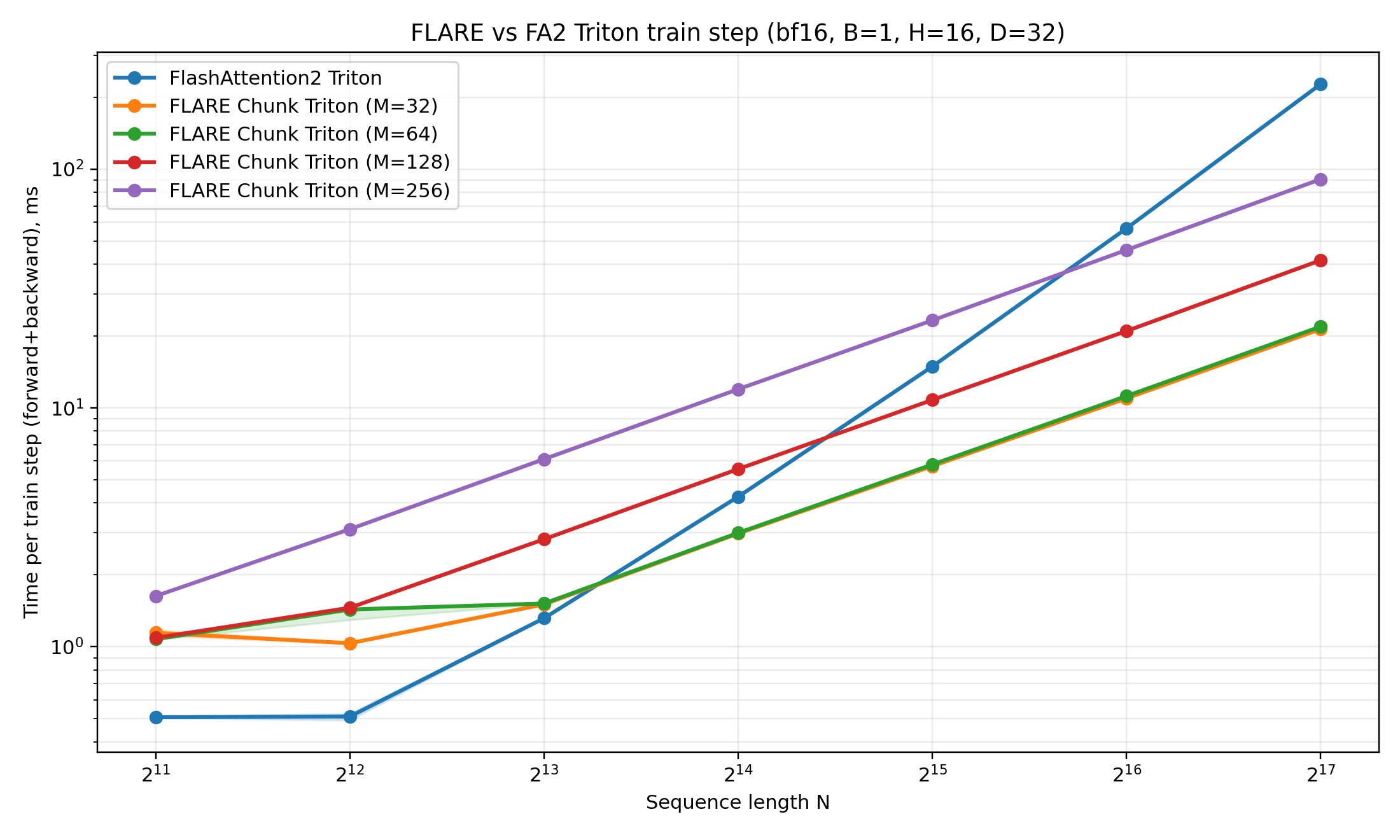
2. Contrib: Constant-memory autoregressive decoding algorithm
3. (TODO) Contrib: Linear-memory training via chunkwise recomputation algorithm
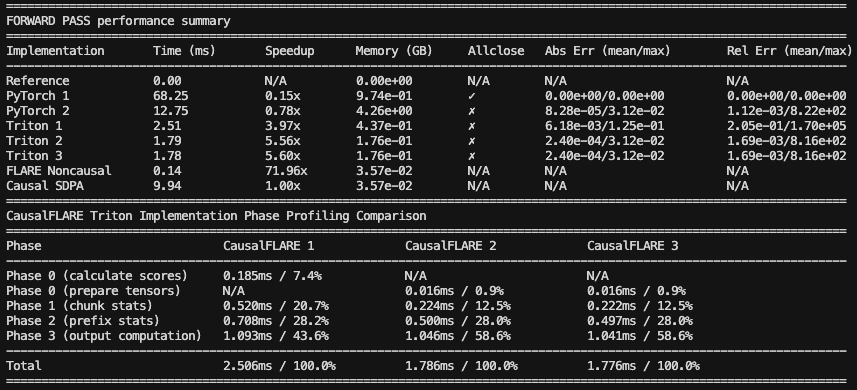
4. (TODO) Contrib: Optimized GPU kernels for scalable training and inference
5. (TODO) Contrib: Adaptive latent queries for content aware compression (new architecture improvement over FLARE)
(from gated linear attn paper)
Efficient Causal Attention via Latent Routing (FLARE Decoder)
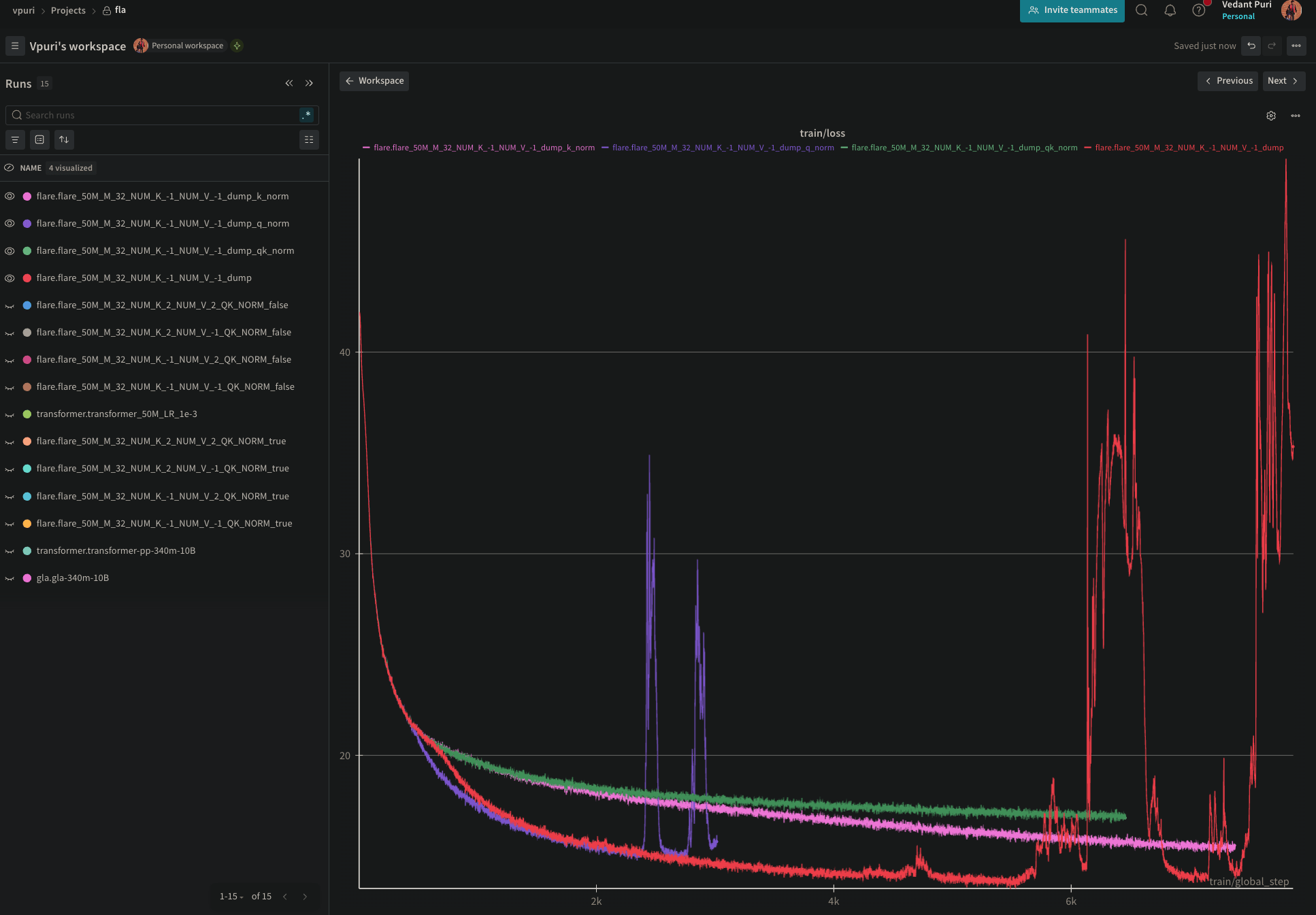
Progress
Efficient Causal Attention via Latent Routing (FLARE Decoder)
Progress
Next steps
Efficient Causal Attention via Latent Routing (FLARE Decoder)
Progress
Efficient Causal Attention via Latent Routing (FLARE Decoder)
Progress
Efficient Causal Attention via Latent Routing (FLARE Decoder)
Progress
FLARE-Connect: Topologically consistent transformers for PDE surrogate modeling on arbitrary geometries
Target: Journal publication May/June 2026
Core Idea:
Contributions:
Method:
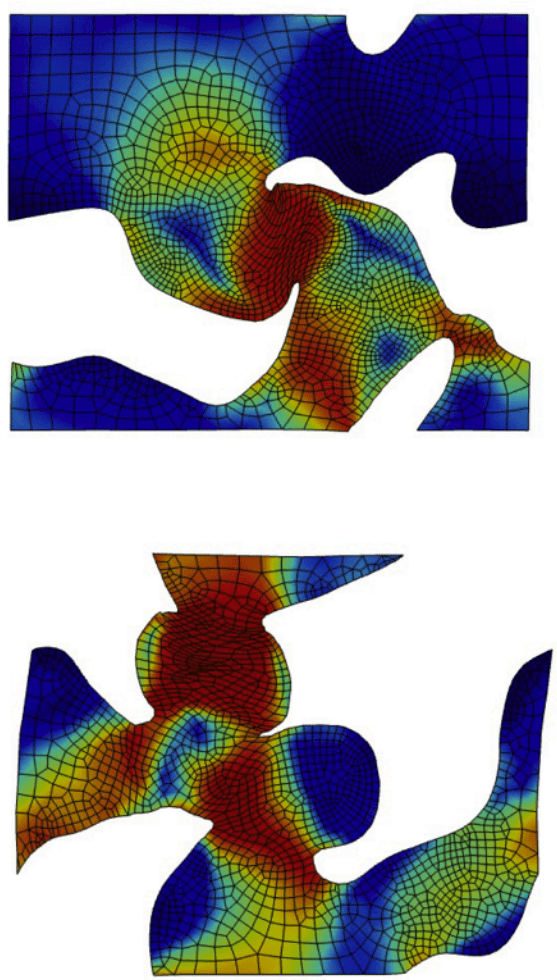
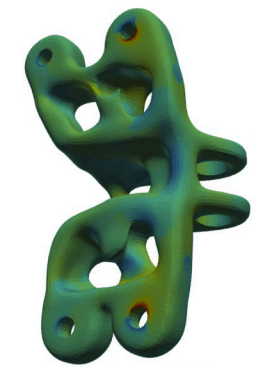
Jet Engine Bracket (50k points)
Periodic Unit Cell (10k points)
Conditioning mechanism for incorporating boundary information
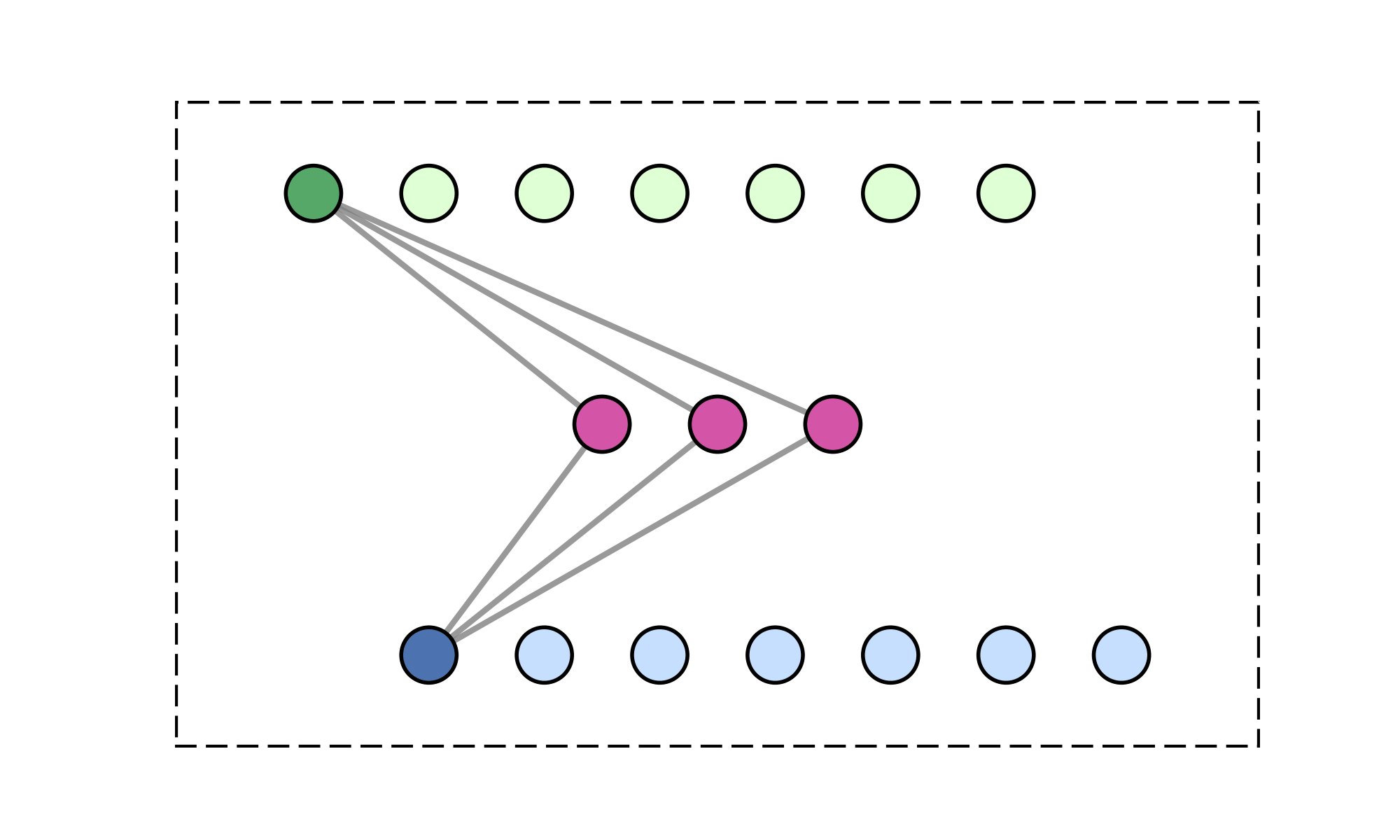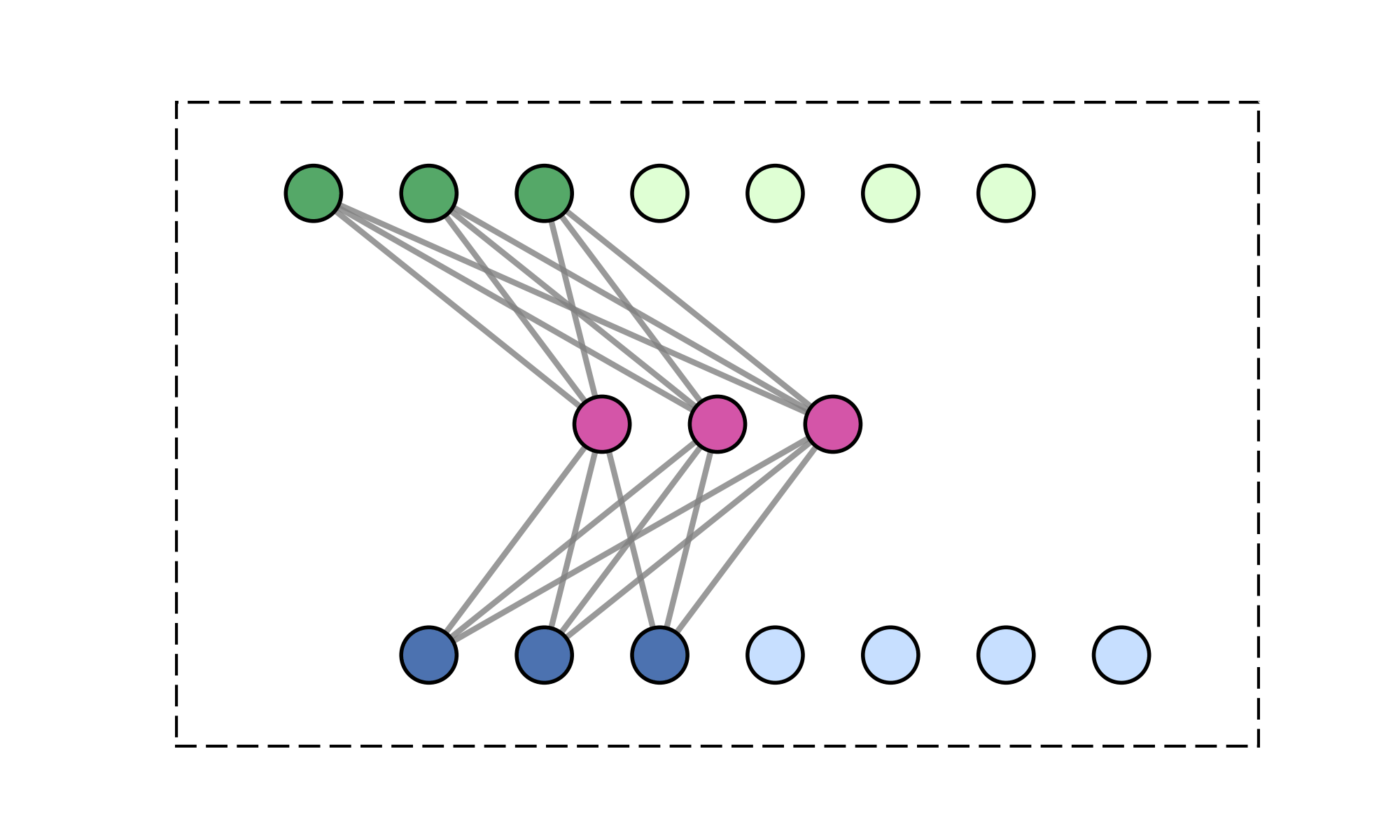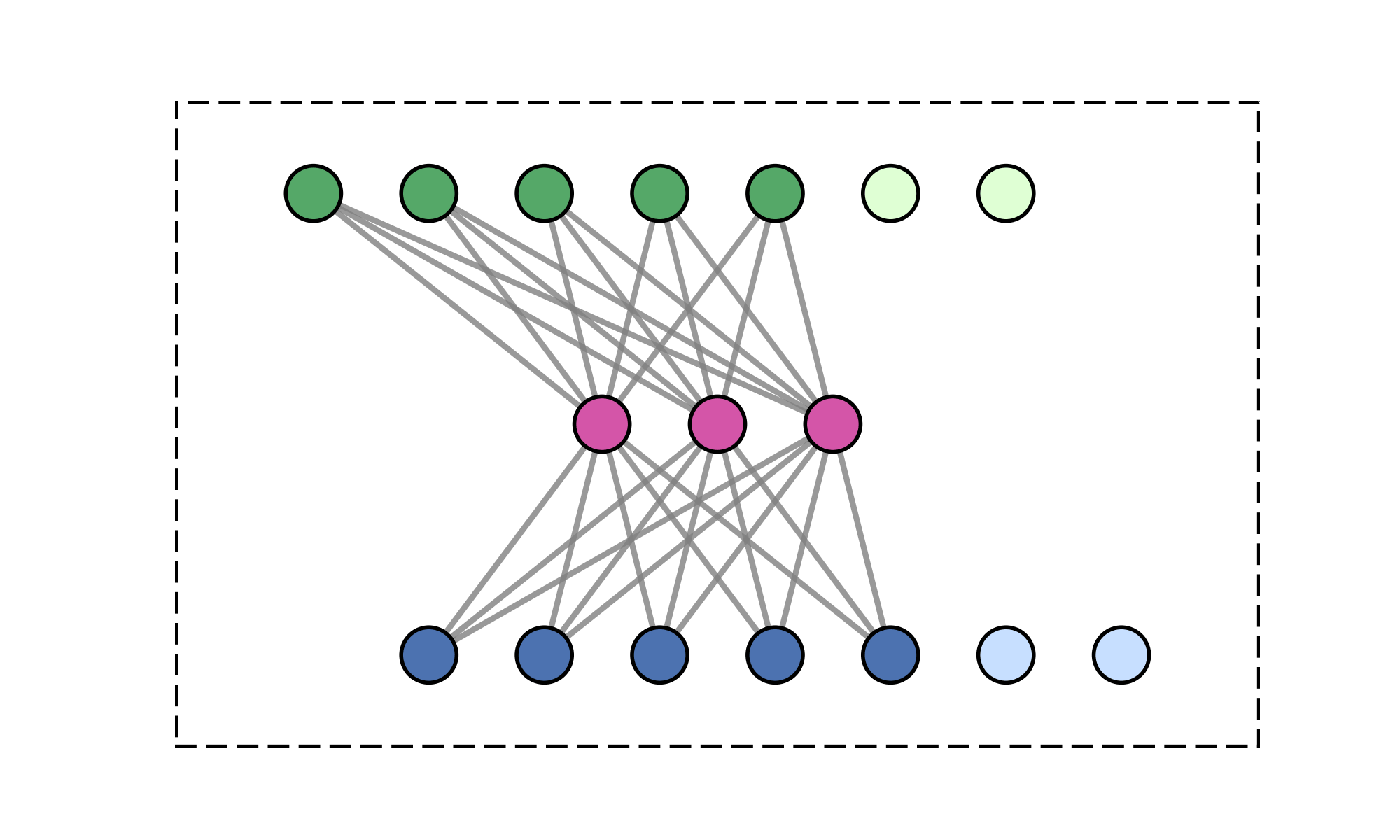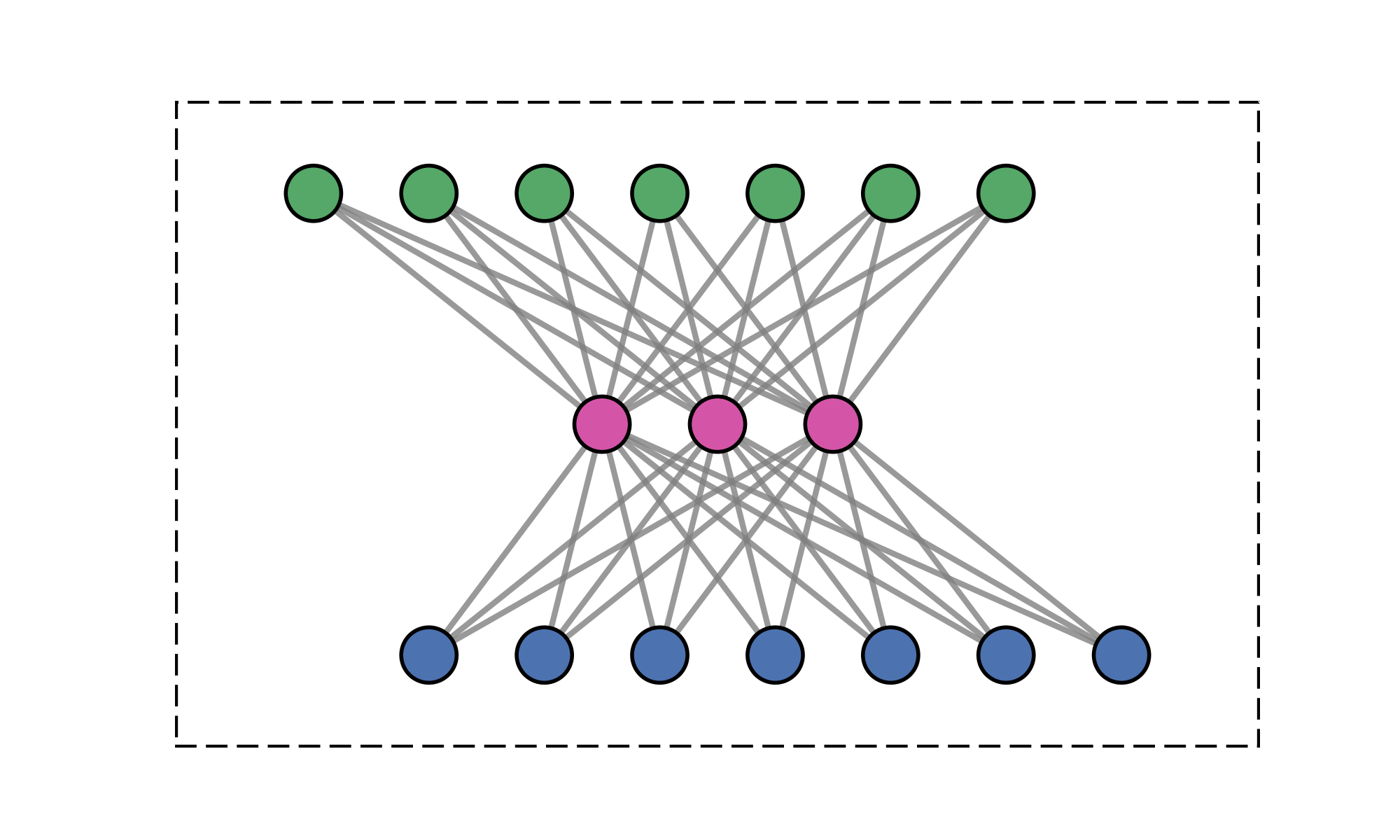
Constrain attention to topologically connected/close-by clusters
Transformer-based neural operators achieve strong performance by learning global geometry-to-field mappings, but they implicitly rely on Euclidean proximity and attention to infer physical interactions. This becomes problematic in highly nonconvex or topology-rich domains (e.g., microstructures with holes, thin ligaments, or closely spaced but disconnected regions), where spatial closeness does not imply physical connectivity. As a result, these models can introduce subtle but important errors, such as smoothing stress across voids or misrepresenting load paths, despite maintaining low global error metrics.
We propose a connectivity-grounded FLARE, which augments FLARE’s global low-rank attention with explicit mesh-topology information. Instead of replacing global attention, the model incorporates local graph-based structure (derived from mesh connectivity or geometric neighborhoods) to constrain or guide information flow. This hybrid design preserves FLARE’s scalability and global reasoning while enforcing physically meaningful locality where it matters. The key hypothesis is that explicit topology grounding improves robustness in nonconvex geometries and stress-concentration regions, leading to better generalization under topology shifts without sacrificing global accuracy.
By Vedant Puri
Biweekly co-advisor meeting




