
Alireza Afzal Aghaei
Graduate student at SBU
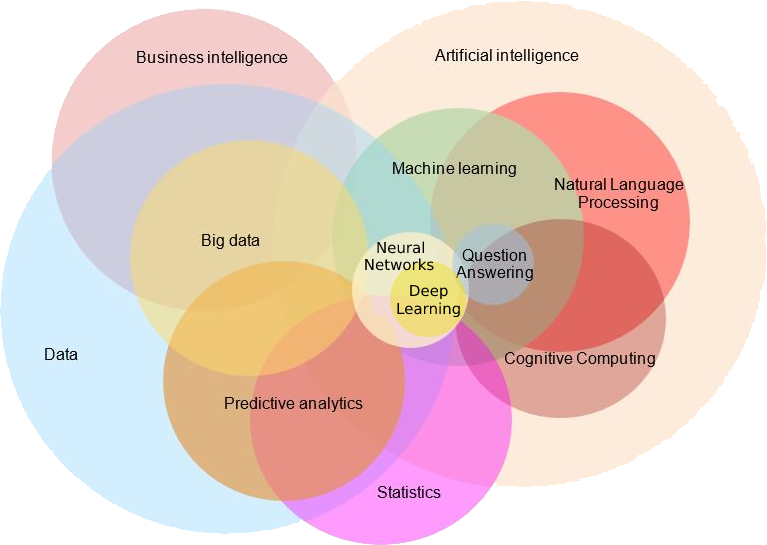
Artificial Intelligence is the intelligence demonstrated by machines or robots, as opposed to the natural intelligence displayed by humans or animals.
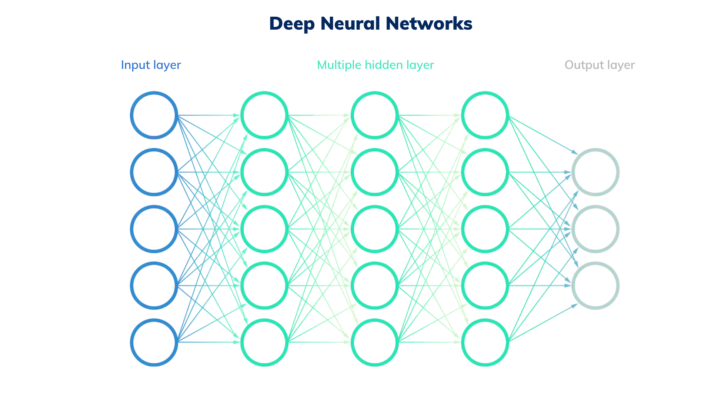
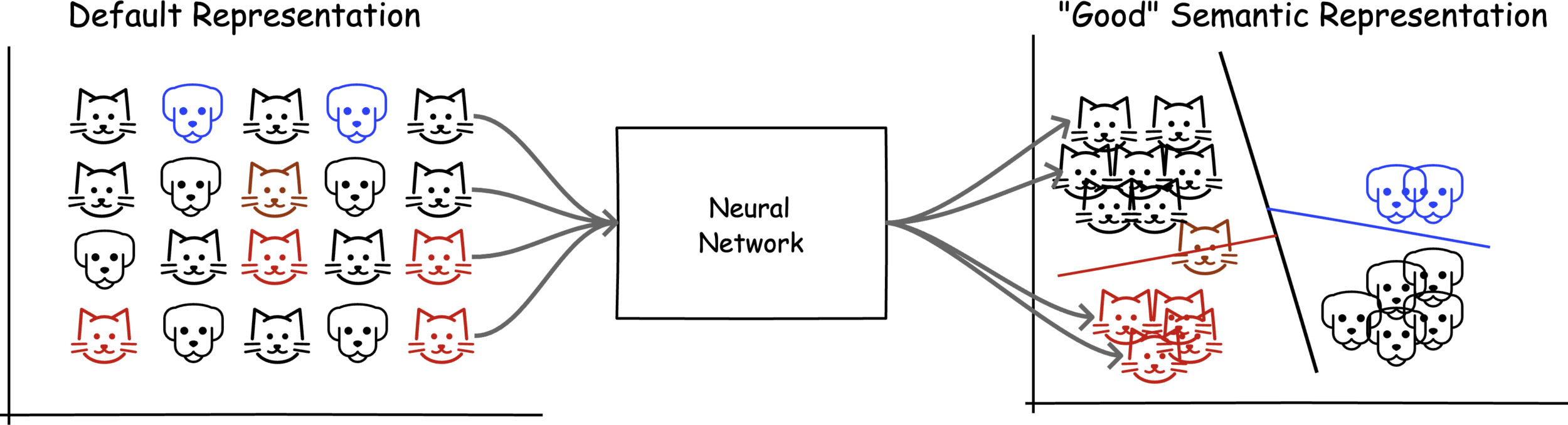
Machine Learning is a subset of AI that utilizes advanced statistical techniques to enable computing systems to improve at tasks with experience over time.
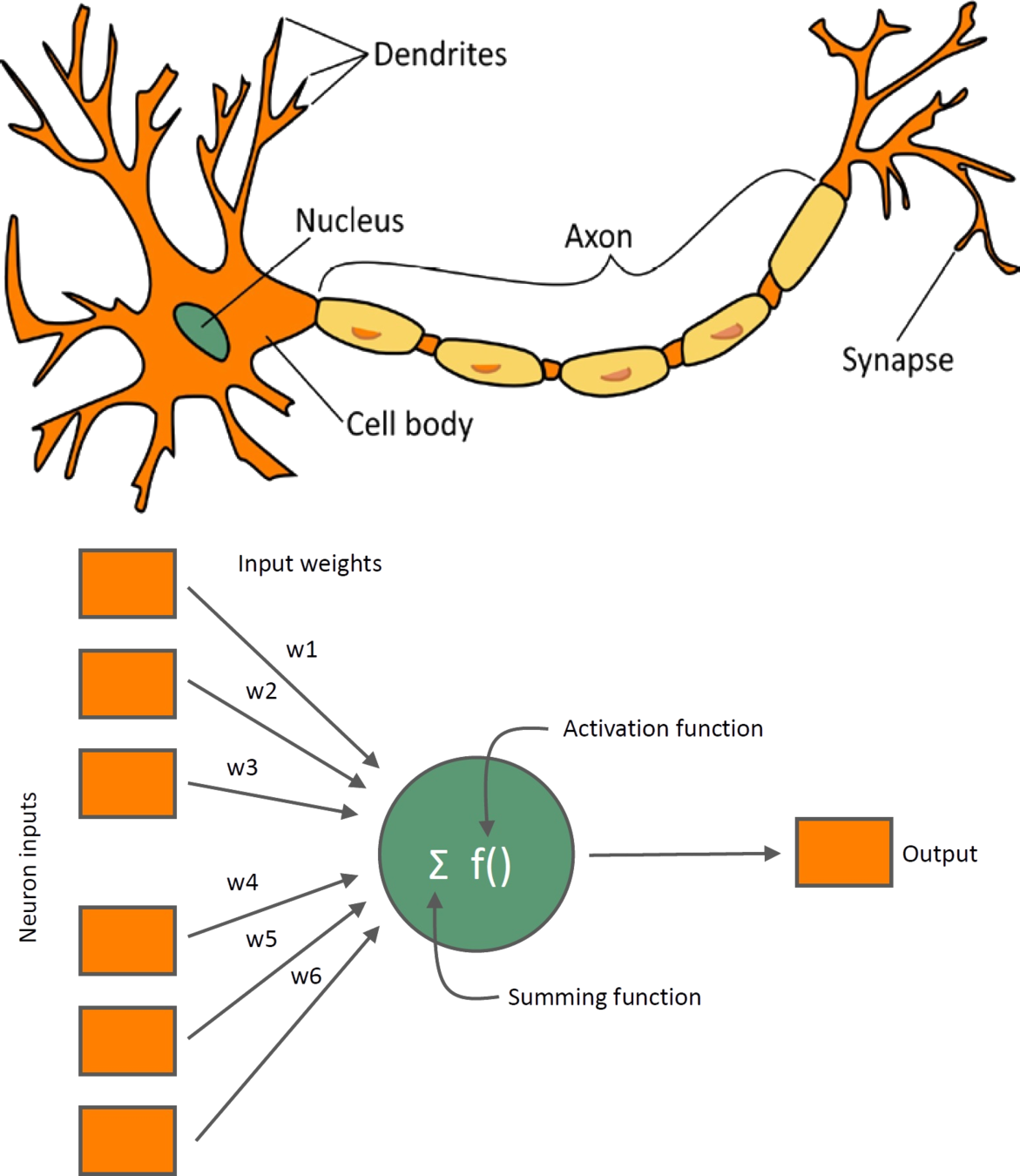
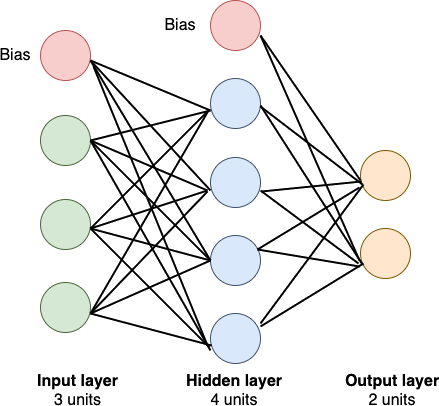
$$y = f(w^T x + b)$$
$$f(x)=\frac{1}{1+e^{-\alpha x}}$$
$$f(x)=tanh(x) = 2\ sigmoid(2x) - 1$$
$$L(y , \hat y) = \frac{1}{N}\sum_{i=1}^N(y_i - \hat y_i)^2$$
$$L(y , \hat y) = \frac{1}{N}\sum_{i=1}^N|y_i - \hat y_i|$$
If we employ:
Then to find the optimal parameters, we can use a first-order gradient-based optimization algorithm.
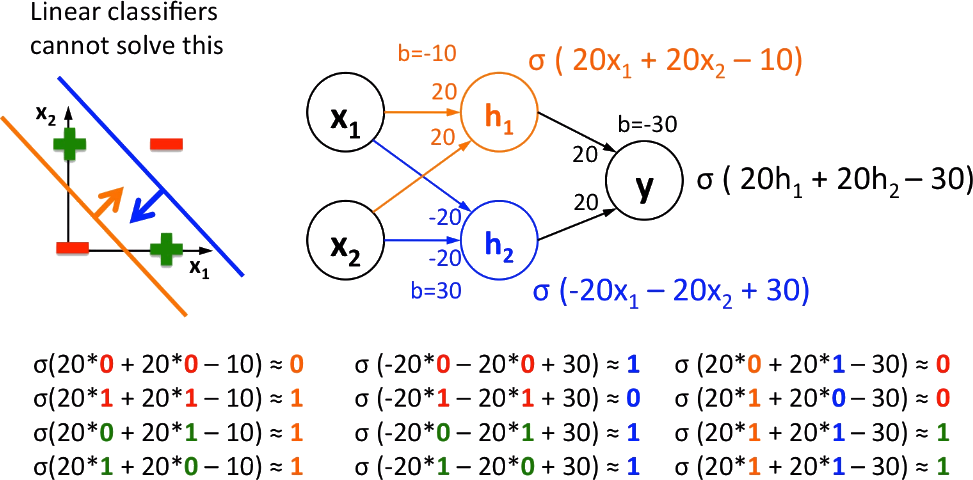
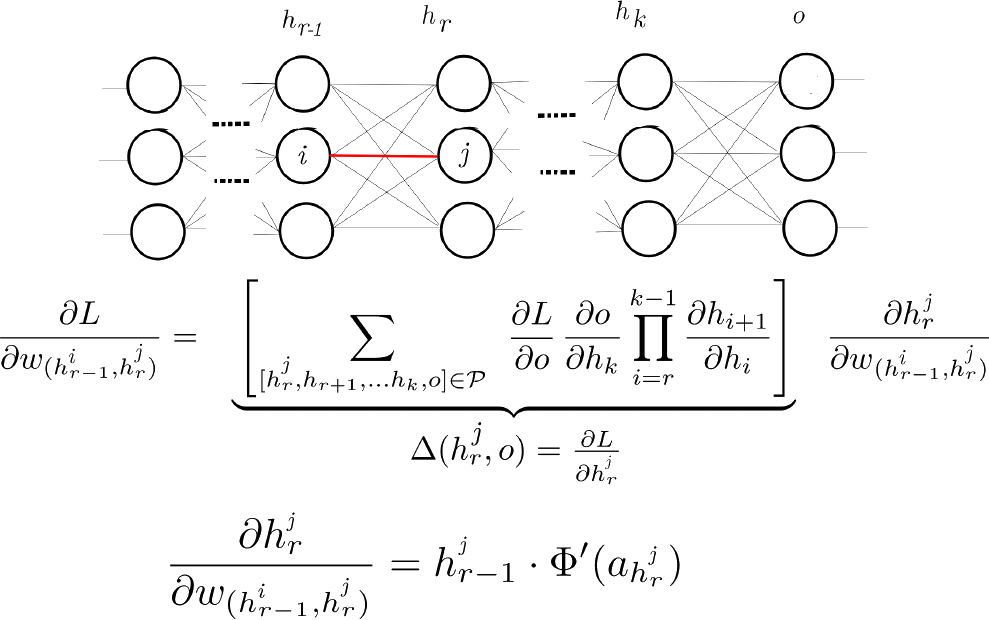
How to find the gradient of loss function w.r.t parameters?
$$w^{(new)} = w^{(old)} - \eta \nabla_{w} L(w)$$
$$\begin{aligned} v_t &= \gamma v_{t-1} + \eta \nabla_{w} L(w) \\ w^{(new)} &= w^{(old)} - v_t \end{aligned}$$
$$\begin{aligned} g_t &= \nabla_{w_t} L(w_t)\\ m_t &= \beta_1 m_{t-1} + (1 - \beta_1) g_t \\ v_t &= \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 \\ w^{(new)} &= w^{(old)} - \dfrac{\eta}{\sqrt{\hat{v}^{(old)}} + \epsilon} \hat{m}^{(old)} \end{aligned}$$
| Task | Dataset | Architecture | # of params |
|---|---|---|---|
| Language Modelling | WikiText-103 | GLM-XXLarge | 10B |
| Machine Translation | WMT2014 French-English | GPT-3 | 175B |
| Image Classification | ImageNet | ViT-MoE-15B | 14.7B |
| Object Detection | COCO | YOLO-V3 | 65M |
Computationally Expensive
Use more efficient optimizers, momentum, adam, etc.
Vanishing & Exploding Gradients
By Alireza Afzal Aghaei




