

Eric Earl
Eric Earl is a Neuroinformaticist acting as a Data Scientist in the NIMH Data Science & Sharing Team.
and enough regular expressions to get you in trouble.
DSST Lunch & Learn
Thursday, March 10, 2022
grep
global search regular expression print (g/re/p)
sed
stream editor
awk
A. Aho
P. Weinberger
B.W. Kernighan
# history
# regex
A pattern describing a certain amount of text where the engine stops after the first appearance of a match.
# regex
# regex
# regex
# regex
# regex
# regex
# regex
# regex
# regex
# regex
# regex
Print the first (1-indexed) column in the file "file".
awk -F , '{print $3}' some.csv
# awk
> ls -l
total 594356
-rwxr-x--- 1 earlea users 150314498 Feb 15 16:56 abcd_fastqc01_reformatted.csv
-rw-r--r-- 1 earlea users 309218172 Feb 24 13:57 abcd_fastqc01.txt
drwxrwx--- 7 earlea users 4096 Feb 15 16:47 BIDS
-rw-r--r-- 1 earlea users 149070377 Aug 27 2021 fmriresults01.txt
-rw-rw---- 1 earlea users 2044 Oct 5 15:39 fmriresults01.txt.header
-rw-rw---- 1 earlea users 1938 Oct 5 15:40 fmriresults01.txt.NDAR_INV1L1ZCWL5
> ls -l | awk '{print $9}'
abcd_fastqc01_reformatted.csv
abcd_fastqc01.txt
BIDS
fmriresults01.txt
fmriresults01.txt.header
fmriresults01.txt.NDAR_INV1L1ZCWL5# awk
# awk
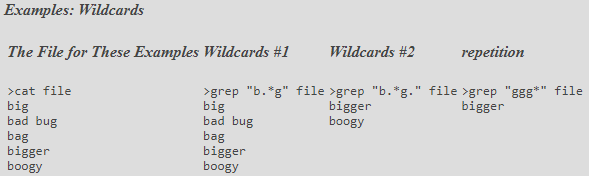
Returns all the lines that contain a string matching the expression "foo" in the file "file".
cat file | grep foo > newfile
# grep
Note the original on the left.
# grep
# grep
> head -n 3 datasets.txt
ds000001
ds000002
ds000003
> wc -l datasets.txt
640 datasets.txt
> grep 3 datasets.txt | wc -l
339
> grep -v 3 datasets.txt | wc -l
301
> grep -e 3 -e 4 datasets.txt | wc -l
434
> grep -v -e 3 -e 4 datasets.txt | wc -l
206# grep
> head -n 3 datasets.txt
ds000001
ds000002
ds000003
> wc -l datasets.txt
640 datasets.txt
> grep 3 datasets.txt | wc -l
339
> grep 3 datasets.txt | grep 4 | wc -l
107
> grep 3 datasets.txt | grep -v 4 | wc -l
232Finds all regular expression matches for "find" and replaces them with "replace" in the file "file".
cat file | sed 's|a|b|g' > newfile
# sed
> cat file I have three dogs and two cats > cat file | sed 's|dog|cat|g' I have three cats and two cats
# sed
# sed
# sed
> cat file
I have three dogs and two cats
> cat file | sed 's|.\+\(...s\).\+\(...s\)|\1 \2|g'
dogs cats
> head -n 1 abcd_fastqc01_reformatted.csv
collection_id,abcd_fastqc01_id,dataset_id,pGUID,src_subject_id,interview_date,SeriesTime,sex,img03_id,origin_dataset_id,EventName,image_file,ftq_series_id,ABCD_Compliant,ftq_complete,ftq_quality,ftq_recalled,ftq_recall_reason,QC,ftq_notes,collection_title,image_description,image_timestamp
> head -n 1 abcd_fastqc01_reformatted.csv | awk -F, '{print $22}'
image_description
> tail -n +2 abcd_fastqc01_reformatted.csv | awk -F, '{print $22}' | sort -u | head -n 5
ABCD
ABCD-Coil-QA
ABCD-Diffusion-FM
ABCD-Diffusion-FM-AP
ABCD-Diffusion-FM-PA
> tail -n +2 abcd_fastqc01_reformatted.csv | awk -F, '{print $22}' | sort -u | grep -v -e "ABCD\$" -e QA | head -n 3
ABCD-Diffusion-FM
ABCD-Diffusion-FM-AP
ABCD-Diffusion-FM-PA
> tail -n +2 abcd_fastqc01_reformatted.csv | awk -F, '{print $22}' | sort -u | grep -v -e "ABCD\$" -e QA | sed 's|ABCD-||g' | head -n 3
Diffusion-FM
Diffusion-FM-AP
Diffusion-FM-PA# awk|grep|sed
By Eric Earl




