Survey of Superoptimization
Jiangyi Liu, Xingyu Xie
Approaches
# Superoptimization
Enumerative search
Stochastic search
Synthesis-based
- Component-based synthesis problem
- Counter-Example Guided Inductive Synthesis
# Enumerative search
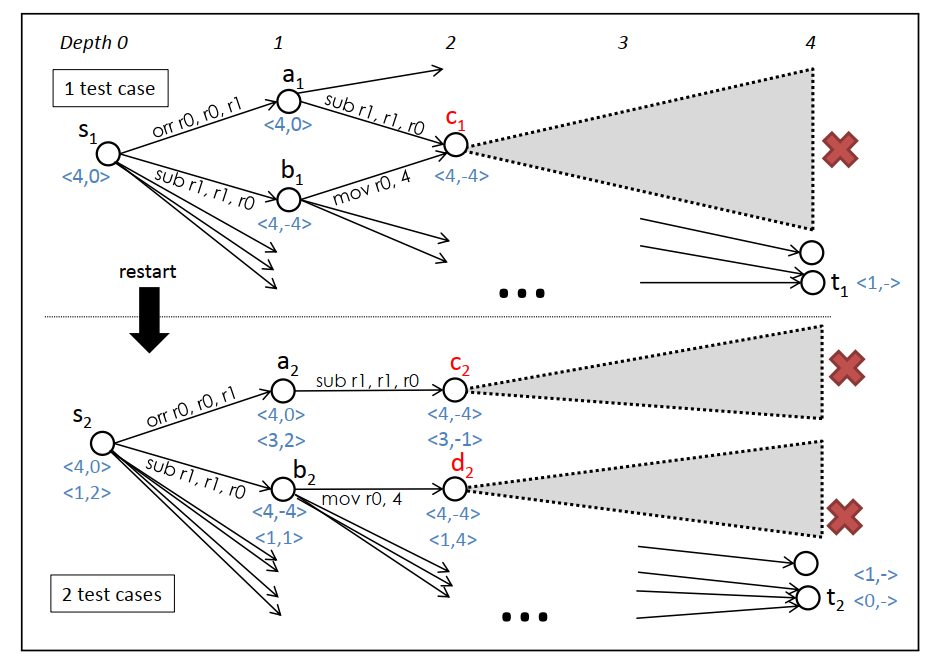
Enumerative search
- node: a vector of program states
- edge: a instruction with a defined cost
- path: an execution of a program
- source: inputs of testcases
- destination: outputs of testcases
Basic idea: enumerate all paths of cost lower than the one to optimize.
Many techniques for speedup:
- merge equivalence class
- refine (but not rebuild) the graph with a new testcase
- bidirectional search
(ASPLOS'13) Phitchaya Mangpo Phothilimthana et al. Scaling up Superoptimization
# Stochastic search
Stochastic search
program space
(blue area is the equivalent programs to the target)
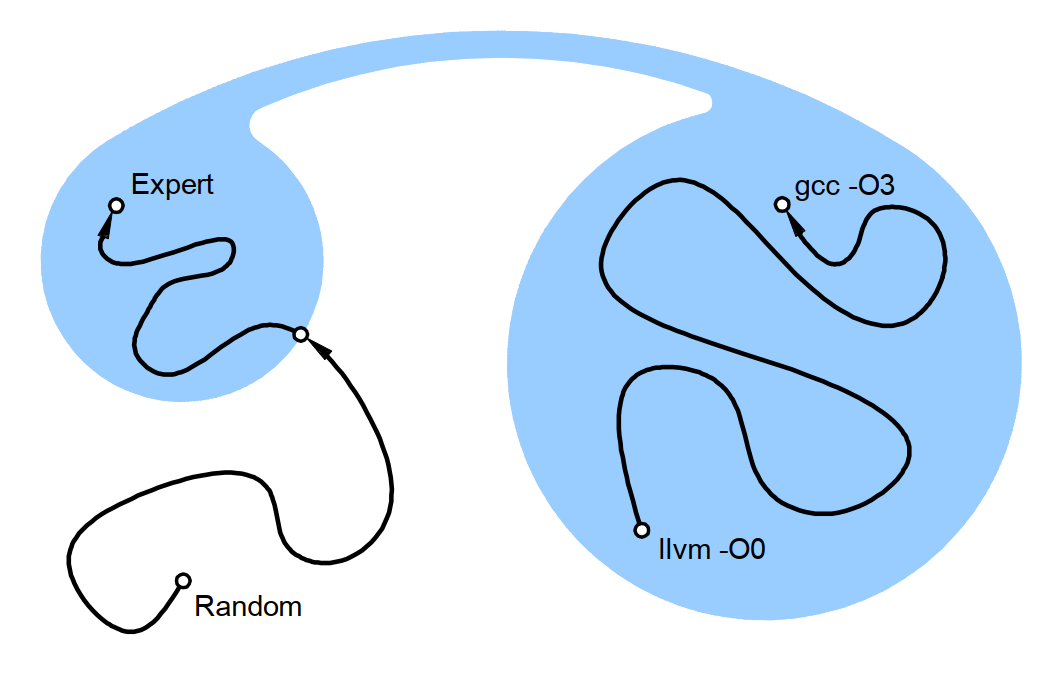
cost function
Basic idea: (Metropolis-Hastings algorithm) mutate the current program, and accepted with a probability according to the cost.
(ASPLOS'13) Eric Schkufza et al. Stochastic Superoptimization
# Equivalence checker
Equivalence checker

Data-driven non-deterministic approach:
- Use template to generate alignment predicates.
- Construct a product CFG, by aggregating the paired states satisfying the alignment predicate to one node.
- Generate invariants for each node from data.
- Use SMT-solver to verify proof obligations.
(OOPSLA'13) Rahul Sharm et al. Data-Driven Equivalence Checking
(PLDI'19) Berkeley Churchill et al. Semantic Program Alignment for Equivalence Checking
# Testcases
Testcases
- User provided testcases are required.
- If there is no control-flow, we could manually assign cost for each kind of instruction. But testcases are necessary for evaluate performance when branches or loops exist.
- To better handle loops, "counter-example" found by bounded verifier is added into the set of testcases (above figure).
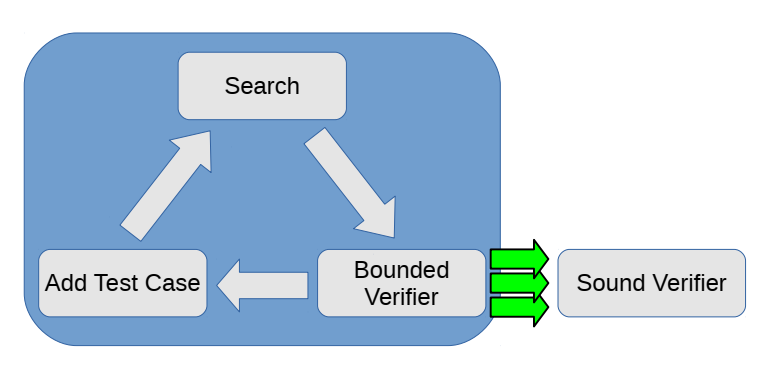
(ASPLOS'17) Berkeley Churchill et al. Sound Loop Superoptimization for Google Native Client
# Reinforcement learning
Reinforcement learning
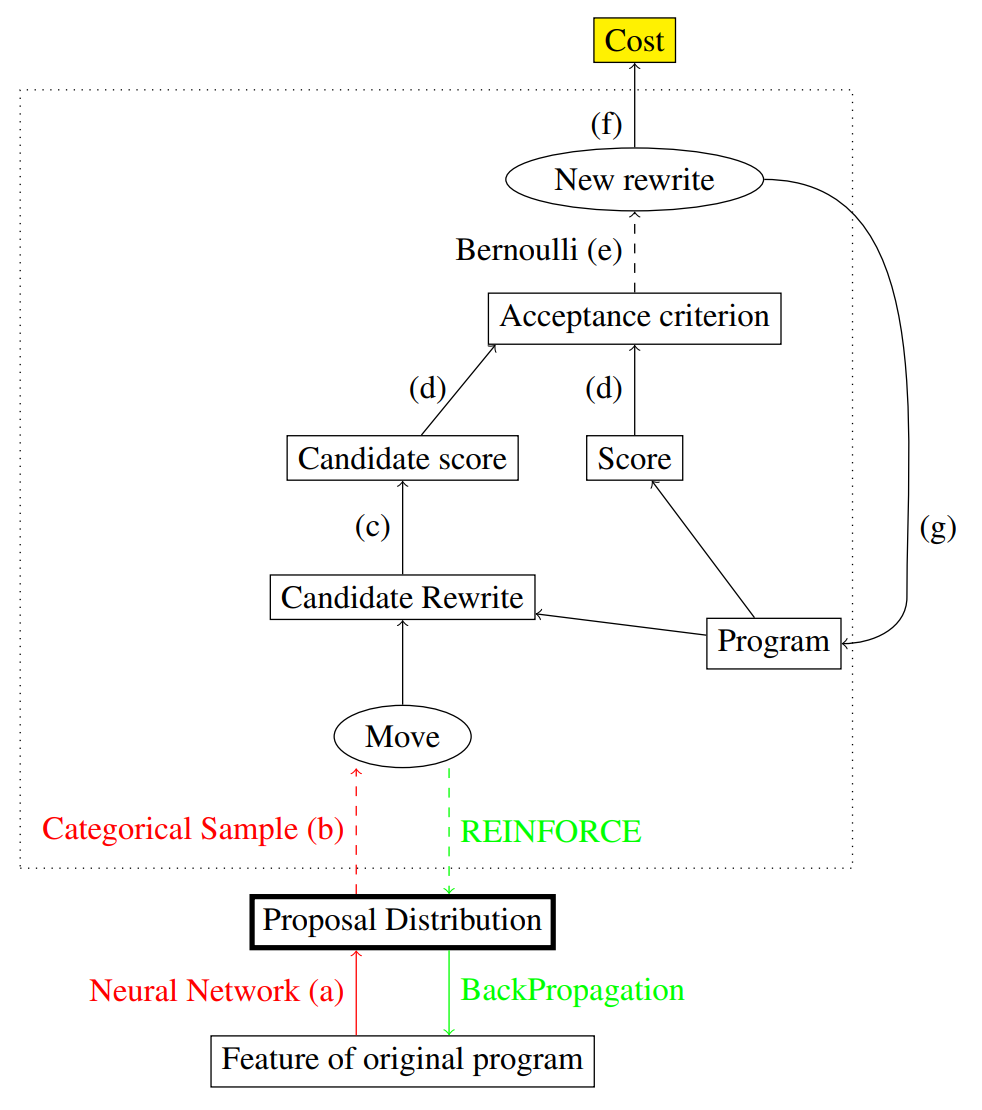
Mutations:
- operand moves
- rotate moves
- opcode width moves
- delete moves
- add nop moves
- replace nop moves
- memory+swap
Use RL to learn the distribution to perform each mutation, which is uniform before.
(ICLR'17) Rudy Bunel et al. Learning to superoptimize programs
(DL4C workshop at ICLR'22) Alex Shypula et al. Learning to superoptimize real-world programs
# SYNTHESIS
Synthesis-based approaches
Souper: A Synthesizing Superoptimizer
- Component-based Synthesis; CEGIS
- Target: loop-free subset of LLVM IR

Raimondas Sasnauskas et al. A Synthesizing Superoptimizer
From Software Analysis (2021), instructed by Yingfei Xiong, Peking University
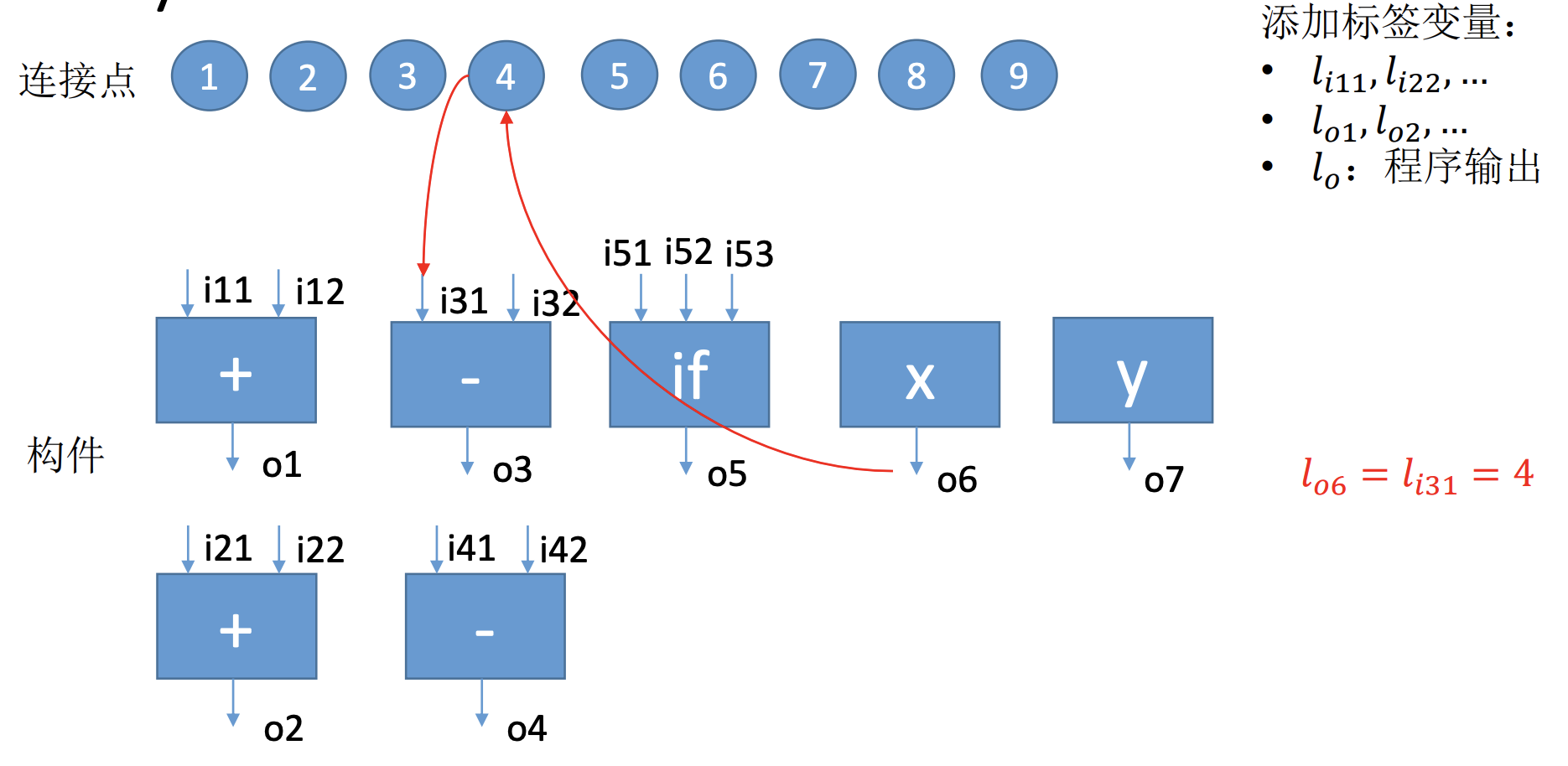
What is component-based synthesis?
The user provides a library of components:
\( \{\langle\vec I_i, O_i, \phi_i(\vec I_i, O_i)\rangle \mid i = 1 \dots N \}\)
- Here \(\phi_i\) is the constraint on a component
- to allow multiple use of a component, put more than one copies in the library
Besides, a specification of the desired program should be given:
\( \langle \vec I, O, \phi_{spec}(\vec I, O)\rangle \)
GOAL: Find a straight-line program that only uses components given in the library
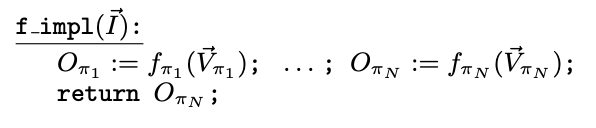
- A mental model: components are connected by input/output relations
- f_impl should satisfy the following formula
i.e. for every combination of input value & temporary variable values, if the spec for components holds, then f_impl meets \(\phi_{spec}\)
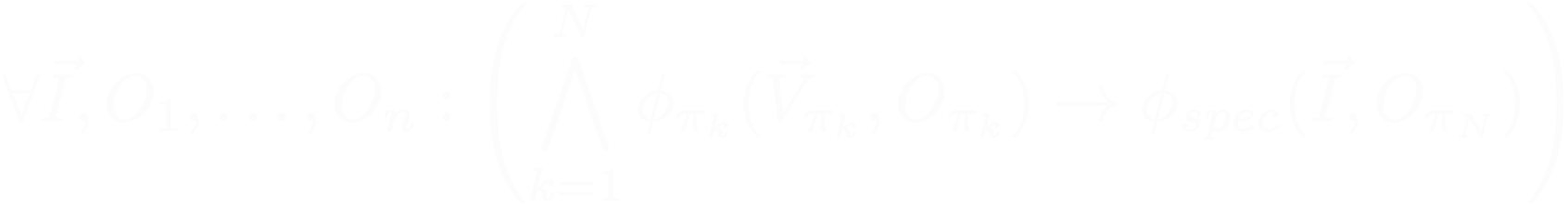
Encode connections in SMT formulas.
- Divide I/O vars into sets:
- \(\mathbf{P} = \bigcup_{1 \le i \le N} \vec I_i\), \(\mathbf{R} = \{O_1, \dots, O_N\}\)
- Location = Line number OR input variable
- Location 0 ~ Location (M-1): input for every component
- Location M, ...: assignment to temp var / final output
- \(M = \sum_{1 \le i \le N} \mathsf{arity}(\vec I_i)\)
- Consistency: locations are distinct
\[\psi_{cons} := \bigwedge_{x,y\in\mathbf{R},x\ne y} l_x \ne l_y\]
- Acyclic: all connections don't form a loop
\[\psi_{acyc} := \bigwedge_{1 \le i \le N} \left(\bigwedge_{x \in \vec I_i} l_x < l_{O_i}\right)\]
Encode connections in SMT formulas (cont.)
- wfp = cons + acyc + bounding locations
\[\psi_{\mathrm{wfp}}(L):=\bigwedge_{x \in \mathbf{P}}\left(0 \leq l_{x} \leq M-1\right) \wedge \bigwedge_{x \in \mathbf{R}}\left(|\vec{I}| \leq l_{x} \leq M-1\right) \wedge\\ \psi_{cons}(\mathbf{L}) \wedge \psi_{acyc}(\mathbf{L})\]
where \(L\) stands for the set of locations
- \(\phi_{lib}\): library specs
\[\phi_{lib} := \bigwedge_{1 \le i \le N} \phi_i(\vec I_i, O_i)\]
- \(\psi_{conn}\): connection
\[\psi_{conn} := \bigwedge_{x,y \in \mathbf{P} \cup \mathbf{R} \cup \vec I \cup \{O\}} (l_x = l_y \to x = y)\]
Encode connections in SMT formulas (cont.)
Synthesis Constraint

Counterexample Guided Inductive Synthesis
- solves \(\exists L \forall \vec I: \phi(L, \vec I)\)
- \(\mathcal{S}\): finite set containing valuation of \vec I
- Loop:
- find \(L\) that satisfies \(\phi(L, \vec I_i)\), where \(I_i \in \mathcal{S}\)
- check if \(L\) satisfies the \(\forall\)-clause;
- if not, add the counterexample to \(\mathcal{S}\)
- else, L corresponds to the synthesized program

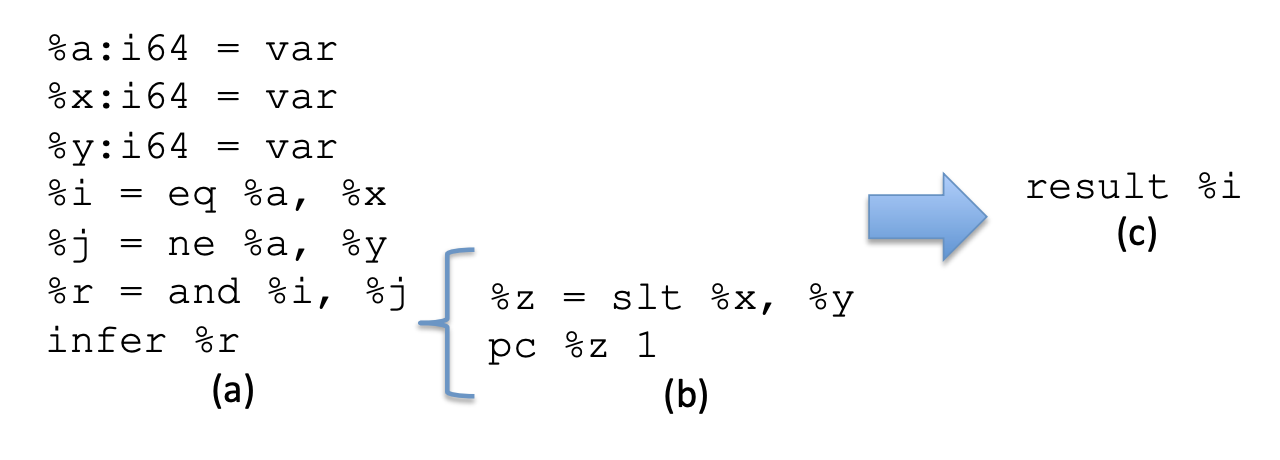
Souper is a superoptimizer based on CEGIS and component-based synthesis.
`infer` marks the entry of superoptimizer.
CEGIS process is wrapped in another loop.
Thus the cost of yielded program is bounded, and the 1st result is always the optimized version.
# Expansions
Expansions
- floating-point: hard to optimize and reason because of rounding error
- STOKE uses ULP (a uniform approximate measure of rounding error) to describe correctness (difference) in searching, and furthermore use Metropolis-Hastings algorithm to find maximum error to validte.
- conditional correctness: equivalent under restricted inputs
- make the input domain smaller to enable better optimization
- cooperative superoptimizer: share the currently found best rewrite
(PLDI'14) Eric Schkufza et al. Stochastic Optimization of Floating-Point Programs with Tunable Precision
(OOPSLA'15) Rahul Sharma et al. Conditionally Correct Superoptimization
(ASPLOS'13) Phitchaya Mangpo Phothilimthana et al. Scaling up Superoptimization
- Comparison of approaches
- Possible project plans
- Reseach possibilities
Summary
Comparison of approaches
# Comparison
| Tool | Approach | Language | Size | Loop? |
|---|---|---|---|---|
| STOKE | Stochastic search | x86-64 | ~100 inst, <=200 inst |
Y |
| Souper | Synthesis | Souper IR (from LLVM IR) | 1KB | N |
| GreenThumb | Enumerative search | ARMv7-A, GreenArrays |
~10 inst, <=30 inst | N |
Possible project plans
# Plans
Reproduce STOKE on ARM64
- A sandbox or instrumented assembler: the one of STOKE (OOPSLA'13) could be regarded as a reference, but more research is needed
- A rewrite generator: counter-example guided simulated annealing (ASPLOS'13) (ASPLOS'17)
- An equivalence checker: migrate the equivalence checker in STOKE onto ARM64 (OOPSLA'13) (PLDI'19)
Research possibilities
# Research possibilities
- improvements inspired by real programs from Huawei: since equivalence checker is incomplete
- specific to ARM64 (RISC ISA): improve current approaches
- conditions of input: maybe developers of Huawei could give some useful & complicated restrictions of domain knowledge
- data-driven invariant (precondition) generation: our group is familiar with this technique
Superoptimization
By Xingyu Xie




