



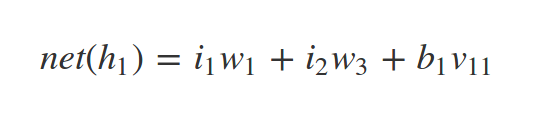
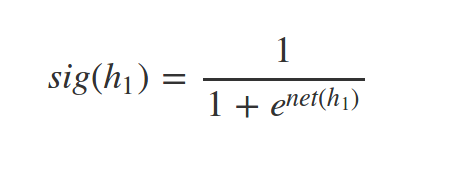
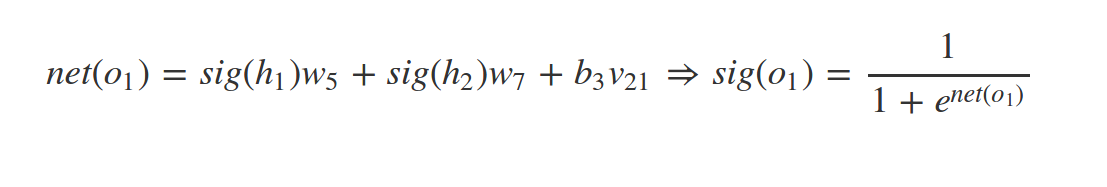
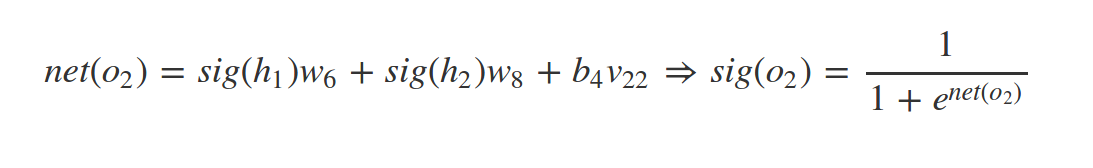
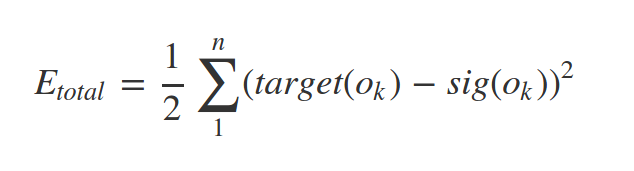
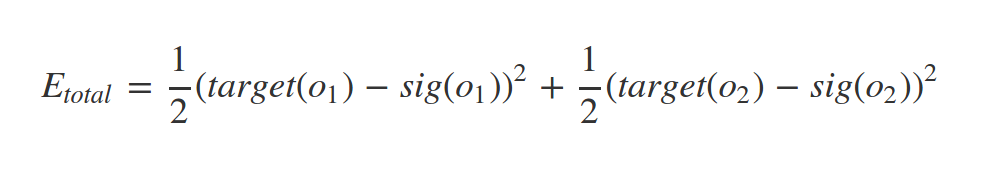

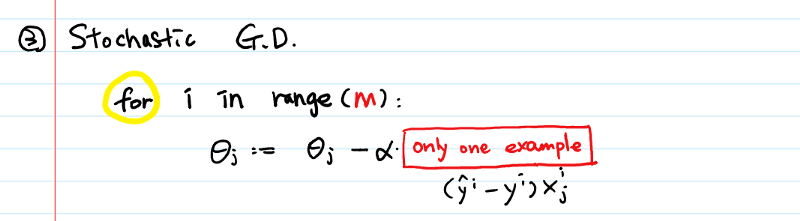
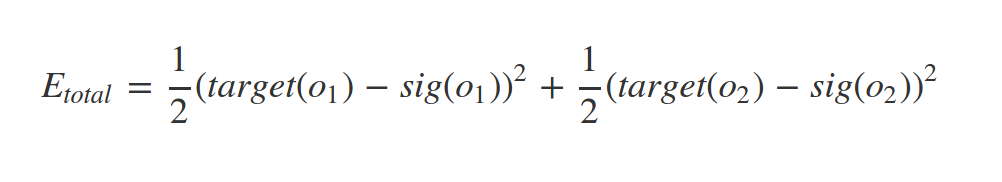
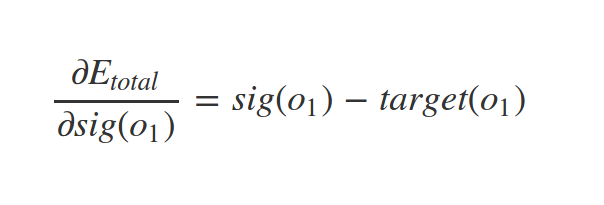
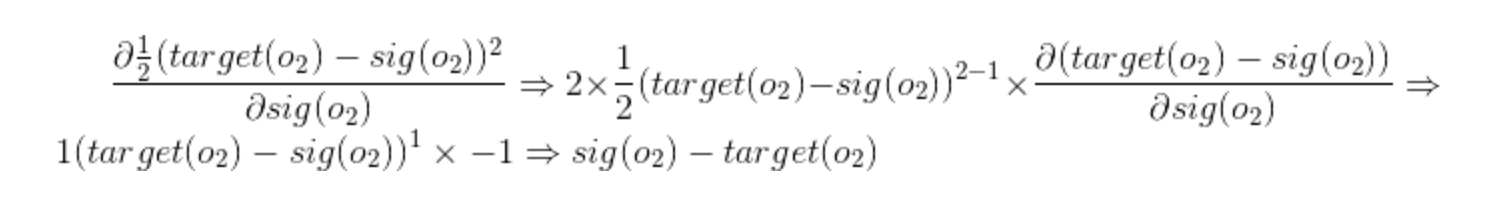
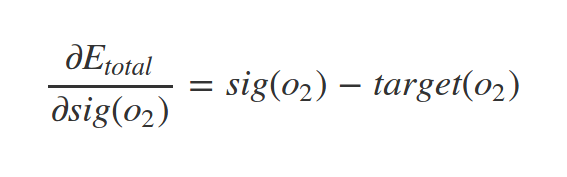
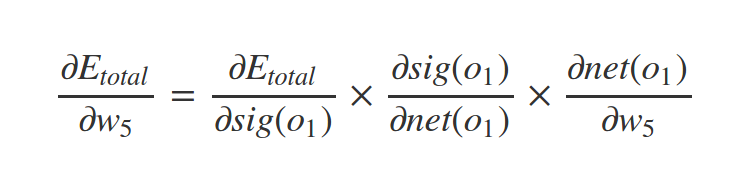
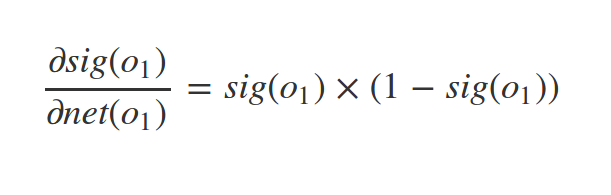
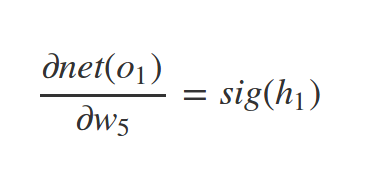
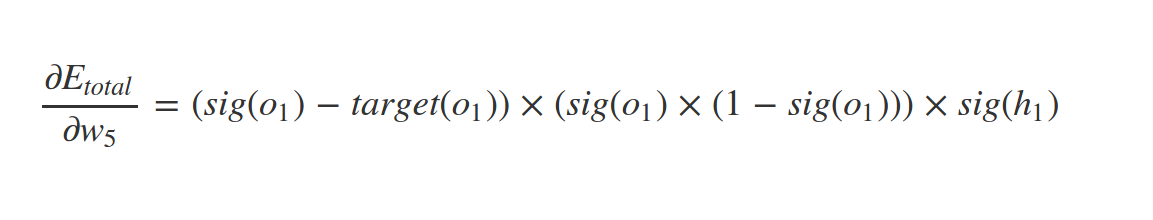
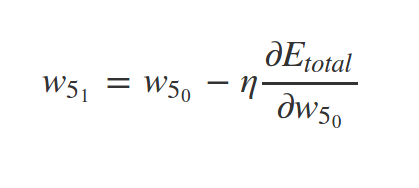
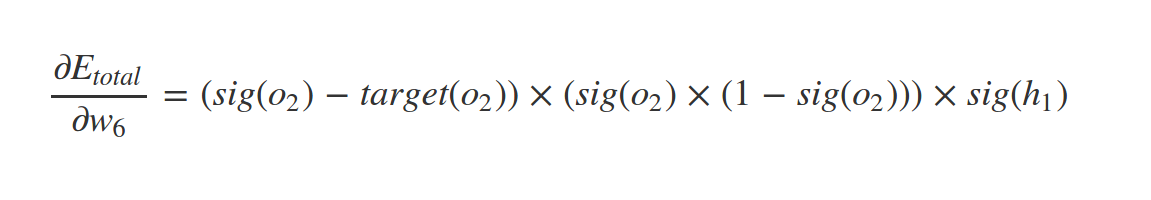
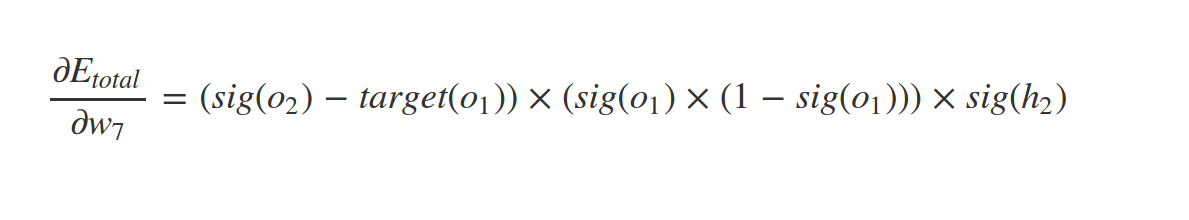
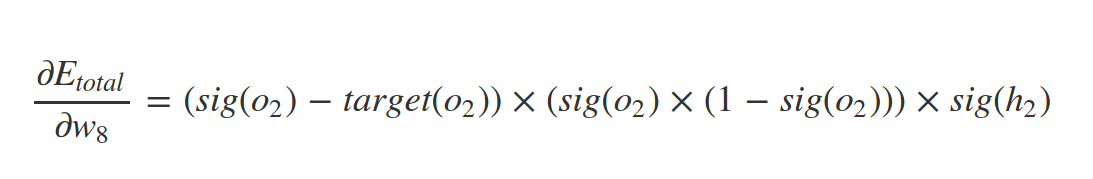
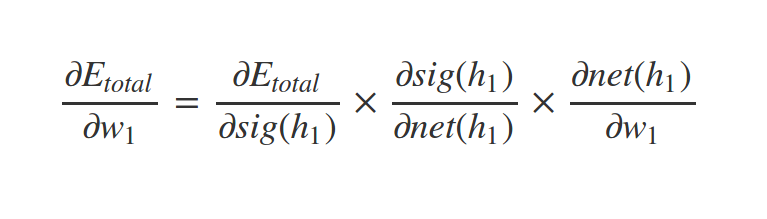
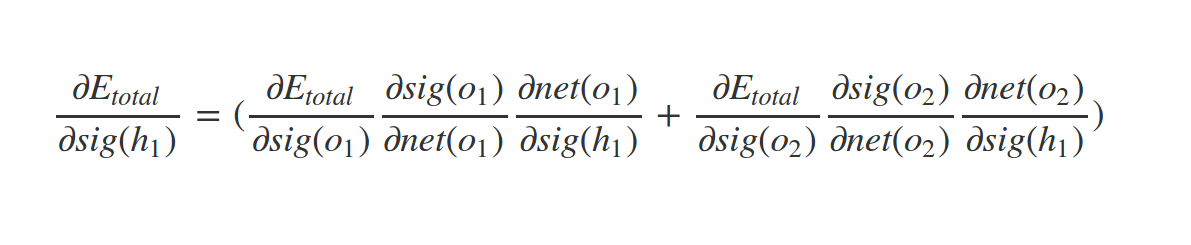
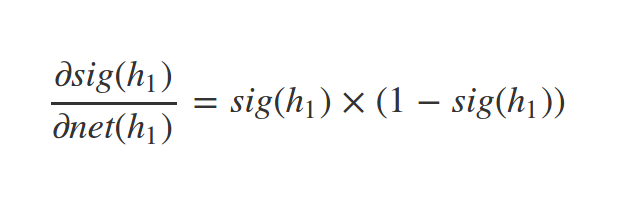
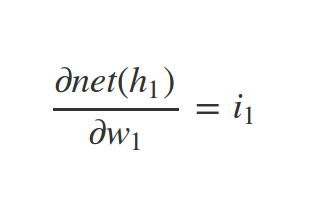
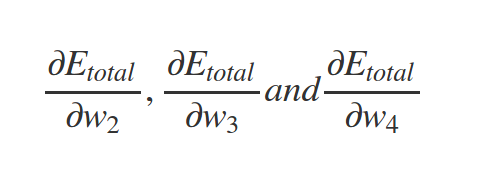
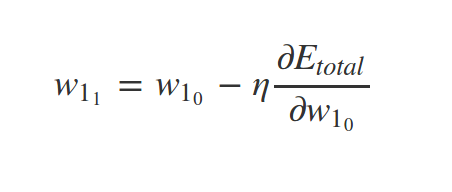
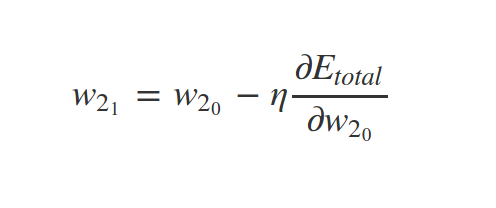
Alireza Afzal Aghaei
Graduate student at SBU
Alireza Afzal Aghaei
M.Sc student at SBU
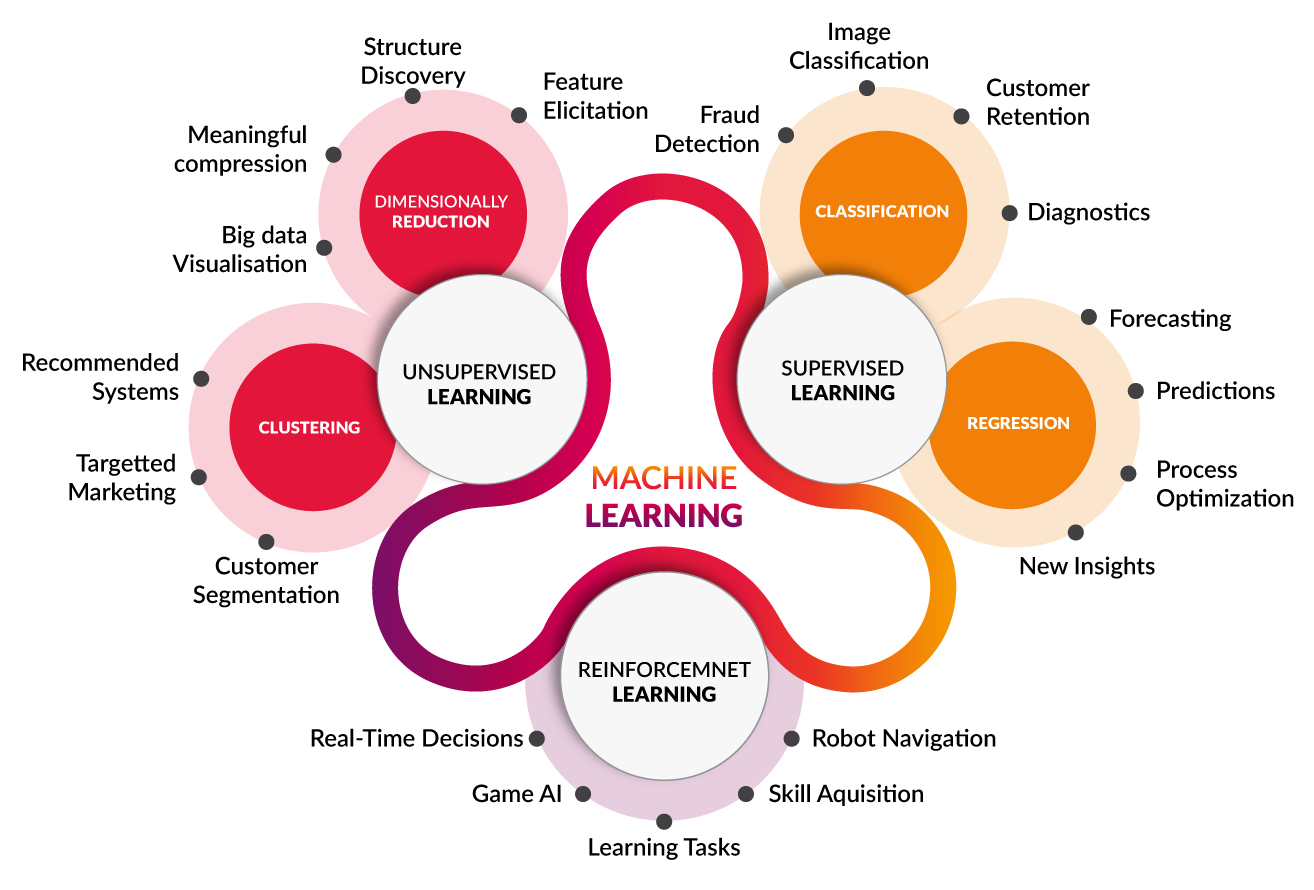
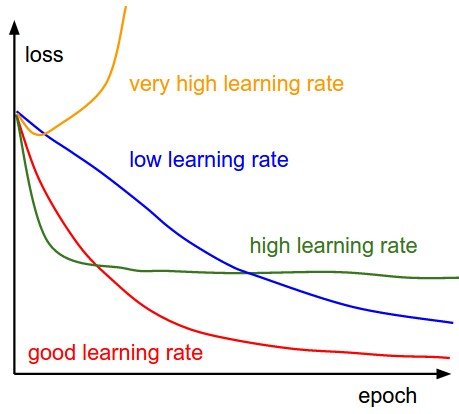
offline learning vs online learning
The motivation of studies in neural networks lies in the flexibility and power of information processing that conventional computing machines do not have
Information processing occurs at many simple elements called neurons.
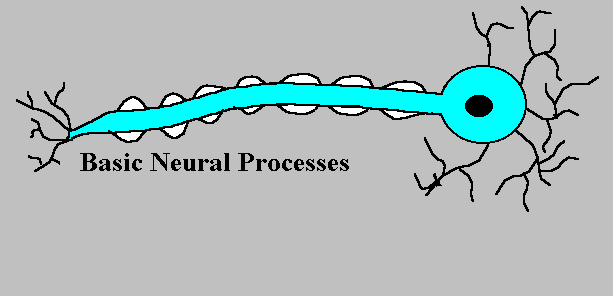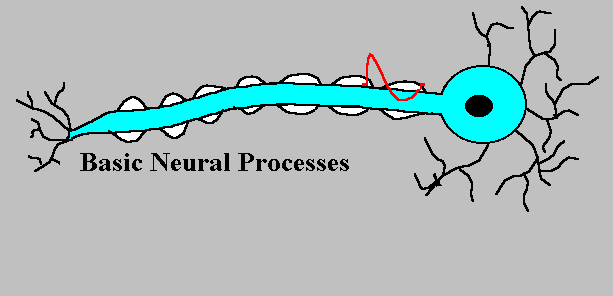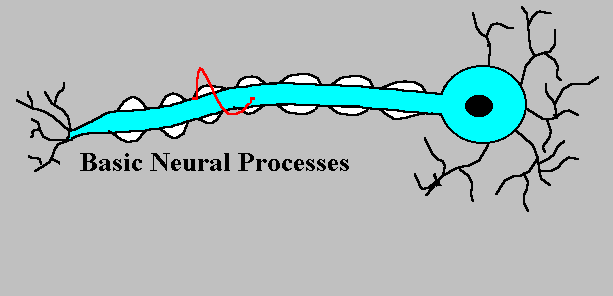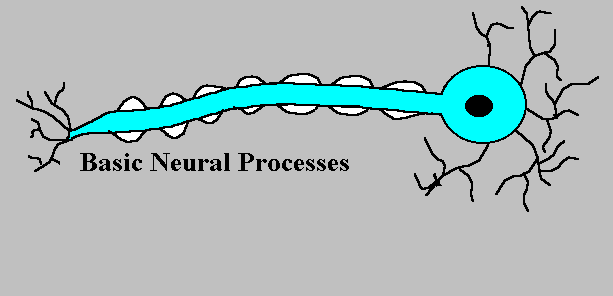
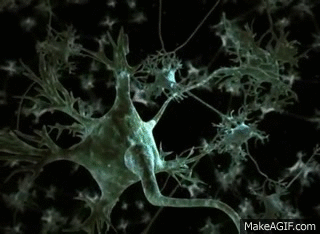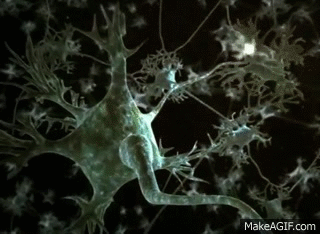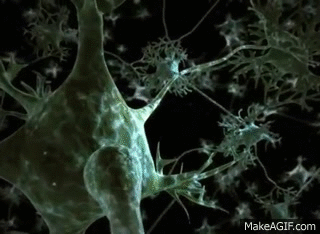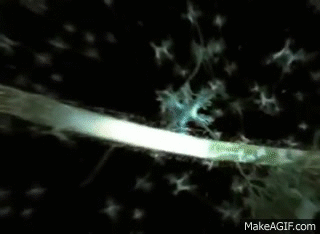
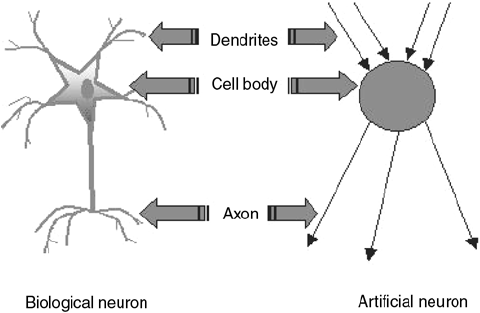
LET'S DIVE INTO BIOLOGY
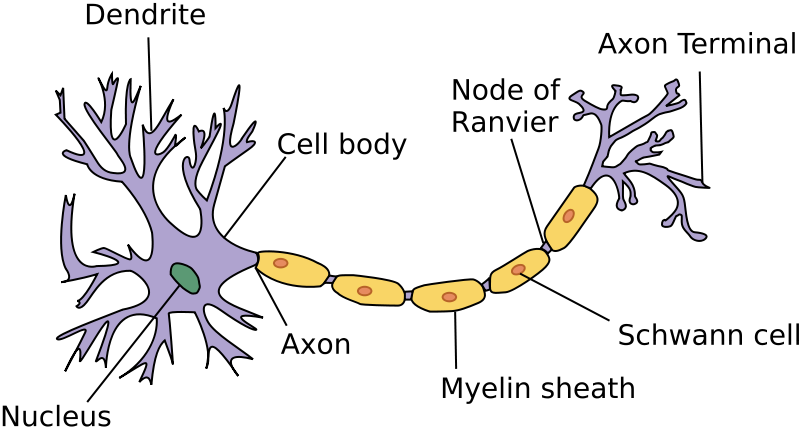
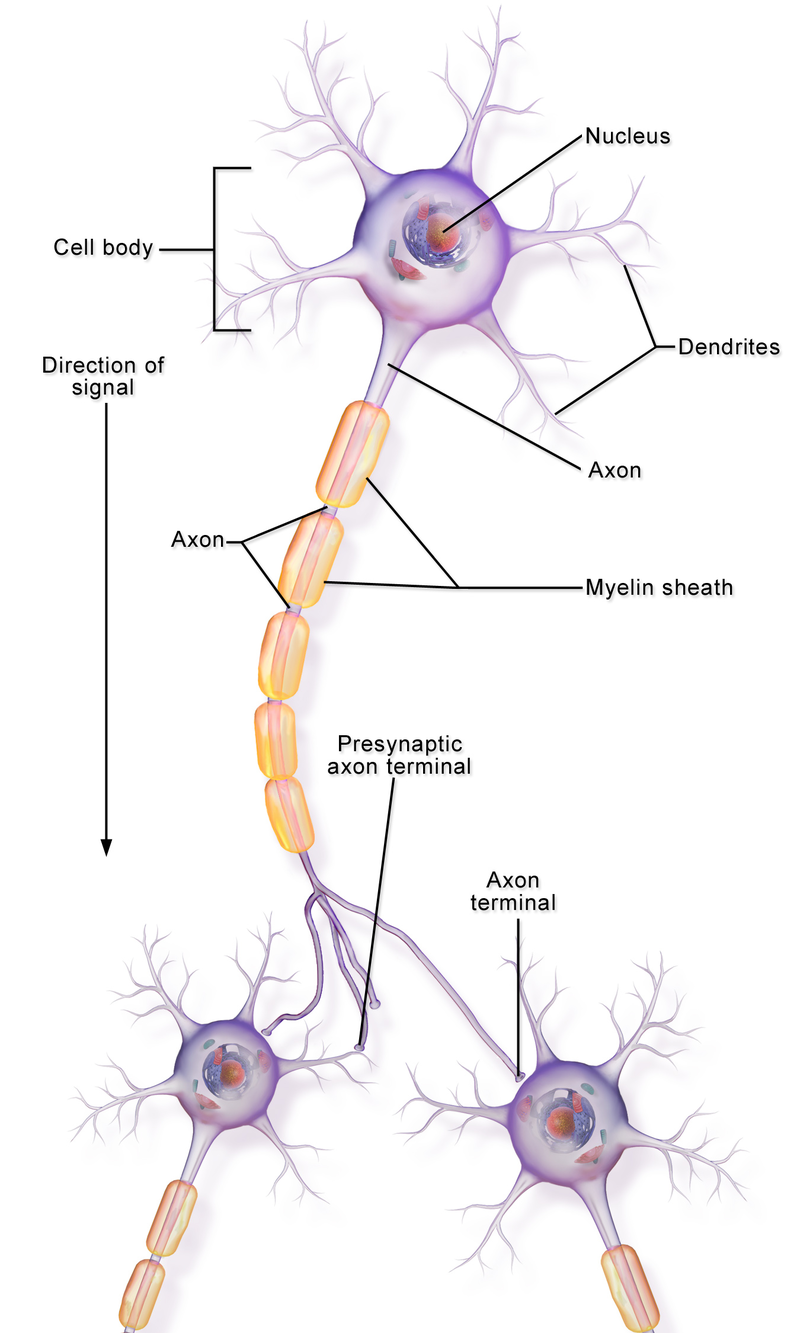
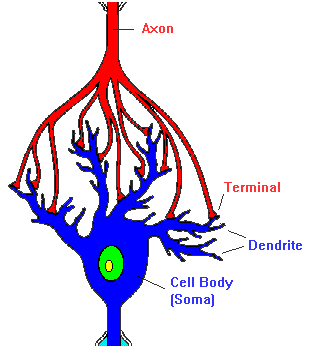
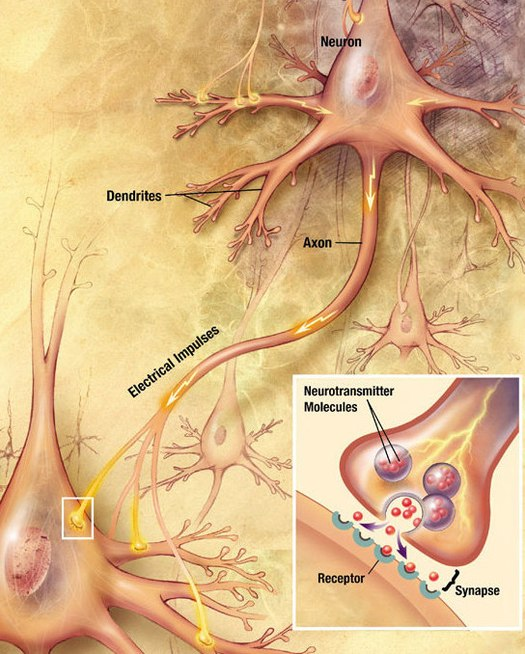
A neuron, is an electrically excitable cell that receives, processes, and transmits information through electrical and chemical signals
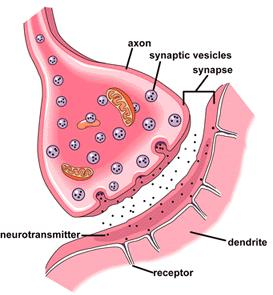
the connection between the two neurons is strengthened when both neurons are active at the same time
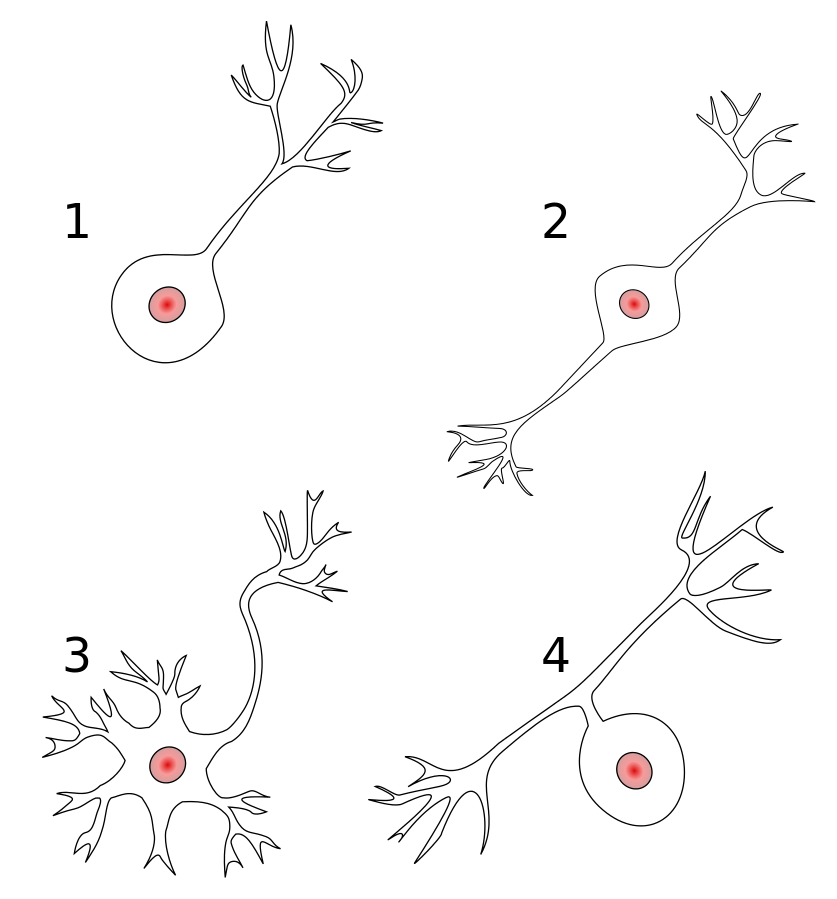
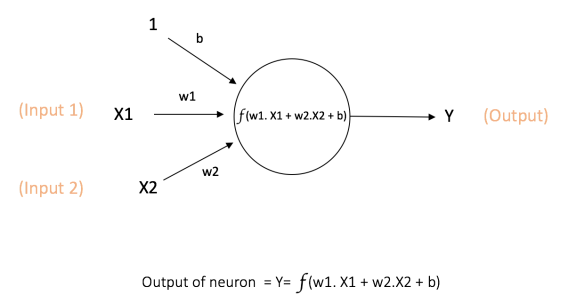
Dendrite: It receives signals from other neurons
Soma: It sums all the incoming signals to generate input
Axon: When the sum reaches a threshold value, neuron fires
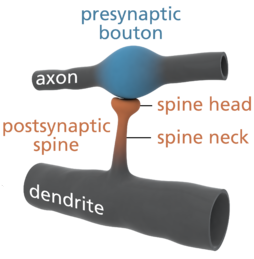
Synapses: The point of interconnection of one neuron with other neurons
The connections can be inhibitory or excitatory in nature
Hebb rule
So, neural network, is a highly interconnected network of billions of neuron with trillion of interconnections between them
LET'S DIVE INTO ARTIFICIAL NEURAL NETWORKS
| Criteria | BNN | ANN |
|---|---|---|
| Processing | Massively parallel, slow
|
Massively parallel, fast but inferior than BNN |
| Size | 10 11 neurons and 10 15 interconnections | Depends |
| Learning | Tolerate ambiguity | Precise |
| Fault tolerance | robust | Performance degrades with partial damage |
| Storage | synapse | Continuous memory |
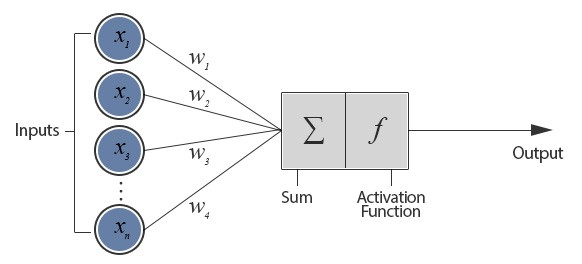
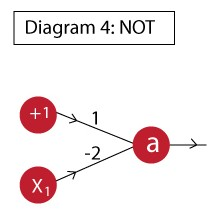
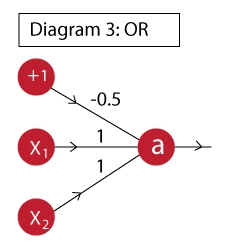
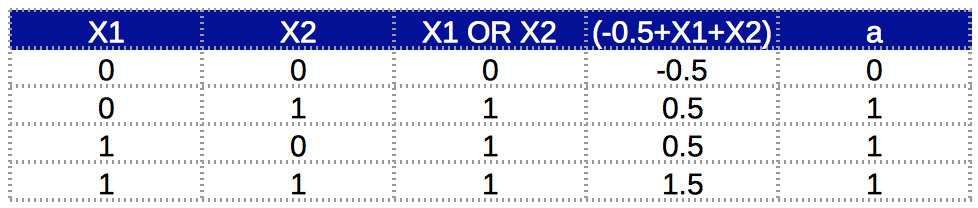
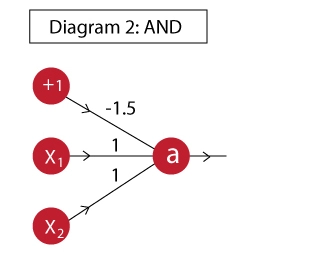
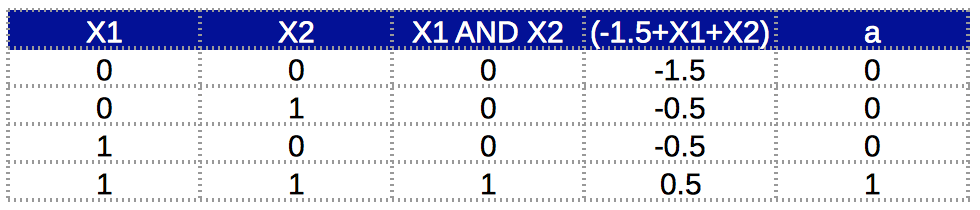
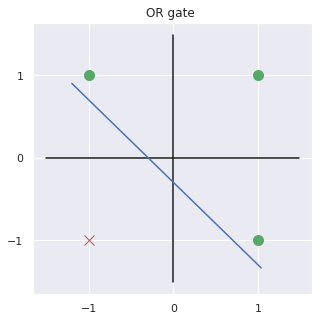
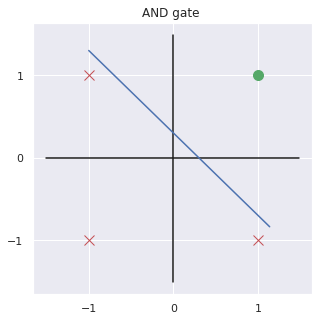
we call this artificial neuron perceptron
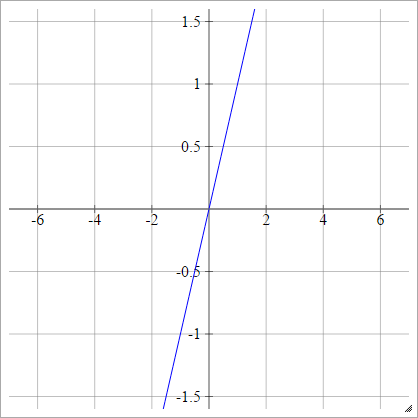
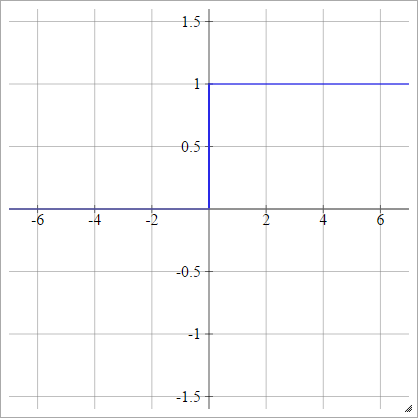
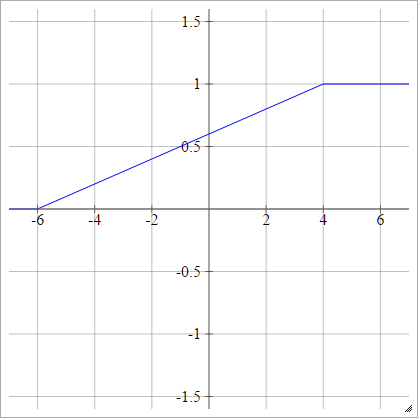
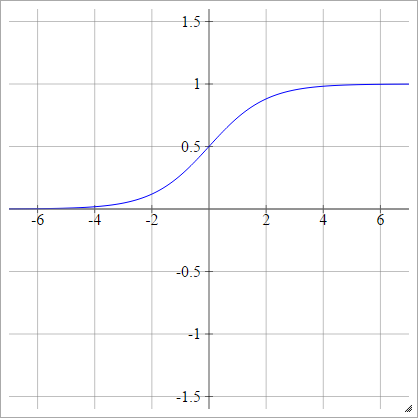
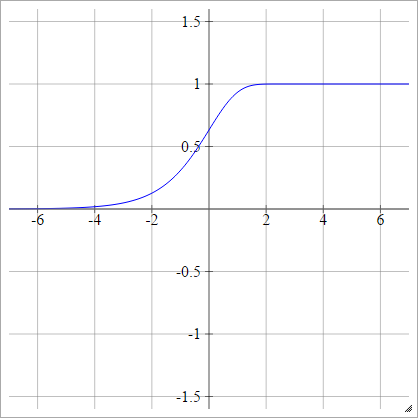
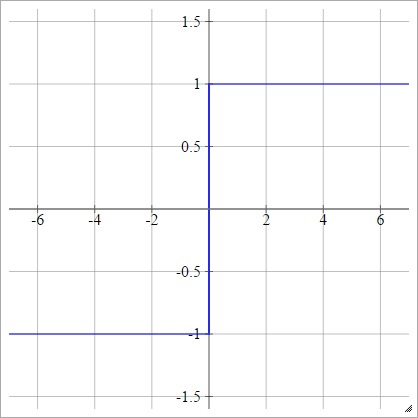
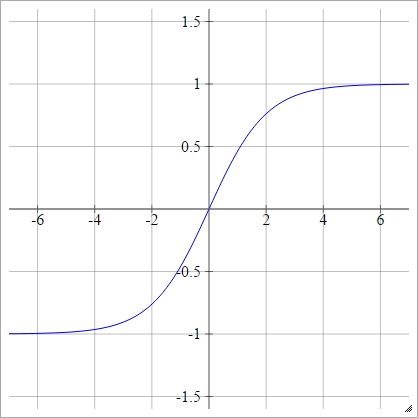
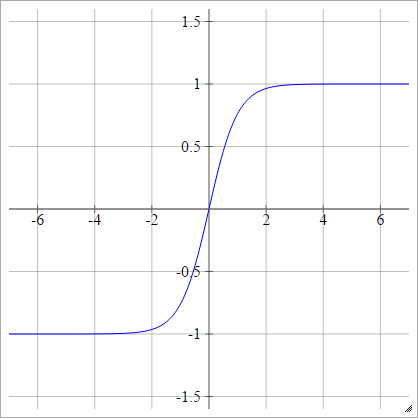
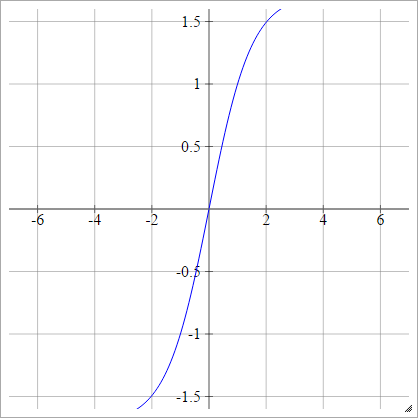
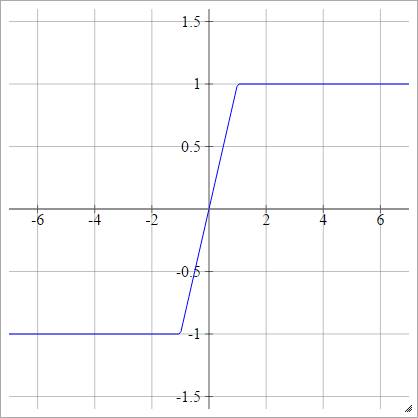
Can we use any arbitrary activation function?
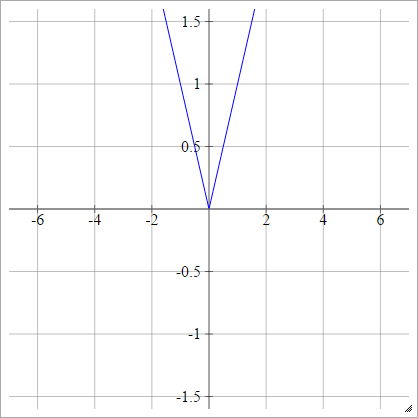
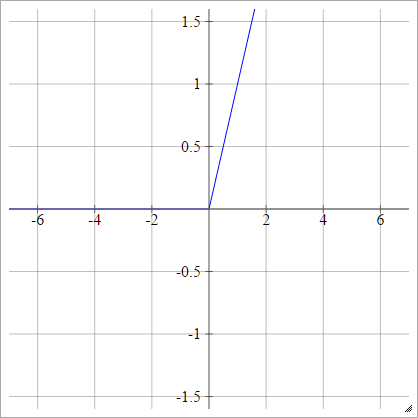
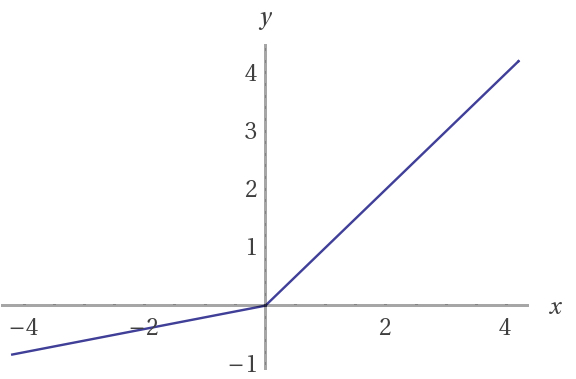
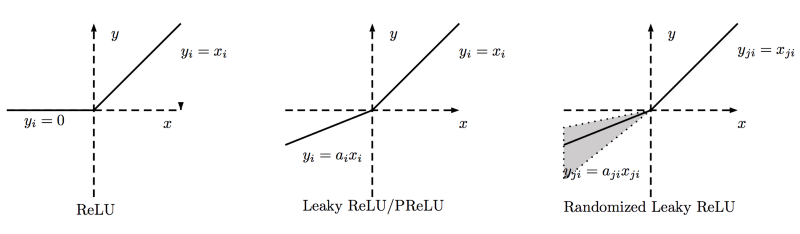
Why ReLU is Non linear?
For negative X the gradient go towards 0 so the weights will not get adjusted during gradient descent
It has proved that 6 times improvement in convergence from Tanh function
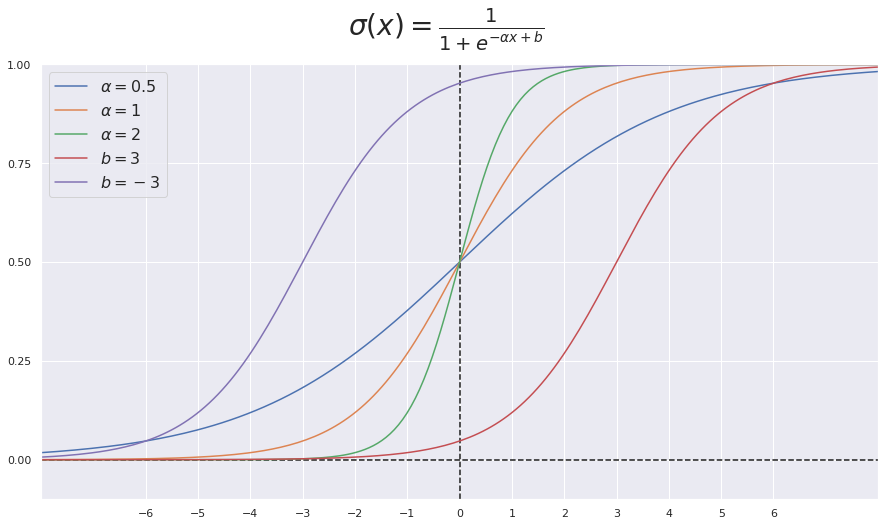
Sigmoid function used for the two-class classification
Softmax function is used for the multi-class classification
Bias allows us to shift the activation function to the left/right
Let's see some Examples
Seams easy, Nah?
Oh wait!
How can we find the weights?!
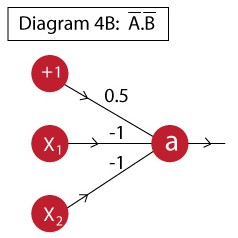
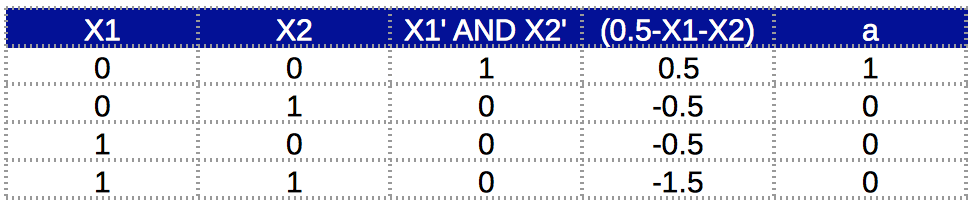
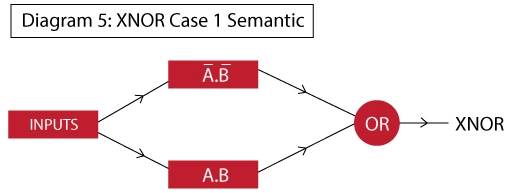
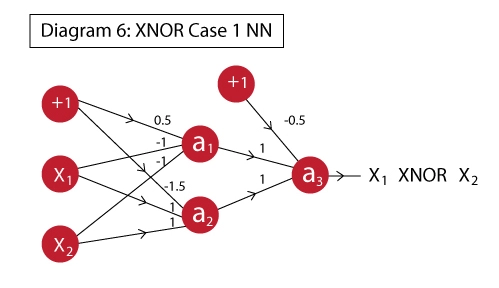
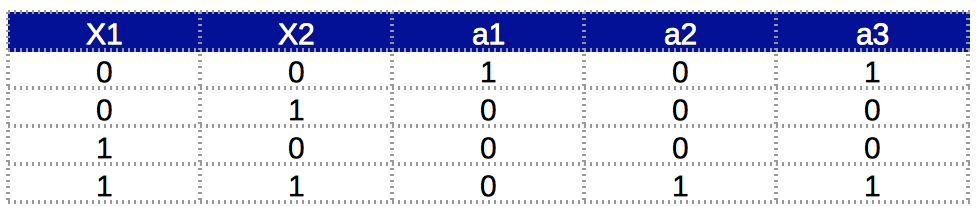
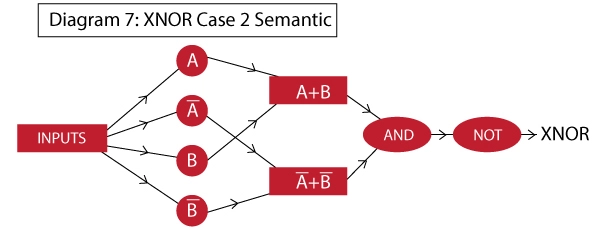
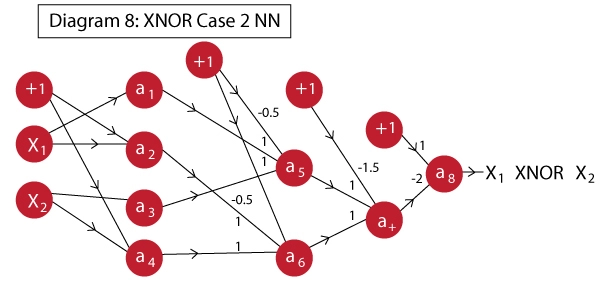
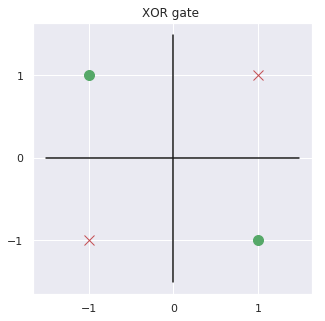
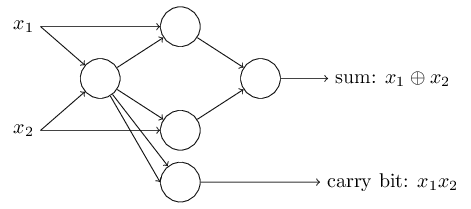
Can we implement XOR gate in a single neuron?
Before answer to this question let's ask a few more!
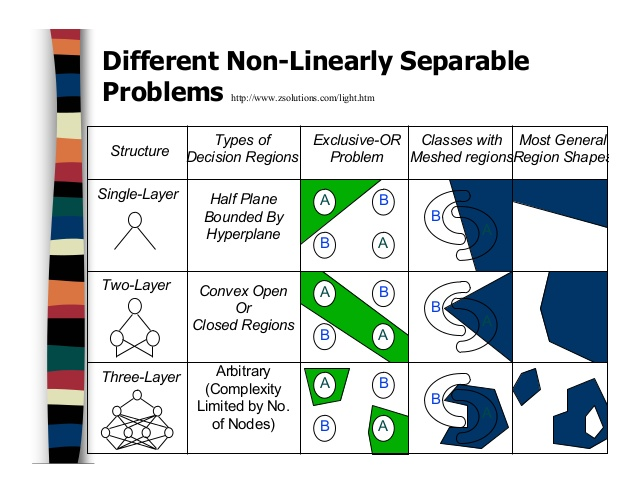
whats best architecture for our data?
A neural network is made up of multiple logistic regressions
unfortunately it's time to
DIVE INTO MATHEMATICS
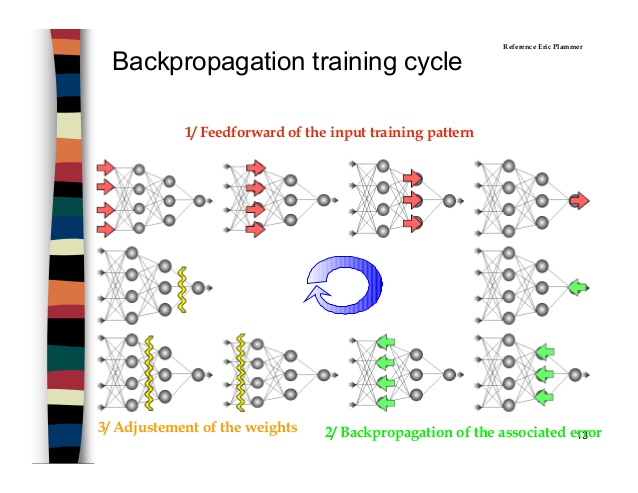
In this section we focus on Supervised Learning to train our neural network
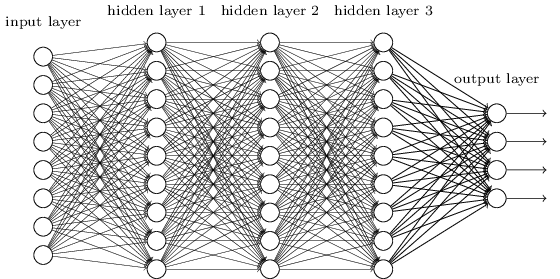
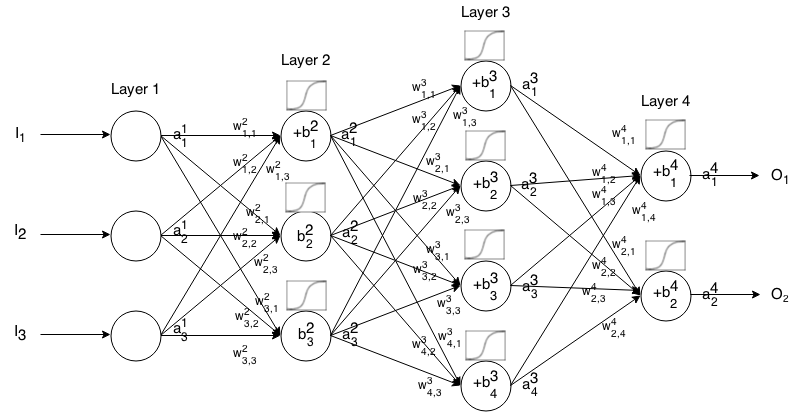
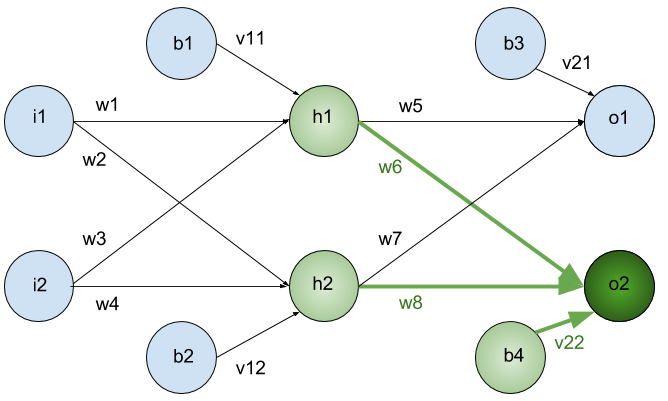
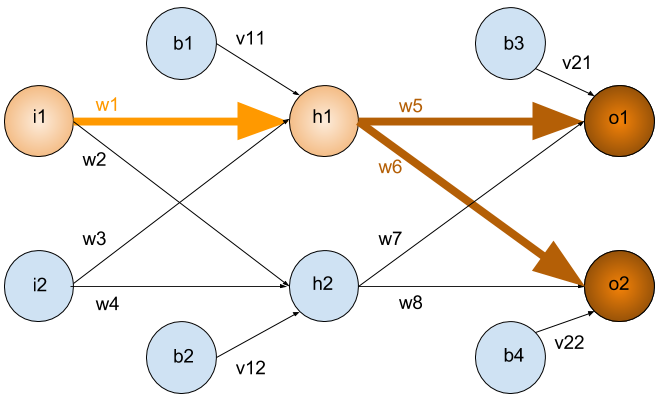
We split our network to 3 main layers
This type of Artificial neural network known as MultiLayer Perceptron (MLP)
Since there is no cycle in this architecture we call this Feed Forward Network
Now can you guess why we shouldn't use linear activation function?
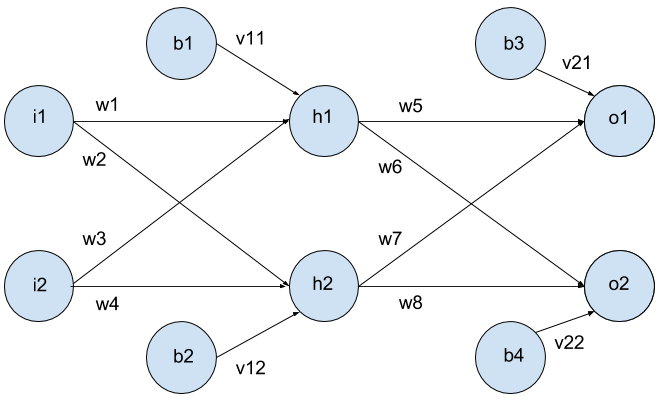
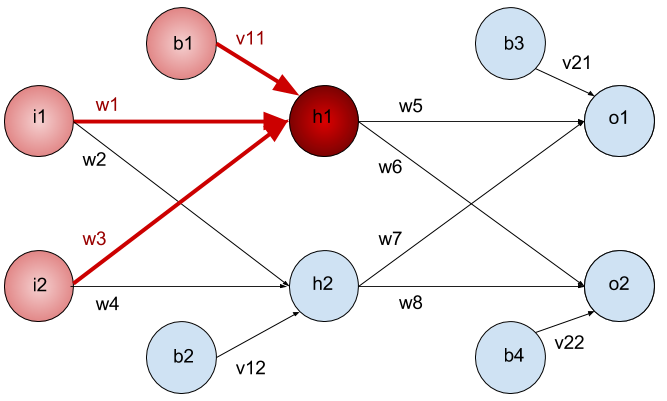
Lets start with an example
Whats \(net(h_2)\) and \(sig(h_2)\) ?
since we have target value of our samples (supervised learning) we can find the error of network predict as follow:
some times this called loss function
Where n = number of neurons at output layer
In our example:
In order to get best predicts we need to minimize error value
To minimize error we can:
since
As you saw this lost function has a quadratic form
It's obvious that this function may has much many variables
so we cant use calculus to find the minimum!
Here we focus on Gradient descent algorithm
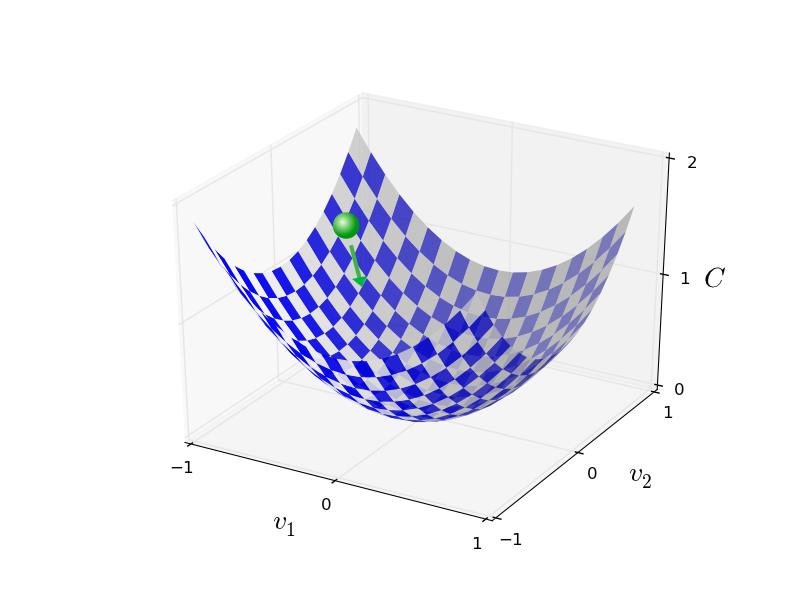
Let's forget neural network aspects of this function
Just think you have a n-variable quadratic function and we want to minimize it
we simulate the random ball's rolling down motion by computing derivatives of function
Since
we are going to find a way to make \(\Delta C\) negative
Define:
So:
we want to make \(\Delta C\) negative since we look for a good \(\Delta v\)
let's suppose \(\Delta v = -\eta \nabla C^T\)
we had \(\Delta C \approx \nabla C \cdot \Delta v \) so:
Obviously \(\Delta C \lt 0\)
GOAL:
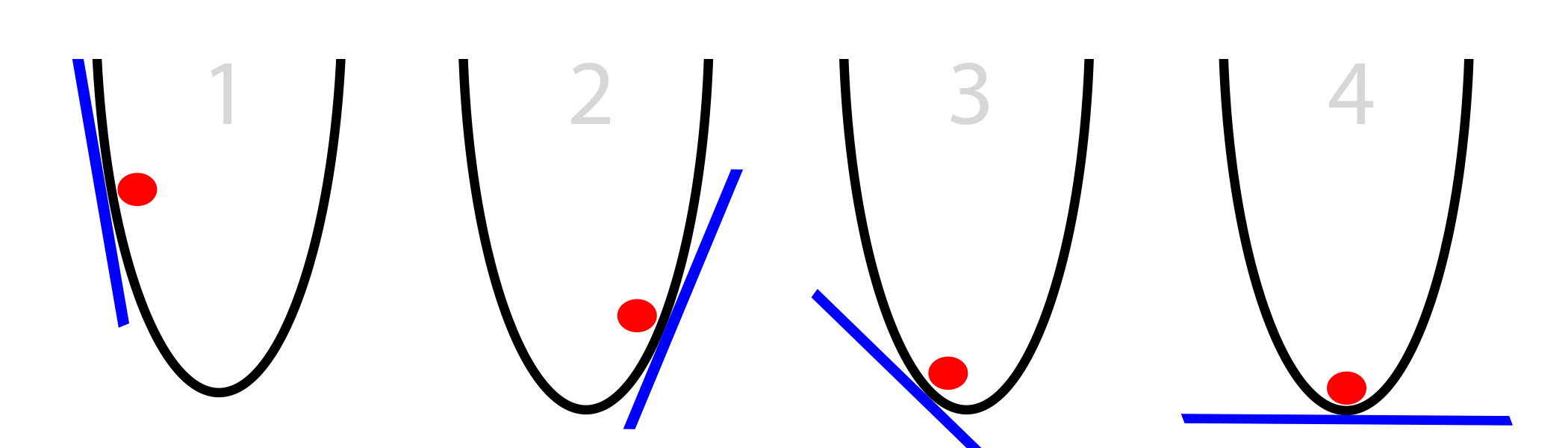
find \(\Delta v\) to change ball position in order to rich the functions minimum
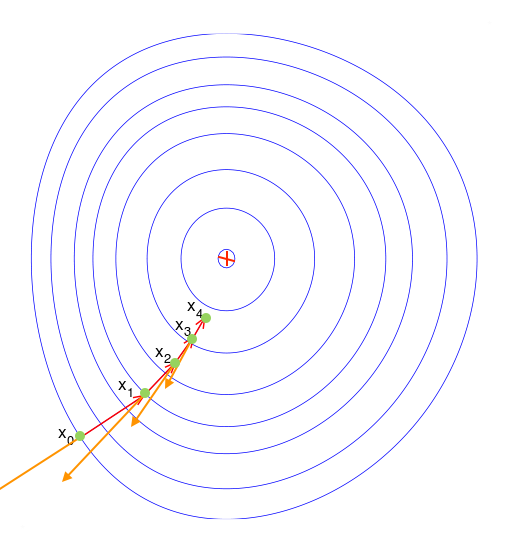
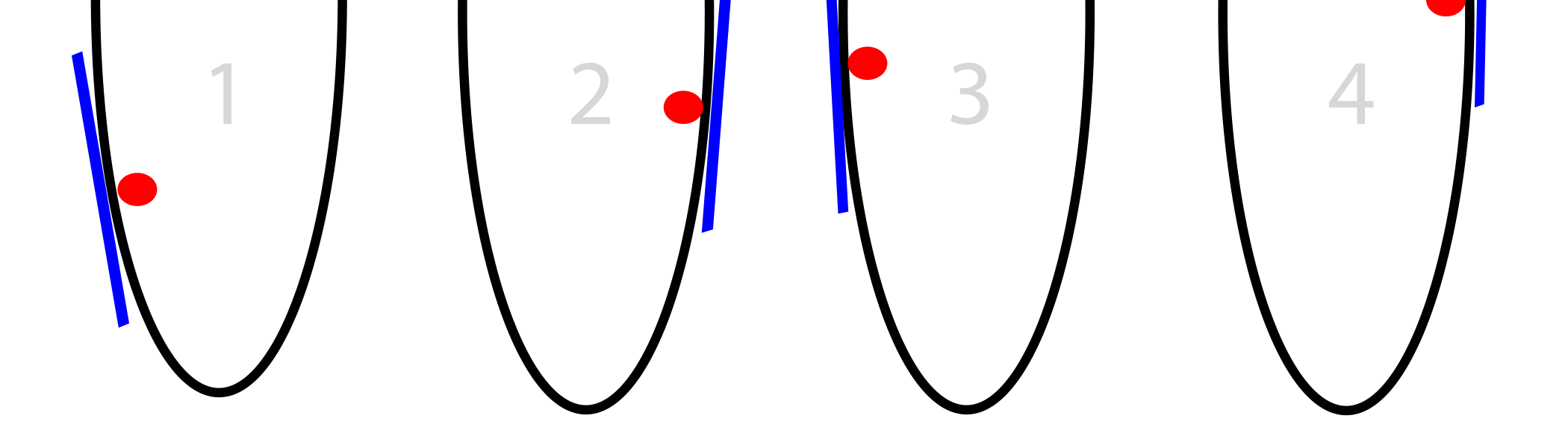
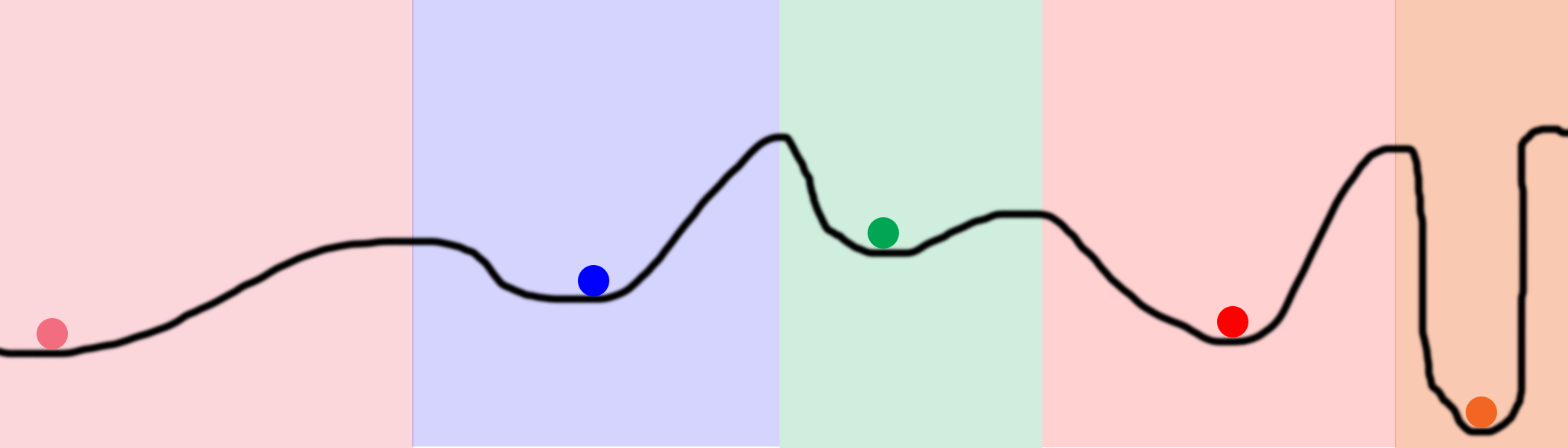
if we do this over and over we rich global minimum
This approach works with more than two variable
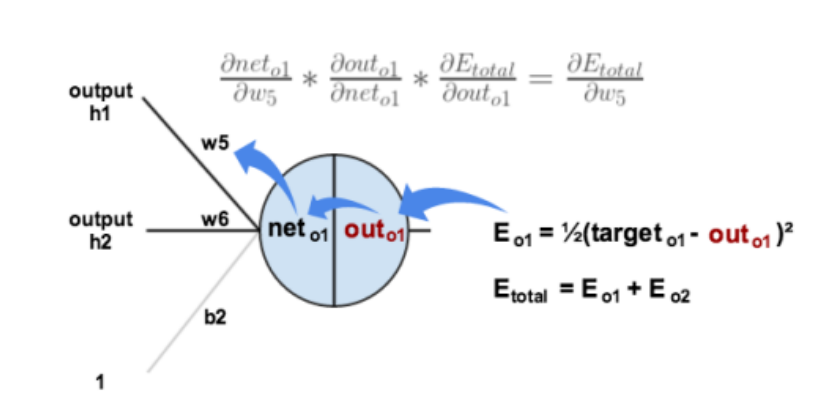
gradient descent in neural network form
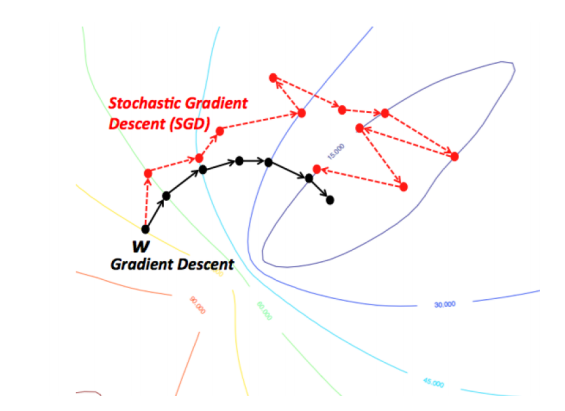
Computes gradient with the entire dataset
Performs update for every mini-batch of n examples
Same as Mini-batch but unit batch size on shuffled data
How to find \(\nabla C\)?
Derivative of sigmoid
Similarly we have:
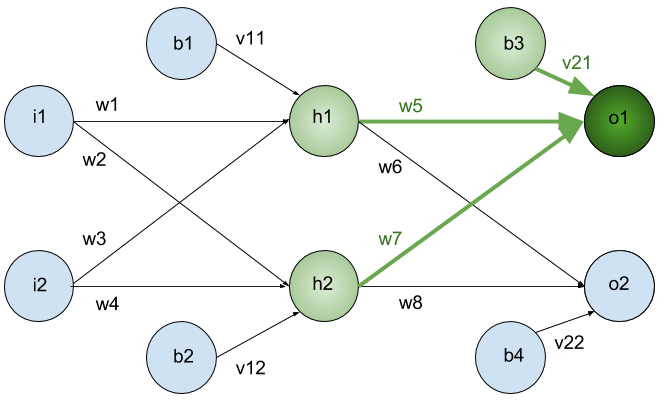
What about \(w_1\) ?
Similarly
And so on . . .
What about biases?
Now you know why we need an activation function with big gradient for all inputs!
Why \(\eta\) ?
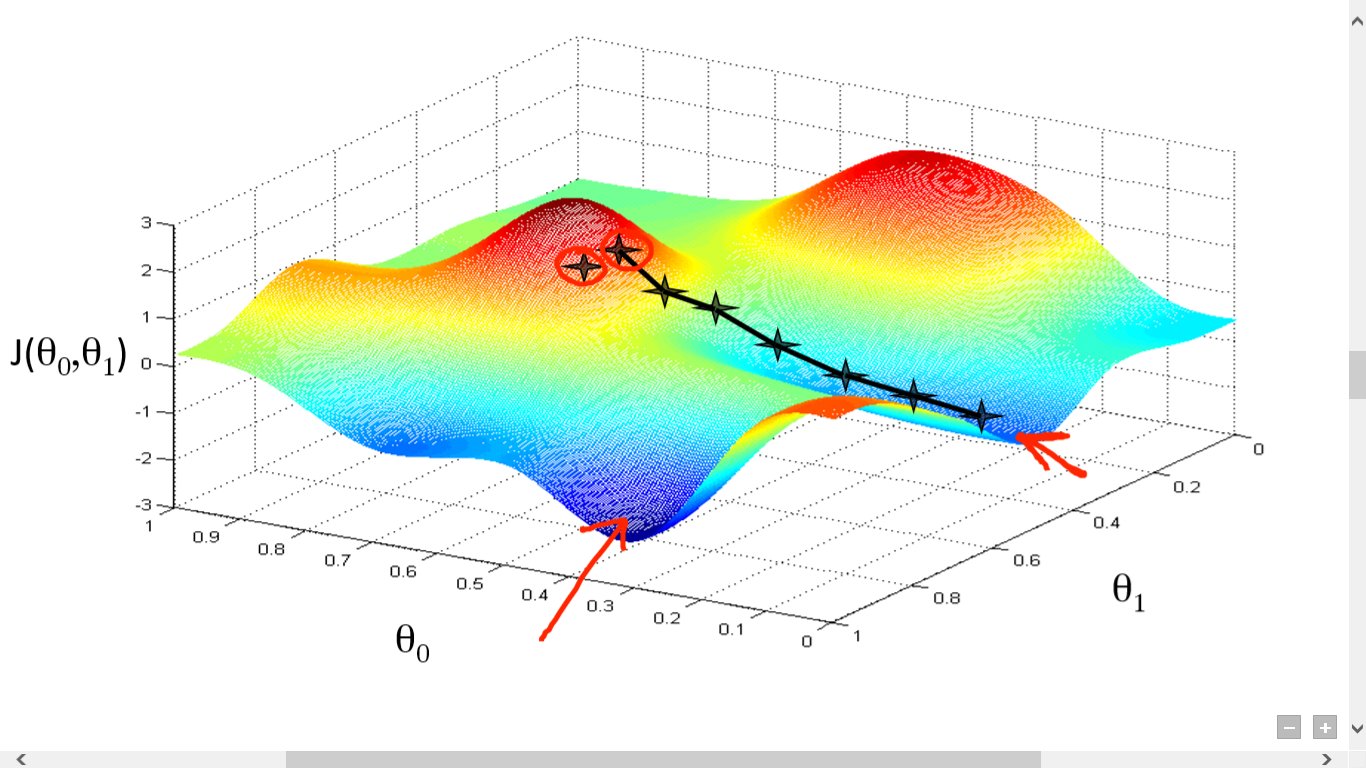
Local minimum and gradient descent!
http://iamtrask.github.io/2015/07/27/python-network-part2/
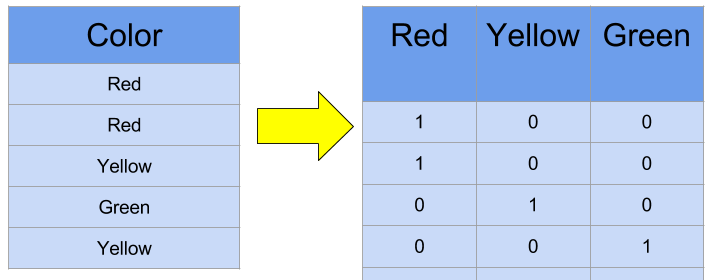
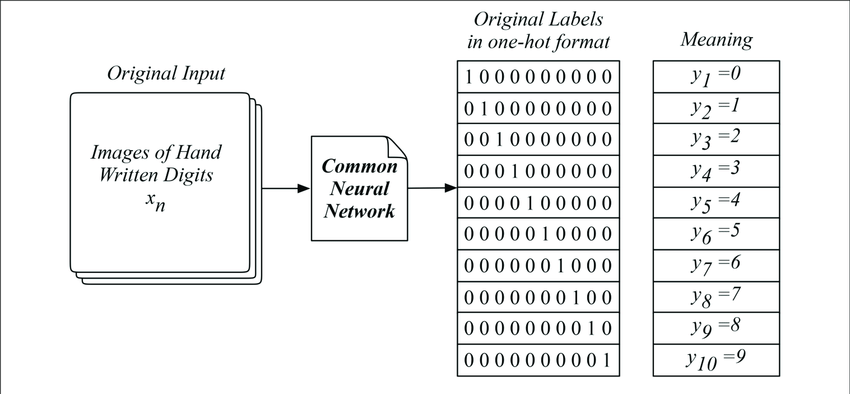
Categorical or Nominal data
Many machine learning algorithms cannot operate on label data
Theorem.
2 layer MLP is a universal approximator
datasets: train,test,valid
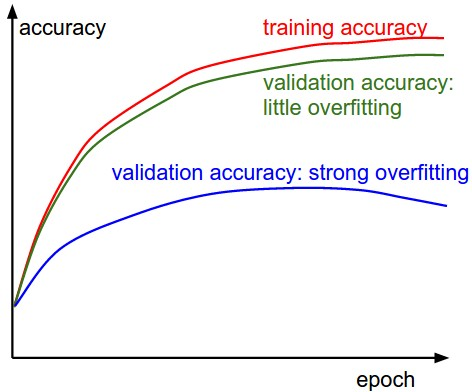
over-fit, vs under-fit -> regulaization
fully connected-layer, dense
https://stats.stackexchange.com/questions/297749/how-meaningful-is-the-connection-between-mle-and-cross-entropy-in-deep-learning
https://stats.stackexchange.com/questions/167787/cross-entropy-cost-function-in-neural-network
https://datascience.stackexchange.com/questions/9302/the-cross-entropy-error-function-in-neural-networks
https://www.quora.com/What-are-the-differences-between-maximum-likelihood-and-cross-entropy-as-a-loss-function
https://aboveintelligent.com/deep-learning-basics-the-score-function-cross-entropy-d6cc20c9f972
https://en.wikipedia.org/wiki/Perceptron
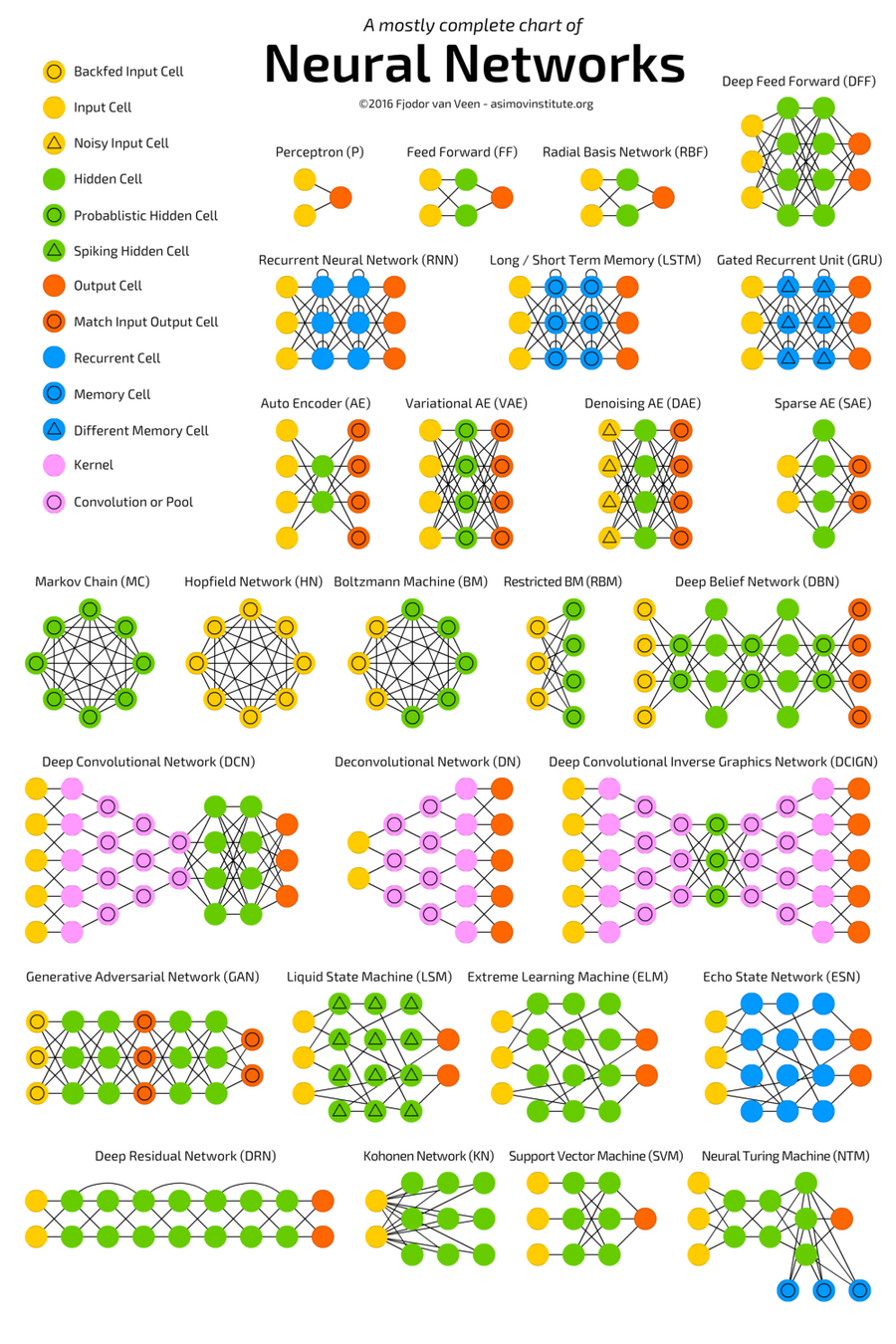
delta rule,hebb,backpropagation,feed forward
https://medium.com/biffures/all-the-single-neurons-14de29a40f47
https://towardsdatascience.com/logistic-regression-detailed-overview-46c4da4303bc
https://en.wikipedia.org/wiki/Backpropagation
https://ml4a.github.io/ml4a/how_neural_networks_are_trained/
https://www.slideshare.net/MohdArafatShaikh/artificial-neural-network-80825958
https://juxt.pro/blog/posts/neural-maths.html
http://www.robertsdionne.com/bouncingball/
softmax probability vs sigmoid
KIYOSHI KAWAGUCHI, BSEE , A MULTITHREADED SOFTWARE MODEL FOR BACKPROPAGATION NEURAL NETWORK APPLICATIONS, 2000
By Alireza Afzal Aghaei




